GoogLeNet论文解读
GoogLeNet论文翻译及解读
论文地址:https://arxiv.org/pdf/1409.4842.pdf
源代码:googlenet
摘要
推出的CNN关键结构为Inception,此结构的关键核心点为网络内部对计算资源的进一步利用,实现方法是当保持计算耗费稳定时让此结构的微妙设计使得网络的深度和宽度都增加。为优化网络,此架构是基于赫布原理和多尺度处理的。GoogLeNet为22层结构。
一、介绍
GoogLeNet所使用的参数比AlexNet使用参数少了12的整数倍个(具体多少个需要计算得出),且更加准确。目标检测之所以可以取得巨大成效并非只是单独的深度网络或更大的模型起作用,而是来自深度架构和经典计算机视觉的协同作用,如RCNN算法。
更加值得注意的因素为算法的效率(尤其是功耗和内存使用),本文提出的架构受制于这个因素。
本文重点介绍Inception结构,这是一种用于计算机视觉的高效深度神经网络结构。在这篇文章中深度有两层含义:①以Inception模块的形式引入了一个新的组织网络的模块,并且更直接的感受是增加了网络的深度。②可以将Inception视为逻辑顶点,该技术的引入使得ILSVRC2014挑战走得更深。
二、相关工作
Inception模型中的所有过滤器都是学习中的,而且Inception层会重复多次,这使得在GoogLeNet模型下会有22层的深度。
NIN结构应用于卷积层时,会被看作是额外的1×1卷积层后跟一个典型的ReLU非线性激活层,这种结构方法在本篇文章的结构中应用更多。在本文设置中1×1卷积有其他目的:被更主要的用作降维模块,可以降低计算量,这使得增加网络深度和宽度而不会增加计算量。
当前领先的目标检测方法是R-CNN,它将整个检测问题分解为两个子问题。首先利用低层的线索(颜色,超像素的一致性)生成物体潜在的区域(不考虑类别),其次使用CNN分类器去识别这些区域的物体的种类。这种两步方法充分利用了低层信息进行边界框分割的准确度,和最先进的CNN的强大分类能力。在检测任务中采用了一个相似的pipline,但是在两个步骤都有了提高。
三、动机和高层面的思考
提高深度神经网络性能方法:增加网络大小,包括深度和宽度,这是最直接的办法,也是最简单最安全的办法,尤其是当给定大量带标签的训练数据时。但是缺点明显:增加网络中训练的参数(导致过拟合),增加计算量。
解决上述问题的方法:从FC层完全转变到稀疏连接的结构,卷积层内部也是如此。Arora等人的开创性工作给了这种方法更坚实的理论基础,因为他们的主要结果表明如果数据集的概率分布可以用一个大的、非常稀疏的深度神经网络来表示,那么可以通过分析最后一层激活函数的相关统计量(均值方差等)和聚合有着高度相关输出的神经元来逐层生成最优的网络拓扑,这与赫布原理相仿——神经元一起发射且连接在一起。
Inception Net设计的思考是什么?(好的深度网络有哪些设计原则)
- 逐层构造网络:如果数据集的概率分布能够被一个神经网络所表达,那么构造这个网络的最佳方法是逐层构筑网络,即将上一层高度相关的节点连接在一起。几乎所有效果好的深度网络都具有这一点,不管AlexNet VGG堆叠多个卷积,googLeNet堆叠多个inception模块,还是ResNet堆叠多个resblock。
- 稀疏的结构:人脑的神经元连接就是稀疏的,因此大型神经网络的合理连接方式也应该是稀疏的。稀疏的结构对于大型神经网络至关重要,可以减轻计算量并减少过拟合。 卷积操作(局部连接,权值共享)本身就是一种稀疏的结构,相比于全连接网络结构是很稀疏的。
- 符合Hebbian原理: Cells that fire together, wire together. 一起发射的神经元会连在一起。 相关性高的节点应该被连接而在一起。
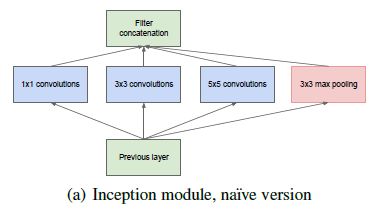
inception中 1×1的卷积恰好可以融合三者。我们一层可能会有多个卷积核,在同一个位置但在不同通道的卷积核输出结果相关性极高。一个1×1的卷积核可以很自然的把这些相关性很高,在同一个空间位置,但不同通道的特征结合起来。而其它尺寸的卷积核(3×3,5×5)可以保证特征的多样性,因此也可以适量使用。于是,这就完成了inception module下图的设计初衷:4个分支:
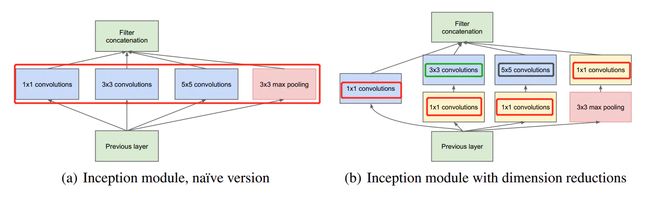
四、Inception结构细节
Inception架构的主要想法是考虑怎样近似卷积视觉网络的最优稀疏结构并用容易获得的密集成分进行覆盖。本文网络将以卷积构建块为基础,我们所需要做的是找到最优的局部构造并在空间上重复它。基于Arora等人提出的逐层构造结构,其中应该分析最后一层的相关统计量并将它们聚集成具有高相关性的单元组,这些聚类形成了下一层的单元并与前一层的单元相连接。我们假设较早层的每个单元都对应输入层的某些区域,并且这些单元被分到过滤器组中,在较低的层(接近输入的层)相关单元集中在局部区域。这意味着最终会得到大量聚集在单个区域中的集群,并且它们可以被下一层的1×1卷积层覆盖。然而人们也可以预期,在更大的块上,可以被卷积覆盖的空间分布更广的簇的数量将会减少,并且在越来越大的区域上块的数量会越来越少。为了避免块校正的问题,目前Inception架构形式的卷积核的尺寸仅限于1×1、3×3、5×5,这个决定更多的是基于简便性而不是必要性,这也意味着提出的架构是所有这些层的组合,其输出卷积核组连接成单个输出向量形成了下一阶段的输入。另外,由于池化操作对于目前卷积网络的成功至关重要,因此建议在每个这样的阶段添加一个替代的并行池化路径应该也具有额外的增益效果。
