知识图谱课程报告-关系抽取文献综述
关系抽取文献综述
引言:
随着大数据的不断发展,在海量的结构化数据或非结构化数据中更低成本的抽取出有价值的信息越来越重要,可以说信息抽取是自然语言处理领域的一项最基本任务,信息抽取进而可被分成三个子任务:实体抽取(entity extraction)、关系抽取(relation extraction)和事件抽取(event extraction),而关系抽取搭建起知识图谱研究的基石。本文先介绍了关系抽取的定义和研究意义,而后指出了关系抽取目前存在的一些挑战,并介绍了关系抽取评测所使用到的几个主流测试数据集,之后将关系抽取从限定域和开放式两种抽取角度进行详细说明,将限定域关系抽取方法分类为四大类:关系分类、实体关系联合抽取、多关系抽取和远程监督关系抽取;将开放式关系抽取分为两类:传统方法和深度学习方法的关系抽取。再之后,根据每种抽取方法类别介绍了其几种经典的论文方法,文章最后对关系抽取领域作了简要的总结,并简要说明了关系抽取领域未来发展方向的看法。
关键字:知识图谱、关系抽取、机器学习、神经网络
1. 关系抽取的定义
通常我们将实体间的关系形式化的表达为一个三元组
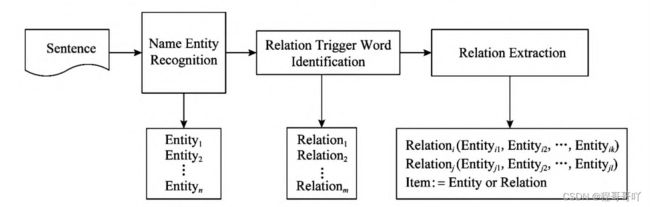
Fig.1 Relationship extraction system framework
图1 关系抽取系统框架
2. 关系抽取研究意义
关系抽取是信息抽取的基本任务,关系抽取从海量半结构化和非结构化数据中抽取出结构化的数据,这有利于数据的挖掘和探索,将抽取出来的结构化数据放入知识库存储,可以进一步研究和分析数据之间的关系,并充分开发数据智能。关系抽取是很多研究领域的基础研究之一,不但具有理论意义,还具有较好的应用前景,如知识图谱表示学习、知识推理、语言模型、问答系统和对话系统等[2],可以说关系抽取的质量的好坏,一定程度上直接决定了该领域的后期建模预测的准确率,而且关系抽取在当今研究中仍然存在很多研究瓶颈,很多问题人需要解决,因此,关系抽取依旧是一项意义重大的研究领域。
3. 关系抽取分类
关系抽取从抽取的文本上分类大致可分为两类:非结构化文本的关系抽取和半结构化的文本关系抽取,因为结构化文本和半结构化文本的关系抽取已经相对成熟,本文主要讨论关于非结构化文本的关系抽取方法。对于非结构化文本的关系抽取方法,可主要分为两类:1. 限定域关系抽取 2. 开放域关系抽取。之前的大多研究主要都是针对限定域关系抽取的,对于限定域关系抽取的分类,主要可以分为以下几类:1. 关系分类 2. 实体关系联合抽取 3. 多关系抽取 4. 远程监督关系抽取;近些年来,随着深度学习的慢慢兴起,开放域关系抽取开始由传统抽取方法逐渐过渡到深度学习抽取方法去。整个关系抽取的大致分类图如下[3]:
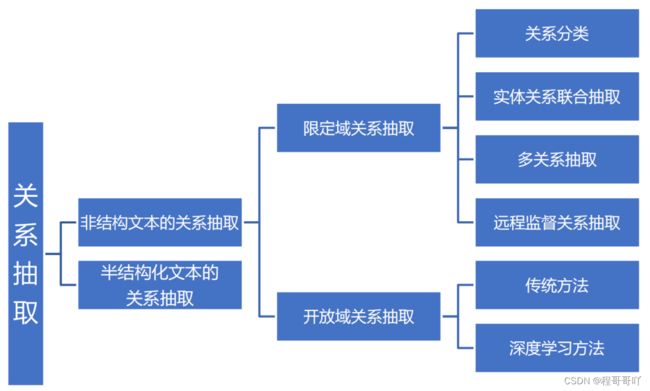
Fig 2. Relation extraction classification diagram
图2 关系抽取分类图
-
关系分类
给定一个句子以及句子中的两个实体,判断这两个实体之间是什么关系。因为关系集合已经预先定义好了,所以这个任务实质上是一个分类任务,因此叫做关系分类。
-
实体关系联合抽取
给定一个句子,需要识别句子中的实体以及实体之间的关系,实体和关系都一起识别出来。
-
多关系抽取
