VIT学习笔记
最近跟着B站大佬学习VIT
详见链接:28、Vision Transformer(ViT)模型原理及PyTorch逐行实现_哔哩哔哩_bilibili
论文地址:An Image is Worth 16x16 Words:Transformers for Image Recognition at Scale
之前的算法大都是保持CNN整体结构不变,在CNN中增加attention模块或者使用attention模块替换CNN中的某些部分。ViT算法中,作者提出没有必要总是依赖于CNN,仅仅使用Transformer结构也能够在图像分类任务中表现很好。
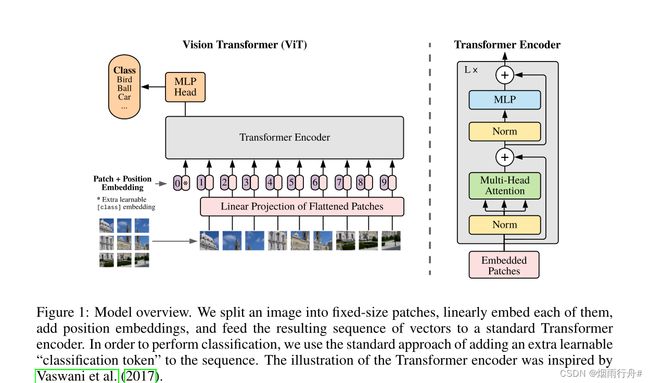
受到NLP领域中Transformer成功应用的启发,ViT算法中尝试将标准的Transformer结构直接应用于图像,并对整个图像分类流程进行最少的修改。具体来讲,ViT算法中,会将整幅图像拆分成小图像块,然后把这些小图像块的线性嵌入序列作为Transformer的输入送入网络,然后使用监督学习的方式进行图像分类的训练。ViT算法的整体结构如 图1 所示。
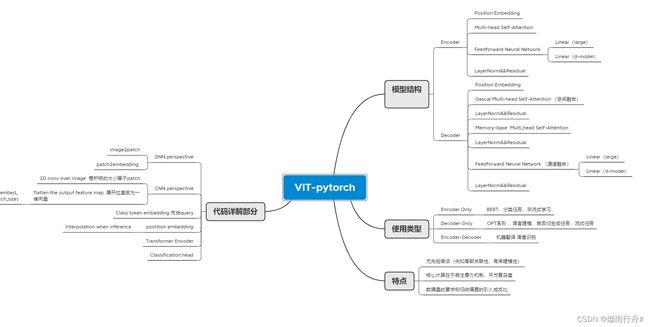
难点和代码总结是大佬写的:
具体代码实现如下所示。其中,使用了卷积和patch分割来代替对每个大小为 8*8 图像块展平后使用全连接进行运算的过程
from torch import nn
import torch
import torch.nn.functional as F
## stage 1 图片变成patch,在转换为enmbedding
def img2emb_naive(image,patch_size,weight):
patch=F.unfold(image,kernel_size=patch_size,stride=patch_size).transpose(-1,-2)
# print(patch.shape)
patch_embedding= patch @ weight
return patch_embedding
def img2emb_conv(image,kernel,stride):
conv_output=F.conv2d(image,kernel,stride=stride)
bs,oc,oh,ow=conv_output.shape
patch_embedding= conv_output.reshape(( bs,oc,oh*ow)).transpose(-1,-2)
return patch_embedding
bs , ic, image_h, image_w =1,3,8,8
patch_size=4
model_dim=8
max_num_token=16
num_classes=10
label=torch.randint(10,(bs,))
patch_depth=patch_size*patch_size*ic
image=torch.randn(bs , ic, image_h, image_w)
#weight
weight = torch.randn(patch_depth,model_dim) #model_dim输出通道数目
# print(weight.shape)
patch_embedding_navie=img2emb_naive(image,patch_size,weight)
kernel=weight.transpose(0,1).reshape((-1,ic,patch_size,patch_size)) #oc用-1表示
patch_embedding_conv=img2emb_conv(image,kernel,patch_size)
# print(patch_embedding_conv)
# print(patch_embedding_navie)
### 4 是数目的数目 48 patch_depth 1是bs
# stage2 加入可学习的cls token embediding
cls_token_embedding=torch.randn(bs,1,model_dim,requires_grad= True)# requires_grad=Ture 加入可学习的cls token embediding
token_embedding=torch.cat([cls_token_embedding,patch_embedding_conv],dim=1)
#stage3 增加位置编码
position_embedding_table =torch.randn(max_num_token,model_dim,requires_grad= True)#3requires_grad=Ture 可训练的
seq_len=token_embedding.shape[1]
position_embedding=torch.tile(position_embedding_table[:seq_len],[token_embedding.shape[0],1,1])
token_embedding+=position_embedding
##stage4 输入Encoder
encoder_layer = nn.TransformerEncoderLayer(d_model=model_dim,nhead=8)
transformer_encoder=nn.TransformerEncoder(encoder_layer,num_layers=6)
encoder_output = transformer_encoder(token_embedding)
## stage 5 分类
cls_token_output=encoder_output[:,0,:]
linear_layer=nn.Linear(model_dim,num_classes)
logits = linear_layer(cls_token_output)
loss_fn=nn.CrossEntropyLoss()
loss=loss_fn(logits,label)
print(loss)本次实现是参考大佬的思想写的,根据模块书写,与原文还是有很大差异。不过新手还是先了解框架再进行进一步的代码编写,感觉大佬的思维导图很清晰,希望大家多多跟着大佬学习。
本文仅供学习参考使用,不做任何经济活动,侵权删除。