长URL链接转短链接算法
引言
很多大型网站都加入了短链接的功能。之所以要是使用短链接,主要是因为微博只允许发140 字,如果链接地址太长的话,那么发送的字数将大大减少。短链接的主要职责就是把原始链接很长的地址压缩成只有6 个字母的短链接地址,当我们点击这6 个字母的链接后,我们又可以跳转到原始链接地址。
开始以为短链接是按照某种算法把原始链接压缩为短链接,再根据算法从短链接反算成原始链接的。后来尝试了下压缩算法(比如gzip 压缩算法),发现对于url 这种字符串越是压缩,长度就越长。通过对压缩算法的一些了解,发现靠压缩算法来实现这个功能不太靠谱。
后来在网上找到一个生成算法,该算法主要使用MD5 算法对原始链接进行加密(这里使用的MD5 加密后的字符串长度为32 位),然后对加密后的字符串进行处理以得到短链接的地址。
原始的算法是C 版本的,这里我把该算法修改成Java 版本的. 算法的具体代码如下,代码中有注释:
代码
public class ShortUrlGenerator {
/**
* @param args
*/
public static void main(String[] args) {
// 长连接: http://tech.sina.com.cn/i/2011-03-23/11285321288.shtml
// 新浪解析后的短链接为: http://t.cn/h1jGSC
String sLongUrl = "http://tech.sina.com.cn/i/2011-03-23/11285321288.shtml" ;
// 3BD768E58042156E54626860E241E999
String[] aResult = shortUrl (sLongUrl);
// 打印出结果
for ( int i = 0; i < aResult. length ; i++) {
System. out .println( "[" + i + "]:::" + aResult[i]);
}
}
public static String[] shortUrl(String url) {
// 可以自定义生成 MD5 加密字符传前的混合 KEY
String key = "wuguowei" ;
// 要使用生成 URL 的字符
String[] chars = new String[] {
"a" , "b" , "c" , "d" , "e" , "f" , "g" , "h" ,
"i" , "j" , "k" , "l" , "m" , "n" , "o" , "p" , "q" , "r" , "s" , "t" ,
"u" , "v" , "w" , "x" , "y" , "z" , "0" , "1" , "2" , "3" , "4" , "5" ,
"6" , "7" , "8" , "9" , "A" , "B" , "C" , "D" , "E" , "F" , "G" , "H" ,
"I" , "J" , "K" , "L" , "M" , "N" , "O" , "P" , "Q" , "R" , "S" , "T" ,
"U" , "V" , "W" , "X" , "Y" , "Z"
};
// 对传入网址进行 MD5 加密
String sMD5EncryptResult = ( new MD5()).getMD5ofStr(key + url);
String hex = sMD5EncryptResult;
String[] resUrl = new String[4];
for ( int i = 0; i < 4; i++) {
// 把加密字符按照 8 位一组 16 进制与 0x3FFFFFFF 进行位与运算
String sTempSubString = hex.substring(i * 8, i * 8 + 8);
// 这里需要使用 long 型来转换,因为 Inteper .parseInt() 只能处理 31 位 , 首位为符号位 , 如果不用 long ,则会越界
long lHexLong = 0x3FFFFFFF & Long.parseLong (sTempSubString, 16);
String outChars = "" ;
for ( int j = 0; j < 6; j++) {
// 把得到的值与 0x0000003D 进行位与运算,取得字符数组 chars 索引
