数模混合仿真
SPICE模型
参考:做电路仿真必须知道什么是SPICE模型!
如今,每一天都有不知其数的半导体芯片设计公司与设计验证工程师,在用着电路仿真软件SPICE。SPICE广泛应用在仿真模拟电路(例如运放OpAmp,能隙基准稳压电源BandgapReference,数模/模数转换AD/DA等),混合信号电路(例如锁相环PLL,存储器SRAM/dRAM,高速输入/输出接口high-speedI/O),精确数字电路(例如延时,时序,功耗,漏电流等),建立SoC的时序及功耗单元库,分析系统级的信号完整性,等等。作为最早的电子设计自动化软件,它今天仍然是最重要的软件之一。可以说,没有SPICE,就没有电子设计自动化这个产业,也就没有今天的半导体工业。它的市场超过上亿美元。所有这一切,都是从1970年加州大学伯克利分校电机工程系的一堂课开始的。
spice的诞生-1970s
1970年,在加州大学伯克利分校电机工程与计算机科学系(UCBerkeley , Dept. EECS),Ron Rohrer教授给七个研究生上“电路综合”课。Rohrer教授那时刚刚从仙童半导体公司(Fairchild Semiconductor)返回伯克利,没有时间准备教材。所以,在第一堂课,他就宣布:学生们一起写一个电路仿真程序。他跟系里的管教学的主任DonPeterson教授达成一个协议:只要Peterson教授认可学生们写的仿真程序,他们就全部通过。否则的话,他们就全部不及格。这七个学生中有一个还是从机械系来的。他感到十分委屈:教授啊,俺啥电路都不会,俺就是来学电路的。这倒好,电路没学到,反而要去写电路仿真程序。这可咋办啊?Rohrer教授想了想,说没关系。虽然电路你不懂,但你的数值分析不是很厉害吗?OK,你就负责解方程这块吧。最后的结果证明了恰恰是学生们自己开发的解稀疏矩阵的模块是一个亮点,它使得可处理的电路规模成倍的增大。为什么这么说呢?如果你学过数值方法,你就知道一般解方程组用的是高斯消元法。它的复杂度是O(n^3)。也就是说,电路规模增大一倍,你的运算时间就要增大到8倍。当时的电路仿真程序最多可以仿真10个晶体管。超过这个数,不是你的预算被烧没了,就是你的耐心被耗没了。但是,学生们注意到从电路搭出来的矩阵有个特点,就是它的稀疏性。一个电路矩阵里很多元素都是0(意味着两个电路节点之间没有连接关系)。既然是0,那就没有必要去存储和计算它了。这样一来,存储量和计算量大大减少了(是啊,连小学生都知道任何数乘0还是0。你没事儿就别搞一大堆乘0的运算了)。
很多SPICE里面的基本要素都来自于Rohrer教授指导的这一堂电路分析课的项目,包括上面讲到的解稀疏矩阵的模块,还有隐式积分算法的使用使得瞬态分析更加稳定。并且,程序里加入了自带的半导体器件模型,用户只需要给出一组模型参数,用不着自己提供器件模型的FORTRAN模块了。
(美国著名的计算机先驱人物约翰·巴克斯开发出了第一种高级编程语言Fortran,(1954)为现代软件开发奠定了基础。)
这七个学生推举LaurenceNagel为代表,由他负责向Peterson教授汇报结果。这个结果就是CANCER。没错,它的意思就是“癌症”。它是“不包括辐射的非线性电路计算机分析”(”ComputerAnalysis of Nonlinear Circuits, Excluding Radiation”)的缩写。不要忘了,这是在一个叛逆的时代。当时绝大部分的电路分析软件来自于大公司与政府/军方的合同开发。在冷战和核威胁的环境下,政府/军方要求这些软件都具有分析电路抗核辐射的能力。伯克利是反战的大本营,学生们自己开发的程序当然要跟政府/军方的要求对着干了。
有同学可能会问:为什么要开发一个电路仿真程序?呵呵,要知道在这之前,人们分析电路,要么是用笔和纸,要么就要搭电路板(breadboard)。Peterson教授就被学生们称之为“信封教授”,因为他认为电路分析用个信封的背面来做就足够了。但随着电路规模的增大,用笔纸变得越来越不可能,搭电路板又不能精确反应芯片上的电路特性,而且费用也越来越高。因此,用软件来做电路仿真就变得日益迫切了。
当课程结束,Nagel向Peterson教授汇报CANCER之后,Peterson教授给予了全心的认可。学生们都通过了!CANCER成了Nagel的硕士论文课题。它在伯克利被很多本科生及研究生使用,并且给了大量的建议去改进它。呵呵,都说学生是最好的“小白鼠”,这话果然不假(再插一段话:基于这堂课的巨大成功,Rohrer教授后来又用同样的办法试了几堂课,但都失败了。他自己总结说,是因为有Nagel,伯克利的那堂课才成功了。所以,如果没有Rohrer教授那样的功力和Nagel那样天分的学生,SPICE也不可能从一堂课里诞生出来。)
到了1971年的秋天,Nagel在伯克利又开始了他的博士生生活,这一回是在Peterson教授的指导下了。(在这之前,Rohrer教授离开了伯克利到工业界去发展。原因嘛,据说Rohrer教授与Peterson教授在是否要公开CANCER的源代码上有不同意见。Rohrer教授后来又回到了学术界,在卡内基-梅隆大学(CMU)做教授,并指导开发了AWE,这是后话。)
Peterson教授给Nagel的第一个任务是给程序起个新名字。确实,CANCER太难听了,谁都不喜欢。Nagel花了天知道多长时间才想出来这样好听的,也是我们现在还在用的名字:SPICE(SimulationProgram with Integrated Circuit Emphasis)。(所以,同学,如果你要写一个新程序,创建一个新公司,生一个小孩,一定要给她/他起个好听的名字。)1971年被正式认定为SPICE诞生的年份。
SPICE还是开源代码的先驱。当时也有开源代码,但都没有太大的商业价值。SPICE就不同了。有人已经看到它的商业价值,但Peterson教授坚持要把代码开源(我们都得真心的感谢Peterson教授)。任何人只要花20美元的手续费,就可以得到SPICE的源代码(当然,在冷战时期,SPICE被禁止出口到政府认为的“共产国家“)。有人会问,那这样一来,伯克利是不是损失了一大笔钱呢?事实并非如此。伯克利的SPICE帮助数字设备公司(DEC)卖出了很多台VAX机。反过来,DEC给伯克利电子系捐赠了一千八百万美元(这可是二十年前的数目,考虑到通货膨胀,你可以想象现在值多少钱)。这么多钱可不是一个学校卖代码能获得的。所以,做好事终究还是会得到好报的。
spice2 &spice3
在70年代初期,伯克利电子系用的计算机是CDC6400大型机,它的运算能力相当于286(它的时钟频率是10兆赫,可它的成本是六百万美元。再看看今天你手中的iPhone,它的时钟频率超过1000兆赫,成本不到六百美元–这是一百万倍性价比的差别!)分给每个学生的主内存白天为256K字节。到了晚上人少,你就可得到384K。运行一个不算太大的电路仿真,用Nagel的话来说,就像把你11码大的脚穿进婴儿的鞋里–你得想尽一切办法节省内存。能仿真的最大的电路规模也就是25个双极晶体管(相当于50个电路节点)。而且,那时候SPICE还只有双极晶体管模型。
71年的秋季,从贝尔实验室来到伯克利的DavidHodges教授带来了第一个MOSFET模型:Shichman-Hodges模型。如果你用过SPICE(并且年头足够多的话),你应该知道这就是Level1 MOSFET模型。它是所有MOSFET模型的鼻祖(下面我们还会讲到MOSFET模型的)。
1975年Nagel从伯克利博士毕业。他的论文“SPICE2:A COMPUTER PROGRAM TO SIMULATE SEMICONDUCTOR CIRCUITS”, 成为了EDA行业被引用最多的文章。
论文下载地址:SPICE2-A COMPUTER PROGRAM TO SIMULATE SEMICONDUCTOR CIRCUITS-1975-Nagel
SPICE2这个版本基本上奠定了今天电路仿真程序的基石,其中包括:改进的节点分析法(ModifiedNodal Analysis),稀疏矩阵解法(Sparse Matrix Solver),牛顿-拉夫逊迭代(Newton-RaphsonIteration),隐性数值积分(ImplicitNumerical Integration),动态步长的瞬态分析(Dynamic Time Step Control),局部截断误差(LocalTruncation Error),等等-- 说太多技术细节了,还是接着讲故事吧。
Nagel毕业后去了贝尔实验室。从此以后,SPICE2的改进就由Nagel的室友,EllisCohen,继续进行下去。Ellis是个计算机编程能手。用当时周围学生的话说,他就是一个长成人形的计算机。是他(以及后来的AndreiVladimirescu和Sally Liu)把学校里开发的程序SPICE改造成了实用的SPICE2G6。在SPICE的早期开发中,他是个无名英雄。今天工业界里的很多商业SPICE就是基于SPICE2G6开发出来的。
这是Nagel博士论文的封面。
如果你想了解SPICE的核心秘密,就下载一份好好读读吧!
