GAN一点都不鲁棒?清华学霸们赢得NIPS攻防赛3项冠军的绝招在这里!
本文介绍了如何用对抗样本修改图片,误导神经网络指鹿为马;对 NIPS 2017 神经网络对抗攻防赛 3 项冠军清华团队的算法模型进行了解读。
文章部分内容来自 2018 CNCC 中国计算机大会—人工智能与信息安全分会场报告。
GAN 一点都不撸棒,简直不要太好骗:胖达变成猴,山误认为狗
对抗样本不是仅在最后预测阶段产生误导,而是从特征提取过程开始就产生误导
NIPS 2017 神经网络对抗攻防赛中,清华大学的学霸们采用了多种深度学习模型集合攻击的方案,训练出的攻击样本具备良好的普适性和可迁移性。
全文大约3500字。读完可能需要好几首下面这首歌的时间

胖虎和吴亦凡,边界是如此的模糊
王力宏和张学友,看上去竟如此的神似
人脸识别、自动驾驶、刷脸支付、抓捕逃犯、美颜直播…人工智能与实体经济深度结合,彻底改变了我们的生活。神经网络和深度学习貌似强大无比,值得信赖。
但是人工智能是最聪明的,却也是最笨的,其实只要略施小计就能误导最先进的深度学习模型指鹿为马。
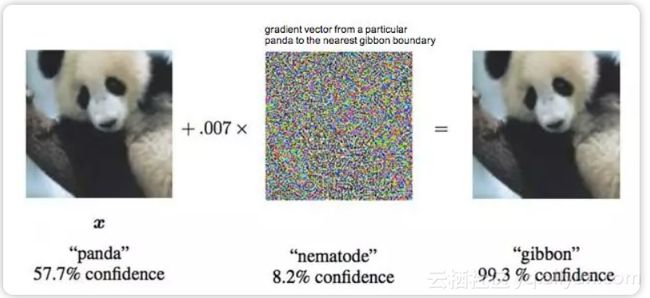
大熊猫 = 长臂猿
早在2015年,“生成对抗神经网络 GAN 之父” Ian Goodfellow 在 ICLR 会议上展示了攻击神经网络欺骗成功的案例。
在原版大熊猫图片中加入肉眼难以发现的干扰,生成对抗样本。就可以让 Google 训练的神经网络误认为它 99.3% 是长臂猿。
阿尔卑斯山 = 狗
2017 NIPS 对抗样本攻防竞赛案例:阿尔卑斯山图片篡改后被神经网络误判为狗、河豚被误判为螃蟹。
对抗样本不仅仅对图片和神经网络适用,对支持向量机、决策树等算法也同样有效。

那么,具体有哪些方法,可以把人工智能,变成人工智障呢?
人工智障:逃逸攻击,白盒/黑盒,对抗样本
逃逸攻击可分为白盒攻击和黑盒攻击。
白盒攻击是在已经获取机器学习模型内部的所有信息和参数上进行攻击,令损失函数最大,直接计算得到对抗样本。
黑盒攻击则是在神经网络结构为黑箱时,仅通过模型的输入和输出,逆推生成对抗样本。下图左图为白盒攻击(自攻自受),右图为黑盒攻击(用他山之石攻此山之玉)。
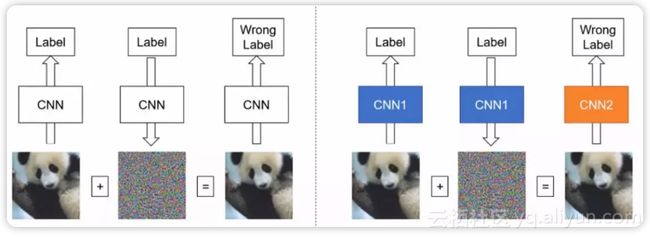
对机器学习模型的逃逸攻击,绕过深度学习的判别并生成欺骗结果,攻击者在原图上构造的修改被称为对抗样本。
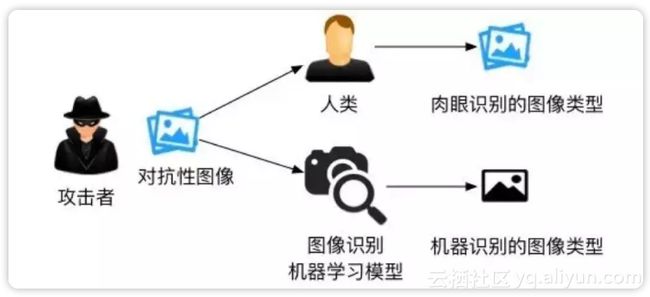
神经网络对抗样本生成与攻防是一个非常有(zhuang)趣(bi)且有前景的研究方向。
2018年,Ian Goodfellow 再发大招,不仅欺骗了神经网络,还能欺骗人眼。

论文链接:https://arxiv.org/abs/1802.08195
文中提出了首个可以欺骗人类的对抗样本。下图左图为猫咪原图,经过对抗样本干扰之后生成右图,对于右图,神经网络和人眼都认为是狗。