给定一个句子,需要识别句子中的实体以及实体之间的关系,句子中可能包含多个三元组时,它们之间可能会发生重叠,需要把所有的三元组都抽取出来,传统判别式模型,一个token只能输出一个标签。
-
远程监督关系抽取
利用知识库对文本自动进行回标得到远程监督数据集,无需人工参与,获取代价低,容易扩展到大规模的场景。
预定义关系抽取 关系分类 实体关系联合抽取 多关系抽取 远程监督关系抽取 给定条件 句子、实体对 句子 句子 包、实体对 目标 实体间的关系 两个实体和实体间关系(三元组) 多个三元组 包的关系 表1 关系抽取类别对比
在语言种类上,中文的关系抽取难度要比英文的大一些,主要体现在中文的句子需要分词,且中文本身语言的复杂程度要比英语高,多一些歧义和噪声,不像英语的句子已经用空格分好了词。
4. 主要挑战
当前关系抽取的主要挑战[4]主要有三点:1. 自然语言的多样性,同一个关系可以有多种不同的表述,如"国籍"关系,“姚明是中国人"和"姚明出生并生活在中国”、“姚明是中国籍运动员"这三句话对于"姚明"与"中国"之间的关系都是同一个表述,计算机算法却很容易把它辨别为三种关系;2. 自然语言的歧义性,相同的表述在不同的语境下可以表示不同的关系,如"乔布斯离开了苹果公司”,有可能有多重意思,有可能是被解雇了,也有可能是走出公司,下班回家了,人尚且会区分错,跟别说机器;3. 实体和关系类型的识别准确率仍旧有待提高,通过自然语言处理算法识别实体和关系类型虽然已经准确率挺高了,但仍然有进步空间,因为实体的识别准确率直接关系到关系抽取的准确率。
5. 数据集
5.1 ACE数据集
ACE数据集由ACE评测会议[5]提出,是一个关系分类数据集,由宾夕法尼亚大学的语言数据组织标注,2008年之后,ACE评测并入了TAC评测。该数据集预先定义了位置、机构、成员、整体-部分、人-社会五大类关系,主要使用机器学习方法针对英语、阿拉伯语、西班牙语等语言完成关系抽取任务,并不适用于汉语,该数据集主要用于关系的检测和识别,多被用于分类任务。
5.2 TPC-KBP数据集
是美国国家标准技术研究所主办的文本分析会议(TAC)发布的一个任务[6],主要研究从自然语言文本中抽取信息,并且链接到现有知识库的相关技术,可以视作是传统的关系抽取任务。该任务主要是抽取关于PER的25中属性和ORG的16中属性。主要是使用维基百科快照作为现有的知识库,从现有的新闻或者网络文本中获取关于实体的现有信息和更新信息,以构建知识库,此数据集关系种类较为丰富,数据量庞大。
5.3 SemEval数据集
SemEval 数据集完成基本任务是推特的情感分析[7]。对于推特的文本情感分析基于SemEval 数据集始于2013年,之后任务和数据都在不断发展为更复杂。到2019年,该数据集的数据已经包括框架语义和语义解析、观点、情感和脏话检测、事实与虚构、信息抽取和问答、科学应用中的自然语言处理多个方面的数据。其中跟关系抽取相关的是SemEval-2010,SemEval2010年的信息抽取任务数据集应用最广泛信息抽取任务是当年的第八个任务,故称为SemEval-2010任务8,数据集包含了9种有序关系和一个"其它"关系,共10717个样本,训练集8000个样本,测试集2717个样本,涵盖了10余种关系类别,且每种关系都是有序关系,是个预定义关系类别数据集。
5.4 NYT数据集