最早的SPICE2没有用户界面。它的运行是批处理方式。也就是说,你准备好了你的电路描述和仿真命令,就把它们提交给主机系统里。然后呢?然后你就可以下班回家了(多好啊)。因为你的几十个(或几百个)同事也在做着同样的事。这就好像在一个银行里只有一个办事员(主机),而有几百个顾客(提交的仿真任务)排着队。这个办事员动作又慢(286的速度)。所以,等第二天早上上了班再看结果吧!(下面在讲HSPICE时我们还会讲到这个情况)。
SPICE2的输入是用打卡。你可能会问:什么是打卡啊?呵呵,祝贺你年纪够小。对那些年过半百的人,最初接触到的计算机输入界面就是像下面这样的卡:

你把你的电路描述及仿真命令打在一叠这样的卡上,然后放到读卡机里。你可能听说过SPICE的输入叫“SPICE DECK”,这个名字就是从这叠卡来的。
SPICE2的输出是行打印机。是的,就是用下面这样的打印机打出仿真结果在纸上(想象一下那时消耗了多少纸张)。
你也可以打印输入输出的信号波形。每个波形是用不同的字符画的。像下面这样(看着是不是很粗糙啊):

有同学读SPICE手册时会看到一个奇怪的选择项叫”NOPAGE“。这是因为SPICE的输出在页与页之间的折线处会加入一个分页符,留出空白。这个选项就是要求不要停止打印的。这样一来,波形就不会因为换页而在页与页之间断掉了。随着行打印机的消失,这个选择项也进入了历史。呵呵,如果有谁知道这个选项,那他的“年龄”至少在40岁以上。
后来SPICE2的输入/出也进化成了文件输入/出,像下面这样:

到了八十年代,SPICE2已经遍及了各个大学。但它的问题也显现出来:FORTRAN代码太难维护,加新的器件模型需要改动的地方太多,等等。在此同时,C作为一种新的程序语言正方兴未艾。于是,用C语言重新写SPICE就被提到了议事日程上来。这个任务被伯克利的Thomas
Quarles在89年的时候完成了。比起SPICE2来,SPICE3增加了用户界面,你可以使用命令,甚至命令串来控制程序。另外,还增加了图形界面看波形。更重要的是,SPICE3的程序构架更加清晰,更加模块化。维护及修改起来更加容易。八十年代也是计算机硬件突飞猛进的时代:大型机(mainframe)被工作站(workstation)取代。UNIX及架构在它上面的C-shell和X-window成为软件开发及应用的基本框架。另外,个人电脑(PC)也越来越普及。这些都为SPICE的广泛应用打下了坚实的基础(下面我们讲商业SPICE时会提到)。
下面是SPICE3(版本3f5)的执行语句,注意它是交互式的。每一个“Spice->”后面是一个Spice3的命令。比如“source”就是把电路读入,“run”就是运行,”display”就是显示,”quit”就是退出。
C语言-spice3-1980s
C语言诞生于美国的贝尔实验室,由丹尼斯·里奇(Dennis MacAlistair Ritchie)以肯·汤普森(Kenneth Lane Thompson)设计的B语言为基础发展而来,在它的主体设计完成后,汤普森和里奇用它完全重写了UNIX,且随着UNIX的发展,c语言也得到了不断的完善。为了利于C语言的全面推广,许多专家学者和硬件厂商联合组成了C语言标准委员会,并在之后的1989年,诞生了第一个完备的C标准,简称“C89”,也就是“ANSI C”,截至2020年,最新的C语言标准为2018年6月发布的“C18”。
C语言之所以命名为C,是因为C语言源自Ken Thompson发明的B语言,而B语言则源自BCPL语言。
1967年,剑桥大学的Martin Richards对CPL语言进行了简化,于是产生了BCPL(Basic Combined Programming Language)语言。
20世纪60年代,美国AT&T公司贝尔实验室(AT&T Bell Laboratories)的研究员肯·汤普森(Kenneth Lane Thompson)闲来无事,手痒难耐,想玩一个他自己编的,模拟在太阳系航行的电子游戏——Space Travel。他背着老板,找到了台空闲的小型计算机——PDP-7。但这台电脑没有操作系统,而游戏必须使用操作系统的一些功能,于是他着手为PDP-7开发操作系统。后来,这个操作系统被命名为——UNICS(Uniplexed Information and Computing Service)。
1969年,美国贝尔实验室的Ken Thompson,以BCPL语言为基础,设计出很简单且很接近硬件的B语言(取BCPL的首字母),并且用B语言写了初版UNIX操作系统(叫UNICS)。
1971年,同样酷爱Space Travel的丹尼斯·里奇为了能早点儿玩上游戏,加入了汤普森的开发项目,合作开发UNIX。他的主要工作是改造B语言,使其更成熟。 [6]
1972年,美国贝尔实验室的丹尼斯·里奇在B语言的基础上最终设计出了一种新的语言,他取了BCPL的第二个字母作为这种语言的名字,这就是C语言。
1973年初,C语言的主体完成。汤普森和里奇迫不及待地开始用它完全重写了UNIX。此时,编程的乐趣使他们已经完全忘记了那个“Space Travel”,一门心思地投入到了UNIX和C语言的开发中。随着UNIX的发展,C语言自身也在不断地完善。直到2020年,各种版本的UNIX内核和周边工具仍然使用C语言作为最主要的开发语言,其中还有不少继承汤普逊和里奇之手的代码。 [6]
在开发中,他们还考虑把UNIX移植到其他类型的计算机上使用。C语言强大的移植性(Portability)在此显现。机器语言和汇编语言都不具有移植性,为x86开发的程序,不可能在Alpha、SPARC和ARM等机器上运行。而C语言程序则可以使用在任意架构的处理器上,只要那种架构的处理器具有对应的C语言编译器和库,然后将C源代码编译、连接成目标二进制文件之后即可在哪种架构的处理器运行。 [6]
1977年,丹尼斯·里奇发表了不依赖于具体机器系统的C语言编译文本《可移植的C语言编译程序》。
C语言继续发展,在1982年,很多有识之士和美国国家标准协会(ANSI)为了使C语言健康地发展下去,决定成立C标准委员会,建立C语言的标准。委员会由硬件厂商、编译器及其他软件工具生产商、软件设计师、顾问、学术界人士、C语言作者和应用程序员组成。1989年,ANSI发布了第一个完整的C语言标准——ANSI X3.159-1989,简称“C89”,不过人们也习惯称其为“ANSI C”。C89在1990年被国际标准化组织(International Standard Organization,ISO)一字不改地采纳,ISO官方给予的名称为:ISO/IEC 9899,所以ISO/IEC9899:1990也通常被简称为“C90”。1999年,在做了一些必要的修正和完善后,ISO发布了新的C语言标准,命名为ISO/IEC 9899:1999,简称“C99”。 [6] 在2011年12月8日,ISO又正式发布了新的标准,称为ISO/IEC9899:2011,简称为“C11”。
于是,用C语言重新写SPICE就被提到了议事日程上来。这个任务被伯克利的ThomasQuarles在89年的时候完成了。
电路仿真的性能与收敛问题分析-1989-Quarles
比起SPICE2来,SPICE3增加了用户界面,你可以使用命令,甚至命令串来控制程序。另外,还增加了图形界面看波形。更重要的是,SPICE3的程序构架更加清晰,更加模块化。维护及修改起来更加容易。八十年代也是计算机硬件突飞猛进的时代:大型机(mainframe)被工作站(workstation)取代。UNIX及架构在它上面的C-shell和X-window成为软件开发及应用的基本框架。另外,个人电脑(PC)也越来越普及。这些都为SPICE的广泛应用打下了坚实的基础(下面我们讲商业SPICE时会提到)。
下面是SPICE3(版本3f5)的执行语句,注意它是交互式的。每一个“Spice->”后面是一个Spice3的命令。比如“source”就是把电路读入,“run”就是运行,”display”就是显示,”quit”就是退出。

SPICE3自带了一个图形模块nutmeg。下面是nutmeg显示的波形,是不是比SPICE2的行打印的字符波形好看多了?

