亚马逊云科技 2022 re:Invent 观察 | 天下武功,唯快不破

引子
“天下武功,无坚不摧,唯快不破”,相信大家对星爷电影《功夫》中的这句话耳熟能详。实际上,“天下武功,唯快不破”最早出自古龙先生的著名武侠小说《小李飞刀》:“小李飞刀,例无虚发,只出一刀,无人能挡,只因天下武功无坚不摧,唯快不破。”
其意思是说,天下的众多武功里,只有“快”找不到克制它的方法。当武功的速度达到极致的时候,有时候不需要复杂招式,只是简单的一招就可以克敌。

2022年11月28日,一年一度的亚马逊云科技 re:Invent 2022 大会在美国内华达州拉斯维加斯拉开帷幕。据悉,本次大会吸引了约50000人现场参加,而线上参加的人数超过300000 人。这场为期五天的云计算盛会又给大家带来了很多新的惊喜。

在笔者看来,本次峰会有三大焦点主题,分别是 数据、性能和安全。Amazon CEO Adam Selipsky 的 Keynote 至少一半时间都在谈数据,包括数据的产生、数据的处理、数据的分析、数据的保护、数据的应用等。还有 VP Swami Sivasubramanian 的 Keynote,几乎整个都在谈数据。而VP Peter DeSantis 的 Keynote 则大部分时间在谈性能,包括更快的网络访问速度、更高的磁盘访问速度、更快的芯片运转速度、更快的函数启动速度等等。实际上纵观峰会,还有快速的产品发布速度、更快的数据流动速度、更快的创新速度等。
所有这些“快”,就像火箭高速发动机,将亚马逊云科技推向了一个全新高度。如同“天下武功,唯快不破”中的“快”,“速度”也已成为亚马逊云科技手中的一把最快的刀,披荆斩棘,势不可挡,奔向远方。下文,将选取本次峰会上众多发布之中笔者认为非常具有代表性的五个底层性能创新,来一一为您讲述亚马逊云科技是如何将“快”做到极致的。
1. Lambda函数冷启动时间降低90%
2015年,亚马逊云科技正式发布 Amazon Lambda,开创了无服务器计算时代。过去8年间,Lambda的功能一直在丰富和完善中。
Lambda 具有独到的优势。在开发方面,它采用简单的编程模型,可方便地调用其它亚马逊云科技服务;在运维方面,Lambda 函数能快速响应不断变化的使用模式。因此,越来越多的用户喜欢它、使用它。在本次峰会上,亚马逊云科技宣布,每个月有100万客户使用 Lambda,每个月 Lambda 函数的调用量超过100亿次。

但是,过去,Lambda 函数冷启动时间过长的问题一直在困扰着用户们。要理解这个问题的根因,需首先简单了解下其实现原理。
Lambda 函数运行在微虚机 (MicroVM) 中。关于 Firecracker,多年前笔者曾经写过一篇介绍性文章,容器在公有云上的落地姿势,您可以参考,请注意文中有些信息可能已经有些过时了。

亚马逊云科技划分了一个池子,专门用于运行 Lambda 函数的微虚机。当用户部署函数时,函数代码要么被上传到 S3 中,要么将函数镜像上传到 Amazon Elastic Container Registry(ECR)中。
当函数第一次被调用时,Lambda 从 S3 或 ECR 中拉取代码,然后拉起一个 Firecracker 微虚机,并进行运行时和函数代码初始化。接着,代码被执行,并返回函数的输出。
接下来,Lambda 将使这个微虚机保持运行一段时间,因此后续请求都将由这个正在运行的容器来处理和执行。一段时间内没有函数调用的话,亚马逊云科技将关闭此容器。当一个新事件出现时,Lambda 会启动一个新微虚机—这过程包括亚马逊云科技为启动“微虚机”所做的一切,以及初始化你的代码。
这就是亚马逊云科技启停其 Lambda 函数的基本方式。这种方法可提高亚马逊云科技的基础设施的效率,大大降低客户的运行成本。
每个 Lambda 函数的生命周期包括三个过程:初始化(init)、调用(invoke)和关闭(shutdown)。所谓初始化过程,指的是第一次调用函数时所需要的执行和响应时间,包括下载代码、拉起微虚机、运行时初始化和函数初始化等环节所花的时间。后续调用过程则会比第一次初始化快得多,因为只包括函数执行环节。我们将函数的初始化过程称为“冷启动”。任何后续请求都将由正在运行的容器中已经包装好的函数处理,每次函数调用只需要一次所谓的“热启动”。
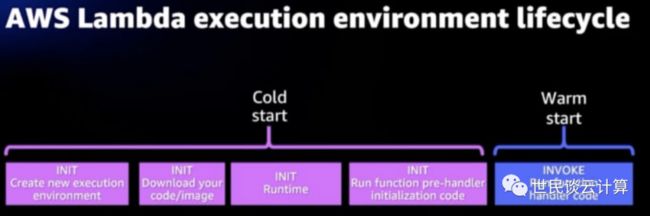
根据对生产 Lambda 工作负载的分析,冷启动通常发生在不到1%的调用中。冷启动的持续时间从不到100 毫秒到超过1秒不等。其中,Java 语言编写的 Lambda 函数的冷启动时间最长,主要因为三个因素:一是 JVM 的启动时间,二是 Java 类的解压时间,三是 Java 类的初始化代码的执行时间。
Lambda 函数冷启动时间过长会带来一系列问题,这也让 Lambda 函数启动性能优化成为近几年最热门的优化领域之一。特别是其最长的1秒时间,决定了 Lambda 函数可能很难用于对延时非常敏感的联机交易,这会大大压缩了 Lambda 的使用场景。为了克服这个问题,用户们甚至发明了非常规手段,比如每隔15分钟 ping 一次自己的函数,以确保它是活着的。

