论文阅读:Real-time Semantic Segmentation with Fast Attention
Real-time Semantic Segmentation with Fast Attention
文章目录
- Real-time Semantic Segmentation with Fast Attention
-
- 摘要
- 贡献
- 方法
-
- FA
- 网络结构
- 视频语义分割
- 实验
- 原文链接
摘要

对于语义分割任务,准确性的提升需要更大的感受野和更精细的空间特征,代价是计算开销的增长。为了解决这两个问题,本文提出了一个FA(快速注意力)方法,实现了速度和准确性的双赢。
贡献

1) 为了有效地进行语义分割,我们引入了非局部上下文聚合的快速注意模块,并将其推广到一个时空版本的视频语义分割中。
(2) 我们的经验表明,在网络的中间特征阶段应用额外的空间约简可以有效地降低计算成本,同时增强模型丰富的空间细节。
(3) 我们提出了一个快速注意力网络,用于图像和视频的实时语义分割,其准确度和效率都比以前的方法高很多。
方法
FA

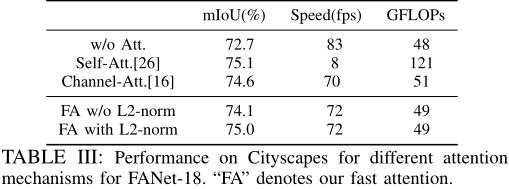
这里提到了一个 self-attention,和我这篇讲的论文阅读:LRNNet:一种高效减少非局部操作的轻量级实时语义切分网络里用到的方法一样,都是参考自2018年的《 Non-local neural networks》。
Eq.1的计算复杂度: O ( n 2 c ) O(n^2c) O(n2c)
为了解决计算开销问题,将 Softmax 移除,使用归一化余弦相似度代替。

改变下相乘次序
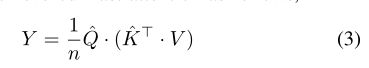
计算复杂度: O ( n c 2 ) O(nc^2) O(nc2),在语义分割任务中,>>
可以看到,计算开销明显减少。
(这里我没明白,为什么要交换一下乘法次序,文中也没有说)
网络结构
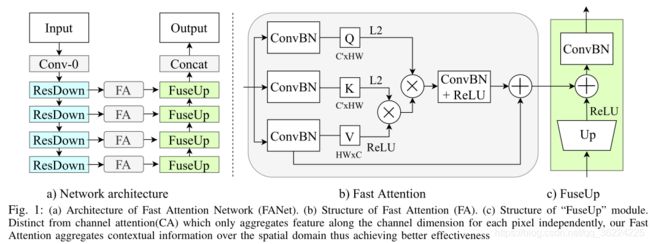
a)Backbone: ResNet-18,去掉全连接层。第一个下采样是4倍,其余的都是2倍。
b)FA模块由3个1x1卷积层构成,分别嵌入 query、key 和 value 映射的输入特征。去掉了Q和K后的RELU层以允许像素之间更大范围的相关性。沿通道维度的 L2 归一化确保亲和力在-1到+1之间。
为了在高层次的上下文中增强解码后的特征,进一步通过跳越连接来连接中间的特征。根据解码器输出的增强特征,预测了一个分辨率为 /×/的输出。
C)解码模块,在FA对特征金字塔进行处理后,解码器按照从深到浅的特征映射的顺序,逐步地对特征进行合并和上采样。
个人理解:每个FuseUp输出为1/4,最后 Concat 恢复原图像大小
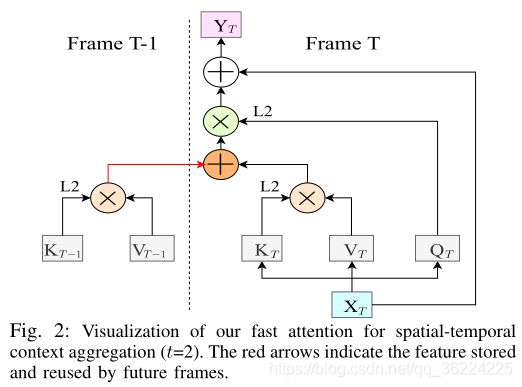
视频语义分割
不增加计算成本的情况下改善了视频语义分割

实验
数据集:Cityscapes、CamVid、CoCo-Stuff
使用 ResNet-18/34 在Imagenet 上预训练作为 FANet 的编码器
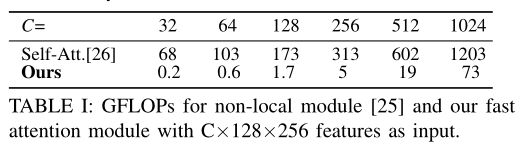
对于不同大小的输入特征,FA的运行效率明显更高,计算量减少了94%以上。