器件模型发展-1990s
自从上世纪九十年代后,学术界SPICE的发展基本就停止在SPICE3f5这个版本了。这是不是意味着SPICE停滞不前了呢?非也。至少在两个方向上SPICE还在一直发展:一个是器件模型(特别是MOSFET模型),另一个是商业SPICE程序。(这里值得提一下,有一批SPICE的爱好者及高校把SPICE3f5接过来,并整合了其他几个开源软件(xspice,cider, gss,adms,等),建成了ngspice。Ngspice也在缓慢的进化着,但比起商业SPICE进化的速度慢多了。你可以在sourceforge上找到ngspice。)
SPICE里面自带了很多模型。像无源元件电阻,电容,电感等等,以及有源器件二极管,双极管等。但花样最多的,变化最频繁的,复杂度最高的,当属MOSFET的模型了。这主要是因为从七八十年代以后,MOSFET的工艺因它的低功耗,高集成度而变成了主流。那时候还是个半导体工业百花争鸣的年代。很多半导体公司如雨后春笋般的冒出来(就像现在的社交媒体公司一样)。几乎每一家公司都在工艺及器件上有点自己的绝活,所以集成电路公司大多是个独立器件制造商(IDM)。这就造成了MOSFET的模型也层出不穷。谁家的SPICE支持的MOSFET模型越多,谁的SPICE用户群就越大。这点我们在下面HSPICE的章节中还会提到。
**71年的秋季,从贝尔实验室来到伯克利的DavidHodges教授带来了第一个MOSFET模型:Shichman-Hodges模型。如果你用过SPICE(并且年头足够多的话),你应该知道这就是Level1 MOSFET模型。**它是所有MOSFET模型的鼻祖(下面我们还会讲到MOSFET模型的)。
前面我们说过SPICE2中加上了MOSFET Level1的模型。等到SPICE3出来的时候,里面已经加入了Level2及Level3模型。到了九十年代,又加入了著名的BSIM(BerkeleyShort-channel IGFET Model)模型。
可以这样说,现在所有的foundry用的模型都来自于BSIM家族。为什么在那么多MOSFET模型中,BSIM胜出了呢?
我们知道,SPICE是用来解含有非线性器件的电路方程的。解非线性方程的一个有效方法就是牛顿迭代–把非线性方程在某个点给它线性化,然后逐次逼近最终解。这个过程有点像俩个宇航飞船对接–如果对方的接口在你的左边,你就往左偏一下。如果你偏多了,对方的接口在你的右边了,你就再稍往右偏点,直到最后俩个接口对准锁定。**但这里面有个要求:就是非线性曲线的一阶导数要连续。**如果不连续的话,就好像喝醉酒的人来控制飞船对接,忽左忽右,或者根本就掉过头来,不知东西南北,上下左右了,如何能对接上呢?不幸的是,很多早期的MOSFET模型(包括Level1,2,3)都有这个问题–模型的电流曲线的一阶导在工作区域内不连续。这是因为人为的把器件分成了不同的工作区域(呵呵,如果你是学器件的,你应该知道截止区,线性区,饱和区)。不同区之间能保证电流连续已经不错了,哪还去管它的导数呢!。这样做的后果就像管对接的人喝醉了酒(呵呵),没法瞄准目标,最后导致SPICE不收敛(non-convergence),或时间步长太小(TimeStep Too Small – 这有很大可能也是不收敛造成的)。
早期的BSIM模型还保留了工作区域的观念。但在不同的区域之间加入了平滑过渡曲线,以保证电流曲线及其一阶导的连续性。在它后来的版本中,就彻底抛弃了工作区域的观念–干脆只用一个(连续且可导的)曲线来代表整个工作区域里的特性。这样就从根本上解决了不连续的问题。**BSIM家族中最成功的代表是BSIM3v3(HSPICE中的Level49)和BSIM4v5(HSPICE中的Level54)。从此以后,再也没有其他的模型能出其右。它们俩也是工业界的MOSFET器件模型标准。BSIM3v3跨越了亚微米的工艺(0.3微米至0.13微米,大致从1993年到2000年),BSIM4v5跨越了深亚微米到纳米的工艺(90纳米至20纳米,大致从2002年到2012年)。
你可能会问:这么好的器件模型是谁做的?猜一下–对了,还是伯克利。是伯克利电子系器件模型小组。它的掌门人就是胡正明教授(Prof.Chenmin Hu)。
商业spice的演变
前面我们提到当CANCER出来的时候就有人意识到了它的商业价值。毫无疑问,SPICE的出世必定会有人把它商业化。事实确实如此。八九十年代是商业SPICE出现的高峰期。至少有几十个SPICE的变种冒出来。有的获得了巨大成功,有的毫无声息的消失了,有的还在惨淡经营着。同学,如果你想创业,这里面有太多的经验和教训了。
HSPICE(1078-1996)
先来说说HSPICE,记得我们前面讲过的批处理运行吧。在当时的大公司里,这是电路仿真标准的运行方式,但这么做的效率太低了。设计者需要尽量短的时间看到仿真结果,然后修改电路参数再做仿真。如此多次以达到最佳结果。有俩个孪生兄弟ShawnHailey及KimHailey,当时都在AMD做设计,看到了这里面的问题。与其让几百个客户排队等一个银行柜员,为什么不让每一个客户都有一个柜员呢?问题就是商机。他们决定跳出来开自己的公司。于是78年,Meta-Software成立了,他们把改进的SPICE变种取名为HSPICE(你现在明白了吧,为什么要以H开头?这可是兄弟俩姓的第一个字母啊)。他们把SPICE2从大型机移植到了VAX小型机上,后来又移植到Sun工作站上。就这样,借着计算机硬件改朝换代的东风,越来越多的公司开始使用HSPICE了。直到如今,这个HSPICE成了工业界的”金标准“。只要你做个仿真器,人们一定会跟HSPICE比结果的。而且,在SPICE前面加一个字母成了时尚。到今天,有人开玩笑说A-SPICE一直到Z-SPICE都已经被人用过了(当然,HSPICE仍然是最出名的)。
有人可能会问:要是我当时也把SPICE移植到小型机上,我是不是也可以成功?呵呵,成功的要素有很多,光用一条是远远不够的。比如说用户的反馈就是相当重要的一条。举个例子,HSPICE是第一个把器件模型库卡(.LIB)和结果测量卡(.MEASURE)做进去的。像这样的例子还有很多。这些虽然不是什么革命性的技术创新,但它们很实用,能大大提高用户的使用效率。甚至某些时候,对用户来说,这样的小改进比创新的算法更重要。
