CVPR-2018-SiamRPN:High Performance Visual Tracking with Siamese Region Proposal Network阅读笔记
论文地址:https://link.csdn.net/?target=http%3A%2F%2Fopenaccess.thecvf.com%2Fcontent_cvpr_2018%2Fpapers%2FLi_High_Performance_Visual_CVPR_2018_paper.pdf
论文代码:https://github.com/makalo/Siamese-RPN-tensorflow
https://github.com/songdejia/Siamese-RPN-pytorch
一、 动机
摒弃传统的多尺度测试和在线微调,引入RPN,在实时速度下获得最佳性能。
二、 主要贡献
① 我们提出了Siamese区域提议网络(SiameseRPN),该网络采用大规模图像对进行端到端离线训练来完成跟踪任务。
② 在在线跟踪过程中,提出的框架被制定为一个局部一次性检测任务,可以细化建议,摒弃昂贵的多尺度测试。
③ 在VOT2015、VOT2016、VOT2017实时挑战中表现领先,速度为160帧/秒,在精度和效率上均具有优势。
三、 主要内容
网络架构:

1) Siamese Network
在Siamese网络中,采用了一个没有填充的全卷积网络。设lτ表示平移算子(Lτx)[u] = x[u−τ],则去掉所有填充以满足步长 k的完全卷积的定义:

这里使用了改良的AlexNet,其中conv2和conv4中的组被移除。
2) Region Proposal Network
区域建议子网络由一对相关段和监督段组成。监督部分有两个分支,一个是前景-背景分类,一个是回归。
在分类分支和回归分支上计算相关性:




在分类任务中使用交叉损失,在回归任务中使用归一化坐标下平滑损失。设Ax, Ay, Aw, Ah为锚箱中心点和形状,设Tx, Ty, Tw, Th为地面真值中心点和形状,则归一化距离为:

然后经过平滑损失L1,可以被写成如下形式:

最后对损失函数进行了优化:

其中,

3) Training phase: End-to-end train Siamese-RPN
采用的anchor ratio为[0.33,0.5,1,2,3]。
训练对中一共有64个样本,限制正样本最多有16个。
正样本:IoU > thhi thhi= 0.6
负样本:IoU < thlo thlo =0.3
四、 跟踪作为一次性检测
将跟踪任务指定为局部的一次性检测任务,并使用一些策略使检测框架适用于跟踪任务。(RPN本来就是用于目标检测的)。
1、 公式化
一次性检测的目标是找到使预测函数平均损失最小的参数w:

一次性学习是指从感兴趣的类的单个模板z中学习W。区别性一次性学习的挑战在于找到一种将类别信息纳入学习者的机制,即学习学习。为了解决这一挑战,提出了一种通过元学习过程从单个模板zi学习预测器参数W的方法,即映射(z;W’)到W的前馈函数ω。

z表示模板patch, x表示检测patch,函数ϕ表示特征提取孪生子网,函数ζ表示区域提议子网络,那么一次性检测任务可以表述为:

2、 推理阶段:一次性检测

在推理阶段,孪生框架被修剪。只留下除了初始帧之外的检测分支,从而导致高速。

3、 建议选择策略
在生成前K个建议后,使用一些建议选择策略使它们适合于跟踪任务。在这里一共提出了两种方案。
**第一种:**丢弃离中心太远的锚点生成的边界框。

如:在Aclsw×h×2k特征图上保留中心gg子区域,由此可得到ggk个锚,而不是mn*k。采用此方法的原因是,邻近帧总是没有大的运动,所以丢弃策略可以有效的去除异常值。
**第二种:**利用余弦窗口和比例变化惩罚对方案的评分进行重新排序,得到最佳的方案。丢弃离群值后,添加余弦窗来抑制大位移,然后添加惩罚来抑制尺寸和比例的大变化:

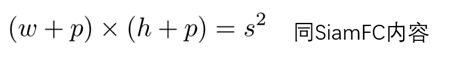
K是参数,r是建议的高宽比,r’是最后一帧的高宽比,s是建议总体比例尺,s’是最后一帧的总体比例尺。
在这些操作之后,将分类分数乘以时间惩罚后,对前K个建议重新排序。然后执行非最大抑制(NMS),得到最终的跟踪包围框。选定最终的边界框后,通过线性插值更新目标尺寸,以保持形状的平滑变化。
五、 对性能至关重要的几个因素
1. 数据大小
视频稀疏标记:
该跟踪框架只需要图像对,而不需要连续的视频流。所以可以从大规模的稀疏标记视频中获益。Youtube-BB包含超过10万个视频,每30帧注释一次。且实验表明添加来自Youttube-bb的数据可以逐步提高性能。性能不是饱和的,这意味着随着训练数据的增加,跟踪器的性能可能会变得更好。因此可以通过逐步添加更多来自Youtube-BB的数据来训练不同数据集大小的Siamese-RPN。
2. 锚大小
比率:尝试了三种
A3:[0.5,1,2]
A5:[0.33,0.5,1,2,3]
A7:[0.25,0.33,0.5,1,2,3,4]

实验结果表明,A5的追踪器表现最好,虽然A7跟踪器可以通过添加更多的训练数据来减少差距,但其性能并没有持续提高,这可以是过拟合造成的。所以最终选择A5作为最终锚框比率。
锚点中心大小:

上图表明了中心大小对不同数据集的影响。实验表明,当添加Youtube-BB数据集时,设置的中心尺寸越大,我们得到的EAO越好。当仅使用VID数据集时,锚点的最佳中心大小为4,说明区域建议子网络的判别能力不足以使用大的搜索区域。
3. 锚位置
实验表明,当使用Youtube-BB对网络进行训练时,随着中心尺寸的增大,性能也随之提高。但是,如果只使用ILSVRC训练,RPN的性能并没有像预期的那样提高,这意味着RPN的判别能力不足以使用大的搜索区域。
六、 实验结果







【补充】
目标检测与目标跟踪的异同:
目标检测实现已知类别的定位识别,而目标跟踪可以根据运动特征来进行跟踪,无需知道跟踪的是什么。如果对每帧画面进行目标检测可以实现目标追踪,但计算十分昂费耗时。