由于这些Inception模块相互堆叠,他们的输出统计量必然会发生变化:随着更高抽象层的特征被更高层捕获,它们的空间集中度预计会降低,这意味着随着网络向更高层移动,3×3和5×5卷积块的比例会上升。
Inception模块较大的一个问题(即便是在原始版本)是在具有大量卷积核的卷积层上即使是适度数量的5×5卷积,计算耗费也会过于昂贵,一旦将池化单元添加到混合的卷积块中,这个问题会更加明显:它们输出过滤器的数量等于之前阶段过滤器的数量。将池化层的输出与卷积层的输出合并将导致从一个阶段到另一个阶段的输出数量增加,即便这种架构可能涵盖了最优稀疏架构,但它的效率会非常低,也会导致在一些阶段中的计算爆炸。
下面就以上问题提出的第二个架构:应用降维和投影(否则计算需求会增加太多)。这是基于嵌入的成功提出:即便是低维嵌入也可能包含大量相对较大图像块的信息。然而嵌入以密集、压缩的形式表示信息,而压缩信息更难建模。1×1卷积用于在计算昂贵的3×3和5×5卷积之前计算减少量,除了用作还原之外,它们还包括使用线性激活整流的方法,这使它们拥有双重用途。架构结果如下图:

Inception网络由上述类型的模块相互堆叠而成,偶尔会出现步幅为2的最大池化层用于将网格的分辨率减半。
此架构的主要优点是:①允许显著地增加每个阶段的单元数量,会使得计算复杂度可控地增加。降维的普遍使用使得技术中可以屏蔽最后一级到下一层的大量输入过滤器。首先降低它们的维度,然后用大的块对它们进行卷积。②符合直觉,视觉信息应该在不同的尺度上进行处理然后再进行聚合,以便下一阶段可以同时从不同的尺度中提取特征。
1、基本卷积模块定义(每个卷积块后都跟ReLU)
class BasicConv2d(nn.Module):
def __init__(self, in_channels, out_channels, **kwargs):
super(BasicConv2d, self).__init__()
self.conv = nn.Conv2d(in_channels=in_channels, out_channels=out_channels, **kwargs)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
x = self.conv(x)
return self.relu(x)
2、Inception模块定义
# 定义Inceptionv1模块
class Inception(nn.Module):
def __init__(self, in_channels, ch1_1, ch3_3_in, ch3_3_out, ch5_5_in, ch5_5_out, maxpool_out):
super(Inception, self).__init__()
self.block1 = BasicConv2d(in_channels, ch1_1, kernel_size=1, stride=1)
self.block2 = nn.Sequential(BasicConv2d(in_channels, ch3_3_in, kernel_size=1),
BasicConv2d(ch3_3_in, ch3_3_out, kernel_size=3, padding=1))
self.block3 = nn.Sequential(BasicConv2d(in_channels, ch5_5_in, kernel_size=1),
BasicConv2d(ch5_5_in, ch5_5_out, kernel_size=3, padding=2))
self.block4 = nn.Sequential(nn.MaxPool2d(kernel_size=3, stride=1, padding=1),
BasicConv2d(in_channels, maxpool_out, kernel_size=1))
def forward(self, x):
branch1 = self.block1(x)
branch2 = self.block2(x)
branch3 = self.block3(x)
branch4 = self.block4(x)
output = [branch1, branch2, branch3, branch4]
return torch.cat(output, dim=1) # 想要去对那哪一个维度进行concat就必须要保证其他维度的大小是一样的
# 维度0为width,卷积过后都是一致的;维度2为depth,卷积过后不一致。因此concat只能在维度1上进行
3、Inception模块中辅助分类器定义