long index = 0x0000003D & lHexLong;
// 把取得的字符相加
outChars += chars[( int ) index];
// 每次循环按位右移 5 位
lHexLong = lHexLong >> 5;
}
// 把字符串存入对应索引的输出数组
resUrl[i] = outChars;
}
return resUrl;
}
}
输出结果
执行上面代码的结果如下,会产生4 组6 位字符串,任意一组都可以作为当前字符串的短链接地址。
[0]:::7nUFJn
[1]:::f6Zzy2
[2]:::j6jmQb
[3]:::2eAjea
跳转原理
当我们生成短链接之后,只需要在表中(数据库或者NoSql )存储原始链接与短链接的映射关系即可。当我们访问短链接时,只需要从映射关系中找到原始链接,即可跳转到原始链接。
参考
- 调用第三方接口自动转
- springboot 实现长链接转短链接转换原理: 将原url通过一系列方式,转换成6位短码(只要能不重复,随便怎么方式都行);将长短链接存入数据库,形成一条对应关系;访问短链接的时候,在数据库找到对应的长链接,并通过重定向实现原url的访问;(如果你的转换方式能过还原,也可以不要数据库,但必须保证转换后的短码不能重复)(代码部分和正文部分一样的算法)**缺点:**这个index的取值范围额只有32个,永远不可能是 2、3、6、7、10、11… 。所以自己重新写一个算法。
- 改进2的算法算法的步骤如下: 对Url进行md5编码,对md5码进行base64编码,长度为22剔除base64码中的‘+’和‘/’, 取前面的一段,如果位数不够,用base64码加上url再进行一次md5,用这个补齐,循环4直到位数满足短码的长度需求
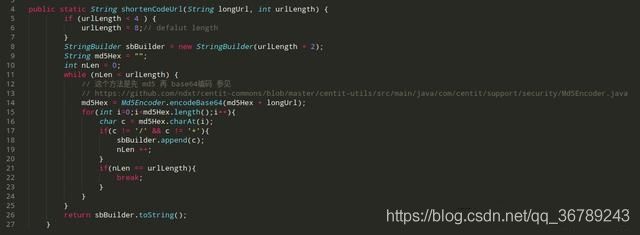
网上还有很多算法,比如:自增长算法(这个可能存在增长锁的问题),随机数算法。按理来说都是可行的,但是这些算法无法去重,就是可能会出现一个url在对应表中有多条记录。用上面基于Md5的算法,可以解决这个问题。在发现编码存在时进一步核实原始url是否一致,如果一致就不是冲突。
最烂的回答
实现一个算法,将长地址转成短地址。实现长和短一一对应。然后再实现它的逆运算,将短地址还能换算回长地址。
这个回答看起来挺完美的,然后候选人也会说现在时间比较短,如果给我时间我去找这个算法就解决问题了。但是稍微有点计算机或者信息论常识的人就能发现,这个算法就跟永动机一样,是永远不可能找到的。即使我们定义短地址是100位。那么它的变化是62的100次方。62=10数字+26大写字母+26小写字母。无论这个数多么大,他也不可能大过世界上可能存在的长地址。所以实现一一对应,本身就是不可能的。
再换一个说法来反驳,如果真有这么一个算法和逆运算,那么基本上现在的压缩软件都可以歇菜了,而世界上所有的信息,都可以压缩到100个字符。这~可能吗。
短 URL 系统是怎么设计的?
另一个很烂的回答
和上面一样,也找一个算法,把长地址转成短地址,但是不存在逆运算。我们需要把短对长的关系存到DB中,在通过短查长时,需要查DB。
怎么说呢,没有改变本质,如果真有这么一个算法,那必然是会出现碰撞的,也就是多个长地址转成了同一个短地址。因为我们无法预知会输入什么样的长地址到这个系统中,所以不可能实现这样一个绝对不碰撞的hash函数。
比较烂的回答
那我们用一个hash算法,我承认它会碰撞,碰撞后我再在后面加1,2,3不就行了。
ok,这样的话,当通过这个hash算法算出来之后,可能我们会需要做btree式的大于小于或者like查找到能知道现在应该在后面加1,2,或3,这个也可能由于输入的长地址集的不确定性。导致生成短地址时间的不确定性。同样烂的回答还有随机生成一个短地址,去查找是否用过,用过就再随机,如此往复,直到随机到一个没用过的短地址。
正确的原理
上面是几种典型的错误回答,下面咱们直接说正确的原理。
正确的原理就是通过发号策略,给每一个过来的长地址,发一个号即可,小型系统直接用mysql的自增索引就搞定了。如果是大型应用,可以考虑各种分布式key- value系统做发号器。不停的自增就行了。第一个使用这个服务的人得到的短地址是xx.xx/0 第二个是 xx.xx/1 第11个是 xx.xx/a 第依次往后,相当于实现了一个62进制的自增字段即可。
几个子问题
1. 62进制如何用数据库或者KV存储来做?