幸运的是,本次峰会上,亚马逊云科技宣布了 Lambda SnapStart 新特性。为 Java 函数启用 Lambda SnapStart,可以使其冷启动速度提高10倍。这是一次数量级级别的性能提升。

我们来看看该特性的实现原理。它利用了 Firecracker 的 MicroVM Snapshot 功能。在函数冷启动或函数更新阶段或新版本创建时,函数会被启动运行并完成初始化,Lambda 然后会为函数的内存和磁盘状态创建一个快照(Snapshot)并缓存下来。在冷启动过程中,通过恢复(Resume)快照,就可以让函数很快就绪。
只要快照存在,当函数被调用时,只需要恢复快照就可以了。而恢复快照比创建和初始化新的 Lambda 执行环境要快10倍,这就是为什么该特性虽小但效果这么明显的原因。
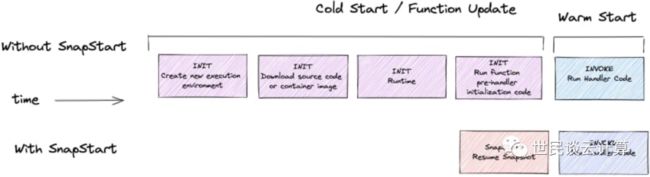
此优化使 Lambda 函数的调用时间更快且更可预测。实际上,该技术的背后还有三个创新点。一是采用一致性的快照技术,二是提升了快照处理的效率,三是预测性快照加载。这三大创新合并在一起,才带来数量级的性能提升。

本次峰会上,亚马逊云科技推出了对使用 Amazon 自己的 JDK 发行版 Corretto (java11) 运行时的 Lambda Java 函数的支持,其他 Java 框架的支持应该很快就会推出。
实际上,我们回头看的话,这功能实在太重要了,其实应该更早些推出才对,甚至在2014年宣布的时候就应该具备。
这个看起来小小的特性,也许能为 Lambda 巨大的改变,因为用户们太需要它了。他们在欢呼:“This is a great and long awaited change!”“Honestly, this is how Lambda should be, by default.”“其它 Java 版本、python 和 node.js 什么时候开始支持呢?”
亚马逊云科技的合作伙伴 Micronaut 迫不及待地使用“Hello World”Java 程序做了对比测试。很显然,程序的启动速度得到了大幅提升。
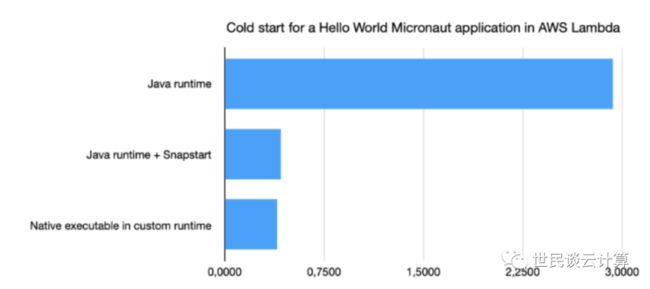
在该功能所声称的性能提升得到充分的证实并在持续优化后,笔者甚至相信它将改变 Lambda 的扩展性在无服务器领域和整个行业中的认知,并将使得 Lambda 函数作为联机函数变成可能。甚至 Serverless 时代的真正到来会因此而大大加快!
2. 数据库TPS性能提升30%
现在亚马逊云科技谈性能,已经无法不谈 Nitro 了。Peter DeSantis 在其 Keynote 中一上来就说,自2014年以来推出的每一个的 Amazon EC2 实例都在利用 Amazon Nitro 这项技术,它对亚马逊云科技产品和服务性能的提升居功至伟。
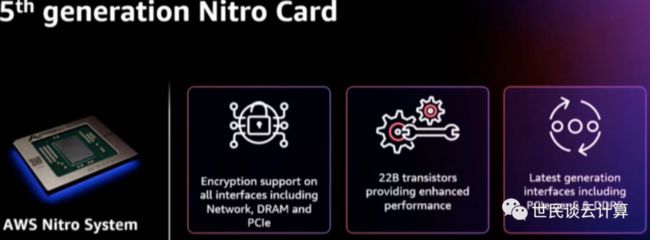
本次峰会上发布的最新版本 Amazon Nitro v5,相比前一代 v4,它具有两倍的计算能力、多出50%的内存带宽和两倍带宽的外围组件互连高速 (PCIe) 适配器,支持每秒60%的数据包 (PPS) 速率增加,数据包延迟减少30%,每瓦性能提高40%。
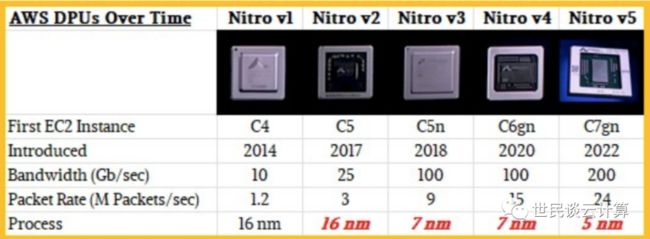
在2021年 re:Invent 峰会上,亚马逊云科技发布了 Nitro SSD。