NYT数据集也是一个关系分类数据集[8],其文本来源于纽约时报New York Times所标注的语料,用斯坦福命名实体识别工具识别句子中的实体提及,用Freebase三元组中的实体名称与实体提及进行字符串匹配,将三元组中两个实体同时出现的句子收集在一起构成包。其中,纽约时报语料中2005-2006年的语料回标为训练集,2007年的语料回标为测试集。
5.5 WebNLG数据集
WebNLG数据集出自在INLG 2018年论文[9],描述 WebNLG是自然语言生成(NLG)社区的宝贵资源和基准。但是,与其他NLG基准一样,它仅包含一组并行的原始表示形式及其对应的文本实现。该数据集为了自然语言生成任务而构建,使用了DBPedia中的三元组,包括六个类别(宇航员、建筑、纪念碑、大学、运动队、著作)。
5.6 关系抽取评价体系
为了评测关系抽取的好坏,业内一般使用准确率(Precision)、召回率(Recall)和F1值来评价。其计算方法如下:

其中,在测试集和训练集两个数据集中,TP(True Positive):正确的正例,一个实例是正类并且也被判定成正类;FN(False Negative):错误的反例,漏报,本为正类但判定为假类;FP(False Positive):错误的正例,误报,本为假类但判定为正类;TN(True Negative):正确的反例,一个实例是假类并且也被判定成假类。
6. 经典方法
6.1 关系分类方法
给定一个句子以及句子中的两个实体,判断这两个实体之间是什么关系[10]。因为关系集合已经预先定义好了,所以这个任务实质上是一个分类任务,因此叫做关系分类。采用统计机器学习的方法,将关系实例转换成高维空间中的特征向量,在标注语料库上训练生成分类模型,然后再识别实体间关系。有以下这几种典型方法:
-
基于特征向量的方法
主要任务:如何获取各种有效的词法、句法、语义等特征,并把它们有效地集成起来,从而产生描述实体语义关系的各种局部特征和简单的全局特征。
Kambhatla[11]等人综合上下文信息,通过分析语法树、依存关系,结合词汇、句法和语义提出了一种最大熵模型来进行关系分类,该方法为了达到扩展关系表达得到规模和质量,利用到了上下文丰富的语言特征,为关系抽取奠定了基础;之后Zhao[12]等人借鉴最大熵模型的关系抽取方法,将支持向量机模型代替最大熵模型,一定程度上提高了关系抽取的准确率,在上文所说的ACE数据集上进行评测,F1值可达55.5%;Jiang等人[13]为了进一步提高关系抽取的准确率,提出了一种考虑技术复杂程度以及不同维度的特征的特征子空间方法,,该方法结合了条件随机场,在ACE数据集上测评,F1值可达54.0%。
-
基于核函数的方法
主要任务:如何有效挖掘反映语义关系的结构化信息及如何有效计算结构化信息之间的相似度。核函数k(x,y)用于计算x,y之间的相似度,x,y可以是字符串、句子、树等,比如说:x+表示一个句子具有某个关系,x-表示一个句子不具有某个关系,需要判断句子y是否有该关系,如果k(x+,y)>k(x-,y),表示y具有该关系,如果k(x+,y)
近年来,各种核函数被广泛的应用在关系抽取任务中。Zelenco等人[14]在解析树结构中首次应用核函数,该方法使用支持向量机和核函数投票机制来对实体之间关系进行分类,从而达到关系抽取的目的;Culotta等人[15]在Zelenco等人基础之上,引入外部知识库和依存核函数,使得关系抽取的准确率得到了进一步的提升;Zhang等人[16]首次将多个单一核函数融合,利用多个核函数复合计算用于关系抽取任务,并实验得到了一个比较好的结果,实验的准确率、召回率、F1分别是76.6%,67.0%,71.5%。