前面我们提到了七八十年代有很多的MOSFET器件模型。HSPICE把能拿到的器件模型都收进去了。所以,HSPICE的MOSFET器件模型是最全的(不信的话,你就去拿本HSPICE的MOSFET模型手册读一下–注意,它是一本独立的手册。也就是说,光是它里面的七八十个MOSFET模型就是一本书了)。但这样还不够。Meta还开发了自己的MOSFET模型:Level28。他们跟用户的工艺线紧密联系。在工艺线流片之前,相应的器件模型参数已由芯片加工厂(foundry)提供给芯片设计者了。如果你是设计者,你还能不用它吗?这样做的结果直接导致了HSPICE用户群急速的扩大。就像滚雪球一样,一旦超过了临界质量(criticalmass),它自己就会越滚越大。据Meta-Software的人说,在公司巅峰的时候,他们的销售员就是一台传真机。你只要把传真机号码告诉客户,他们就把订单发来啦(那时候的钱真好赚啊,当然公司里肯定不止一台传真机)。从78年成立到96年这18年期间,公司一共卖出了一万一千多套HSPICE,它的年成长率达到了25-30%。
1996年Meta-Software被Avant!收购。到2001年,Avant!又被Synopsys收购。关于Avant!的故事有很多。这个公司(包括它的头JerryHsu)就像EDA业界的一匹黑马。它的故事足可以写另一个长篇了。这里且按下不表。
Meta-Software兄弟俩中的老大,ShawnHailey,已于2011年去世。在此之前,他把自己的名字改成了AshawnaHailey。(下图就是AshawnaHailey,大家可能会疑问怎么图片会是女的?可以点击最下方到论坛参与讨论获知)
PSPICE(1984-)
PSPICE像HSPICE一样,PSPICE的故事也跟它的名字有关。首先,这第一个字母“P”并不是其创始人的名字。事实上,创始人的名字WolframBlume里根本没有字母“P”。那这字母“P”到底是什么意思呢?对了,它就是PC。PSPICE的发展跟PC的发展是密不可分的。但这并不是PSPICE的初衷。
时间回到1984年,那时WolframBlume从加州理工(CalTech)毕业加入南加州一家半导体公司。工作中,他听到很多抱怨,说公司内部的SPICE速度太慢了。这位老兄也不含糊,立马对其SPICE来了一个详尽的分析。结果发现,大部分时间花在了算MOSFET模型的方程上(记得前面我们讲的MOSFET的复杂性吧)。他一想,如果能用硬件来并行处理这些方程,岂不就可以加快仿真速度了吗(呵呵,又是一个看到商机的主)?**恰恰那个时候英特尔推出了支持硬件并行的8085/8086/8087。说干就干。**这位老哥创立了MicroSim公司。又是在这时,IBM推出了基于Intel芯片的IBM-PC。另一个机会又来了:**只要把SPICE从大型机上移植到PC上就行了。**这事儿比起第一个事儿简单太多了。可是,人们当时认为PC就是个游戏机而已,没人拿它来做什么正经事儿(呵呵,看看现在不还是这样吗?)。所以,这位老哥并没有把这第二件事看得太重,而是集中绝大部分精力和资源去做硬件并行。
当时的IBM-PC有640KB内存。最大的数组只允许64KB内存。而SPICE是用一个巨长的数组 来存储所有的数据。把SPICE的数据放到IBM-PC的结构,用这位老哥的话说,就像把一只鲸鱼塞进一个金鱼缸里。但他们做到了(中间略去他们N个睡不着的工作之夜)。并行硬件的确加快了方程的处理,可他们也快没钱了。这位老兄忽然想到,咱不是把SPICE移植到PC上了吗?咱就先卖着这个软件,用卖它的钱继续开发咱的并行硬件。就这样,PSPICE就开始在PC上出现了。
最初这位老兄想卖硬件加速器的PSPICE版本,可结果恰恰相反,俩年后,纯软件的PSPICE卖出去了一千多套,而硬件加速器只卖了俩套。到这时候,这位老兄也明白了。做硬件吃力不讨好,市场并不需要。他把卖出去的俩套硬件加速器又自己买了回来(当然又半卖半送给人家N套纯软件的版本)。
同学你看,一个高新复杂的技术并不一定会做出一个卖座的产品。反过来,一个貌似简单的技术可能很受市场的欢迎。另外,PSPICE虽然不是赚钱最多的,但它的用户数绝对是最大的(遍及全世界五大洲)。你可以下载一个免费的PSPICE用。当然,只限于十个晶体管。但这对一般学生的学习来讲,大部分情况下已经够用了(想一想当年的大型机也就只能算这么多)。你如果在网上搜一搜,就会发现阿拉伯语(以及其他语言)的PSPICE教材。你如果是在校生的话,很可能也在用PSPICE。
MicroSim1998年被OrCAD收购。OrCAD在2000年又被Cadence收购。
OrCAD是一款非常专业的电路原理图设计软件,该款软件集电原理图绘制、印制电路板设计、数字电路仿真、可编程逻辑器件设计等功能于一身,为广大用户带来精致的电路制作功能,适用于电子工程师设计电路图及相关图表、设计印刷电路板所用的印刷图以及电路的模拟等领域。
Spectre(1995s+Verilog-AMS)
Spectre话说89年,伯克利毕业了最后一批做SPICE研究的学生。其中一个叫KenKundent。Ken非常有才气。他在伯克利的研究成果后来成为了安捷伦的微波仿真软件。同时他的傲气也不小。在加入了Candence后,他看到HSPICE卖的很火,就决定做个新的仿真工具去取代它。这就是Spectre。 据说他用了俩个星期就写出了第一个版本(呵呵,不愧是伯克利SPICE大本营出来的)。**SPECTRE比HSPICE要快俩三倍,还具有更高的精度及更好的收敛性。但它并没能取代HSPICE。为什么呢?一个原因是兼容性。SPECTRE的输入格式跟HSPICE有很大不同。Ken计算机编程的功底很深,他设计的Spectre的输入格式像C语言一样。虽然从计算机语言角度看,Spectre的输入比HSPICE的输入更规范,但SPICE的用户是电路设计者,他们才不管你的语言多么优美,只要好用就行。另外,如果你是个电路设计者,花了几年功夫好不容易才学会了一种语言格式,用它已经写了成百上千个电路网表,而且它们都工作的好好的,为什么要去换成另外一个呢?另外,还有一个更重要的原因,就是用户对HSPICE的信赖。**这种信赖不是一时半会儿就能建立起来的。它是经过几十年,成千上万遍仿真,几百次tapeout(送出去流片)才能形成的。怎么能说换就换呢?