class Inception_Aux(nn.Module):
def __init__(self, in_channels, num_classes):
super(Inception_Aux, self).__init__()
self.averagePool = nn.AvgPool2d(kernel_size=5, stride=3)
self.conv = BasicConv2d(in_channels, 128, kernel_size=1) # output[batch, 128, 4, 4]
self.fc1 = nn.Linear(2048, 1024)
self.fc2 = nn.Linear(1024, num_classes)
def forward(self, x):
# aux1: N x 512 x 14 x 14, aux2: N x 528 x 14 x 14
x = self.averagePool(x)
# aux1: N x 512 x 4 x 4, aux2: N x 528 x 4 x 4
x = self.conv(x)
# N x 128 x 4 x 4
x = torch.flatten(x, 1)
x = F.dropout(x, 0.5, training=self.training)
# N x 2048
x = F.relu(self.fc1(x), inplace=True)
x = F.dropout(x, 0.5, training=self.training)
# N x 1024
x = self.fc2(x)
# N x num_classes
return x
五、GoogLeNet
GoogLeNet是Inception结构的转化
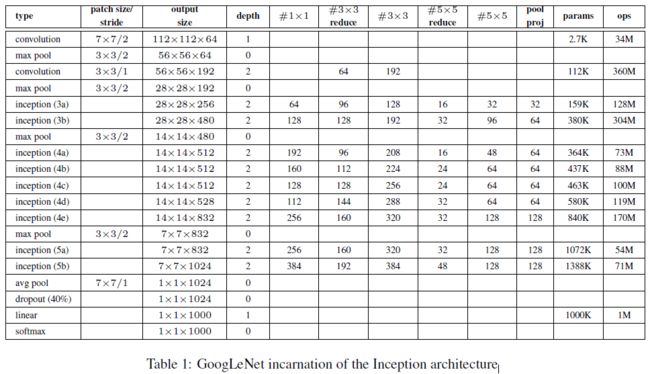
1、所有的卷积层(包括在Inception模块里的)都用到了ReLU。
2、本文网络的接受域大小为224×224来自三通道(RGB)去均值后的图片,“#3×3 reduce” 和 “#5×5 reduce”代表在3×3和5×5卷积层之前使用的缩小层中的1×1卷积数量,pool proj这一列数字表示内置最大池化层后投影层中1×1过滤器的数量,所有缩小层、投影层也都用到ReLU。
3、仅计算带有参数的层时网络只有22层的深度(如果计算池化层的话网络深度为27层),用于构建网络的总层数(独立构建块)大约为100层(这个数字取决于所使用的机器学习基础设施系统)
*4、分类器之前使用的平均池化是基于NIN论文中的全局平均池化层,不同之处是使用了额外的线性层,这使得本文可以轻松针对其他标签集微调GoogLeNet网络,不过这大部分是为了方便而且我们也估计这样不会产生多大的影响。从FC到平均池化的转变提高了网络准确率,移除FC层之后Dropout使用仍非常关键。
全局平局池化层
在NIN网络中,作者用feature maps的空间池化(spatial average)代替了常用的FC层,这种池化被称为全局平均池化(global average pool)。作者将全局平均池化层的输出当做各类别的概率。使用FC(黑箱)时很难解释各类别的概率信息是怎么反向传播回前面的卷积层的。全局平均池化层有实际意义,它将feature maps和类别对应起来。并且,FC层容易过拟合并且严重依赖Dropout正则化。传统的卷积网络用卷积提取特征,然后得到的特征再用FC+softmax逻辑回归分类层进行分类。使用全局平均池化层,每个特征图作为一个输出。这样参数量大大减小,并且每一个特征图相当于一个输出特征(表示输出类的特征)。
AlexNet网络的参数很大一部分来自于FC,NIN网络中用全局平均池化层取代FC,大大减少了参数量,所以,NIN在性能超AleNet的情况下,参数量从230M降到29M,很大一部分的减少来自于FC的去除。
*5、网络深度较大使得梯度回传至所有层是个问题,解决方法是添加辅助分类器连接到一些网络中间层(这些网络中间层产生的特征是非常有辨别力的)。我们希望在分类器的较低阶段中鼓励区分,增加得到回传的梯度信号并提供额外的正则化。这些分类器采用较小的卷积网络形式,放在Inception(4a)和(4d)模块的输出上。训练时,它们的损失会以加权权重的形式添加到网络的总损失中(辅助分类器的损失加权为0.3);推理时辅助分类器网络就被抛弃。
*6、边沿额外网络的确切结构,包括辅助分类器:
①大小为5*5,步幅为3的平均池化层,输出为4×4×512给4(a),而输出4×4×528给4(d)
②有着128个过滤器的1×1卷积模块用作降维和线性激活整流
③带有1024个单元的FC层和线性激活整流
④dropout层,丢弃率为0.7
⑤一个以softmax loss作为分类器的线性层(预测与主分类器相同的1000个类,但是在推理阶段移除该层)
1、GoogLeNet实现
class GoogLeNet(nn.Module):
def __init__(self, num_classes=1000, aux_logits=True, init_weights=False):
