CNN卷积神经网络之DCN(Deformable Convolutional Networks、Deformable ConvNets v2)
可变形卷积网络Deformable ConvNets V1、V2
- 前言
- 一、Deformable Convolutional Networks
-
- Deformable Convolution
- Deformable RoI Pooling
- Position-Sensitive (PS) RoI Pooling
- offset偏移学习
- 实验效果
- 思考
- 二、Deformable ConvNets v2
-
- Stacking More Deformable Conv Layers
- Modulated Deformable Modules
- R-CNN Feature Mimicking
- 思考
前言
2017年《Deformable Convolutional Networks》
论文地址:https://arxiv.org/pdf/1703.06211.pdf
2018年《Deformable ConvNets v2: More Deformable, Better Results》
论文地址:https://arxiv.org/pdf/1811.11168.pdf
由于构造卷积神经网络所用的模块中几何结构是固定的,其几何变换建模的能力本质上是有限的。可以说CNN还不能很好实现旋转不变性的。在以往会使用数据增强的方式,让网络强行记忆不同的几何形状。
作者认为以往的固定形状的卷积是网络难以适应几何变形的“罪魁祸首”,比如同一层的特征图的不同位置可能对应的是不同形状的物体,但是都和同一个形状卷积做计算,那么不能很好的将感受野作用在整个物体之上,因此提出了可变性卷积。
一、Deformable Convolutional Networks
下图展示了卷积核大小为 3x3 的正常卷积和可变形卷积的采样方式,(a) 所示的正常卷积规律的采样 9 个点(绿点),(b)( c)(d) 为可变形卷积,在正常的采样坐标上加上一个位移量(蓝色箭头),其中 ( c)(d) 作为 (b) 的特殊情况,展示了可变形卷积可以作为尺度变换,比例变换和旋转变换的特殊情况 :

下面介绍,如何计算偏置位移量:
Deformable Convolution

假设输入的特征图为WxH,将要进行的可变性卷积为kernelsize=3x3,stride=1,dialated=1,那么首先会用一个具有与当前可变性卷积层相同的空间分辨率和扩张率的卷积(这里也要k=3x3,s=1,dial,才能保证偏移个数一致)进行学习offset。conv会输出一个WxHx2N的offset filed(N是可变性卷积的3x3=9个点,2N是每个点有x和y两个方向向量)。之后,DConv可变形卷积核会根据偏移量进行卷积。
偏移量是小数,需要对原特征图进行双线性插值。

下图是连续三级可变形卷积带来的效果,每一级卷积都用3*3的卷积核做卷积,三层卷积后就能产生93=729个采样点。可以看到经过训练后所有的采样点都偏移到了不同尺度目标周围。
Deformable RoI Pooling

可变性ROIPooling的偏移值计算:首先RoI pooling产生pooled feature maps(绿色),然后用FC去学习归一化后的偏移值(为了使偏移量学习不受RoI大小的影响,需要对偏移量进行归一化),这个变量会和(w, h)做点乘,然后再乘以一个尺度因子,其中w,h是RoI的宽和高,而伽马是一个0.1的常数因子。用该位移作用在可变形兴趣区域池化(蓝色)上,以获得不局限于兴趣区域固定网格的特征。p也是个小数,需要通过双线性插值来得到真正的值。

个人理解,前者是为了让deformable能和RoI的尺度结合起来,更好地估计偏移位置;而后者是为了防止偏移量太大甚至超出RoI和整个图像。
调整后的bin如图红色框所示:此时并不是规则的将黄色框ROI进行等分成3x3的bin。

