知识蒸馏论文翻译(5)—— Feature Normalized Knowledge Distillation for Image Classification(图像分类)
知识蒸馏论文翻译(5)—— Feature Normalized Knowledge Distillation for Image Classification(图像分类)
用于图像分类的特征归一化知识蒸馏
文章目录
- 知识蒸馏论文翻译(5)—— Feature Normalized Knowledge Distillation for Image Classification(图像分类)
- 摘要
- 一、介绍
- 二、相关工作
- 三、方法
-
- 3.1 One-Hot 标签中的噪声
- 3.2
- 3.3 倒数第二层中的特征
- 3.4 特征规范化知识提取
- 四、实验
-
- 4.1 在Cifar上的结果
- 4.2 关于细粒度视觉分类的结果
- 自蒸馏
- 与Hypershpere嵌入的关系
- 五、结论
摘要
知识蒸馏(KD)将知识从繁琐的教师模型转移到轻量级的学生网络。因为单个图像可能合理地与几个类别相关,所以one-hot标签将不可避免地引入编码噪声。从这个角度出发,我们系统地分析了蒸馏机制,并论证了在标签噪声的影响下,倒数第二层特征的L2范数会过大,KD中的温度T可以作为L2范数的修正因子来抑制噪声的影响。注意到不同的样本遭受不同强度的标签噪声,我们进一步提出了一种简单而有效的特征归一化知识提取,其引入了特定于样本的校正因子来代替统一的温度T,以更好地降低噪声的影响。在Cifar-100、CUB-200-2011和Stanford Cars数据集上的实验表明,该方法明显优于标准KD和自蒸馏方法。
关键词:标签噪声;知识蒸馏;图像分类
代码:https://github.com/aztc/FNKD
一、介绍
卷积神经网络(CNN)近年来在人工智能领域取得了巨大的成功,尤其是在计算机视觉领域[10,39,2,8,7,16,1]。然而,这种成功伴随着计算和存储方面的高推理成本。许多工作致力于降低计算复杂性,如模型剪枝[9,5],轻量级网络结构设计[12,28,20]和自动化架构搜索[31,32]。Hinton等人[11]提出的知识蒸馏(KD)是一种有前途且广泛使用的模型轻量化方法,它通过软目标交叉熵损失函数将“暗知识”从集合或完整模型转移到单个紧凑模型。经过提炼,学生模型不仅继承了教师的优秀品质,而且由于其紧凑性,推理效率更高。
最近,知识发现取得了巨大的成功,一些工作将这种有效的思想扩展到其他应用领域[13,39,18],另一些[37,17,24]通过各种技术如基于特征的提取来改进标准的知识发现,并取得了更好的结果。研究者也试图寻求对KD更好的理解。例如,Lopez-Paz等人[19]建立了知识发现与特权信息之间的联系,Yuan等人[38]将知识发现视为标签平滑正则化(LSD)的一个特例,对学生训练施加了约束,Tang等人[33]将知识发现的影响分解为标签平滑、实例重新加权和最优输出层几何的先验知识三个方面。本文从标签噪声的角度系统地分析了温度在KD中的作用机制,并将倒数第二层特征的L2范数引入软目标中进行进一步的改进。

图一. 本文的概述。(a)由于图像之间存在视觉上的相似性,假设类别独立的一次性标签不能总是准确地描述图像在类别上的真实分布。one-hot标签和真实分布的区别是一种标签噪声。LSD和KD可以提供更好的监督。(b) KD通过用统一的T降低倒数第二层中特征的L2范数来软化标签,而我们的方法对每个样本使用唯一的 ∥ f ∥ \lVert f \rVert ∥f∥。