super(GoogLeNet, self).__init__()
self.aux_logits = aux_logits
self.conv1 = BasicConv2d(in_channels=3, out_channels=64, kernel_size=7, stride=2, padding=3) # 224*224*3 → 112*112*64
self.maxpool1 = nn.Sequential(nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True)) # 112*112*64 → 56*56*64
self.conv2 = BasicConv2d(in_channels=64, out_channels=64, kernel_size=1) # 56*56*64 → 56*56*64
self.conv3 = BasicConv2d(in_channels=64, out_channels=192, kernel_size=3, stride=2, padding=1) # 56*56*64 → 56*56*192
self.maxpool2 = nn.Sequential(nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True)) # 56*56*192 → 28*28*192
self.inception3a = Inception(in_channels=192, ch1_1=64, ch3_3_in=96, ch3_3_out=128, ch5_5_in=16, ch5_5_out=32, maxpool_out=32) # 28*28*192 → 28*28*256 只改变通道数,不会改变尺寸
self.inception3b = Inception(in_channels=256, ch1_1=128, ch3_3_in=128, ch3_3_out=192, ch5_5_in=32, ch5_5_out=96, maxpool_out=64) # 28*28*256 → 28*28*480 只改变通道数,不会改变尺寸
self.maxpool3 = nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True) # 28*28*480 → 14*14*480
self.inception4a = Inception(in_channels=480, ch1_1=192, ch3_3_in=96, ch3_3_out=208, ch5_5_in=16, ch5_5_out=48, maxpool_out=64) # 28*28*192 → 14*14*512 只改变通道数,不会改变尺寸
self.inception4b = Inception(in_channels=512, ch1_1=160, ch3_3_in=112, ch3_3_out=224, ch5_5_in=24, ch5_5_out=64, maxpool_out=64) # 14*14*512 → 14*14*512 只改变通道数,不会改变尺寸
self.inception4c = Inception(in_channels=512, ch1_1=128, ch3_3_in=128, ch3_3_out=256, ch5_5_in=24, ch5_5_out=64, maxpool_out=64) # 14*14*512 → 14*14*512 只改变通道数,不会改变尺寸
self.inception4d = Inception(in_channels=512, ch1_1=112, ch3_3_in=144, ch3_3_out=288, ch5_5_in=32, ch5_5_out=64, maxpool_out=64) # 14*14*512 → 14*14*528 只改变通道数,不会改变尺寸
self.inception4e = Inception(in_channels=528, ch1_1=256, ch3_3_in=160, ch3_3_out=320, ch5_5_in=32, ch5_5_out=128, maxpool_out=128) # 14*14*528 → 14*14*832 只改变通道数,不会改变尺寸
self.maxpool4 = nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True) # 14*14*832 → 7*7*832
self.inception5a = Inception(in_channels=832, ch1_1=256, ch3_3_in=160, ch3_3_out=320, ch5_5_in=32, ch5_5_out=128, maxpool_out=128) # 7*7*832 → 7*7*832 只改变通道数,不会改变尺寸