Position-Sensitive (PS) RoI Pooling
另外就是作者还搞出了一个和R-FCN的位置敏感比较类似的另一种RoI方法,同样是考虑deformable因素的,叫Position-Sensitive (PS) RoI Pooling,这里就不详细介绍了
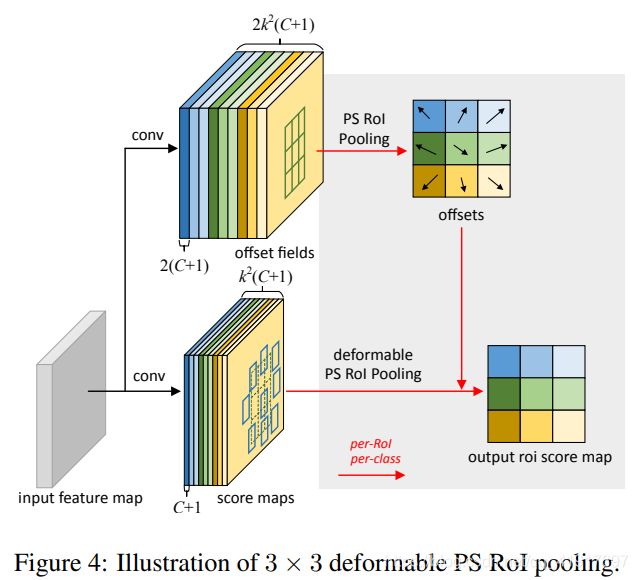
偏移式学习是不同的,如图所示。在顶部分支中,一个conv层生成全空间分辨率偏移字段。对于每个RoI(同样对于每个类别),在这些字段上应用PS RoI池化,得到归一化偏移量∆pbij,然后将其转换为真实偏移量∆pij,方法与上述可变性RoI池化相同。
offset偏移学习
作者采用的是0初始化,然后按照网络其它参数学习率的 β \beta β倍来学习,这个 β \beta β默认是1,但在某些情况下,比如faster rcnn中的fc的那些,是0.01。
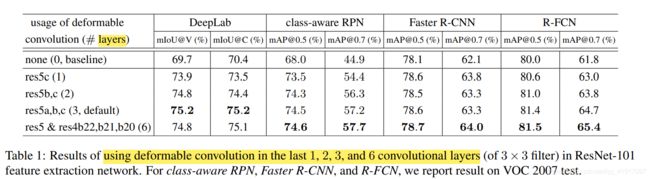
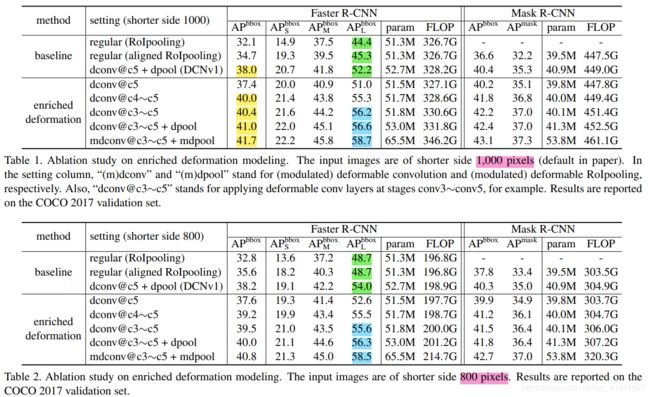
此外,并不是所有的卷积都一股脑地换成可行变卷积就是好的,在提取到一些语义特征后使用形变卷积效果会更好一点,一般来说是网络靠后的几层。下图是在不同层加入可变形卷积所带来的性能提升:
实验效果
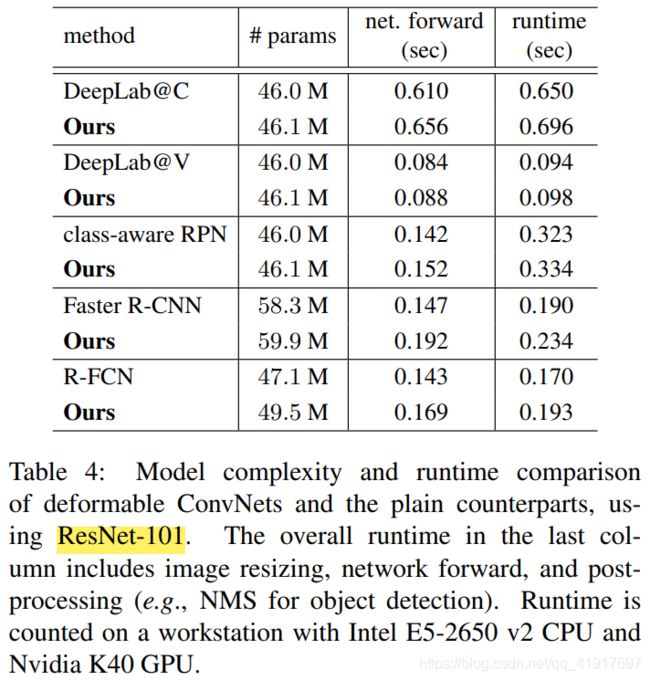
加入DCN,参数量和速度只会略微增加:
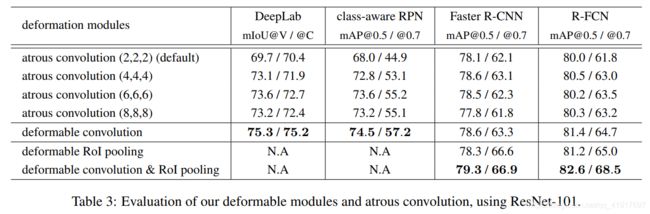
下图是在各项任务中的性能对比:加入可变性卷积或者可变性ROI池化都能带来提升。(Atrous convolution也叫做空洞卷积dilated convolution)