-
基于深度学习的方法
传统的方法需要的特征提取量大,如实体和关系类型的具体数量不确定,且人工抽取关系类型成本大且不准确,传统的关系抽取方法仍存在如下问题:1. 对于缺少NLP处理工具和资源的语言,无法提取文本特征2. NLP工具引入的"错误累积"3. 人工设计的特征不一定适合当前任务。
因为传统的关系抽取方法或多或少存在一些问题,随着近些年深度学习的热潮掀起,基于深度学习的关系抽取方法吸引了大量学者进行研究,基于深度学习的关系抽取方法主要任务:如何设计合理的网络结构,从而捕捉更多的信息,进而更准确地完成关系的分类。
Zeng等人[17]利用数据的局部特征建模,提出了一种基于卷积神经网络的关系抽取方法,该方法利用卷积深度神经网络(DNN)提取词汇和句子级特征,该方法接受所有的单词标记作为输入,没有进行复杂的预处理。首先,通过查找word embeddings将单词标记转换为向量。然后,根据给定的名词提取词汇级特征。同时,使用卷积方法学习句子级别特征。将这两个层次特征串联起来,形成最终提取的特征向量。最后,将特征输入softmax分类器,预测两个有标记名词之间的关系。该方法用于关系分类的神经网络结构如图3所示,该方法用于提取句子级特征的框架如图4所示。

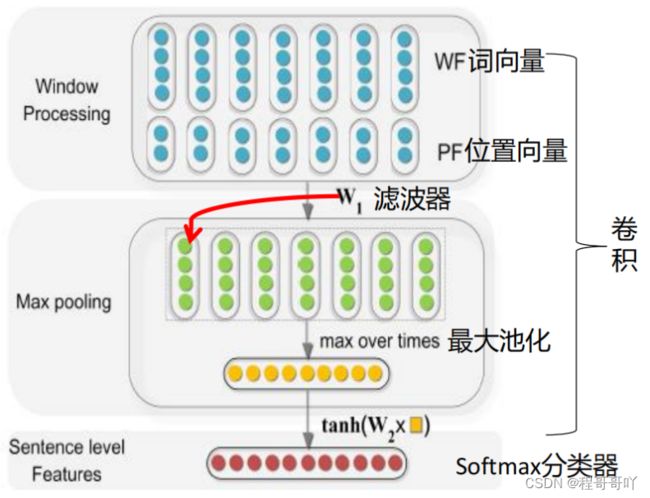
图3 关系分类的神经网络结构 图4 提取句子级特征的框架
该方法实验使用的数据集是SemEval-2010任务8,在8000个训练实体和2700个测试实体、19类关系类型的数据规模中,F1值可达到82.7%,实验结果表明(图5),该方法优于当时的最好方法SVM。
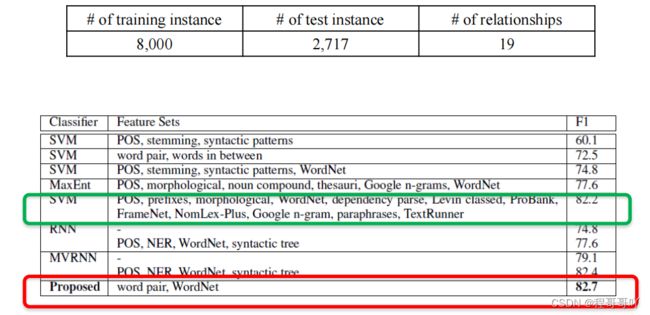
图5 CNN关系抽取实验结果
CNN的方法虽然一定程度上弥补了传统关系抽取方法的缺陷,但仍然存在一些缺点,如句子中的不同位置的词有不同程度的重要性,而CNN的方法难以建模句子中长距离的依赖关系,当遇到一些远距离文本语义的情况会变得不好解决。
Peng等人[18]提出使用一种使用长短期记忆神经网络(LSTM)并融合注意力关注机制的关系抽取方法,该方法提出了基于注意的双向长短时记忆网络(AttBLSTM)来捕捉句子中最重要的语义信息,利用双向LSTM编码每个词的表示,该模型如图6所示:

图6 带注意力机制的双向LSTM模型
该方法实验使用的数据集也是SemEval-2010任务8,综合F1值达到了84%,效果优良。
- 特征向量的方法、核函数的方法和深度学习方法对比
| 基于特征向量方法 | 基于核函数方法 | 基于神经网络方法 | |
|---|---|---|---|
| 优点 | 简单实用计算速度较快 | 能够有效挖掘结构化信息 | 人工干预小,可扩性好,适用于大规模数据环境 |
| 缺点 | 难以进一步挖掘有效的平面特征,性能很难进一步提高 | 句法分析的错误引入了噪声,同时由于树核的计算度非常慢,很难开发实用系统 | 可解释性差训练时间长 |
表2 关系抽取方法对比
6.2 实体关系联合抽取方法
给定一个句子,需要识别句子中的实体以及实体之间的关系。比如"乔布斯创立了苹果公司"这句话,要对这句话进行实体关系联合抽取,可得到创始人(乔布斯,苹果公司)类似的实体关系。