Ken琢磨着,既然更快更好还没办法取代SPICE,那我们就得做点SPICE没有的东西。做什么呢?恰好在九十年代中期,一种标准的设计语言VHDL开始向模拟电路扩展,这就是VHDL-AMS(VHDL的模拟电路及数模混合电路描述语言)。(这里再插一句,最早的数模混合电路描述语言是MAST,它是Analogy公司的仿真器Saber里面使用的。VHDL-AMS是基于欧洲Anacad公司开发的HDL-A语言发展而来的。后来Anacad的仿真器成为Mentor的Eldo)。但当时还没有Verilog的AMS扩展(原因是VHDL主要在欧洲使用。而Verilog主要在美国使用)。Ken就想,好吧,我们也来做个标准的设计语言到Spectre里。这就是Verilog-AMS(Verilog的模拟电路及数模混合电路描述语言)。不过这事儿说起来容易做起来难。首先,既然你是标准,那就要大伙儿都同意。让大伙儿都同意的事是要花时间的,没那么快。其次更重要的,是你要让模拟电路设计者来学习并使用这个语言。 这可是比登天还难的事儿。如果你是一个模拟电路设计者,你想想你在学校的课本上看到的是运放的电路还是它的描述语言?当然是电路了。至少到今天为止,还没有一本模拟电路的教科书是只用描述语言的。你再看看数字电路的教材,几乎全部都是VHDL或Verilog描述语言(呵呵,如果你还用晶体管来设计数字电路,那你的年龄够大了)。另外,当你做模拟设计的时候,你是在搭晶体管电路呢,还是在写描述语言?对模拟电路设计者来说,用语言而不用电路来做设计是不可想象的。反过来,对数字电路设计者来说,用电路而不用语言来做设计也是不可想象的。
Spectre-AMS做出来后,Ken发现当时的感兴趣者寥寥无几(呵呵,这哥儿们专找硬骨头啃)。那怎么办?在公司做产品是要卖钱的。Ken有点儿绝望了。这时,他想到了回去做他在学校做的老本行:射频电路仿真。至少这个功能别的SPICE还没有。他把这个想法告诉了当时Candence的市场经理JimHogan。Jim做了个市场调查。那时射频电路设计市场几乎不存在,只有几家做镓砷电路的算搭点边儿。当Jim把这调查结果告诉Ken,Ken也无可奈何的耸耸肩。Jim对Ken看了好一会儿,说,管它呢,你就做去吧。谁知道这一次却是歪打正着了。九十年代中后期正是无线通信市场腾飞的时候。很多在学校用Spectre-RF的毕业生加入了新的做射频电路芯片的设计公司。这些公司必须要用Spectre-RF做射频仿真。而Spectre-RF是Spectre的一个选项。因此,Spectre也就借着Spectre-RF的东风开始流行起来了。后来,HSPICE和Smart-Spice也跟风在自己的SPICE中加进了RF的选项。这也算是Spectre对SPICE的功能扩展做的贡献吧。
Smart-Spice()
Smart-Spice是Silvaco公司的产品。说到Silvaco,就不得不说它的创始人IvanPesic。Ivan来自黑山共和国(Montenegro欧洲巴尔干半岛的一个小国家)。像所有第三世界国家的穷学生一样,通过自己的勤奋努力来到美国。来美国之后,他先开了一家修车店。直到攒够了钱,才在1984年成立了Silvaco。他有一个儿子。可能是年幼时受了老爸的修车店的熏陶,决定长大了当个汽车修理工。因此学习也不上进。怎么让这小子好好学习呢?简单。有一天,老Ivan把儿子带到了圣荷塞(SanJose,硅谷一大城市)一个最破的修车店的马路对面,对儿子说:你就坐在这儿,看看汽车修理工一天的工作是什么样的。自从那一天结束以后,儿子的学习成绩就全变成A了。
说到IvanPesic,我们还不得不说他打官司的故事。Silvaco的历史上与N家公司打过官司(而且大部分都赢了)。在此我们只讲讲与Meta-Software(后被Avant!并购)的官司。话说八十年代末到九十年代初,Meta-Software和它的HSPICE如日中天,这其中它自己的Level28模型起了重要作用。Silvaco最初的产品是TCAD(TechnologyCAD),并不是SPICE。这时它也准备开发自己的Smart-Spice,但它拿不到HSPICE的Level28模型。怎么办?Silvaco采用了一个瞒天过海的迂回战术。**Silvaco有个不错的模型参数提取软件叫Utmost。**它就找到Meta-Software说,你看,如果把你们的Level28模型公式放到我们的Utmost中,就会有更多的用户用你们的HSPICE。Meta一想也对,就把Level28模型给了Silvaco。没成想,过了二年,Silvaco自己的Smart-Spice出来了,而且里面还带着Level28模型。这下Meta-Software气坏了。就把Silvaco告上了法庭。也就在这个前后,Avant!并购了Meta-Software。但Avant!只看到了HSPICE这只下金蛋的鹅,却忽略了Meta-Software跟Silvaco的官司。也许是因为Avant!恰恰正在和Cadence打着一场更大的官司,从而忽略了这个小案子。不管是什么原因,当法庭开庭要宣判的那一天,Avant!居然没有人出庭。这下法官可气坏了。好啊,竟敢藐视本法庭,来啊,判Avant!输,并赔Silvaco俩千万!本来Silvaco上庭前战战兢兢的,盼望着和解就不错了。这下到好,不光不用和解了,还得了一大笔钱。呵呵,人们都说国外重视知识产权。这种重视其实是来自于众多这样的动不动就成百上千万的官司。所以同学,如果你是学理工出身的,那你不妨去学学法律。如果你是学文科出身的,那你不妨去学学理工。估摸着在不久的将来,国内这样的涉及知识产权的大官司也会越来越多。做为一个懂高科技的律师(或者一个懂知识产权法律的工程师)会很抢手的。
但是,一个公司如果光靠打官司,那也是赢得不了客户的。说实话,Smart-Spice做得还是蛮不错的,价格又便宜。Smart-Spice还是第一个“基于使用时间许可证”(use-timebased license)的工具。这对许多小公司或个人用户是个好消息。如果你没几万美元去买高大上的商业SPICE,或者你就只需跑几次仿真,那就可以最少花十几美元用Smart-Spice完成你要做的事。这就像买车还是租车一样。卖车店能赚钱,租车店也会有很多顾客的。这不也是一个很好的商业模式吗?
