【机器学习】特征工程中常见的特征编码
类别特征(Categorical Features)编码方式
One Hot Encoding(独热编码)
独热编码,又称为一位有效编码。其方法是使用N位状态寄存器来对N个状态进行编码,每个状态都由他独立的寄存器位,并且在任意时候,其中只有一位有效。可以这样理解,对于每一个特征,如果它有m个可能值,那么经过独热编码后,就变成了m个二元特征。并且,这些特征互斥,每次只有一个激活。
如果数据是离散的,而且是无序的,则可以考虑独热编码。接下来请看下面的数据
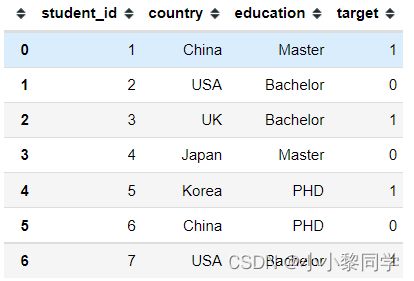
country和education都是类别型的字段,是发散同时无序的。可以使用pandas中的get_dummies或者sklearn中的进行编码。
import pandas as pd
#生成数据
df = pd.DataFrame({
'student_id': [1,2,3,4,5,6,7],
'country': ['China', 'USA', 'UK', 'Japan', 'Korea', 'China', 'USA'],
'education': ['Master', 'Bachelor', 'Bachelor', 'Master', 'PHD', 'PHD', 'Bachelor'],
'target': [1, 0, 1, 0, 1, 0, 1]
})
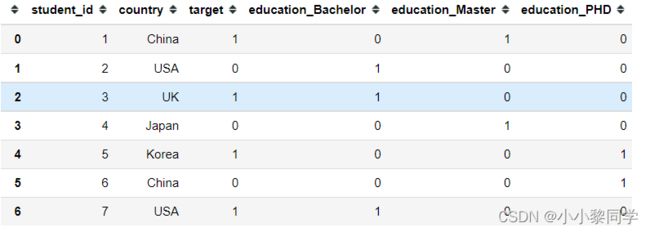
pd.get_dummies(df, columns=['education'])
运行结果:
from sklearn.preprocessing import OneHotEncoder
OneHotEncoder().fit_transform(df[['education']]).toarray()
运行结果:

独热编码优缺点
- 优点:独热编码解决了分类器不好处理属性数据的问题,在一定程度上也起到了扩充特征的作用。它的值只有0和1,不同的类型存储在垂直的空间。
- 缺点:当类别的数量很多时,特征空间会变得非常大。在这种情况下,一般可以用PCA(主成分分析)来减少维度。而且One-Hot Encoding+PCA这种组合在实际中也非常有用。
Label Encoding(标签编码)
Label Encoding是使用字典的方式,将每个类别标签与不断增加的整数相关联,即生成一个名为class_的实例数组的索引。
Scikit-learn中的LabelEncoder是用来对分类型特征值进行编码,即对不连续的数值或文本进行编码。
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
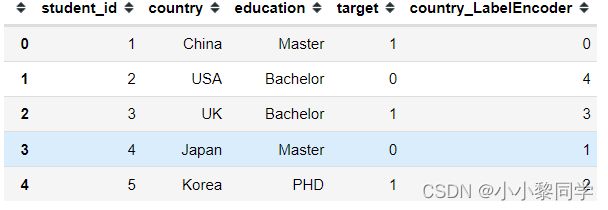
df['country_LabelEncoder'] = le.fit_transform(df['country'])
df.head()
也可以使用pandas进行转换
df['country_LabelEncoder'] = pd.factorize(df['country'])[0]
df.head()
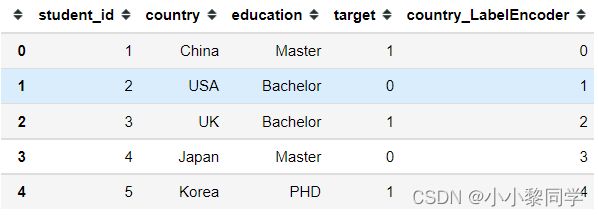
需要注意的是factorize返回的是元组,第一个元素是一个array,其中的元素是标称型元素映射为的数字;第二个元素是Index类型,其中的元素是所有标称型元素,没有重复。