Zheng等人[19]将实体关系联合抽取转化为一个序列标注问题,该方法首先提出了一种新的标记方案,将联合提取任务转化为标记问题,然后,在此标记方案的基础上,研究不同的端到端模型,直接提取实体及其关系,而不需要分别识别实体和关系。详细操作为:1. 对每个关系,将其与(Begin,Inside,End,Single)以及头实体和尾实体的序号(1,2)组合。 2. 额外考虑一个Other标签,表示不属于任何一个关系。3. 如果总共有|R|个关系,那么一共有2 ∗4 ∗|R| + 1个标签。 4. 根据标注结果得到三元组。此方法的标记方案示例如图7所示:

图7 实体关系标记方法示例
该标注方法还尝试了分别使用长短期记忆神经网络融合马尔科夫随机场方法(LSTM+CRF)、双向长短期记忆神经网络(LSTM+LSTM)和双向长短期记忆神经网络加偏置(LSTM+LSTM+bias)三种方法进行序列标注,已达到关系抽取的目的,这三种方法的综合网络模型如图8所示:
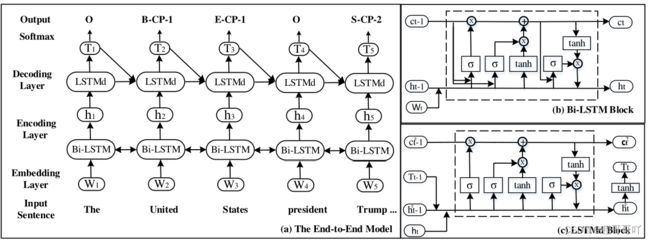
图8 Bi-LSTM方法网络模型
该方法使用使用弱监督的NYT数据集,看做监督数据。训练集包括353k个三元组,测试集包括3880个三元组,总共24种关系,在上文所说的三种抽取方法中,双向长短期记忆神经网络加偏置(LSTM+LSTM+bias)在大多数情况下是表现最好的,其实验结果如图所示:

图9 LSTM+CRF、LSTM+LSTM和LSTM+LSTM+bias实验对比
6.3 多关系抽取方法
传统的判别式模型,一个token只能输出一个标签,现在给定一个句子需要识别句子中的实体以及实体之间的关系,句子中可能包含多个三元组时,它们之间可能会发生重叠,需要把所有的三元组都抽取出来,比如说"姚明是一名中国籍的篮球运动员"这句话,需要抽取出两个三元组职业(姚明,运动员)和国籍(姚明,中国)。
这项工作有个比较困难的点是,当句子中包含多个三元组时,它们之间可能会发生重叠,为了弥补这个问题,Zeng等人[20]提出了一种融合拷贝机制的端到端模型,根据三元组重叠程度将句子分为三类:普通型、实体对重叠型和单个实体重叠型。该模型可以从任意类的句子中联合提取关系事实,将自然语言句子编码成一个定长的语义向量视为编码过程,将该语义向量直接解码成各个三元组作为解码过程。在译码过程中,该方法采用了两种不同的策略:只使用一个联合译码器或使用多个分离译码器。其模型示意图如图10所示:
拷贝机制来源于对话生成[21],对话生成等序列到序列模型在生成句子时:词可以来源于词表,还可以来源于上文的句子。因此,不仅需要计算词表中每个词的置信度,还计算源句子中每个词的置信度。在多关系抽取任务中:不需要从词表中生成词,因此只需要计算源句子中每个词的置信度,选择置信度最高的词作为被拷贝的词。

图10 融合拷贝机制的端到端模型
该方法的实验评测使用的是远程监督数据集NYT数据集,但是把它看作有监督数据来用,同时也使用了有监督的WebNLG数据集来进一步验证实验效果,实验结果表明,该模型有一定的效果,且由于传统方法,其实验结果如图11所示:
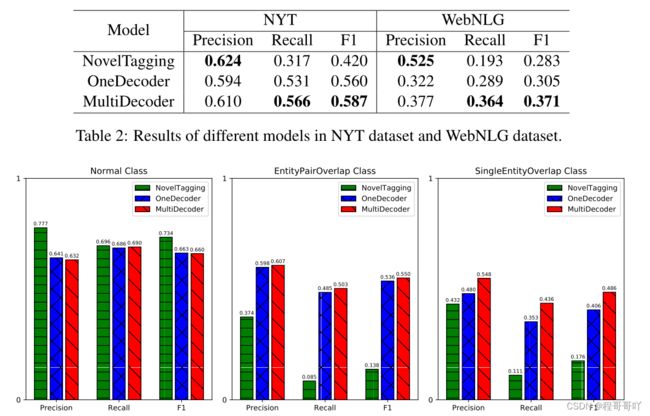
图11 NYT数据集和WebNLG数据集实验对比
6.4 远程监督关系抽取方法
前面所提到的关系分类、实体关系联合抽取、多关系抽取方法都存在一些缺陷,如都依赖有监督数据、有监督数据标注费时费力等,所以基于远程监督的关系抽取方法吸引了大批学者进行研究。远程监督关系抽取方法利用知识库对文本自动进行回标得到远程监督数据集,无需人工参与,获取代价低,容易扩展到大规模的场景。但是远程监督关系抽取也存在很多问题,如无法确定关系的类型、无法获取训练语料等。