IvanPesic于2012年因癌症在日本去世。如今,他本来想当汽车修理工的儿子已经继承了老爸的事业,接替掌管Silvaco了。
Aeolus-AS
我们应该感到骄傲–-这是我们中国本土的SPICE。虽然名字叫起来很拗口。光从名字上也看不出这是SPICE。它是由北京华大九天开发的。至于为什么起这样一个名字,还是请华大的刘总来解答吧(呵呵)。本人并没有用过这个工具。下面的几句话是从华大的网页上摘下来的,也算给他们做个广告吧。“它是新一代高速高精度并行晶体管级电路仿真工具,能够在保持高精度的前提下突破目前验证大规模电路所遇到的容量、速度瓶颈。Aeolus-AS能够处理上千万个元器件规模的设计,仿真速度也比上一代晶体管级电路仿真工具有大幅提升,同时支持多核并行。”
还有一类是工业界但非商业(也就是不拿出来卖的)SPICE。通常它们都是在公司内部开发使用的。一般只有拥有fab的大公司(像Intel,前Infenion,前Motorola,Fujitsu等)才能负担得起一个开发团队。这种公司内部的SPICE基本都会有自己的器件模型。在这里我们就不多说了。
未来发展
SPICE最初是用来做小型电路仿真的。电路中的元器件数也就几十最多到几百个。随着电路规模越做越大,电路种类越来越多,人们会问:SPICE能不能跑得更快一些,能运行的电路更大一些?自然而然的,SPICE的变种就出现了。我们在这儿讲三个方面:第一是快速仿真,第二是数模混合仿真,第三是扩展应用。
先说说快速仿真(fastSPICE)。这也是市场最大,发展最多的一块儿。
因为SPICE是把整个电路放到一个矩阵中来解。人们就想能不能把电路分成小块单独解,然后再把各块之间联接起来,这样不就快了吗?的确,对数字电路,确实可以用分割的方法。因为数字电路的信号是有方向的,我们可以在没有直流通路的地方把它分开(例如在两个串联的反相器中间)。
另外就是数字信号是离散的,我们可以把它分成几段。分的段越大,时间步长也就能越大,需要解的次数就少了(当然结果也就没那么精确了)
。还有就是器件模型。我们前面讲过如今的mosfet模型非常复杂,要花很多时间去算,那能不能把它简化呢?可以。事实证明对数字电路以及数模混合电路(像PLL,memory,serdes)来说,用表格模型(tablemodel)来代替复杂的方程模型是个不错的选择。
通过这些简化,快速仿真可以比原来的SPICE快几十到上百倍,而精度是在SPICE的5-10%之内。
像EPIC的PowerMill(后来成为Synopsys的Nanosim),Anagram的ADM(后来成为Avant!的StarSim),Celestry(后来成为Cadence)的Ultrasim,Nassda(后来成为Synopsys)的HSIM,等等。最近比较流行的是Magma(现在是Synopsys)的Finesim,BDA(现在是Mentor)的AFS,Proplus的Nanospice。

其次来说说数模混合仿真。
当一个系统中既有模拟电路,又有数字电路,人们自然就会想到把SPICE和数字仿真器(如Synopsys的VerilogVCS,Cadence的NC,Mentor的Modelsim)联在一起运行。
SPICE去算模拟电路部分,数字仿真器去算数字电路部分,它们之间用数模/模数转换器(AD/DA)连接。注意这种运行方式跟上面的快速仿真不同。
这样的混合仿真需要两个仿真器。但这样的构架有缺点。主要的问题是数模转换没有一个标准。市面上有很多SPICE以及Verilog仿真工具,每一个工具的转换界面都不一样,这就造成混合仿真的界面非常复杂。因此,最近发展的混合仿真都采用数模一体化的构架,大大简化了转换界面,而且用户只需在一个环境下就可进行混合仿真。
这样的工具有Cadence的Virtuoso-AMS,Synopsys的HSIM-plusHDL,Silvaco的Harmony,华大的Aeolus-ADS等。
最后再来说说SPICE的扩展应用。
虽说SPICE是针对集成电路(IC)开发的,但它的应用已扩展到系统级(systemlevel),主要是电路板(PCB)级的仿真。那系统级仿真与集成电路仿真有何区别呢?它们不都是电路吗?呵呵,没错,它们都是电路,但区别还是蛮大的。主要是它们的规模与尺寸的不同。我们知道,集成电路是集成在芯片上的。
**其器件尺寸现在已做到纳米级。**而系统级的尺寸还在毫米,厘米,甚至米的数量级。学过电磁的同学都知道,当器件的尺寸大于信号波长的时候,就要考虑分布的场效应了。拿一段导线做例子。一段在芯片上的导线,你可以把它看作一个电阻。
而一段电路板上的导线,你就必须用传输线(transmission line)来代表它,否则误差就太大了。如果信号的频率再高,那就要用S参数了(S-parameter)。
由此,电路仿真发展出一大分支,这就是所谓的“信号完整性”工具。像Agilent的ADS,Mentor的HyperLynx,以及 Cadence的OrCAD和Allegro。
从70年代初到如今的四十多年里,SPICE从只能仿真十几个节点/器件到今天可以仿真上百万个节点/器件的电路,这是一个非常惊人的成就。但这个成就的主要原因是摩尔定律。前面我们讲过自从90年代中期,SPICE本身就没有太大的变化了。这怪就怪(不,应该是感谢才对)SPICE的先驱们。他们奠定了一个坚实的基础,使得我们后面的人都没什么可做的了(呵呵,这不是好事吗)。的确,要改变SPICE的基石,例如改进的节点分析法(ModifiedNodal Analysis),稀疏矩阵解法(Sparse Matrix Solver),牛顿-拉夫逊迭代(Newton-RaphsonIteration),隐性数值积分(ImplicitNumerical Integration),等等,确实不容易。说到底,SPICE是一个解非线性常微分方程的工具。你要想从根本上有个革命性的改变,那你还是从数学上着手吧。
SPICE是一个非常通用的工具。虽然集成电路是它的着重点,但我们看到它也被广泛应用到了系统级,电源级,甚至延伸到了不同领域的仿真。我们前面讲到了数模混合(mixed-signal),但它还是在电路的范畴内。可不可以把它扩展到其他领域(mixeddomain/multiple discipline),比如机械,热力,甚至生物领域?答案是可以的。例如,在电路领域中,我们解的是跨过两个节点的电压和通过一个支路电流。而在机械领域中,我们解的是两个点的位置和力。从早期Saber的MAST语言,到现在的工业标准Verilog-AMS和VHDL-AMS都已经支持不同领域的描述。这就给跨领域的仿真带来了可能。虽然Verilog-AMS还没有被模拟电路设计者广泛采用,但它很可能先从另一个地方发扬光大。比如,微机电系统(MEMS)很有可能是下一个大的应用领域。
另外一方面,虽然SPICE可以解很多类型的电路,但它的运算速度也因此受到了制约。每一种电路都有它自己的特点,比如数字电路信号的离散性,存储器(ram)结构的重复性,等等。我们可以在SPICE的基础上,利用这些电路的特点来开发特制的“SPICE”以提高仿真的效率。前面说的快速SPICE仿真工具就属于这一类。它们的通用性不如SPICE,但它们针对某一类电路的仿真效率是非常高的。
最后一方面,我们从SPICE的发展可以清晰得看到,软件的发展是与硬件的发展密不可分的。现在的处理器基本上都是多核,多线程的,新一代的商业SPICE也利用了这些新的处理器架构。最新的图形处理器(GPU)更是达到了上百个核,上万个线程。并行的开发工具像开放计算语言(OpenCL),CUDA也逐渐成熟。高性能计算(HPC)以及云计算也在日益普及。SPICE能否利用这些新的的环境来提高仿真效率呢?呵呵,这个问题就需要你来解答了。
下面的图给出了主要SPICE的发展过程。其中的代号如下:UCB:伯克利,gEDA:GNU EDA,Meta:Meta-Software,SNPS:Synopsys,µSIM:MicroSIM,CDN:Cadence,MENT:Mentor