思考
总而言之,卷积改变为类似采样的思路都是很有意义的,但是会存在以下几点需要顾及的地方:是否一层网络真的能有效学习偏置?不同图片的大量不同物体在offset优化上会不会引发竞争什么的(偏置会存在自己的偏好)?
二、Deformable ConvNets v2
本文对V1做了3方面的改进:增加可变形卷积的层数,增加可调节的可变形模块,采用蒸馏的方法模仿RCNN的特征。
Stacking More Deformable Conv Layers
本文题目就是More Deformable, Better Results。v1中使用的ResNet-50,只将conv5中的共3层3x3卷积换成了可变形卷积,本文则将conv3,conv4和conv5中一共12个3x3的卷积层都换成了可变形卷积。v1中发现对于pascal voc这样比较小规模的数据集来说,3层可变形卷积已经足够了。同时错误的变形也许会阻碍一些更有挑战性的benchmark上的探索。作者实验发现在conv3到conv5中使用可变形卷积,对于COCO上的object detection来说,是效率和精度上最好的均衡。△pk,△mk都是通过一个卷积层进行学习,因此卷积层的通道数是3N,其中2N表示△pk,这和DCNv1的内容是一样的,剩下N个通道的输出通过sigmoid层映射成[0,1]范围的值,就得到△mk。
Modulated Deformable Modules
v1仅仅给普通的卷积的采样点加了偏移,v2在此基础上还允许调节每个采样位置或者bin的特征的增益,就是给这个点的特征乘以个系数,如果系数为0,就表示这部分区域的特征对输出没有影响。这样就可以控制有效的感受野。