2009年,Mintz等人[22]首次提出了使用知识库中的关系,启发式地标注训练语料的思想。通过包级别的标签预测:远程监督关系抽取需要给未知的包预测语义标签,最常用的数据集是通过Freebase回标纽约时报得到的NYT数据集,但是这又有一个难点:数据噪声问题如何解决?基于远程监督的关系分类有以下三种主要方法:1. 基于概率图的方法,Riedel、Hoffmann和Surdeanu等人[23,24,25]将句袋和句子的标签视为隐变量,将关系抽取视为对隐变量赋值的过程,在基于概率图的关系抽取领域做出了较好的成果。2. 基于矩阵补全的方法,Fan、Zhang等人[26,27]认为远程监督关系抽取中的特征、标签都有噪声,因此观测矩阵是由一个低秩矩阵加上一个噪声矩阵所构成,一定程度解决了远程监督关系抽取模型噪声的影响。3. 基于深度学习的方法,分段卷积神经网、注意力机制、多实例学习、强化学习等[28,29]深度学习方法都被使用到了关系抽取模型中。
在远程监督领域近,几年有突破性的研究成果有多实例学习方法[30],Zeng等人[30]提出了一个分段卷积神经网络(PCNNs)的多实例学习模型,为了解决启发式对齐可能会失败,导致错误的标签的问题,将远程监督关系抽取视为一个多实例问题,其中考虑了实例标签的不确定性;为了解决特征提取过程中产生的噪声会导致性能下降的缺陷,提出了一种采用卷积架构分段最大池来自动学习相关特征的方法,避免了做大量特征工程损失精度,此方法关系分类模型如图12所示:
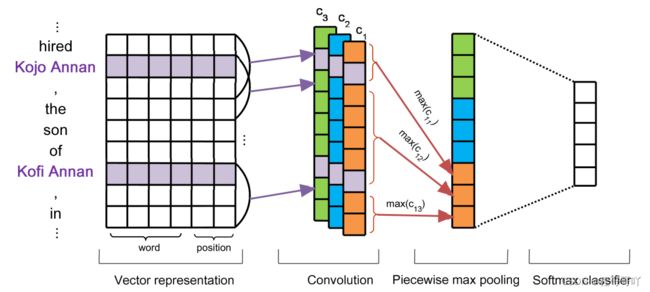
图12 PCNNs关系分类模型
分段卷积神经网络(PCNN)方法使用了远程监督数据集NTY数据集进行测试,其实验结果如图13所示,由图可见,PCNNs模型的效果更优。

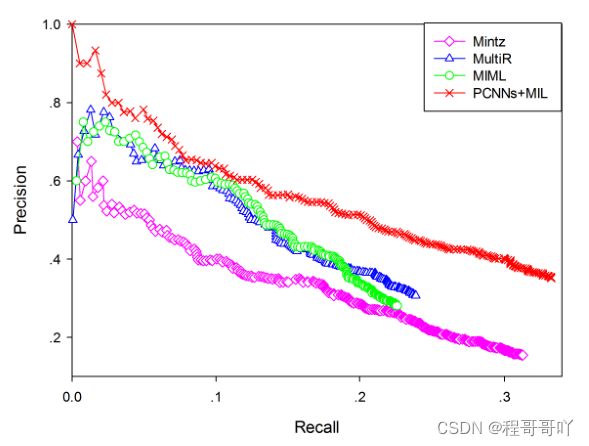
图13 PCNNs模型实验对比
7. 开放式关系抽取
传统的关系抽取是基于特定领域、特定关系类别的,这会让关系抽取成本较大且不利于知识库扩展,开放式关系抽取逐渐受到学者的青睐,开放式关系抽取无需预先定义关系类别,这让关系抽取的限定条件变得更宽松,也使得知识库更容易扩展,但也带来一个缺陷,语义没有归一化,没有同一套准则,使得不同知识库之间数据难以连通。
李航程等人[31]利用一种叫和声搜索算法(HS)的群体智能算法结合BP神经网络提出了一种新颖的关系规则抽取框架,该框架主要针对连续性数据集,从连续性数据集抽取出一种叫加权模糊产生式规则的知识表达,该知识表达不同于之前的实体三元组关系表达,主要由IF-THEN和一个权重组成,实验表明,该知识抽取框架可行,该框架如图14所示:
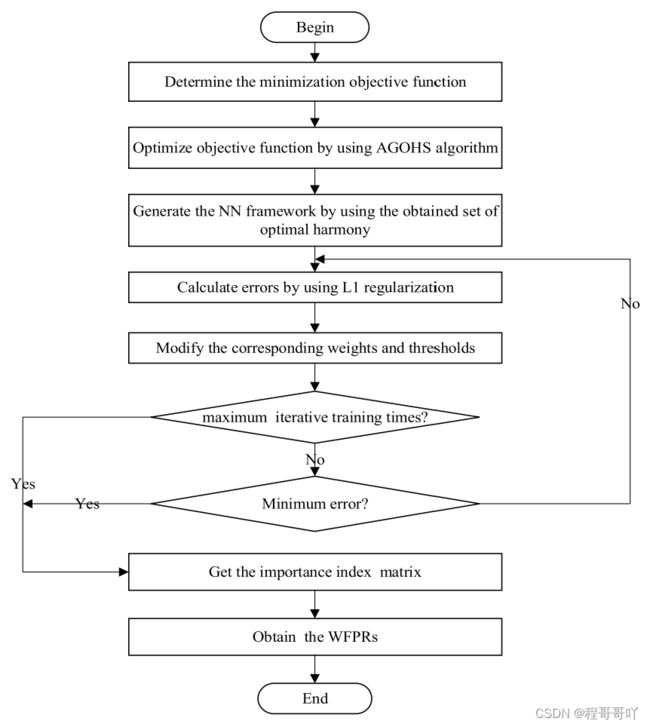
图14 HS+BP知识抽取框架
Sun等人[32]在深度学习开放式信息抽取的基础上引入了拷贝机制,结合序列标注和序列模型,从源句子中拷贝句子片段作为抽取出的三元组,该方法使用序列到序列的范式(称为逻辑学)训练一个端到端神经模型,将句子转换为事实,同时此论文还以众包的方式提出一个数据集,叫SAOKE,该抽取模型与上文远程监督的深度学习方法类型,如图15所示,实验结果表明,该方法具有不错的性能。
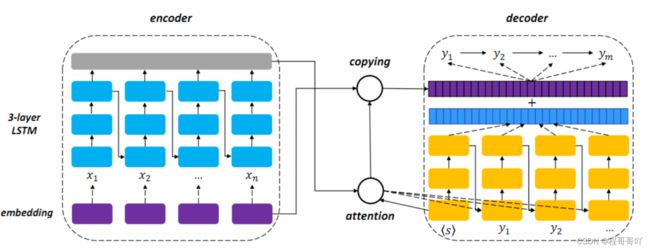