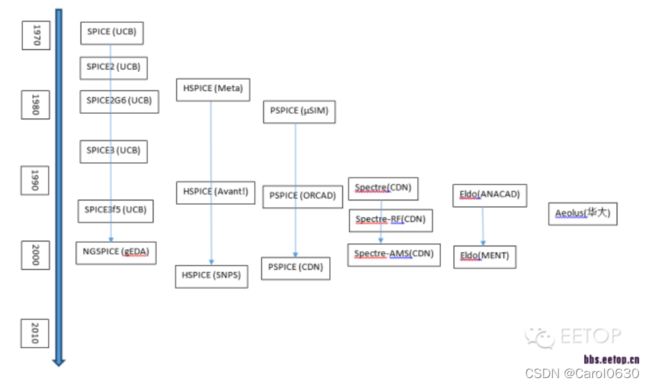
下面的图给出了主要快速仿真工具的发展过程,“+”代表并购。
注意这些快速仿真工具都是商业化的。目前还没有一个开源的快速仿真工具具有像伯克利SPICE那样广泛的影响力。
仿真器
SPICE&FAST SPICE
版上有很多帖子在讨论仿真器之间的差别,现在笼统介绍一下:
spice级仿真工具:hspice,spectre(turbo,aps),finesim_spice,eldo
fast spice仿真工具:synopsys: hsim,XA,nanosim,magma:finesimpro, candence: ultrasim
spice和fast spice之间的区别:
spice是求解全电路方程,不对模型做简化,收敛准则比较严格,一般说来,spectre,finesim等仿真工具比hspice,smartspice等从spice3上衍生过来的工具,检查的准则更严格。一般会检查KCL(基尔霍夫电流守恒),而的spice3上衍生过来的工具不会检查电流守恒。
各个仿真器model差别不大,主要是aps加入节点压缩,将bsim3,bsim4中两个寄生电阻折到沟道里面,因此在做模型扫描测试时会跟spectre,hspice等有差异,一般情况下差别不大,但对某些电路中就不好说了。
各个仿真器差别较大的是步长控制方法,这方面上spectre比较保守,你可以检查计算的时间点数,一般情况下spectre计算的时间点会比hspice要多,hspice一直以来试图通过减少计算时间点数的方法进行加速,最大的风险就是损失计算精度,如果你发现两个工具计算的结果不一致,而且DC值一样的情况下,一般说来hspice精度更差。由于电路存在多个平衡点,如果多个仿真器的结果差别不大也不要惊慌,可以讲其中一个工具的初始值load进来,如果还不一致,一般说来,就可以向其中一家公司报告bug了
fast spice主要使用了事件驱动,同态,查找表模型对仿真进行加速,跟spice不一样的地方,fast spice会使用一些启发式算法,对电路进行切割,讲电路划分为弱耦合的若干个模块,使用事件驱动的方法进行求解,这是跟spice差别很大的地方,简单地说spice会考虑所有的耦合效应,fast spice仅考虑关键的弱耦合效应,甚至不考虑弱耦合效应,通常这种方法会获得比spice一个数量级以上的加速。另一个就是同态技术,对于sram等比较规整的电路仿真速度有大幅提升,同态的意思就是相同结构的模块可以共享一个计算结果,知道某一时刻不能共享为止,因此会节省大量的计算。查找表是预先或者动态的将模型用一个表格来表示,通常比spice的模型计算省3~5倍的计算时间,但有可能损失精度。对于后仿真,有电路往往通过线网耦合在一起,fast spice很难将电路切开,所以在这种情况下,有可能比spice慢,当然精度也没保证。
总而言之,spice比较适合模拟电路等对仿真要求比较高电路,fast spice对于这些的电路的精度是不可预测的
fast spice比较适合数字电路,如sram,rom等对精度要求不高电路
Ultrasim用法
参考:Ultrasim仿真技术-eetop
APS仿真
aps= Advanced Parallel Simulator, 即先进并行仿真,可以利用多核心多线程cpu,进行多线程并行仿真,大大提高仿真速度,提高的速度理论上最高可达到n,n是并发线程的个数。当然这是理论速度,从一些仿真测试来看,达到n/4到n/2的速度提升还是比较靠谱的。
早期的IC平台,仿真器是集成在IC平台里边的,从IC6开始,仿真器从IC平台里边独立出来,叫做MMSIM,包括spectre、AMS、Ultrasim等等。IC514平台也可以调用MMSIM的仿真器,比如spectre等。但是调用aps就会有问题,或者没有aps选项,或者aps功能不全,原因就是此IC平台发布的时候,aps还没有发布。 所以,IC5141的U1~U6在图形界面中都没有aps的选项;IC60~IC613的Base版本也都没有aps选项,IC614 Base版本有aps选项,但只能仿真tran和dc(即使MMSIM本身支持其他仿真)。IC615及其以后的版本,都能在图形界面中完整支持aps。 以上IC514-IC61系列2009年后期到2011年前的版本,包括ISR、hotfix或者update,可以支持在图形界面通过simulator/directory/host菜单切换仿真器来调用aps,但是可能无法调用全部功能;
2011年之后的ISR、hotfix或者update,都能够支持在spectre界面直接调用aps,而无需通过simulator/directory/host菜单切换仿真器,特征就是ADE界面具有Setup->High-performance sumulaiton菜单,打开这个菜单,在选项中点中aps,并在Multithreading options 选项中选中auto,即可开启多线程仿真。如果你的电路规模够大,才会开启多线程,这个时候用top命令,可以看到cpu占有率超过100%,仿真完成的时候,会在outputlog中告诉你,例如 time used cpu=421.26秒,elapsed=119秒,util=354%,第一项是所有cpu为此仿真耗费的cpu时间总和,第二个是实际使用的物理时间,第三个是效率,即第一项除以第二项,告诉你多线程仿真的效率是单线程仿真的3.54倍。
util=time used cpu/elapsed=421.26秒/119秒=354%
当然如果你的电路规模不够,即使打开aps仿真,aps在仿真开始的时候也会很鄙视的告诉你,不给你开启多线程仿真,因为你的电路规模“too small”。传说只有电路中有超过256个threadable的器件的时候,才会开启多进程。注意并非所有的器件都是threadable的。超过256个的非threadable器件,照样开不起来多线程。像一些analogLib和ahdlLib库中的器件,貌似都属于非threadable的,bsim模型,貌似基本都属于threadable的。
Calibre
實習六是介紹一個大部分業界所使用的一套佈局驗證的 軟體―Calibre(為 Mentor 公司之產品),Calibre 是被世界 上大多數的 IC 設計公司做為 sign-off 的憑據,適合做大型電路的驗證。
Calibre 和 Dracula、Diva 有許多不同之處。Calibre 是一套 類似 Diva 的驗證軟體,但其嚴謹度與考靠性遠優於 Diva, 這也是大家為何要使用 Dracula 的原因,但 Dracula 的操作不 易,且無法做 on-line 的驗證。但 Calibre 改進了這些缺點,不 但操作簡易,更可搭配 Virtuoso 或其他 layout 軟體做線上的 驗證,由於 Calibre 的已被大多數的公司所採用,因此 CIC也將轉向支援 Calibre 的技術而漸漸取代 Dracula。
本實習的目的是要將前一實習的電路,經過 Calibre 的 佈局驗證後,以便能將此 Layout 送去製造。而本實習將延續 實習四的 Layout 為實例,藉此介紹整個 Dracula 的操作流程。
数模混合仿真
1.[求助] 请问怎么把DC综合之后的网表转换成spectre的网表,再跟其他模拟电路一起仿真呢
方法有好几种。
数字电路很小,在 Cadence CIW,File - Import - Verilog。 这样其实把Verilog netlist转成了原理图,在ADE里当成模拟电路仿真。
数字电路很大,不可能当成模拟电路仿真,就只能AMS,用现有的AMS设置,加上 -v 把库里标准元的Verilog model文件也装进来,和Verilog网表一起compile, elaborate