从实验上来看,增加DConv的数量,提升还是很明显的;但是Modulated Deformable Modules参数量增加很多,而带来的性能提升很微弱。

R-CNN Feature Mimicking
在detection训练过程中,如果有大量不在roi内的内容,可能会影响提取的特征,进而降低最终得到的模型的精度(但不是说没有额外的context就一定不好,加上这里性能提升微弱,所以说这里还是有待更多的思考。)。
对于V2来说,将在RoIpooling中RoI之外的调节系数设为0可以直接去除无关的context,但是实验表明这样还是不能很好的学习RoI的特征,这是由于Faster R-CNN本身的损失函数导致的,因此需要额外的监督信号来改善RoI特征提取的训练。由于,RCNN训练时是裁剪出roi,使用roi进行训练,因此大大减小了无关区域对特征提取的影响。但是如果直接将RCNN引入到fasterRCNN中,会导致训练和测试的时间大大增加。
于是作者采用feature mimicking的手段,强迫Faster R-CNN中的RoI特征能够接近R-CNN提取的特征。引入feature mimic loss,希望网络学到的特征与裁剪后的图像经过RCNN得到的特征是相似的,在这里设置loss如下,采用的是cos相似度评价指标。

网络训练的框架如上图所示,右侧其实就是一个R-CNN,不过后面只接了分类的branch。

还有就是虽然上图画了两个网络,但是R-CNN和Faster R-CNN中相同的模块是共用的相同的参数,比如Modulated Deformable Convolutions和Modulated Deformable RoIpooling部分。inference的时候就只需要运行Faster R-CNN的部分就行了。这样的话,增加的运算量就小了。
思考
看R-CNN Feature Mimicking实验结果:
- 对于前景上的正样本,使用Mimicking是特别有用的,对于负样本背景,网络倾向于利用更多的上下文信息(context),在这种情况下,Mimicking没有帮助。所以FG Only最好
- 在没有mdconv的网络上,使用Mimicking的提升幅度要小一些,只有0.3个点。这里将之前的Modulated Deformable Modules(涨点也少,两个一起使用涨点就稍微明显一些)一起分析:仅仅通过Modulated带来的提升还是比较有限的,主要原因在于现有的损失函数难以监督模型对无关紧要的区域设置较小的权重,因此在模型训练阶段引入RCNN feature mimicking,通过RCNN网络提供有效的监督信息,发挥modulation的权重作用,使得提取到的特征更加集中于有效区域,因此涨点会更加明显。如果对于Modulated Deformable Convolutions能找到一个更好的学习机制,那么我感觉,仅仅是Modulated Deformable Modules也可以带来更好性能提升。

看不同尺度上的一些结果:
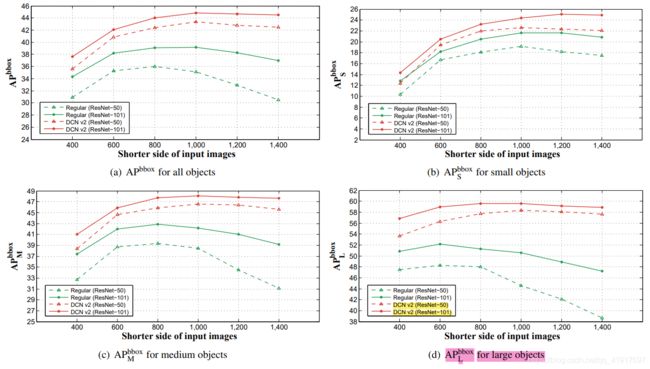
- APL:800 -> 1000 不加可变性卷积(或者是加的不够多的也会掉点,从下表的绿蓝部分可见)都掉点了 [小物体APs涨了],但是 deformable 相关的在涨。分析:把图片调大会等价于减少网络的 receptive field,所以大物体会变得很差。那么这样DCN在调大图片仍然上涨 performance 就合理了,因为毕竟能动态调整感受野。
个人观点,欢迎交流:
按理说多加几层的DCN本应该在V1的时候就应该做实验得到结果,而不应该放在V2的时候说我们多加几层能涨好多点(本篇论文也基本是靠这个涨了很多点),后来看见了其中一个原作者的回答就合理了:

链接:https://www.zhihu.com/question/303900394
modulated 和feature mimicking 涨点都很少,有人会觉得这两项不过是为了发论文而想出来的华而不实的新点子,看起来比较有创新,毕竟涨分靠的是多加几层DConv。但是个人觉得给每个感受野增加增益系数确实是很有创新的,就好比是考虑了信号的相位,接着需要考虑幅度,很自然的想法。但是为什么收益甚微?然而modulated和feature mimicking 一起使用就显出了效果?感觉就是这个增益系数缺少合适的监督信息,训练起来的效果不太好,加入了feature mimicking能提供更多更好的监督信息让增益系数得以学习。
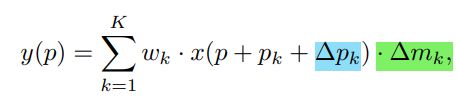
进一步思考一下,怎样才能让卷积更好的学习△mk?从前面可以知道△pk,△mk都是通过一个卷积层进行学习得来的,那么一个卷积层是不是不足以学习如此多的参数了;对于△mk可不可以在学习的时候加入正则化方法,因为一个特征图上需要重点关注的地方是有限的,此外也不能一个地点也不关注;要不要在每个特征图上加入更多的监督,加入增益系数的损失函数
欢迎交流,禁止转载!
上一篇:目标检测之FPN