这款亚马逊云科技自研的 SSD,具有更低延迟、更加可靠、数据自动加密等特点,它不仅帮助亚马逊云科技实现了对 SSD SLA 的控制而且还大大降低了成本了。

Nitro SSD 还有更多的价值。在2022年的 re:Invent 峰会上,亚马逊云科技宣布基于Nitro SSD,亚马逊云科技实现了 TWP(Torn Write Prevention,撕裂写预防)功能,使得数据库的 TPS 性能提升了至少30%。
数据库是网站、APP 等产品重要的底层核心支撑服务,其性能的重要性不言而喻。而 TPS(Transactions per Second,每秒事务数)是数据库最核心的性能指标之一,TWP 使得 IO 密集型的应用能从 MySQL 或 MariaDB 上获得更高的性能和更低的时延。

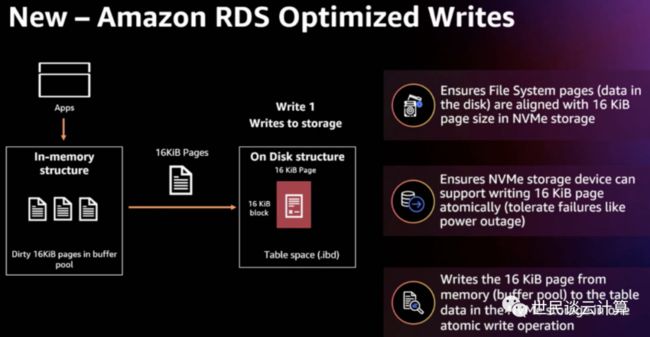
简单介绍下 TWP 产生的背景。通常数据库场景下,数据写入页大小(page size)是16KiB,而目前文件系统中常用的页大小都是4KiB。因此,数据库要将一个16KiB的数据写入磁盘,那在操作系统级别上需要写4个4KiB大小的数据块。在极端情况下(比如系统断电或操作系统宕机)可能无法保证这一操作的原子性,比如可能在写入4KiB 时发生了断电,此时只有一部分写是成功的,这样就产生了数据一致性问题。
为了解决这个问题,数据库实现上通常都会采用“双写缓冲区(Double Write Buffer,以下简称 DWB)”的机制。如下图所示,当 MySQL 要写入16KiB数据的时候,数据首先被写入 DWB 缓冲区,然后分4次写入表空间。

显然,这种设计虽然保证了16KiB数据的写入可靠性和原子性,但是却带来了直接的性能损失和间接的成本增加。

得益于 Nitro SSD 对16KiB原子写的支持,TWP 技术使得亚马逊云科技数据库服务不再需要DWB缓存冲了,而只需要将文件系统的页大小直接修改为16KiB即可,数据库应用就可以原子性地一次性写入16KiB的数据。TWP 可以确保数据库应用的16KiB数据在写入事务期间发生操作系统崩溃或断电时不会被撕毁。