分析了通道数对 key 和 value 映射的影响,最后选择C=32
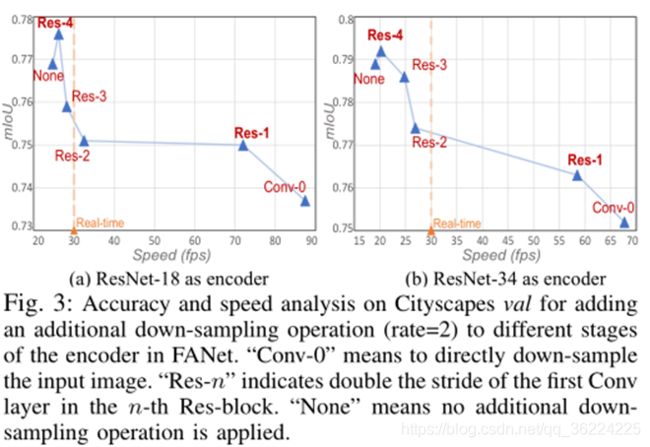
在“Conv-0”之前进行下采样会减少所有后续层的计算,但会丢失关键的空间细节,从而降低结果质量。“Res-1”表示在FANet的第一个Res块阶段减小空间大小。“Res-2”、“Res-3”和“Res-4”等较高阶段的额外空间缩减不会显著提高速度。足够有趣的是,我们观察到对“Res-4”应用下采样实际上比“无”执行得更好,这可能是因为“Res-4”块处理高水平的特征,增加额外的下采样有助于扩大接受场,从而受益于丰富的上下文信息。
根据观察结果,决定对“Res-1”应用额外的下采样,并作为 FANet-18/34 的编码器。
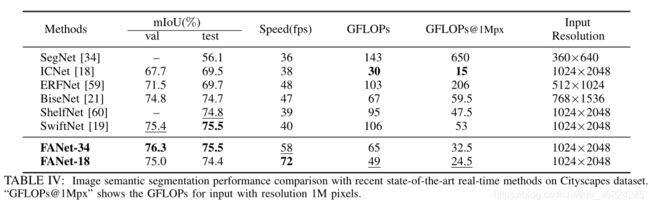
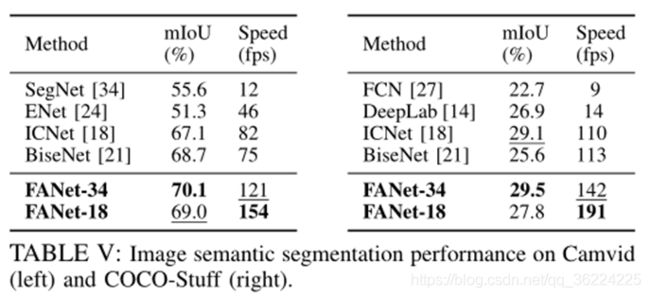
表四和五,说明了该方法对图像语义分割的有效性。
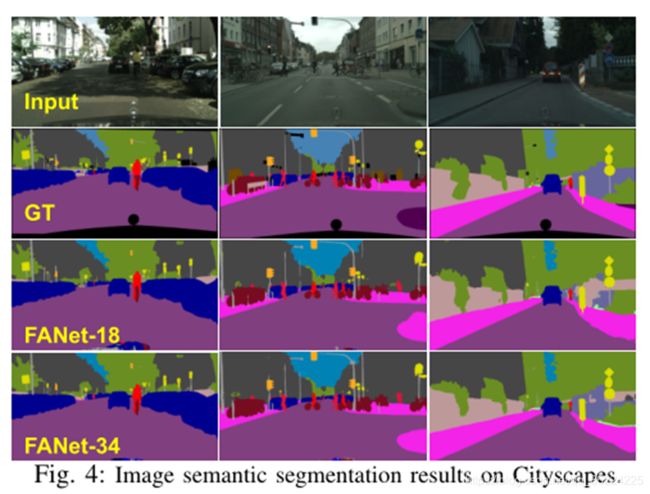
图4的分割效果与GT(ground truth)相比,只有图像下方的车的部分没有分割出来,其他细节的地方还好。
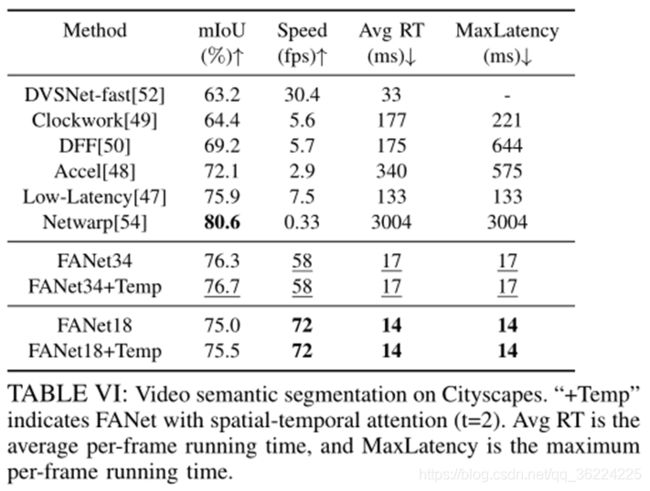
表六说明了该方法对视频语义分割的有效性。
原文链接
下载