由于图像之间存在视觉相似性,假设类别独立的一次性标签并不总能准确描述图像在类别上的真实分布[23],如图1(a)所示。one-hot标签和真实分布之间的差异是一种标签噪声,会损害模型准确性[6]。从标签噪声的角度来看,LSD [30]等方法实际上是引入了先验知识来降低这种噪声。我们表明,KD可以被视为教师网络学习噪声信息并产生更好的去噪标签(图1(a))。然后,我们证明了在标签噪声的影响下,倒数第二层特征的L2范数会过大,KD中的温度可以作为L2范数的修正因子来抑制噪声的影响。由于L2范数也表示标签噪声的强度,我们将L2范数引入软目标作为样本特定的校正因子,以取代统一的温度T,从而更好地降低噪声的影响(图1(b))。最后,我们通过实验证明,我们提出的方法结合了KD和超球嵌入(HE) [26,35]的优点,这是另一种有效的正则化方法。
总之,我们做出了以下贡献:
- 我们从“one-hot标签噪声”的新视角系统地分析了知识蒸馏的温度机制,并验证了较高的温度实际上是代表标签噪声强度的倒数第二层特征的L2范数的一个修正因子。
- 基于我们的理论分析和经验发现,我们提出了一个简单而有效的创新特征归一化KD,用于进一步完善温度机制。在图像分类数据集上的大量实验表明,我们提出的方法比标准的KD方法有所改进。
- 我们已经展示了KD、LSD和HE之间的关系,并且经验地验证了所提出的特征标准化知识提取受益于KD和HE。
本文的其余部分组织如下。我们在第二节回顾相关的工作。第3节介绍了系统的论证和提出的创新方法。图像分类数据集的实验结果在第4节中呈现和分析,随后是第5节中的结论。
二、相关工作
自从Hinton等人[11]提出知识蒸馏来实现知识转移以来,许多工作已经将这种方法扩展到其他领域。例如,通过引入KD,郑等人[13]用紧凑的CNN实现了快速和精确的超分辨率。Zhang等人[39]将来自多个图像部分的知识提取到单个模型中,以提高细粒度视觉分类的性能。Li等人[18]试图用蒸馏法从噪声数据中学习,蒸馏法将在小的干净数据集中学习到的知识传递出去。
除了探索知识发现在其他领域的应用,另一个重要的方向是进一步提高知识提取的性能。Romero等人[27]提出,学生模型也可以模仿教师模型学习的中间表示(特征图),并建议通过MSE损失和软标签损失联合提取知识。在这项工作的指导下,基于特征的提取技术取得了令人印象深刻的进展。Yim等人[37]证明了在教师模型的两层之间学习变换方向比仅仅模仿特征更有效。Park等人[24]介绍了一种转移不同样本特征的关系属性的新方法。Sun等人[29]扩展了FITNET [27]以最小化学生和教师的每个单独层之间的均方误差,这对于BERT模型压缩是有效的。
除了基于特征的提取之外,还有改进训练过程的方法。由于KD需要两个阶段的训练过程,Lan等人[17]提出了一种用于一阶段在线提取的动态原生集成模型学习策略,以降低训练阶段的复杂性。Yang等人[36]从同一epochs的早期epochs中提取信息,以使教师和学生在一个epochs中进行优化,这可以进一步提高培训的效率。Mirzadeh等人[21]发现,当学生和教师之间的差距较大时,学生网络性能会下降,并引入了一种辅助机制来弥合这种差距。
尽管知识蒸馏取得了巨大成功,但令人惊讶的是,很少有理论研究能够更好地理解其工作机制。Phuong等人[25]通过研究深度线性分类器的特殊情况,首次洞察了蒸馏的工作机制,并发现了决定蒸馏成功的三个关键因素,即数据几何、优化偏差和强单调性。Müller等人[22]发现了KD和LSD之间的冲突,并认为不同类的实例之间的相似性对于提取至关重要。此外,Tang等人[33]将KD的影响分解为标签平滑、实例重新加权和最优输出层几何形状的先验知识三个方面,这与[25]类似。与我们的工作最相关的是袁等人[38],他们也认识到KD和LSD之间的关系,但是他们没有进一步揭示这两种方法的潜在原因。此外,我们正在改进KD,而他们的目标是一个无教师框架。
三、方法
在这一节中,我们基于理论和实证结果对我们提出的方法背后的机制进行了系统的分析。我们首先介绍了一键标签中普遍存在的标签噪声,并从标签去噪的角度分析了标准KD。之后,我们基于倒数第二层特征的L2范数是标签噪声的良好估计这一发现,提出了我们的特征归一化知识提取。
3.1 One-Hot 标签中的噪声
标签噪声是图像分类中常见的问题。正如benot[6]所指出的,标签噪声有四种主要的潜在来源。本文主要研究标签编码噪声。