使用 TWP 技术,在 EC2、EBS 和托管服务(如 Amazon RDS)上运行 MySQL 或 MariaDB 等关系数据库的客户可以关闭双写操作,从而在不影响工作负载弹性的情况下将数据库性能每秒事务数 (TPS) 加快多达30%。
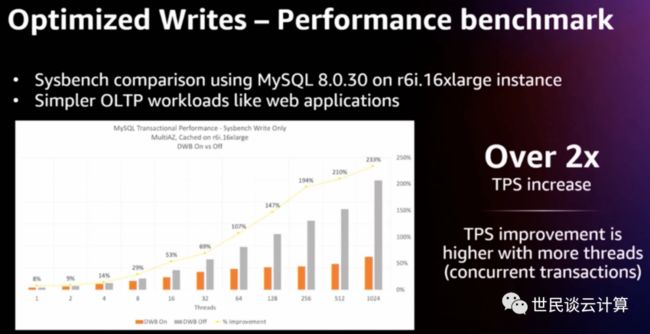
下图是在 Amazon r6i.16xlarge EC2 实例上运行 MySQL 8.0 并使用简单 OLTP 负载的对比测试结果。在关闭 DWB 的情况下,其 TPS 在512个并发线程数时提升了2倍,而且随着线程数越多,提升效果越大。
数据库服务是云上最基础的服务之一。TWP 这特性看起来也许不大起眼,但是却能带来如此高的性能提升,这让我们又一次见证了硬件创新的威力。
3. ENA网卡性能跃升5倍
在看具体内容之前,我们来看看过去16年中 Amazon EC2 实例的网络带宽的提升曲线。这图非常直观、非常漂亮、非常震撼人心。re:Invent 材料的视觉效果越来越好了。
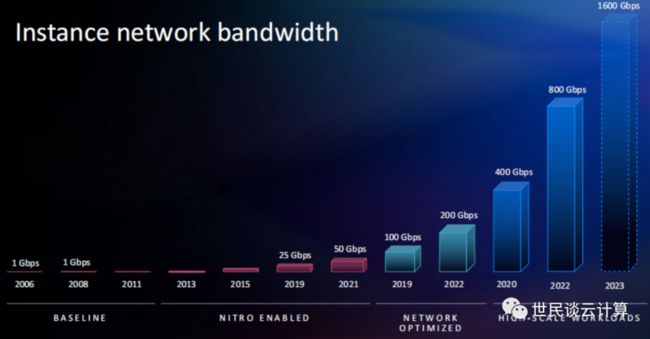
亚马逊云科技网络支持三种网卡,分别是 ENI、ENA 和 EFA。
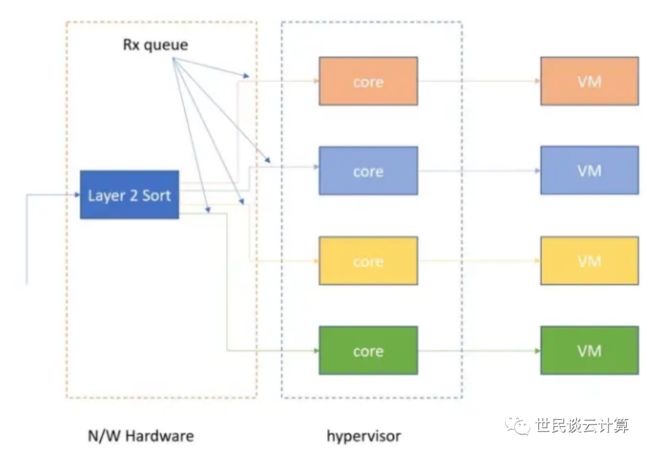
ENI:Elastic Network Interface,弹性网络接口。ENI 是一种逻辑网络设备,代表虚拟网卡,依赖 Hypervisor 通过网络虚拟化功能实现。
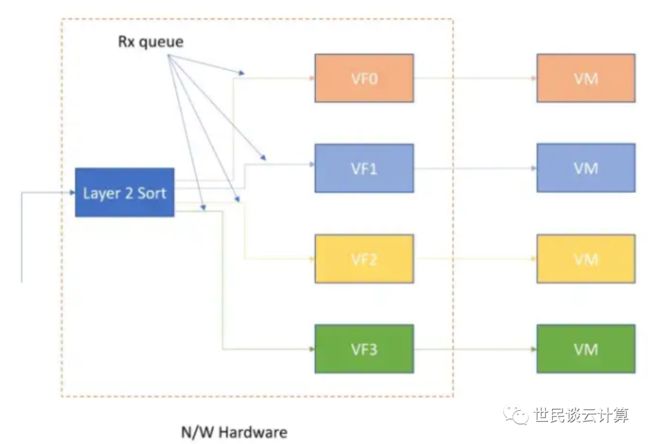
ENA:Elastic Network Adaptor,弹性网络适配器,是一种通过 SR-IOV(Single Root I/O Virtualizatio,单根 I/O 虚拟化)虚拟化技术实现的硬件网络设备。这是一种经过优化了的网络接口,能提供更高吞吐量和更好的每秒数据包 (PPS) 性能。
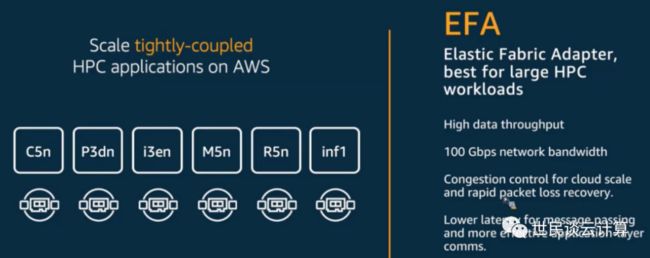
EFA:Elastic Fabric Adapter,使用定制的操作系统旁路技术来增强实例间通信的性能。一开始 EFA 用在高性能计算场景中,使得客户能够在亚马逊云科技上大规模运行需要高级别实例间通信的 HPC 应用程序,例如计算流体动力学、天气建模和油藏模拟。
三种网卡的特性对比:

