shuffleNet v1 v2笔记——总结(重点)
前言
在ResNeXt[3]的文章中,分组卷积作为传统卷积核深度可分离卷积的一种折中方案被采用。这时大量的对于整个Feature Map的Pointwise卷积成为了ResNeXt的性能瓶颈。一种更高效的策略是在组内进行Pointwise卷积,但是这种组内Pointwise卷积的形式不利于通道之间的信息流通,为了解决这个问题,ShuffleNet v1中提出了通道洗牌(channel shuffle)操作。
在ShuffleNet v2的文章中作者指出现在普遍采用的FLOPs评估模型性能是非常不合理的,因为一批样本的训练时间除了看FLOPs,还有很多过程需要消耗时间,例如文件IO,内存读取,GPU执行效率等等。作者从内存消耗成本,GPU并行性两个方向分析了模型可能带来的非FLOPs的行动损耗,进而设计了更加高效的ShuffleNet v2。ShuffleNet v2的架构和DenseNet[4]有异曲同工之妙,而且其速度和精度都要优于DenseNet。
1. ShuffleNet v1




def channel_shuffle(x, groups):
"""
Parameters
x: Input tensor of with `channels_last` data format
groups: int number of groups per channel
Returns
channel shuffled output tensor
Examples
Example for a 1D Array with 3 groups
>>> d = np.array([0,1,2,3,4,5,6,7,8])
>>> x = np.reshape(d, (3,3))
>>> x = np.transpose(x, [1,0])
>>> x = np.reshape(x, (9,))
'[0 1 2 3 4 5 6 7 8] --> [0 3 6 1 4 7 2 5 8]'
"""
height, width, in_channels = x.shape.as_list()[1:]
channels_per_group = in_channels // groups
x = K.reshape(x, [-1, height, width, groups, channels_per_group])
x = K.permute_dimensions(x, (0, 1, 2, 4, 3)) # transpose
x = K.reshape(x, [-1, height, width, in_channels])
return x
从代码中我们也可以看出,channel shuffle的操作是步步可微分的,因此可以嵌入到卷积网络中。
1.2 ShuffleNet v1 单元
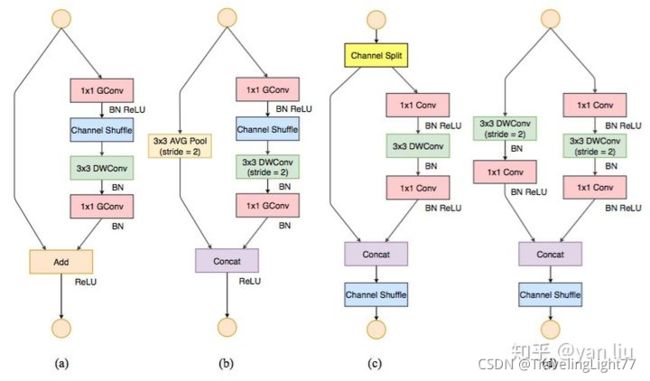
图3.(a)是一个普通的带有残差结构的深度可分离卷积,例如,MobileNet[5], Xception[6]。ShuffleNet v1的结构如图3.(b),3.©。其中3.(b)不需要降采样,3.©是需要降采样的情况。



1.3 ShuffleNet v1 网络
ShuffleNet v1完整网络的搭建可以通过堆叠ShuffleNet v1 单元的形式构成,这里不再赘述。具体细节请查看已经开源的ShuffleNet v1的源码。
2. ShuffleNet v2
2.1 模型性能的评估指标
在上面的文章中我们统一使用FLOPs作为评估一个模型的性能指标,但是在ShuffleNet v2的论文中作者指出这个指标是间接的,因为一个模型实际的运行时间除了要把计算操作算进去之外,还有例如内存读写,GPU并行性,文件IO等也应该考虑进去。最直接的方案还应该回归到最原始的策略,即直接在同一个硬件上观察每个模型的运行时间。如图4所示,在整个模型的计算周期中,FLOPs耗时仅占50%左右,如果我们能优化另外50%,我们就能够在不损失计算量的前提下进一步提高模型的效率。
在ShuffleNet v2中,作者从内存访问代价(Memory Access Cost,MAC)和GPU并行性的方向分析了网络应该怎么设计才能进一步减少运行时间,直接的提高模型的效率。
2.2 高效模型的设计准则
G1):当输入通道数和输出通道数相同时,MAC最小



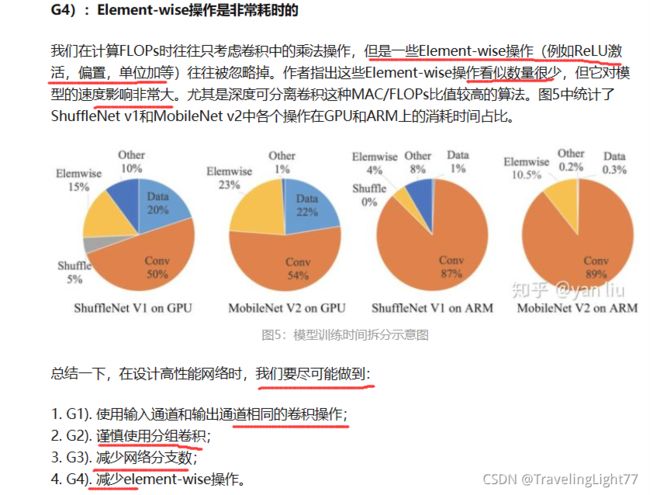
例如在ShuffleNet v1中使用的分组卷积是违背G2的,而每个ShuffleNet v1单元使用了bottleneck结构是违背G1的。MobileNet v2中的大量分支是违背G3的,在Depthwise处使用ReLU6激活是违背G4的。
从它的对比实验中我们可以看到虽然ShuffleNet v2要比和它FLOPs数量近似的的模型的速度要快。
2.3 ShuffleNet v2结构
图6中,(a),(b)是刚刚介绍的ShuffleNet v1,©,(d)是这里要介绍的ShuffleNet v2。


总结
截止本文截止,ShuffleNet算是将轻量级网络推上了新的巅峰,两个版本都有其独到的地方。
ShuffleNet v1中提出的通道洗牌(Channel Shuffle)操作非常具有创新点,其对于解决分组卷积中通道通信困难上非常简单高效。
ShuffleNet v2分析了模型性能更直接的指标:运行时间。根据对运行时间的拆分,通过数学证明或是实验证明或是理论分析等方法提出了设计高效模型的四条准则,并根据这四条准则设计了ShuffleNet v2。ShuffleNet v2中的通道分割也是创新点满满。通过仔细分析通道分割,我们发现了它和DenseNet有异曲同工之妙,在这里轻量模型和高精度模型交汇在了一起。
ShuffleNet v2的证明和实验以及最后网络结构非常精彩,整篇论文读完给人一种畅快淋漓的感觉,建议读者们读完本文后拿出论文通读一遍,你一定会收获很多。
参考:https://zhuanlan.zhihu.com/p/51566209