考虑K路图像分类,对于给定的x,目标是学习一个参数映射函数 σ ( Ψ ( x ; θ ) ) \sigma(\varPsi(x;\theta)) σ(Ψ(x;θ)),它生成一个类分布 p ( k ∣ x ) p(k|x) p(k∣x)来估计真实分布 q ^ ( k ∣ x ) \hat{q}(k|x) q^(k∣x),其中 k ∈ { 1... K } k\in \{1...K\} k∈{1...K}, σ \sigma σ是softmax归一化函数, Ψ ( x ; θ ) \varPsi(x;\theta) Ψ(x;θ)表示由叠加卷积、汇集、relu等组成的CNN。在大多数情况下,我们并不确切知道 q ^ ( k ) \hat{q}(k) q^(k),而是使用ont-hot编码标签 q ( k ) = { 1 k = t 0 k ≠ t q(k)=\begin{cases}1 &\text{k}=t \\ 0 &\text{k} \not = t\end{cases} q(k)={10k=tk=t来近似它,其中t是x的基本类别,为了简单起见,我们在条件分布中省略了x。然而, q ( k ) q(k) q(k)的近似会引入标签噪声。这里,我们展示了图2中数据集CUB-200-2011 [34]和ImageNet [4]的一些例子。
从最上面一行,我们可以看到,虽然“黑脚信天翁”中的图像与“煤灰信天翁”中的图像非常相似,但它们属于“煤灰信天翁”类的概率仍然由一个热点标签指定为0。此外,“黑脚信天翁”类看起来比“冠啄木鸟”更接近“煤灰信天翁”,但一热标签使这两个类与“煤灰信天翁”有相同的“距离”。这些现象在ImageNet中更加突出,ImageNet包含1000个类别和更多视觉上相似的子类。例如,图2中最下面一行的图像可以被分类为“膝上型计算机”或“屏幕CRT ”,然而,由于一些主观原因,它们最终被分配为“膝上型计算机”类别的概率为100%。这种现象在这个数据集中很严重也很普遍。

图二. 标签噪声的可视化示例。从顶行,我们可以看到,虽然属于“黑脚信天翁”的图像与“煤灰信天翁”的图像非常相似,但它们属于“煤灰信天翁”类的概率仍然由一个热标签指定为0。“黑脚信天翁”这一类看起来更像“乌烟瘴气的信天翁”,而不是“有羽冠的啄木鸟”,但这三个类彼此之间有相同的“距离”,这是由一个热标签假设的。在ImageNet中也会观察到类似的情况。
根据上面的分析,我们可以看到,one-hot标签假设类别是相互独立的,并且每个x与非基本事实类没有关联。然而,属于不同类别的图像通常具有许多视觉相似性,即使它们在语义上是独立的。因此,one-hot标签的强假设会带来 q ^ ( k ) \hat{q}(k) q^(k)和 q ( k ) q(k) q(k)之间的噪声(图1(a))。有鉴于此,我们引入一个补偿分布 η ( k ) \eta(k) η(k)并设:
![]()
η ( k ) \eta(k) η(k)可以用来表示由单热标签引起的噪声,如图1(a)所示。尽管具有独热标签的数据集通常包含噪声,但是仍然很难找到比手动估计 q ( k ) q(k) q(k)更精确的 q ^ ( k ) \hat{q}(k) q^(k)估计。因此,噪声 η ( k ) \eta(k) η(k)会不同程度地广泛存在,并导致过拟合等问题。
除了上面的定性分析,我们还在CUB-200-2011上执行了一个简单的实验,以定量测量标签噪声对模型准确性的影响。虽然我们不知道真实的 q ^ ( k ) \hat{q}(k) q^(k),因此无法获得真实的噪声 η ( k ) \eta(k) η(k),但我们仍然可以引入一些先验来估计它,就像标签平滑正则化(LSD)一样[30]。LSD是一种有效的正则化方法,它通过将 q ( k ) q(k) q(k)与 u ( k ) u(k) u(k)均匀分布混合来软化独热标签,其数学公式为:
![]()