需要注意的是,EFA 因为采用了 SRD 协议,其最大单流带宽被提高到100Gbps。但 EFA 和 ENA 有些不一样,它没有采用标准 TCP/IP 协议栈,只能面向高性能计算场景。因此,很多用户早就在期盼着,若能将 SRD 用在 ENA 上,则能惠及更多用户的更多场景。
2022年的 re:Invent 峰会上,亚马逊云科技首次将 SRD 应用到 ENA 上,新推出了 ENA Express。它具有三个特点:
简单:在网卡上通过简单配置或一次 API 调用来启用 SRD 即可;
透明:应用还是使用 TCP/UDP 协议,ENA Express 自动检测通信双方 EC2 实例之间的兼容性,并在两通信实例均启用 ENA Express 后建立 SRD 连接;
高效:能大幅提高 EC2 实例之间的单流带宽和降低网络流量尾部延迟。

SRD 将使用 ENA 的 EC2 实例的最大单流带宽从5 Gbps增加到25 Gbps,足足提升了5倍。而且,它最多可将P99的延迟降低50%、将 P99.9 延迟降低85%。

那到底 SRD 有什么魔力能如此大幅提高网络传输性能呢?我们来看看 SRD 是什么、从何而来,又要到哪里去。
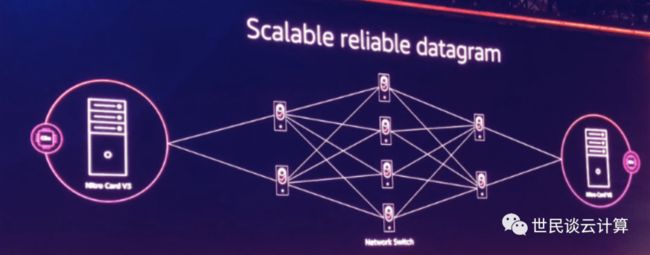
2020年,亚马逊云科技发表了一篇论文《A Cloud-Optimized Transport Protocol for Elastic and Scalable HPC》,对 SRD 进行了详细阐述(论文地址:https://assets.amazon.science/a6/34/41496f64421faafa1cbe301c007c/a-cloud-optimized-transport-protocol-for-elastic-and-scalable-hpc.pdf
在论文摘要中作者写道:
“亚马逊云科技重新审视了现有网络协议,以提供超级计算应用程序(supercomputing application)所需的持续低延迟,同时保持公共云的优势:可扩展性、按需获取弹性容量、性价比以及快速采用更新的 CPU 和 GPU。
我们创造了一种新网络传输协议 - 可扩展的可靠数据报 (SRD),旨在充分利用现代商业多租户数据中心网络的优势(具有大量网络路径),同时克服它们的局限性(负载不平衡和不相关流冲突时导致的延迟抖动)。
SRD 不保留数据包顺序,而是通过尽可能多的网络路径发送数据包,同时避免过载路径。为了最大限度地减少抖动并确保对网络拥塞波动做出最快的响应,SRD 在亚马逊云科技定制的Nitro 网卡中实现。
SRD 由 EC2 主机上的 HPC/ML 框架通过亚马逊云科技弹性结构适配器(EFA)内核旁路接口(kernel-bypass interface)使用。”
关于SRD的详情,可阅读该论文,本文不再赘述。简单总结,SRD 是一种基于以太网的传输协议,设计初衷是面向超算场景,要结合 EFA 才能使用。其主要特点包括:
乱序交付:SRD 放宽了对按顺序传递数据包的要求,亚马逊云科技在 EFA 用户空间软件堆栈中实现了数据包重排序处理引擎。
等价多路径路由(ECMP):两个 EFA 实例之间可能有数百条路径,使用大型多路径网络的一致性流哈希的属性,以及 SRD 对网络状况的快速反应能力,找到消息的最有效路径。
快速的丢包响应:SRD 对丢包的响应比任何高层级的协议都快得多。偶尔的数据包丢失是正常网络操作的一部分,这不是异常情况。

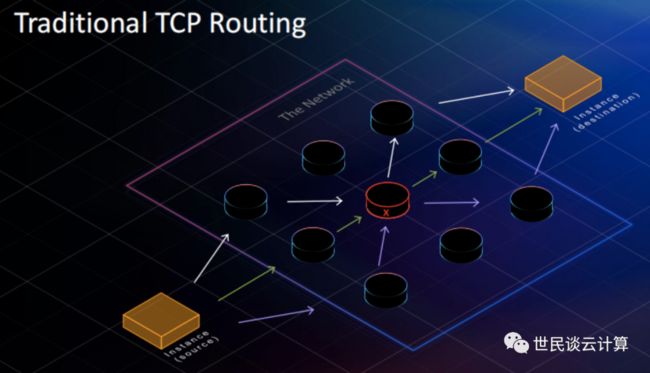
我们来通过 TCP 和 SRD 两种协议的对比来看看其优势。TCP 的传统路由方式示意图:
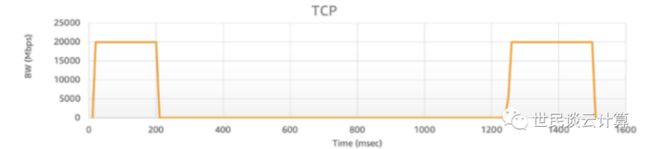
丢包很大概率会引起 TCP 传输带宽的大幅下滑。
而 SRD 采用全路径传输方式:
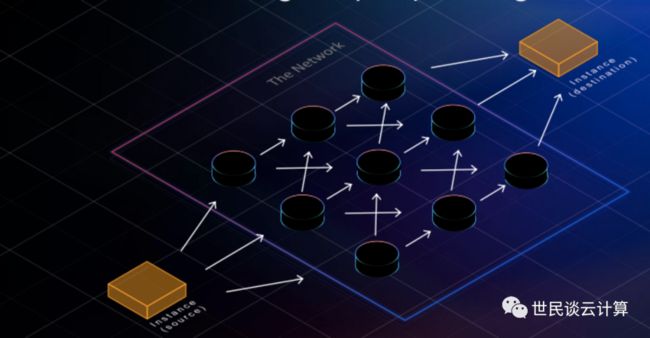
这种情况下,丢包对带宽的影响非常小,除了短时间的小抖动,几乎没有影响。
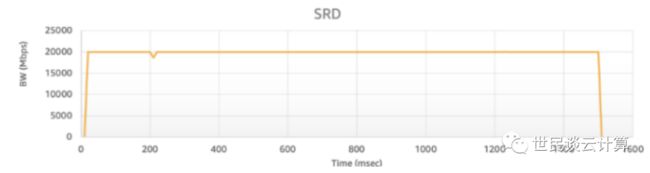
“旧时王谢堂前燕,飞入寻常百姓家”。过去只能用于 HPC 集群中的 SRD 协议,如今应用到最为通用的 ENA 网卡中。就是它,让 ENA 网卡性能一下子跃升了5倍!

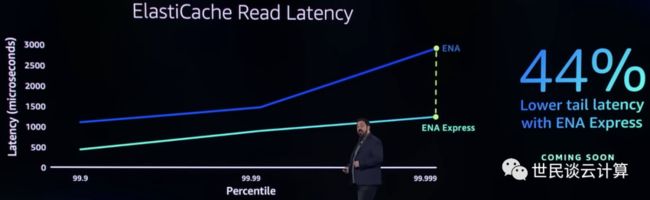
这种性能提升带来的好处是实实在在的。以亚马逊云科技内存数据库服务 Amazon ElastiCache 为例,与普通ENA网络相比,ENA Express 能够降低44%的尾部延迟,TCP 最大单流带宽将增加4倍,从5Gbps增加到25Gbps。
4. EBS卷最大IOPS提升4倍

