似然函数 极大似然估计 本质讲解
似然函数
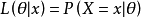
例子:
考虑投掷一枚硬币的实验。通常来说,已知投出的硬币正面朝上和反面朝上的概率各自是pH = 0.5,便可以知道投掷若干次后出现各种结果的可能性。比如说,投两次都是正面朝上的概率是0.25。用条件概率表示,就是:
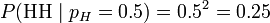
其中H表示正面朝上。
在统计学中,我们关心的是在已知一系列投掷的结果时,关于硬币投掷时正面朝上的可能性的信息。我们可以建立一个统计模型:假设硬币投出时会有pH 的概率正面朝上,而有1 − pH 的概率反面朝上。这时,条件概率可以改写成似然函数:
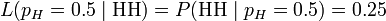
也就是说,对于取定的似然函数,在观测到两次投掷都是正面朝上时,pH = 0.5 的似然性是0.25(这并不表示当观测到两次正面朝上时pH = 0.5 的概率是0.25)。
如果考虑pH = 0.6,那么似然函数的值也会改变。
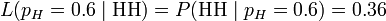
注意到似然函数的值变大了。这说明,如果参数pH 的取值变成0.6的话,结果观测到连续两次正面朝上的概率要比假设pH = 0.5时更大。也就是说,参数pH 取成0.6 要比取成0.5 更有说服力,更为“合理”。总之,似然函数的重要性不是它的具体取值,而是当参数变化时函数到底变小还是变大。对同一个似然函数,如果存在一个参数值,使得它的函数值达到最大的话,那么这个值就是最为“合理”的参数值。
给定结果,我们写出给定结果的似然函数(也就是将结果用已知的参数表示出来),我们改变要估计的参数值,然后计算似然函数的值,值大的参数我们有理由相信该参数更可信,更合理。(我们观测的结果就是这些,那么最可信的参数就是使得似然函数计算出的概率最大),这个结果发生了,什么样的参数使得这样的结果发生的概率最大。
在这个例子中,似然函数实际上等于:
-
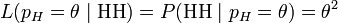 , 其中
, 其中
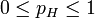 。
。
如果取pH = 1,那么似然函数达到最大值1。也就是说,当连续观测到两次正面朝上时,假设硬币投掷时正面朝上的概率为1是最合理的。
类似地,如果观测到的是三次投掷硬币,头两次正面朝上,第三次反面朝上,那么似然函数将会是:
-
 , 其中 T表示反面朝上,
。
, 其中 T表示反面朝上,
。
这时候,似然函数的最大值将会在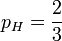 的时候取到。也就是说,当观测到三次投掷中前两次正面朝上而后一次反面朝上时,估计硬币投掷时正面朝上的概率是最合理的。
的时候取到。也就是说,当观测到三次投掷中前两次正面朝上而后一次反面朝上时,估计硬币投掷时正面朝上的概率是最合理的。
极大似然估计
贝叶斯决策
首先来看贝叶斯分类,我们都知道经典的贝叶斯公式:
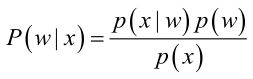
其中:p(w):为先验概率,表示每种类别分布的概率;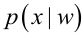 :类条件概率,表示在某种类别前提下,某事发生的概率;而
:类条件概率,表示在某种类别前提下,某事发生的概率;而 为后验概率,表示某事发生了,并且它属于某一类别的概率,有了这个后验概率,我们就可以对样本进行分类。后验概率越大,说明某事物属于这个类别的可能性越大,我们越有理由把它归到这个类别下。
为后验概率,表示某事发生了,并且它属于某一类别的概率,有了这个后验概率,我们就可以对样本进行分类。后验概率越大,说明某事物属于这个类别的可能性越大,我们越有理由把它归到这个类别下。
我们来看一个直观的例子:已知:在夏季,某公园男性穿凉鞋的概率为1/2,女性穿凉鞋的概率为2/3,并且该公园中男女比例通常为2:1,问题:若你在公园中随机遇到一个穿凉鞋的人,请问他的性别为男性或女性的概率分别为多少?
从问题看,就是上面讲的,某事发生了,它属于某一类别的概率是多少?即后验概率。
设:
由已知可得:

男性和女性穿凉鞋相互独立,所以
(若只考虑分类问题,只需要比较后验概率的大小,的取值并不重要)。
由贝叶斯公式算出:
问题引出
但是在实际问题中并不都是这样幸运的,我们能获得的数据可能只有有限数目的样本数据,而先验概率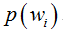 和类条件概率(各类的总体分布)
和类条件概率(各类的总体分布) 都是未知的。根据仅有的样本数据进行分类时,一种可行的办法是我们需要先对先验概率和类条件概率进行估计,然后再套用贝叶斯分类器。
都是未知的。根据仅有的样本数据进行分类时,一种可行的办法是我们需要先对先验概率和类条件概率进行估计,然后再套用贝叶斯分类器。
先验概率的估计较简单,1、每个样本所属的自然状态都是已知的(有监督学习);2、依靠经验;3、用训练样本中各类出现的频率估计。
类条件概率的估计(非常难),原因包括:概率密度函数包含了一个随机变量的全部信息;样本数据可能不多;特征向量x的维度可能很大等等。总之要直接估计类条件概率的密度函数很难。解决的办法就是,把估计完全未知的概率密度转化为估计参数。这里就将概率密度估计问题转化为参数估计问题,极大似然估计就是一种参数估计方法。当然了,概率密度函数的选取很重要,模型正确,在样本区域无穷时,我们会得到较准确的估计值,如果模型都错了,那估计半天的参数,肯定也没啥意义了。
极大似然估计
极大似然估计的原理,用一张图片来说明,如下图所示:

总结起来,最大似然估计的目的就是:利用已知的样本结果,反推最有可能(最大概率)导致这样结果的参数值。
原理:极大似然估计是建立在极大似然原理的基础上的一个统计方法,是概率论在统计学中的应用。极大似然估计提供了一种给定观察数据来评估模型参数的方法,即:“模型已定,参数未知”。通过若干次试验,观察其结果,利用试验结果得到某个参数值能够使样本出现的概率为最大,则称为极大似然估计。
由于样本集中的样本都是独立同分布,可以只考虑一类样本集D,来估计参数向量θ。记已知的样本集为:

似然函数(linkehood function):联合概率密度函数 称为相对于
称为相对于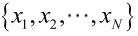 的θ的似然函数。
的θ的似然函数。

如果 是参数空间中能使似然函数
是参数空间中能使似然函数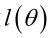 最大的θ值,则应该是“最可能”的参数值,那么就是θ的极大似然估计量。它是样本集的函数,记作:
最大的θ值,则应该是“最可能”的参数值,那么就是θ的极大似然估计量。它是样本集的函数,记作:

对数似然函数
涉及到似然函数的许多应用中,更方便的是使用似然函数的自然对数形式,即“对数似然函数”。求解一个函数的极大化往往需要求解该函数的关于未知参数的偏导数。由于对数函数是单调递增的,而且对数似然函数在极大化求解时较为方便,所以对数似然函数常用在最大似然估计及相关领域中。