Sequence to Sequence 经典必读两篇论文
Sequence to Sequence Learning with Neural Networks 论文
Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation
论文
第一篇是Quoc V. Le 大神的2014年经典文章,引用量14161,只要涉及序列2序列,肯定要引用这篇文章,应用包括不限于语言翻译,音频识别,字符识别,序列识别等
我分别概括下两篇开山论文的梗概
Sequence to Sequence Learning with Neural Networks
Introduction
在这篇论文中,我们提出了一种通用的端到端序列学习方法,它对序列结构做出了最小化的假设。
我们的方法使用了一个多层的长短期记忆网络(LSTM)将输入序列映射成一个固定维度的向量,然后再用另外一个深层LSTM将这个向量解码成目标序列。
LSTM还学习到了对单词顺序较为敏感,学习到了对积极和消极语言相对不变的合理的短语和句子。
最终,我们发现通过颠倒原句子中的单词顺序能够显著提升LSTM的性能,因为这样做会在源语句和目标句子之间引入许多短期依赖关系,这使得优化问题更容易。
尽管DNN具有灵活性和强大的功能,但它只能应用于输入和目标可以使用固定维数向量进行合理编码的问题。
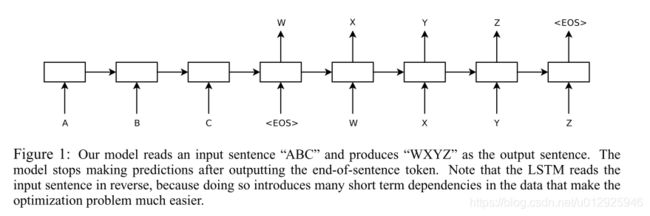
其思想是,通过使用一个LSTM来读取输入序列,为了获得最大固定维度的向量表示(即最终的隐藏态),每一时刻读取一次,然后使用另外一个LSTM从该向量中提取出输出序列(如图1)。
related work:
G提出使用注意力机制专注于输入的不同区域(用于机器翻译)
我们构造了5层LSTM的decoder,模型参数384M,8,000 dimensional state each 隐藏态,使用beam search的机器翻译模型
SGD可以学习长句子无误的LSTMs
翻转源句中单词的简单技巧是这项工作的关键技术贡献之一。
model
LSTM一个非常有用的属性是它能够将一个可变长度的输入句子映射成一个固定维度的向量表示。
(没有CTC的话)尚不清楚如何将RNN应用于其输入和输出序列具有不同长度且具有复杂和非单调关系的问题。
根据输入长度T,估计输出长度T’
首先,根据输入长度T,得到最后一个隐藏态的具有固定维度的向量v
然后,以v作为一个LSTM初始状态,开始计算每个T’的概率

在这个等式中,每一个概率分布p ( y t ∣ v , y 1 , . . . , y t − 1 ) 由所有词汇的softmax表示。需要注意的是我们要求每一个句子的末尾都使用一个特殊的句子结束符 E O S ,这能够使模型去定义一个所有可能长度的句子的分布
我们的三个创新点
1 两个不同的LSTM分别输入和输出,(可以在多个语言对上训练)
2 深层LSTM明显优于浅层,因而使用4个LSTM
3我们发现颠倒输入句子的单词顺序是非常有价值的。例如,并不将句子a,b,c映射成α , β , γ ,而是将c , b , a 映射成α , β , γ 。这样,a 非常靠近α ,b 非常接近β
,依此类推,这使得SGD很容易在输入和输出之间“建立通信”。 我们发现这种简单的数据转换可以大大提高LSTM的性能。
翻转源语句,准确率可以增加5个点
即便在长语句预测,翻转后仍然效果更好
训练细节:
SGD,无动量,lr=0.7,每半个epoch降低一半
一共7.5epoch
LSTM可能有梯度爆炸,我们接了硬约束
不同句子长度差别很大,20的又100的,batch里很大浪费,我们把相近大小的组成batch,速度快了2倍(也不知道是训练速度还是inference,大概是训练把)
翻译质量评估:
24论文中的BLEU评分

5层LSTM吧准确率从22提升至33
12层beam search比1层beam提高1个点
Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation
提出了一种类似于 LSTM 的 GRU 结构,并且具有比 LSTM 更少的参数,更不容易过拟合。
能够在一定程度上学习到短语的语义和语法表示
将Encoder和Decoder联合训练
训练好的模型不仅可以给定输入序列生成对应序列,还可以对给定的输入输出序列打分,分
1 根据上一隐状态和当前输入生成该时刻t的重置门 r (reset gate)和更新门 z (update gate)
2 然后计算当前时刻的隐状态的对应分量:
直观上看,重置门决定选择性地保留来自上一时刻的信息,然后与当前输入的信息混在一起,形成“短期记忆”,更新门控制来自上一时刻的状态和当前状态的信息流,形成“长期记忆”,这类似于LSTM中的记忆细胞。
总结起来,就是当重置门接近1时,GRU记忆更多的短期信息;当更新门接近1时,GRU记忆更多的长期信息。
传统统计机器翻译模型:
Statistical Machine Translation(SMT)

e是输入,f是翻译输出
传统模型最大化P(f|e) , 按照统计模型求f