IOPS,每秒输入/输出操作(Input/Output Operations per Second)的缩写,是一个常用来表征存储设备性能的数字,数字越大表示存储的性能越好。
当亚马逊云科技在2006年推出 Amazon Elastic Compute Cloud (Amazon EC2) 时(Amazon EC2 Beta),m1.small 实例的本地磁盘存储容量只有微不足道的160 GiB。此存储与实例具有相同的生命周期,并且在实例崩溃或终止时消失。在EC2测试版和2008年推出 Amazon EBS 之间的两年时间里,这些早期卷能够提供平均约100 IOPS。
随着亚马逊云科技的早期客户获得了 EC2 和 EBS 的使用经验,他们要求提供更高的 I/O 性能和灵活性。在2012 发布当时新的预配置 IOPS (PIOPS) 卷时,其 IOPS 达到了1000。多年来,随着客户群变得越来越多样化,亚马逊云科技为EBS添加了新的功能和卷类型,同时也在提高性能、耐用性和可用性。
2014年,亚马逊云科技推出 Amazon Elastic Block Store 通用型 (SSD) 卷类型,无论卷大小如何,它都能使每个卷的每秒 I/O 操作 (IOPS) 激增至3,000次。
2020年,亚马逊云科技与 SAP 合作为 SAP 认证了 Amazon EBS io2 卷。与 Amazon EBS io1 卷类型相比,io2卷的卷耐用性提高了100倍,IOPS 与存储的比率提高了10倍。
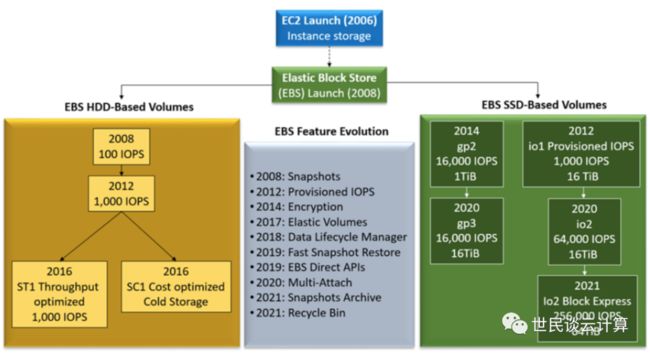
下图是 EBS 家谱,从2008年的100 IOPS 起点开始,到2012年单个 PIOPS 卷可以提供1000 IOPS,再到今天高端 io2 Block Express 卷可以提供高达 256,000 IOPS。
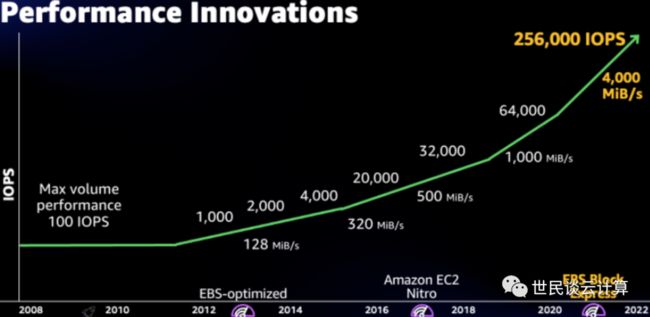
从曲线视角来看 EBS I/O 性能的持续14年的大幅提升历程:
从表的视角来仔细看:
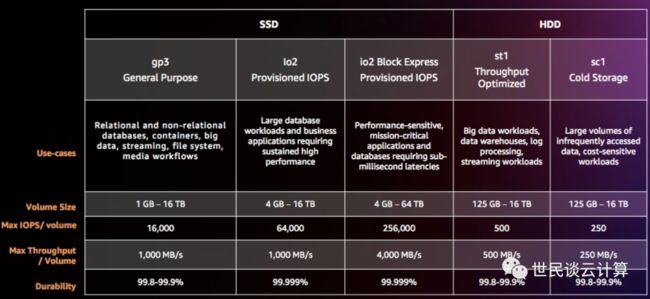
在上面 EBS 卷家谱中,引起笔者最大兴趣的是2021年发布的Io2 Block Express类型,其最高IOPS和吞吐量比io2全都增加了3倍。这是一次多么大的性能跃升啊!
在2020年re:Invent峰会上,亚马逊云科技宣布了io2 Block Express 提供预览版本,它被设计用于对IOPS和延迟有最高要求的最为关键的应用,比如Microsoft SQL Server, Oracle, SAP HANA等。

io2 Block Express 卷使用了多种Nitro系统组件,包括Amazon Nitro SSD存储和用于EBS的Nitro卡。最大容量可达 64 TiB,并且提供高达 256,000 IOPS 和 99.999% 的耐用性和高达 4,000 MiB/s 的吞吐量。
2021年7月,io2 Block Express 卷正式发布。
2022年,亚马逊云科技宣布将SRD应用于io2 EBS卷,这就是本章的主角io2 Block Express 卷。过去的一年中,亚马逊云科技继续将SRD协议的覆盖面延伸到EBS上。甚至可以认为,io2 Block Express = io2 + SRD。
Io2 Block Express 卷性能大幅提升,两种创新技术功不可没:一是在网络方面应用了可扩展可靠数据报 (SRD) 协议;二是在存储方面应用了亚马逊云科技自研的 Nitro SSD。因为这两种创新前文都提到过,这里就不再赘述了。
SRD协议有效改善了 Amazon EBS 块存储性能,减少90%的尾部延迟,并将吞吐量提升4倍。

Io2 Block Express 卷使得客户们可以抛弃本地数据中心昂贵的 SAN 存储了。

亚马逊云科技宣布从2023年初开始,所有新的 Amazon EBS io2 卷都将在 SRD 上运行。我们拭目以待!
5. Graviton全速冲刺云计算制高点
2022年 re:Invent 峰会上,亚马逊云科技发布了 Graviton3E 芯片。