图15 开放关系抽取模型
8. 总结
8.1 关系抽取总结
随着近年来学者的不断研究,关系抽取方法已经得到不断的改进,关系抽取性能也得到不断的提升,目前已被广泛的应用在知识图谱、问答系统、文本挖掘当中。总结出现关系抽取主流方法还是传统的机器学习方法和新兴的深度学习方法,传统的机器学习方法,如基于特征和核函数的方法,如有监督的支持向量机方法和核函数方法,半监督的卷积神经网络方法和无监督的聚类方法等,将关系抽取转化为序列标注的远程监督方法等,这些方法的模型性能都十分依赖人工标注特征数据的规模和准确率,如果能有一个自动抽取出数据特征的方法这个缺陷将会得到解决。深度学习方法具有自学习的特点,能够自动抽取特征,减少人工依赖,深度学习方法主要有有监督和远程监督两种方法,其中(CNN,RNN,LSTM,GCN)各种复杂网络拓扑及其变体都有应用。基于深度学习的方法大大的促进了关系抽取领域的发展,针对特定领域深度学习方法模型性能更好,但其解释性和移植性较差。同时,基于开放式的关系抽取也吸引了广大研究者,但开放式的关系抽取目前还没有完整的评判体系,仍需要完善。
8.2 未来展望
1. 目前来说,随着智能化的要求及普及越来越严格,实体间关系也要求越来越高,关系抽取方法会从单一的关系分类慢慢过渡到实体关系联合抽取和多关系抽取。
2. 基于远程监督的关系抽取方法将会得到更大的发展,传统的有监督学习方法获取训练数据代价太大,太依靠人工标注的规模及准确率,基于远程监督的关系抽取方法能够较好的综合大量需求和精确率之间的平衡。
3. 基于限定域关系抽取得到的关系太过单一,且抽取流程局限较多,很难得到较完美的数据,基于开放式的关系抽取方法将会逐渐兴起,并吸引大量的学者研究。
参考文献:
-
李冬梅,张扬,李东远,林丹琼.实体关系抽取方法研究综述[J].计算机研究与发展,2020,57(07):1424-1448.
-
Q. Wang, Z. Mao, B. Wang and L. Guo, “Knowledge Graph Embedding: A Survey of Approaches and Applications,” in IEEE Transactions on Knowledge and Data Engineering, vol. 29, no. 12, pp. 2724-2743, 1 Dec. 2017, doi: 10.1109/TKDE.2017.2754499.
-
赵军, 刘康, 何世柱,等. 《知识图谱》[J]. 中文信息学报, 2020, 34(9):1.
-
Jing X , Liang G , Zhou B , et al. An Unsupervised Method for Entity Mentions Extraction in Chinese Text[C]// Asia-pacific Services Computing Conference. Springer International Publishing, 2016.
-
Recasens M , Pradhan S . Evaluation Campaigns[M]. Springer Berlin Heidelberg, 2016.
-
Ji H , Nothman J , Hachey B . Overview of TAC-KBP2014 Entity Discovery and Linking Tasks.