其中 q l s d ( k ) q_{lsd}(k) qlsd(k)是修改后的标签,而 ϵ 1 \epsilon_1 ϵ1控制其平滑度。比较等式2和等式1,我们可以认为 ϵ 1 1 − ϵ 1 u ( k ) \frac{\epsilon_1}{1-\epsilon_1}u(k) 1−ϵ1ϵ1u(k)作为 η ( k ) \eta(k) η(k)的估计值,因此LSD实际上是一种标签去噪方法,它使用各向同性滤波来产生近似 q ^ ( k ) \hat{q}(k) q^(k)的分布。考虑到大多数图像在每个类别中表现出不同程度的视觉相似性,而不是LSD假设的均匀多样性,我们提出了一种各向异性LSD,它引入了另一种非均匀分布 ρ ( k ) \rho(k) ρ(k)来更好地估计 q ^ ( k ) \hat{q}(k) q^(k)。各向异性LSD标签 q a l s d ( k ) q_{alsd}(k) qalsd(k)可以表示为:

其中A(x)表示包含更“接近”x的基本事实类的集合。A(x)由数据集提供的类别名称决定。例如,CUB-200-2011包含5个不同种类的“啄木鸟”,那么每个“啄木鸟”子类的概率将是?比其他非地面实况类多1/5。由于引入了关于类别的元信息,我们可以假设 q a l s d ( k ) q_{alsd}(k) qalsd(k)是比 q l s d ( k ) q_{lsd}(k) qlsd(k)更好的对 q ^ ( k ) \hat{q}(k) q^(k)的估计,并且将导致更高的模型精度。
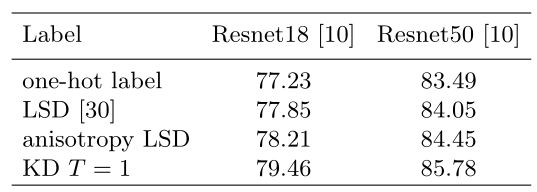
为了验证这一点,我们使用LSD和各向异性LSD与 ϵ 1 = 0.2 \epsilon_1=0.2 ϵ1=0.2和 ϵ 2 = 0.02 \epsilon_2=0.02 ϵ2=0.02来训练Resnet [10],然后比较它们的性能,如表1所示。正如预期的那样,LSD在准确性方面明显优于one-hot标签,这与Szegedy等人[30]的报告一致,我们的各向异性LSD通过引入更多关于 q ^ ( k ) \hat{q}(k) q^(k)的信息而进一步改进。该实验表明,一热标签中的噪声确实导致模型精度的下降,随着 η ( k ) \eta(k) η(k)对的估计变得更加准确,我们将获得更“干净”的目标以减轻一热标签所导致的问题。鉴于LSD通过预定义的先验抑制标签噪声,我们认为从数据中学习是估计真实分布 q ( k ) q(k) q(k)的另一种方式。在下一节中,我们将解释KD实际上是这样的方法之一。
3.2
标准知识蒸馏
如李等人[38]所言,KD是的一个特例。在本节中,我们将从标签去噪的角度进一步讨论它们的关系,并认为KD中的教师对标签噪声提供了更准确的估计,因此KD可以更好地获得近似真实分布的分布 q ^ ( k ) \hat{q}(k) q^(k)以帮助提升学生。
表1. 用不同的标签训练不同的架构。LSD表示标签平滑正则化,各向异性LSD是其改进版本。这两个标签可以看作是原始单热点标签的去噪版本,并且实现了更好的模型精度,这表明单热点标签中的噪声对模型训练有严重影响。最后一行显示了KD分别用Resnet50教师和Resnet152教师进行培训的结果。
通常通过最小化整个数据集的交叉熵损失 H ( q , p ) = − ∑ k = 1 K q ( k ) l o g ( p ( k ) ) H(q,p)=-\sum^K_{k=1}q(k)log(p(k)) H(q,p)=−∑k=1Kq(k)log(p(k))来训练CNN。KD没有优化 H ( q , p ) H(q,p) H(q,p),而是通过添加另一个正则项来修改目标。优化目标通常定义为:
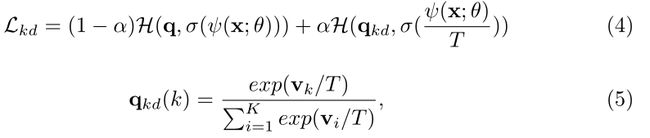
其中, q k d ( k ) q_{kd}(k) qkd(k)是教师模型基于其逻辑 v ∈ R K v\in\reals^K v∈RK以及 α \alpha α生成的另一个标签,控制两项之间的平衡。Hinton等人[11]引入的温度T作为一个因子来平滑教师和学生的输出。
当T = 1时,等式4可以简化为:
