论文阅读笔记SiamRPN:High Performance Visual Tracking with Siamese Region Proposal Network
SiamRPN是2018CVPR上的一篇文章,通过孪生网络+RPN的方式实现高速、精准的目标跟踪。
摘要
主要讲述目前大部分深度学习算法无法达到高速和准确同时兼顾,本文的SiamRPN利用大量训练图片实现端对端的离线训练,通过孪生网络进行特征提取,RPN网络进行分类和回归操作。在实际跟踪阶段,可以视为单样本目标检测过程(one-shot detection),VOT2015,VOT2016,VOT2017可以达到160fps的速度。
1.介绍
主要介绍目标检测的难点在于目标受光照、变形、遮挡等因素干扰,同时实时速度是考虑的重点。然后介绍了一些相关滤波算法,其优势主要体现在实时速度,因为本文主要是深度学习算法,不再赘述。
本文SiamRPN通过离线训练,分为两个分支:模版分支(template branch)和检测分支(detection branch)。个人理解是模版分支通过预训练encode目标特征,相当于模版分支的作用是,给定一张图片,我们可以获取这个图片中目标的特征信息。然后在跟踪过程中,模版分支通过输入第一帧的图像作为模版获取其特征信息,将该特征信息作为RPN网络的kernel放到检测分支中以提取对应的检测目标的位置信息。这个过程即是one-shot detection,即只用第一帧的图像作为标准,实现一段视频后续的每一帧的目标的跟踪检测。
本文指出SiamRPN能够在三个Benchmark中达到leading performace的原因有两点:1.离线训练,因此可以使用大规模的数据集(ILSVRC+Youtube-BB)2.RPN网络可以准确预测位置和边界框,避免使用多尺度检测。
随后列出三个贡献点:1.端对端离线大样本训练。2.将在线跟踪过程变为单样本检测方式,避免了多尺度检测。3.leading performance&160fps,兼顾accuracy&efficiency。
2.相关工作
2.1孪生网络结构
孪生网络用于一些相似性比较任务,最近应用于tracking领域,得益于其banlanced accuracy and speed。然后介绍了一下相关的应用该结构的模型,如GOTURN、SiamFC、CFNet等,后两者没有使用BB回归,所以需要使用多尺度检测。
2.2RPN网络
最早在Faster-RCNN中提出,然后简单提了一下别的网络中的应用,以及tracking领域应用仍比较少见。
2.3One-shot learning
也是简单介绍了一下,指出单样本学习主要用在了分类任务上,tracking领域也比较少见。
3.SiamRPN
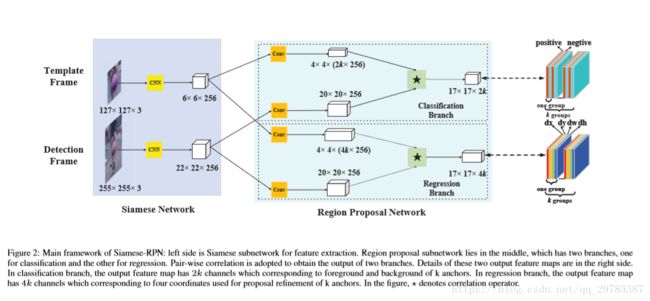
3.1Siamese feature extraction subnetwork
如图2的左侧部分,使用AlexNet,去掉了conv2和conv4以加速训练,分为两个分支,模板分支和检测分支共享CNN的参数,最后得到的输出分别记为 ϕ(z) and ϕ(x) 。
3.2 Region proposal subnetwork
如图2的中间部分,可以看到,模板分支孪生网络训练得到的ϕ(z)会分为两个部分,通过卷积分别得到4*4*(2k*256)以及4*4*(4k*256)的feature map,分别用于前景背景的判别和边界框的位置信息记录。检测分支也通过3*3卷积分为两个部分,然后把模板分支得到的feature map作为卷积核进行卷积操作,最后得到17*17*2k和17*17*4k的feature map。Loss的计算方式采用Faster R-CNN里的方式,直接上图:

3.3Training phase: End-to-end train SiameseRPN
这里提到由于视频跟踪过程中目标大小并不会有很大改变,因此只采用一种尺度的anchor,其ratio分别为[0.33,0.5,1,2,3]五种。其次IOU>0.6记为正样本,IOU<0.3记为负样本。
4.Tracking as one-shot detection
主要讲如何formulate the tracking task as a local one-shot detection task。
4.1. Formulation

即训练的目的是得到参数W,使得在追踪过程中对于单样本模板图像z(即第一帧的图像),输入一系列检测帧的图像xi ,通过一个预测函数ψ(xi;W)得到对该图像追踪情况的预测,和标签 ℓi进行比较后计算得到的损失函数Loss最小。那么在训练中则需要通过一些列模板图像zi进行训练,从而找到一个W′使得W与w(zi;W′)等价,即求训练模型参数W‘:


上图是更直观的解析。
4.2Inference phase: Perform one-shot detection
那么在得到17*17*2k和17*17*4k的feature map之后,如何计算proposals呢:

其中an代表anchor,pro代表最终回归的bounding box。
本文计算的是K个positive channel的proposal。
4.3. Proposal selection


![]()
在17*17的feature map中,每个点都有对应k个比例的proposal,本文在选择的时候,首先不考虑距离中心点超过7的网格,然后通过以上公式进行惩罚(penalty),r代表proposal的宽高比,s代表proposal的大小,'为上一帧的值,相当于做了一个尺度变化的惩罚,并结合余弦窗对proposal score进行重新排序,通过非极大值抑制(NMS)选择最优proposal。
后续略
目前这篇论文仍比较有疑惑的点有:

计算loss回归部分的时候,使用的是ground truth 和anchor box进行正则后计算的,而Faster R-CNN中是使用三组数值,也就是ground truth 、 anchor box以及预测的proposal进行正则之后放入L1函数进行计算的,如上图。前者算法ground truth 和anchor box两组值根本不会改变,放入loss中貌似没有什么意义。。

上图是Faster R-CNN的Loss计算公式,本文中Loss算法没有加入Pi*只对包含目标的样本进行训练,所以所有bounding box都会进行回归训练么?