这是一款专用于高性能计算服务器的 Graviton芯片,在HPC领域内常用的浮点计算和矢量计算上了针对性优化。与 Graviton3 相比,HPC 性能提升了30%。
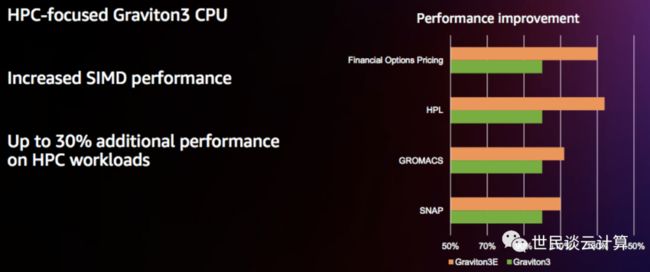
在笔者看来,亚马逊云科技的 Graviton 芯片具有几个“快”特点。
一是发布速度快。2018年发布 Graviton1,2019年发布 Graviton2,2021年 Graviton3。这速度刚刚的!

二是性能提升快。从服务器视角来看,基于 Gravtion 的服务器的架构有很多直接改进:每台服务器3颗 Gravtion 芯片,芯片密度虽然提升了50%,但服务器耗电量却和两路芯片服务器相当;而且全部芯片由 Nitro 统一管理,提升了安全性的同时,还节省了管理成本。

从芯片本身的性能来看,很难对三款芯片的性能直接进行对比。不妨换个视角,从采用了三种芯片的同样规格的 EC2 实例的性能和性价比上进行对比:
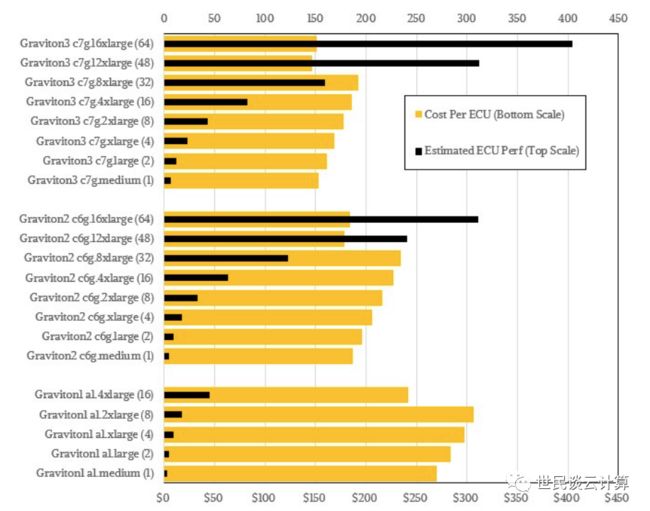
图上可以清楚地看出,每一代 Graviton 的每单位容量成本的橙色条越来越短,而性能的黑色条越来越长。我们没有理由不相信这种趋势会在 Graviton4 上继续下去。
三是,亚马逊云科技自己的服务向 Graviton 迁移的速度快。
除了计算、数据库、大数据分析服务外,亚马逊云科技也把 SageMaker 服务也运行在 Graviton 上了。

四是用户的认可速度快。
Databricks CEO Ghodsi 提到:“越来越多的客户将 Gravtion 芯片带来的性价比提升视为免费的午餐。”
Gravtion 实例在一些客户中变得如此受欢迎,以至于在某些地方,这种服务器有时候甚至会售罄。初创公司 Honeycomb 使用它从英特尔驱动的服务器切换到 Graviton 服务器所节省的资金来开发其它功能,而无需提高其价格。该公司的主要开发人员 Liz Fong-Jones 说:“我们使用我们可以得到的所有 Graviton 2和 Graviton 3服务器,但在我们需要的一些可用性区域 Graviton 3 服务器却售罄了。”
五是用户向 Graviton 迁移的速度快。
这里举两个例子。
一个是 Databricks,它的软件加快了开发机器学习模型的过程。其首席执行官 Ali Ghodsi 在最近的一次采访中表示:“自4月以来,当 Databricks 开始推广其在由第二代 Graviton 芯片提供支持的亚马逊云科技云服务器上运行的软件时,其软件性能提高了20%,成本却降低了20%至40%。”
另一个是 Snowflake。其产品高级副总裁 Christian Kleinerman 在一份电子邮件声明中表示,“与其他类型的服务器相比,在 Graviton 服务器上使用 Snowflake 的软件可以提高10%的速度。性能提升意味着 Snowflake 客户不需要尽可能多地使用其软件,促使 Snowflake 在3月其收入将减少近1亿美元。同时该公司表示,随着客户利用较低的服务器成本并将更多数据放入 Snowflake 数据库,它希望弥补这一不足。”
Gravtion 高速冲刺“抢占制高点”逻辑到底是什么呢?
从一代代产品发布,到一项项性能提升,到自身服务全面应用,到用户加速切换,Gravtion的一切动作都是那么快速。这背后,亚马逊云科技的行为逻辑到底是什么呢?也许,Forrester Research 高级云分析师 Tracy Woo 的一句话一语道破了天机:“Gravtion 服务器芯片成为了亚马逊云科技对抗追赶者的秘密武器,它是亚马逊云科技要把他们和追赶者拉开差距而正在做的最重要的事情之一”。
数据分析初创公司 Starburst Data 的工程副总裁 Ken Pickering 表示,在 Graviton 服务器上运行的一个优势是,它们在并行化或同时处理多个不同的计算作业方面优于英特尔和 AMD,这使得使用 Graviton 处理器的云服务器,耗电量更少、速度更快。
这种优势,也和很多客户反馈中得到了印证。 有客户通过租用 Graviton 服务器节省了10%到40%的计算成本。据一位直接了解相关数据的人士透露,Twitter、Snap、Adobe 和 SAP 都是 Graviton 服务器的客户,Graviton 服务器在推出仅三年后就成为了一项收入达数十亿美元的业务。自从亚马逊在去年5月份推出更具成本效益的第三代 Graviton 芯片以来,竞争对手感受到了更大的追赶压力。
一方面,Graviton服务器的速度和效率为亚马逊云科技客户节省了资金。另一方面,客户对此服务器的需求非常强大,亚马逊从中获得的收入也在飙升。据直接了解数据的人士表示,截至2021年秋,每年Graviton服务器收入有望超过50亿美元。这意味着继续高速增长的话,到2022年可能占亚马逊云科技弹性计算云收入的10%以上。这位人士表示,EC2 收入约占亚马逊云科技去年 620 亿美元收入的一半。(备注:亚马逊云科技尚未披露 EC2 或 Graviton 的收入。)
写在最后
前文介绍的这些性能提升和优化,包括 Lambda 函数、ENA、EBS、TWP 和 Graviton,都发生在亚马逊云科技云基础设施的最底层。它们也许不像全新发布的那些服务那么耀眼,但是,它们带来的效果却是最直接的、最实在的、最惠及大众的、最能帮客户省钱的。因为这些服务,是亚马逊云科技数百万计的用户们最常使用的。
亚马逊云科技的创新注重因地制宜。比如在 SRD 创新上,传统数据中心通常采用 Spine-leaf 网络架构,如下图所示。
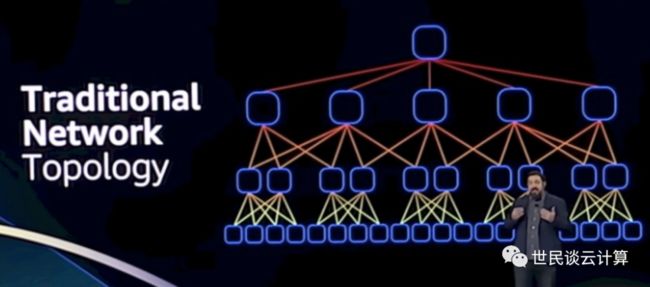
而亚马逊云科技数据中心网络采用改良版本的 CLOS 网络架构。