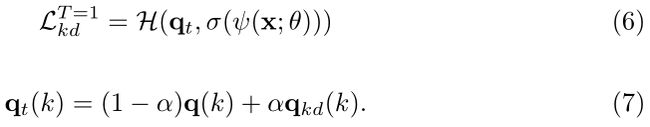
将等式7与等式2和等式3相比较,很容易发现这些等式具有相似的形式。这意味着 q t ( k ) q_t(k) qt(k)在这里扮演着与 q l s d 9 k ) q_{lsd}9k) qlsd9k)和 q a l s d ( k ) q_{alsd}(k) qalsd(k)相同的角色。基于上述讨论,我们认为 α 1 − α q k d ( k ) \frac{\alpha}{1-\alpha}q_{kd}(k) 1−ααqkd(k)也是对补偿分布 η ( k ) \eta(k) η(k)的估计,唯一的区别是 u ( k ) u(k) u(k)和 ρ ( k ) \rho(k) ρ(k)是预定义的,而 q k d ( k ) q_{kd}(k) qkd(k)是由另一个CNN从数据中学习的。因此,从标签去噪的角度来看,LSD和KD都旨在去除独热标签中的噪声,并产生更接近真实分布的分布 q ^ ( k ) \hat{q}(k) q^(k)。为了进一步定量比较KD和LSD,我们使用Resnet152和Resnet50作为教师,分别使用方程6和 α = 0.5 \alpha=0.5 α=0.5训练Resnet50和Resnet18。如表1中的底行所示,KD在两种设置中都以大的裕度优于LSD和各向异性LSD,这表明教师可以从训练数据中了解标签噪声,从而提供比均匀先验 u ( k ) u(k) u(k)更好的补偿 q k d ( k ) q_{kd}(k) qkd(k)。
为了进一步抑制噪声的影响,Hinton等人[11]引入了一种简单而有效的方法,即提高温度T,随着T的增加,等式5计算出的分布将变得更加柔和。当 T ≫ v k T\gg v_k T≫vk,我们可以泰勒展开等式5中的分子和分母,以将 q k d ( k ) q_{kd}(k) qkd(k)近似为:
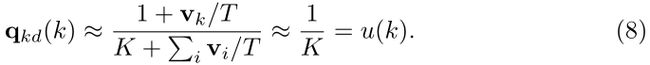
等式8表明,随着温度升高, q k d ( k ) q_{kd}(k) qkd(k)逐渐变得平滑,直到完全均匀。先前的工作[17,11]从经验上发现,适度的T会产生更好的学生。从标签噪声的角度来看,我们认为这是因为具有小T的 q k d ( k ) q_{kd}(k) qkd(k)噪声更大,因为它与单热标签的差异更小,而较高的温度会过滤掉许多噪声的影响,从而更好地帮助学生。为了让这个论点更加清晰,我们将在下一节讨论什么是老师的logits v v v,以及它是如何受到一热标签噪声的影响的。
3.3 倒数第二层中的特征
在本节中,我们将首先展示倒数第二层中的特征的L2范数可以有效地指示独热标签噪声。我们进一步证明,以KD为单位的温度T可以被视为该噪声的校正因子。
用于分类的CNN的最后一层通常是K路全连接操作。它将特征 f ∈ R D f\in\reals ^D f∈RD作为输入,并通过线性变换 v = W f v=Wf v=Wf产生逻辑 v v v,其中 W ∈ R C × D W\in\reals^{C\times D} W∈RC×D是参数矩阵。注意到:
![]()
其中k表示L2范数, v i v_i vi是v的第 i i i个元素, W i W_i Wi是矩阵 W W W的第i行,W和 θ i \theta_i θi是向量 f f f和 W i W_i Wi之间的角度。既然 f f f对每个 v i v_i vi的影响都是一样的,如果只是想知道给定样本的类别, ∥ W i ∥ c o s ( θ i ) \lVert W_i\rVert cos(\theta_i) ∥Wi∥cos(θi)就足够了,那么 ∥ f ∥ ) \lVert f\rVert) ∥f∥)的作用是什么呢?Wang等人[35]已经证明,具有较大范数的特征f可以产生更硬的分布,并且更好地适合独热标签。由于softmax损失总是鼓励正确分类的样本具有更高的概率,所以倒数第二层中的特征的L2范数在训练中会越来越大。