-
Nakov, P., Rosenthal, S., Kiritchenko, S. et al. Developing a successful SemEval task in sentiment analysis of Twitter and other social media texts. Lang Resources & Evaluation 50, 35–65 (2016).
-
Riedel, Sebastian, Limin Yao, and Andrew McCallum. "Modeling relations and their mentions without labeled text."Joint European Conference on Machine Learning and Knowledge Discovery in Databases. Springer, Berlin, Heidelberg, 2010.
-
Zheng H , Wen R , Chen X , et al. PRGC: Potential Relation and Global Correspondence Based Joint Relational Triple Extraction[J]. 2021.
-
S.-Y. Xu, X. Huang, and K.-L. Cheong, “Recent Advances in Marine Algae Polysaccharides: Isolation, Structure, and Activities,” Marine Drugs, vol. 15, no. 12, p. 388, Dec. 2017, doi: 10.3390/md15120388.
-
Kambhatla, Nanda. Combining lexical, syntactic, and semantic features with maximum entropy models for extracting relations. 2004:22-es.
-
Zhou G , Su J , Zhang J , et al. Exploring Various Knowledge in Relation Extraction[C]// ACL 2005, 43rd Annual Meeting of the Association for Computational Linguistics, Proceedings of the Conference, 25-30 June 2005, University of Michigan, USA. 2005.
-
Jing J , Zhai C X . A Systematic Exploration of the Feature Space for Relation Extraction[C]// Human Language Technology Conference of the North American Chapter of the Association of Computational Linguistics, Proceedings, April 22-27, 2007, Rochester, New York, USA. DBLP, 2007.
-
Zelenko D , Aone C , Richardella A . Kernel Methods for Relation Extraction[J]. Journal of Machine Learning Research, 2003, 3(3):1083-1106.
-
F Reichartz, Korte H , Paass G . Dependency Tree Kernels for Relation Extraction from Natural Language Text[C]// European Conference on Machine Learning & Knowledge Discovery in Databases. Springer-Verlag, 2009.
-
Zhang X , Gao Z , Man Z . Kernel methods and its application in Relation Extraction. IEEE, 2011.
-
Zeng D , Liu K , Lai S , et al. Relation classification via convolutional deep neural network. 2014.
-
Peng Z , Wei S , Tian J , et al. Attention-Based Bidirectional Long Short-Term Memory Networks for Relation Classification[C]// Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). 2016.
-
Zheng S , F Wang, Bao H , et al. Joint Extraction of Entities and Relations Based on a Novel Tagging Scheme[J]. 2017.
-
Zeng X , Zeng D , He S , et al. Extracting Relational Facts by an End-to-End Neural Model with Copy Mechanism[C]// Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2018.
-
Gu J , Lu Z , Li H , et al. Incorporating Copying Mechanism in Sequence-to-Sequence Learning[J]. 2016.
-
Mintz M , Bills S , Snow R , et al. Distant supervision for relation extraction without labeled data[C]// ACL 2009, Proceedings of the 47th Annual Meeting of the Association for Computational Linguistics and the 4th International Joint Conference on Natural Language Processing of the AFNLP, 2-7 August 2009, Singapore. Association for Computational Linguistics, 2009.
-
Riedel S, et al. Modeling Relations and Their Mentions without Labeled Text. ECML PKDD 2010
-
Hoffmann et al. Knowledge-Based Weak Supervision for Information Extraction of Overlapping Relations. ACL 2011
-
Surdeanu et al. Multi-instance Multi-label Learning for Relation Extraction. EMNLP 2012
-
Miao Fan et al. Distant Supervision for Relation Extraction with Matrix Completion. ACL 2014
-
Qing Zhang, Houfeng Wang. Noise-Clustered Distant Supervision for Relation Extraction: A Nonparametric Bayesian Perspective. EMNLP 2017
-
Jiang et al. Relation Extraction with Multi-instance Multi-label Convolutional Neural Networks. COLING 2016
-
Feng et al. Reinforcement Learning for Relation Classification from Noisy Data. AAAI 2018
-
Zeng D, Liu K, Chen Y, et al. Distant supervision for relation extraction via piecewise convolutional neural networks. EMNLP 2015
-
H. -C. Li, K. -Q. Zhou, L. -P. Mo, A. M. Zain and F. Qin, “Weighted Fuzzy Production Rule Extraction Using Modified Harmony Search Algorithm and BP Neural Network Framework,” in IEEE Access, vol. 8, pp. 186620-186637, 2020, doi: 10.1109/ACCESS.2020.3029966.
-
Sun M, et al. Logician: A unified end-to-end neural approach for open-domain information extraction. WSDM 2018