Label Encoding只是将文本转化为数值,并没有解决文本特征的问题:所有的标签都变成了数字,算法模型直接将根据其距离来考虑相似的数字,而不考虑标签的具体含义。使用该方法处理后的数据适合支持类别性质的算法模型,如LightGBM、CatBoost。
Ordinal Encoding(序列编码)
Ordinal Encoding即最为简单的一种思路,对于一个具有m个category的Feature,然后手动自定义字典映射到 [0,m-1] 的整数。当然 Ordinal Encoding 更适用于 Ordinal Feature,即各个特征有内在的顺序。例如对于”学历”这样的类别,”学士”、”硕士”、”博士” 可以很自然地编码成 [0,2],因为它们内在就含有这样的逻辑顺序。但如果对于“颜色”这样的类别,“蓝色”、“绿色”、“红色”分别编码成[0,2]是不合理的,因为我们并没有理由认为“蓝色”和“绿色”的差距比“蓝色”和“红色”的差距对于特征的影响是不同的。
df['education'] = df['education'].map(
{'Bachelor': 1,
'Master': 2,
'PHD': 3})
df.head()
运行结果:

**优点:**简单,没有增加维度。
**缺点:**需要人工知识,对未出现的数值不太友好。
Frequency Encoding/Count Encoding(频数编码)
将类别特征替换为训练集中的计数(一般是根据训练集来进行计数,属于统计编码的一种,统计编码,就是用类别的统计特征来代替原始类别,比如类别A在训练集中出现了100次则编码为100)。这个方法对离群值很敏感,所以结果可以归一化或者转换一下(例如使用对数变换)。未知类别可以替换为1。如果训练集和测试集上某字段分布不一样,那么使用频数编码预测结果可能不太好。
频数编码使用频次替换类别。有些变量的频次可能是一样的,这将导致碰撞。尽管可能性不是非常大,没法说这是否会导致模型退化,不过原则上我们不希望出现这种情况。
df['country_count'] = df['country'].map(df['country'].value_counts())
df.head()

Mean Encoding (均值编码)
如果某一个特征是定性的(categorical),而这个特征的可能值非常多(高基数),那么目标编码(Mean Encoding)是一种高效的编码方式。在实际应用中,这类特征工程能极大提升模型的性能。
定性特征的基数(cardinality)指的是这个定性特征所有可能的不同值的数量。在高基数(high cardinality)的定性特征面前,这些数据预处理的方法往往得不到令人满意的结果。
高基数定性特征的例子: IP地址、电子邮件域名、城市名、家庭住址、街道、产品号码。
df['country_target'] = df['country'].map(df.groupby(['country'])['target'].mean())
df.head()
运行结果:

China出现了两次,其target为1和0,取均值后编码为0.5。在这里不难发现,对于基数比较低的,很容易泄露标签,比UK只出现了一次,其编码与标签相同,容易发送过拟合。
数值特征编码方式
取整和缩放
对于含有小数的数值型特征,比如年龄、成绩等,其小数部分的信息可能对标签影响不大,可以对其进行取整,也可以保留其大部分的信息,缩放亦如此。
df = pd.DataFrame({
'age': [34.5, 28.9, 19.5, 23.6, 19.8, 29.8, 31.7],
'target': [1, 0, 1, 0, 1, 0, 1]
})
df['age_round1'] = df['age'].round()
df['age_round2'] = (df['age'] / 10).astype(int)
df
运行结果:

分箱
对数值型进行分箱,可以把连续型数据转换为离散型
df['age_<20'] = (df['age'] <= 20).astype(int)
df['age_20-25'] = ((df['age'] > 20) & (df['age'] <=25)).astype(int)
df['age_25-30'] = ((df['age'] > 25) & (df['age'] <= 30)).astype(int)
df['age_>30'] = (df['age'] > 30).astype(int)
df