其实我们并不需要在存储中用62进制,用10进制就好了。比如第10000个长地址,我们给它的短地址对应的编号是9999,我们通过存储自增拿到9999后,再做一个10进制到62进制的转换,转成62进制数即可。这个10~62进制转换,你完全都可以自己实现。
2. 如何保证同一个长地址,每次转出来都是一样的短地址
上面的发号原理中,是不判断长地址是否已经转过的。也就是说用拿着百度首页地址来转,我给一个xx.xx/abc 过一段时间你再来转,我还会给你一个 xx.xx/xyz 。这看起来挺不好的,但是不好在哪里呢?不好在不是一一对应,而一长对多短。这与我们完美主义的基因不符合,那么除此以外还有什么不对的地方?
有人说它浪费空间,这是对的。同一个长地址,产生多条短地址记录,这明显是浪费空间的。那么我们如何避免空间浪费,有人非常迅速的回答我,建立一个长对短的KV存储即可。嗯,听起来有理,但是。。。这个KV存储本身就是浪费大量空间。所以我们是在用空间换空间,而且貌似是在用大空间换小空间。真的划算吗?这个问题要考虑一下。当然,也不是没有办法解决,我们做不到真正的一一对应,那么打个折扣是不是可以搞定?
这个问题的答案太多种,各有各招。这个方案最简单的是建立一个长对短的hashtable,这样相当于用空间来换空间,同时换取一个设计上的优雅(真正的一对一)。实际情况是有很多性价比高的打折方案可以用,这个方案设计因人而异了。那我就说一下我的方案吧。
我的方案是: 用key- value存储,保存“最近”生成的长对短的一个对应关系。注意是“最近”,也就是说,我并不保存全量的长对短的关系,而只保存最近的。比如采用一小时过期的机制来实现LRU淘汰。
这样的话,长转短的流程变成这样:
在这个“最近”表中查看一下,看长地址有没有对应的短地址,有就直接返回,并且将这个key-value对的过期时间再延长成一小时如果没有,就通过发号器生成一个短地址,并且将这个“最近”表中,过期时间为1小时所以当一个地址被频繁使用,那么它会一直在这个key-value表中,总能返回当初生成那个短地址,不会出现重复的问题。如果它使用并不频繁,那么长对短的key会过期,LRU机制自动就会淘汰掉它。当然,这不能保证100%的同一个长地址一定能转出同一个短地址,比如你拿一个生僻的url,每间隔1小时来转一次,你会得到不同的短地址。但是这真的有关系吗?
3.如何保证发号器的大并发高可用
上面设计看起来有一个单点,那就是发号器。如果做成分布式的,那么多节点要保持同步加1,多点同时写入,这个嘛,以CAP理论看,是不可能真正做到的。其实这个问题的解决非常简单,我们可以退一步考虑,我们是否可以实现两个发号器,一个发单号,一个发双号,这样就变单点为多点了?依次类推,我们可以实现1000个逻辑发号器,分别发尾号为0到999的号。每发一个号,每个发号器加1000,而不是加1。这些发号器独立工作,互不干扰即可。而且在实现上,也可以先是逻辑的,真的压力变大了,再拆分成独立的物理机器单元。1000个节点,估计对人类来说应该够用了。如果你真的还想更多,理论上也是可以的。(雪花算法的优化、美团发号算法的实现)
4.具体存储如何选择
这个问题就不展开说了,各有各道,主要考察一下对存储的理解。对缓存原理的理解,和对市面上DB、Cache系统可用性,并发能力,一致性等方面的理解。
5.跳转用301还是302
这也是一个有意思的话题。首先当然考察一个候选人对301和302的理解。浏览器缓存机制的理解。然后是考察他的业务经验。301是永久重定向,302是临时重定向。短地址一经生成就不会变化,所以用301是符合http语义的。同时对服务器压力也会有一定减少。
但是如果使用了301,我们就无法统计到短地址被点击的次数了。而这个点击次数是一个非常有意思的大数据分析数据源。能够分析出的东西非常非常多。所以选择302虽然会增加服务器压力,但是我想是一个更好的选择。