下图中,绿色框为猫的原图。左上角显示了攻击的目标深度模型数量越多,生成的图像对人类来说越像狗。 左下角显示了针对 10 个模型进行攻击而生成的对抗样本,当 eps = 8 的时候,人类受试者已经把它认成狗了。

除此之外,人工智能还面临模型推断攻击、拒绝服务攻击、传感器攻击等多种信息安全挑战。
人对抗样本有多好骗?
对抗样本会在原图上增加肉眼很难发现的干扰,但依旧能看得出来和原图的区别,下图左图为对抗样本,右图为熊猫原图。

对抗样本不是仅在最后预测阶段产生误导,而是从特征提取过程开始就产生误导. 下图展示了第147号神经元分别在正常深度学习模型和对抗样本中的关注区域。在正常模型中,第147号神经元重点关注小鸟的头部信息。在对抗样本中,第147号神经元则完全被误导了,关注的区域杂乱无章。

同时也说明,对抗样本不是根据语义生成的,它并不智能。而且,正如接下来讲述的,对抗样本对图片预处理过程非常敏感,任何区域截图、放大缩小、更换模型都很容易让对抗样本失效。
其实,如果你把那张经过攻击篡改之后的大熊猫图片稍微放大或缩小,或者直接截一部分图,然后放到其它公开的图像识别模型上运行(比如百度识图),识别结果依旧是大熊猫。
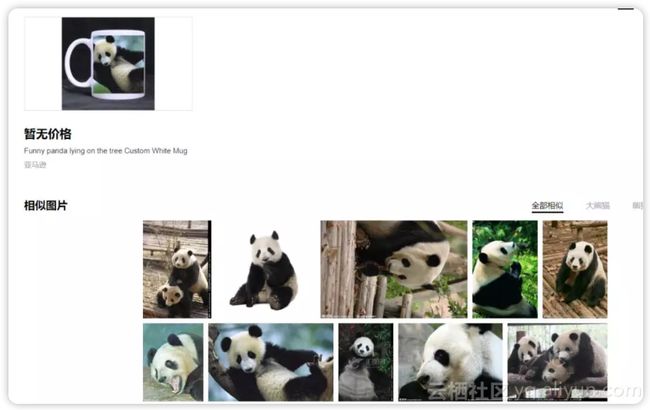
这意味着对抗样本仅对指定的图片和攻击模型生效,对诸如区域截图、放大缩小之类的预处理过程是非常敏感的。
也就是说,如果还想欺骗更多其它的深度学习模型,就要在训练生成对抗样本时尽可能包含更多的已知深度学习模型。
NIPS 冠军是怎么做的
2017 年,生成对抗神经网络(GAN)之父 Ian Goodfellow,牵头组织了 NIPS 的 Adversarial Attacks and Defences(神经网络对抗攻防竞赛)。
清华大学博士生董胤蓬、廖方舟、庞天宇及指导老师朱军、胡晓林、李建民、苏航组成的团队在竞赛中的全部三个项目中得到冠军。
清华大学团队正是采用了多种深度学习模型集合攻击的方案,通过对 Image.Net 网站上的三万张图片进行训练,提出七种攻击模型。
集合攻击考虑了 Inception V3、ResNet、Inception ResNet V2 三种已知的深度学习模型,训练出的攻击样本具备良好的普适性和可迁移性。
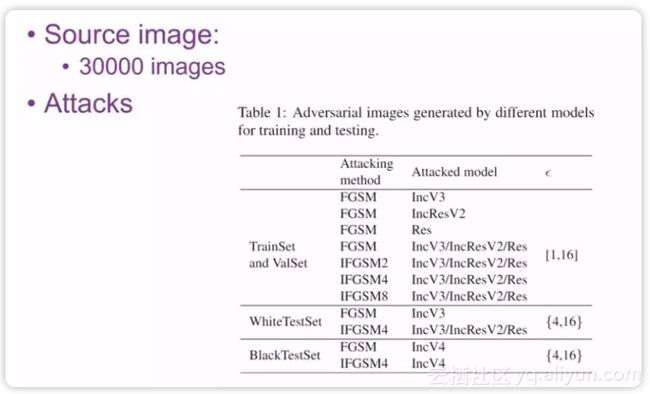
下图展示了他们使用FGSM模型进行攻击的测试:
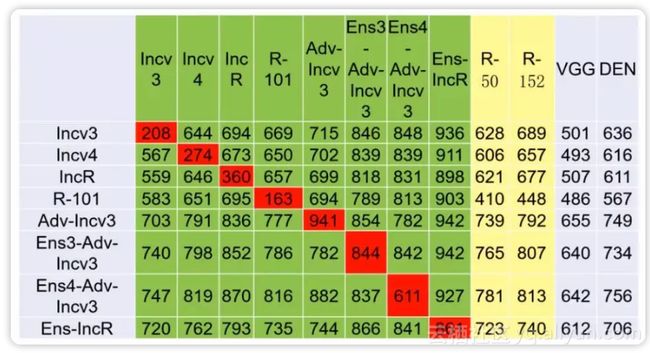
横行为攻击模型名称,竖列为防守模型名称,表格中的数字表示对于每1000张攻击图片,防守模型成功防守的图片数目,数字越大,表示竖列模型防守越有效,数字越小,表示横行模型进攻越有效。
红色表示用同一个模型进行攻防(白盒攻击)。可以看出:下面是个有序序列
白盒攻击成功率远远大于黑盒成功率。如何提高黑盒攻击的可迁移性,实现跨模型的黑盒攻击,是一个重要问题。
由 Adv-Incv3 竖列看出,经过对抗训练之后的防守模型非常强悍。甚至可以达到 94.1% 的防守成功率。
因此,将对抗样本引入训练数据集进行对抗训练是有效的防守策略,相当于士兵平时训练的时候就采用真实战场条件,上了战场自然不怂。
由 Ens4-Adv-Incv3 竖列看出,经过多个模型集合训练之后的防守模型非常强悍。 正所谓“用五岳他山之石攻此山之玉”、“曾经沧海难为水”,使用多个深度模型训练出的防守模型必然是集众家之长。
防御组:图像降噪策略
对抗训练(把真实战场作为训练场):在训练模型的时候就加上对抗样本(对抗训练)。
对抗样本随模型训练的过程在线生成。虽然很耗时,但训练出的模型鲁棒性很强
改进的HGD降噪算法:像素层面上的去噪并不能真正去掉噪音,传统的像素去噪方法全都无效。
采用基于CNN的改进HGD降噪算法,仅使用750张训练图片,大大节省训练时间,且模型可迁移性好。
NIPS 冠军是怎么做的
误导汽车的语音指令
这个方式已经被中国科学院大学教授陈恺实现了。通过对汽车音响播放的歌曲进行干扰编码,虽然人耳听起来仍然是原曲,实际上暗中通过微信的语音,发送了“Open the door”指令。
本文作者张子豪提出另一种思路,使用树莓派微型电脑,发射FM调频广播播放干扰之后的歌曲,直接干扰汽车收音机。
陈恺表示,已经尝试过该方式,决定干扰成功率的关键还是在于过滤外界噪音干扰。
直接破解本地 AI 模型
360智能安全研究院负责人李康认为,人工智能与信息安全的下一个热点:深度学习模型参数被窃取的风险和数据安全。
随着边缘计算和智能移动终端时代的到来,在移动终端部署本地 AI 应用越来越广泛。从iPhone X的刷脸解锁,到华为、高通部署手机端的 AI 芯片。
在移动终端本地运行 AI 应用,可有效解决延迟、传输带宽、用户隐私泄露等问题,但同时也带来本地深度学习模型的数据安全问题。
经过简单的逆推,就可以破解很多本地的 AI 应用,甚至可以知道其中的 Caffe 模型的基本参数。
有些开发者会采用 AES 加密把模型封装起来,但殊不知在 AES 密钥也得保存在本地文件中。
有时甚至根据追踪 AI 应用对内存的访问情况,就可以判断出这个模型的神经网络结构。
所以 AI 开发者在向移动端和嵌入式设备中部署 AI 应用时,一定要事先请教安全团队,确保模型数据安全。
延伸阅读
NIPS 2017 神经网络对抗攻防赛介绍:
比赛分组规则