简而言之, ∥ f ∥ ) \lVert f\rVert) ∥f∥)越大,输出分布将越接近于hot-one标签。然而,考虑到如上所述存在标签噪声的事实,实际分布 q ^ ( k ) \hat{q}(k) q^(k)实际上比hot-one标签更软,因此大的 ∥ f ∥ ) \lVert f\rVert) ∥f∥)部分是由噪声引起的,并且较短的f会更合适。因此,我们可以看到,为什么KD中有一个 T > 1 T>1 T>1,实际上,温度 T T T可以看作是L2范数的一个修正因子,它减弱了,从而减弱了 ∥ f ∥ ) \lVert f\rVert) ∥f∥)标签噪声的影响。
由于 ∥ f ∥ ) \lVert f\rVert) ∥f∥)部分取决于标签噪声,我们认为 ∥ f ∥ ) \lVert f\rVert) ∥f∥)可用于指示噪声强度。为了实证研究这一点,我们在CUB-200-2011上进行了一项实验,选择了三个类别,展示了每个类别中前两个最大和最小 ∥ f ∥ ) \lVert f\rVert) ∥f∥)的图像。如图3所示,具有较低特征L2范数的图像具有相似的角度、照明、背景和非常相似的外观。相对而言, ∥ f ∥ ) \lVert f\rVert) ∥f∥)较大的图像更具特征,更容易区分。Rajeev[26]进行了类似的实验,根据示例的 ∥ f ∥ ) \lVert f\rVert) ∥f∥)将IJB-a[14]数据集中的图像分为3组,发现 ∥ f ∥ ) \lVert f\rVert) ∥f∥)较小的图像质量较差,模型很难正确分类。这些结果表明,尽管一个热标签鼓励f具有较大的L2范数,但由于一些模型先验,这些包含更多标签噪声的硬示例仍然会保持相对较小的L2范数。注意到不同的样本受到不同强度的标签噪声的影响,我们提出了一种新的特征归一化KD,它根据每个样本的L2范数而不是所有样本的相同T来抑制噪声。

图3. 具有不同特征的图像。下一行显示了具有较低特征L2范数的示例,可以看出这些图像具有相似的角度、照明、背景和外观。相比之下,L2范数较大的图像看起来更容易区分。这表明 ∥ f ∥ ) \lVert f\rVert) ∥f∥)可以用来表示一个热标签中的噪声强度。
3.4 特征规范化知识提取
如前所述,示例功能的L2范数表示一个热标签中的噪声强度,其中较低的L2范数表示较强的噪声强度。因此,我们建议用L2norm的倒数来加权每个样本。考虑到这一点,我们引入了一种新颖的教师监督分布:

其中, τ \tau τ是控制分布 q f n ( k ) q_{fn}(k) qfn(k)平滑度的参数,就像原始温度T一样。对于学生,我们让他们按照方程式10计算类似的输出,以模拟老师,因此最终的特征归一化KD学习目标是:
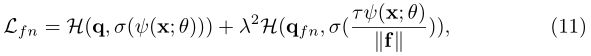
其中,我们去掉参数 α \alpha α,并添加一个新的权重 λ \lambda λ,与公式4中表示的原始软目标交叉熵损失相比。为了进一步说明,我们计算了损耗梯度 ∂ L f n / ∂ z k \partial L_{fn}/\partial z_k ∂Lfn/∂zk,关于蒸馏学生模型的每个logit z k z_k zk。这个梯度由下式给出:

使用与Hinton等人[11]类似的证明技术,假设 ∑ i z i = ∑ i v i \sum_iz_i=\sum_iv_i ∑izi=∑ivi且 ∥ f s ∥ = ∥ f t ∥ ≫ τ z k \lVert f_s\rVert=\lVert f_t\rVert \gg \tau z_k ∥fs∥=∥ft∥≫τzk,我们泰勒展开最后一项中的分子和分母,得到:

很明显,等式13引入了教师监督 v k v_k vk,以平衡“one-hot标签”的影响, ∥ f t ∥ \lVert f_t\rVert ∥ft∥有助于控制 z k − v k z_k-v_k zk−vk的贡献,它代表学生和老师的不同。