可以说,SRD 是最适合亚马逊云科技网络架构的网络协议。在这种网络拓扑之中,SRD 软件在网络端点间提供多路径,减少拥塞并允许网络在硬件故障时自动修复,从而提高其网络的有效吞吐量,同时减少网络延迟。
亚马逊云科技采用立体式全栈创新,系统地提升工程性能。基于各种黑科技,采用以芯片为代表的硬件、以 Nitro 为代表的网络、以 SRD 为代表的协议,为性能带来了成倍乃至数量级上的提升。
亚马逊云科技注重一种协议、全面采用。SRD 在全面支持 ENA 和 EFA 的基础上,增加了对 EBS 的覆盖支持,真正实现了“一种协议,全面采用”,最大化地发挥出价值。笔者预测,SRD 必将成为亚马逊云科技数据中心内主要的基础网络协议。

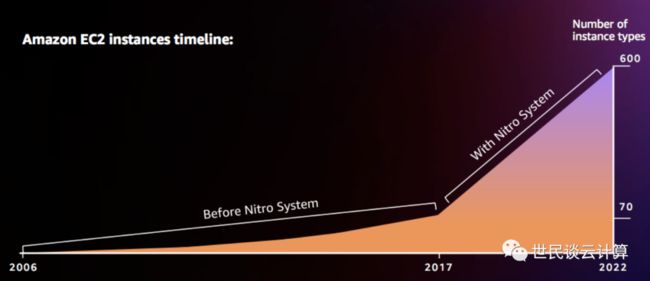
亚马逊云科技自研芯片之战,已赢得累累战果。自研芯片为亚马逊云科技带来了全面的专业性、高性能、创新速度和安全性。以创新速度提升为例,数据显示,自从 Nitro 在2017年发布以来,EC2 实例类型从几十种一下子增长到五百多种。
亚马逊云科技在底层创新的同时,还注重尽量不给用户带来额外改动成本。过去,SRD 一直专注在 HPC 领域中,对 TCP/IP 的支持一直存疑。这一次非常关键的是,使用了 SRD 的 ENA Express 直接支持了 TCP/IP 和 UDP,因此客户不需要修改任何的代码,就能直接利用 SRD 所带来的种种能力提升。
“快”是亚马逊云科技身上一道最亮眼的标签,让亚马逊云科技在短短十几年时间内就成为全球公共云霸主。亚马逊云科技越来越像一位大侠,在内力越发深厚的同时,出招还更快、更准。“快”的背后,是亚马逊云科技长远的眼光、准确的决策和坚决的执行力。
让这种底层创新和核心性能提升来得更多更猛烈一些吧!!

本篇作者

刘世民
云计算技术专家,曾就职于华为、IBM、海航等公司,专注于云计算。曾在海航集团易航科技担任云服务事业群总经理一职,负责 IDC、云平台、系统运维、信息安全以及用户服务等业务。维护有“世民谈云计算”技术博客和微信公众号。《OpenShift云原生架构原理与实践》作者之一、《Ceph Cookbook中文版》《精通OpenStack》、《机器学习即服务:将Python机器学习创意快速转变为云端Web应用程序》译者之一。

阅读原文:https://dev.amazoncloud.cn/column/article/63bce80a7ddc95285eaccd37