self.inception5b = Inception(in_channels=832, ch1_1=384, ch3_3_in=192, ch3_3_out=384, ch5_5_in=48, ch5_5_out=128, maxpool_out=128) # 7*7*832 → 7*7*1024 只改变通道数,不会改变尺寸
if self.aux_logits:
self.aux1 = Inception_Aux(in_channels=512, num_classes=num_classes)
self.aux2 = Inception_Aux(in_channels=528, num_classes=num_classes)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.dropout = nn.Dropout(p=0.4)
self.fc = nn.Linear(in_features=1024, out_features=num_classes)
if init_weights:
self._initialize_weights()
def forward(self, x):
# N x 3 x 224 x 224
x = self.conv1(x)
# N x 64 x 112 x 112
x = self.maxpool1(x)
# N x 64 x 56 x 56
x = self.conv2(x)
# N x 64 x 56 x 56
x = self.conv3(x)
# N x 192 x 56 x 56
x = self.maxpool2(x)
# N x 192 x 28 x 28
x = self.inception3a(x)
# N x 256 x 28 x 28
x = self.inception3b(x)
# N x 480 x 28 x 28
x = self.maxpool3(x)
# N x 480 x 14 x 14
x = self.inception4a(x)
# N x 512 x 14 x 14
if self.training and self.aux_logits: # eval model lose this layer
aux1 = self.aux1(x)
x = self.inception4b(x)
# N x 512 x 14 x 14
x = self.inception4c(x)
# N x 512 x 14 x 14
x = self.inception4d(x)
# N x 528 x 14 x 14
if self.training and self.aux_logits: # eval model lose this layer
aux2 = self.aux2(x)
x = self.inception4e(x)
# N x 832 x 14 x 14
x = self.maxpool4(x)
# N x 832 x 7 x 7
x = self.inception5a(x)
# N x 832 x 7 x 7
x = self.inception5b(x)
# N x 1024 x 7 x 7
x = self.avgpool(x)
# N x 1024 x 1 x 1
x = torch.flatten(x, 1)
# N x 1024
x = self.dropout(x)
x = self.fc(x)
# N x 1000 (num_classes)
if self.training and self.aux_logits: # eval model lose this layer
return x, aux2, aux1
return x
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)
结论
①通过现成的密集构建块来逼近预期的最优稀疏结构
②Inception结构的实施(即使没有用到背景和实施边界框回归)
③迁移到更稀疏的架构
个人理解及总结
此网络更注重于网络计算的效率,重点提出Inception模块和辅助分类器。
Tip1→运用赫布原理和多尺度并行处理:从FC层转变到稀疏结构。
Tip2→Inception模块的集成:使用1×1卷积核进行降维再用5×5卷积核升维。一个googlenet里包含九个Inceptionv1模块。
1×1卷积核的重要作用:①降维或升维②跨通道信息交融③减少参数量④增加模型深度并提高非线性表达能力。
因为原因①和③,所以在原始版本的Inception基础上3×3卷积和和5×卷积核之前都加上了1×1卷积核,且在最大池化层后加上了1×1卷积核。
Tip3→全局平均池化替代FC:减少参数量。做迁移学习更方便,用在弱监督学习和半监督学习中非常的可靠。
引用
[1] Google Inception Net论文细读 - 简书 (jianshu.com)
[2] NIN 论文笔记_黑暗星球-CSDN博客
[3]WZMIAOMIAOdeep-learning-for-image-processin