比较方程式13和KD中的对应项[11],我们可以发现最大的区别在于 ∥ f t ∥ \lVert f_t\rVert ∥ft∥的存在, ∥ f t ∥ \lVert f_t\rVert ∥ft∥在一个热标签和教师之间为每个样本分配了不同的权重,而不是标准KD给出的相同权重。当 q ( k ) q(k) q(k)中的噪声很强时, ∥ f t ∥ \lVert f_t\rVert ∥ft∥将很小,而 z k − v k z_k-v_k zk−vk的影响将相对较高。反过来,如果一个热标签的噪音更小, ∥ f t ∥ 2 \lVert f_t\rVert^2 ∥ft∥2会将教师的影响降低到可忽略的程度, p ( k ) − q ( k ) p(k)-q(k) p(k)−q(k)占主导地位。简言之,特征归一化KD可以根据示例中标签噪声的强度自适应地确定学生对教师的信任程度。
正如Hinton等人[11]所建议的,重要的是确保硬目标和软目标的相对贡献保持大致相同的数量级。因此,我们保持 λ 2 τ 2 / ( ∥ f t ∥ ) 2 ≈ 1 \lambda^2\tau^2/(\lVert f_t\rVert)^2\approx1 λ2τ2/(∥ft∥)2≈1,其中“”是训练集的平均值。为了与标准KD进行公平比较,我们将 ∥ f t ∥ / τ ≈ T \lVert f_t\rVert/\tau\approx T ∥ft∥/τ≈T,具体参数设置将在下面的实验部分介绍。
四、实验
在本节中,我们将在Cifar-100、Cifar-10、CUB-200-2011和斯坦福Cars数据集上进行大量实验,以验证我们提出的特征规范化知识提取(KD-fn)对不同图像分类任务的有效性。在此基础上,进一步将KD-fn与标准知识提取(KD)和超球面嵌入(HE)进行比较,并讨论它们之间的关系。
4.1 在Cifar上的结果
4.2 关于细粒度视觉分类的结果
自蒸馏
自蒸馏指的是特殊的KD,即学生和教师模型共享同一架构。其想法是作为教师,输入培训模型的预测,为再培训本身提供新的目标值。当培训资源受到限制或很难找到比学生更好的老师时,自我蒸馏是获得更高准确性的有效选择。从标签去噪的角度,我们认为,由于学生也可以在一个热标签中学习有关噪声的知识,因此可以利用这些知识来抑制噪声的影响,从而提高自身的学习能力。我们比较了5种不同型号的Cifar-100和CUB-200-2011上的self-KD fn和self-KD。表4显示,在所有情况下,self-KD-fn都优于self-KD-fn,这进一步证明了我们提出的方法的有效性。

与Hypershpere嵌入的关系
Hypershpere嵌入(HE)[26,35]是一种限制倒数第二层特征位于固定半径超球面上的方法,在人脸验证中很流行。该方法通常使用交叉熵损失,将倒数第二层特征的L2范数乘以 r / ∥ f ∥ , r ∈ R r/\lVert f\rVert,r\in\reals r/∥f∥,r∈R,对经过良好训练的模型进行微调∈ R。我们直接把这个方法中关于logit的梯度写为:

式中, p h e ( k ) p_{he}(k) phe(k)是根据公式10计算的输出。我们可以发现,这种方法与KD-fn类似,KD-fn也通过 ∥ f ∥ \lVert f\rVert ∥f∥对每个样本进行加权,以更加关注那些带有大量标签噪声的硬示例。与我们的方法不同的是, p h e ( k ) p_{he}(k) phe(k)的目标仍然是一个热门标签,而 p f n ( k ) p_{fn}(k) pfn(k)的目标是另一个教师。因此,KD-fn同时结合了教师和 ∥ f ∥ \lVert f\rVert ∥f∥的优势。表5显示了比较结果。由于有老师在场,KD-fn的表现明显优于HE。

五、结论
在本文中,我们提出了一种简单而有效的图像分类特征归一化提取策略。在从标签去噪角度进行系统分析的基础上,我们将倒数第二层特征的L2范数引入到软目标中,作为样本特定的校正因子,以取代KD的统一温度,从而更好地降低热标签中噪声的影响。综合实验表明,在Cifar-100、CUB-200-2011和斯坦福Cars数据集上,该方法明显优于标准KD。