比赛为三组选手互相进行攻防
● Targed Attack 组:组委会给 5000 张原图和每张图对应的目标误导结果数据集,制定要求指鹿为马
● Non-ratgeted Attack 组:只要不认不出是鹿就行
● Defense 组:正确识别已经被其他参赛组对抗样本攻击的图片
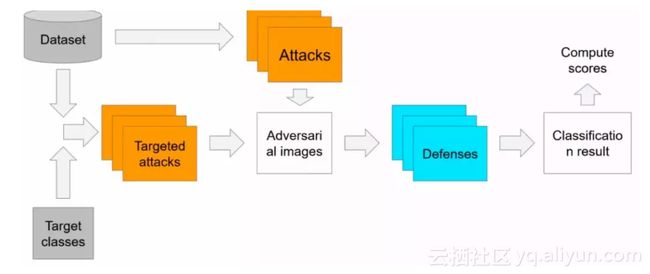
攻击组:对抗样本生成策略
集合攻击(他山之石可以攻玉):攻击多个已知深度学习模型的集合,而不是逐个击破。
比方说,把ResNet、VGG、Inception三个模型视作统一的大模型一起攻击,再用训练好的模型攻击AlexNet,成功率就会大大提高。
可以在模型底层、预测值、损失函数三个层面进行多个模型的集合攻击。
采用这个方法,可以大大提高对抗样本攻击的普适性和可迁移性。
改进的FGSM模型:多步迭代、带目标、引入动量,大大提高对抗样本的可迁移性。
原文发布时间为:2018-11-21
本文作者:张子豪
本文来自云栖社区合作伙伴新智元,了解相关信息可以关注“AI_era”。
原文链接:GAN一点都不鲁棒?清华学霸们赢得NIPS攻防赛3项冠军的绝招在这里!