自建一个库,专门用来放转成原理图的数字电路。
其他按下图填就可以了
要看你的电路是想导出模拟的网表,还是数字的网表,流程是 不一样的
Reference Libraries 应该填上标准元的 Cadence OA 库。 这个库和 DC 综合用的库是完全两个概念。 Cadence OA 库是可以看到每个标准元的 schematic, layout, symbol view 的。 标准元的 Cadence OA 库要加到工作目录的 cds.lib 里。
Cadence 里有了这个库之后,才能 VerilogIn 网表,import 过程中工具才会把网表中的标准元转成 OA 库中的 symbol view 替代,最后生成 schematic。
 当 ASIC 设计完成了前端逻辑综合并生门级网表后,接下来的任务就是基于门级网表的物理设计,即把门级网表转换为版图(Layout)[37]。
当 ASIC 设计完成了前端逻辑综合并生门级网表后,接下来的任务就是基于门级网表的物理设计,即把门级网表转换为版图(Layout)[37]。
目前使用最广泛的物理设计流程主要有两种方式:一种为展平化设计(Flatten), 另一种为层次化设计(Hierarchical)。在展平化设计中,模块均被打散,所有的标准单元在同一层次上。使用展平化的方式进行物理实现不需要考虑模块间连接关系,通过工具就可以完成自动布局布线。使用此方法设置的约束针对整个设计,无法针对单个模块进行约束。在层次化设计中,物理设计保留着逻辑设计的层次,在布局阶要根
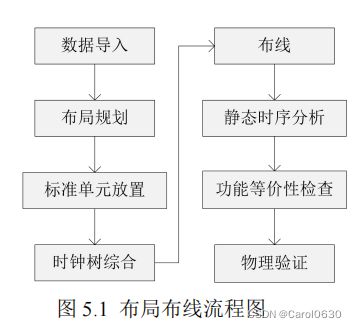
据各个模块的功能和它们间的连接关系,对模块的位置进行规划。此方法不仅要对顶层进行约束设置,要对每个划分的模块进行约束设置,signoff 要求是顶层和模块都需要收敛。展平化和层次化有各自的优缺点,可根据设计师的经验进行选择。在大规模设计中,使用展平化设计,可能会导致设计周期很大,但其优点是无需对子模块设置约束,使用层次化设计方法,需要对每个子模块设置约束,若经验不足,模块划分或约束设置不合理,可能会导致设计无法收敛,需重新划分划分模块、设置约束,这会浪费大量的人力物力,其优点是可以提高设计的并行性,设计被划分多个模块,使得多个设计师可同时进行物理设计,大大减少了设计的周期。对于小规模的设计,层次化设计的优势将大大降低,一般采用展平化设计。使用层次化设计时,划分的子模块使用展平化设计,本文仅介绍展平化设计的流程,大致划分为八个步骤:数据导入、布局规划、标准单元的放置、时钟树综合、布线、静态时序分析、功能等价性检查、物理验证[38]。如图 5.1 布局布线流程。
数据导入[38]:把需要的数据导入到自动布局布线工具中。需要导入的数据有综合后输出的网表和 sdc 约束文件,以及标准单元、宏模块和 I/O 库文件。
布局规划:对模块的形状和面积、pin、宏模块的位置、电源等进行规划,并设置一些标准单元放置的约束。对于一些复杂的设计,需要减少时钟偏差,来提高芯片的性能,因此在布局阶段对时钟网络进行规划,此时的时钟网络是布局规划的一部分。
布局规划有四个目标:确定芯片的面积、确保时序收敛、确保芯片稳定性和满足布线要求。
标准单元的放置:根据布局规划的约束和时序约束,自动布局布线工具进行标准单元放置。
时钟树综合:设计中所有的时序单元都需要时钟来驱动,这会导致时钟的输出端有很多的负载,过多的负载会导致大的延时问题,因此通过插入缓冲单元来解决,这些缓冲单元就构成了时钟树。时钟树一般要多次迭代和优化。
布线:布线在满足工艺规则的条件下,将设计中的 pin、标准单元和宏模块按逻辑关系进行连线。根据设计中的约束,对布线进行优化,来减少布线拥塞、时序优化、消除串扰、降低功耗等。
静态时序分析:在布线完成后,提取互连线的参数,进行时序分析。确保建立时间和保持时间都无违法,才能保证芯片正常工作,此过程一般需要反复迭代。
功能等价性检查[39]:在布局布线时,根据需要可能会修改网表,为了确保修改的网表与原网表逻辑功能的相同,需要做功能等价性检查。
物理验证:主要包括设计规则检查(design rules check, DRC)和电路规则检查(layout versus schematic, LVS)。DRC 主要目的是检查是否有存在设计规则违反,若违反可能在制造过程中出现短路、断路和一些不良的物理效应。LVS 检查版图与设计电路原理图是否一致。
2.[求助] Cadence中怎样从Schematic电路/Layout版图导出Verilog网表?
从layout的话calibre的PEX可以弄出netlist,就是parasitic extraction什么的,另外用ADE L 可以从schematic弄出netlist(没记错的话在Simulation选项下面有个netlist)
但都不是verilog格式的。。
感觉晶体管级的电路没法导成verilog吧……可以导成.sp格式的,用于spice仿真
是不是.cdl或者.db文件?
同问,如何由模拟IP导出.v文件
如果是纯模拟的电路是不可以的。
如果是设计的数字后端标准单元库中的单元呢?比如说反相器,与非门等
Gds 文件不是晶体管级的吗?即便提取出来也只是netlist文件,也还是晶体管级。verilog描述数字电路,导出ncverilog也只是针对数模混合电路的描述语言,和Verilog还是不是一个东西,因此提不出来。来自研一小菜的愚见。
如果是建库,在完成时序信息文件输出后,可继续输出Verilog或者VHDL文件
SignalStorm的话,alf2veri-alf TT.alf-verilog example.v但是elc就不行了,摸索中。。。
3.SOC系统01:软核的获取与仿真
一个SOC系统如下图所示。以软核为中心的soc系统搭建,需要完成软核仿真、FPGA上板验证、外设IP开发、外设挂载与驱动、软硬交互等步骤。这是一个很大的主题,准备用一系列的主题小结记录一点经验。
1.开源核获取
例如ARM架构下的m系列,a系列,可以到官网申请design start版本、eval版本;
或者比较热门的RISC-V架构,如蜂鸟,无剑等软核,可以在github中直接下载
2.仿真平台的搭建
常用的仿真软件,Windows下常用modelsim,Linux下常用questasim,vcs等。
以蜂鸟e203的仿真为例,见https://blog.csdn.net/qq_40946355/article/details/105188993;
一个软核在发布前已经完成相应的验证工作,一般不需要我们额外添加testcase,在相应的EDA工具复现即可。
3.软核需要验证哪些功能
(1)指令集测试
一般会附带在软核的下载包中,用python、makefile脚本集成好,按README说明文件操作即可,例如
(2)指令的写入测试
需要了解指令存储器的位置,在testbench中进行写入指令,并对应读出,完成一个读写回环
integer i;
reg [7:0] itcm_mem [0:31];
initial begin
$readmemh({testcase, “coremark.verilog”}, itcm_mem);
for (i=0;i<32;i=i+1) begin
`ITCM.mem_r[i][00+7:00] = itcm_mem[i*8+0];
`ITCM.mem_r[i][08+7:08] = itcm_mem[i*8+1];
`ITCM.mem_r[i][16+7:16] = itcm_mem[i*8+2];
`ITCM.mem_r[i][24+7:24] = itcm_mem[i*8+3];
end
$display("ITCM 0x00: %h", `ITCM.mem_r[8'h00]);
$display("ITCM 0x01: %h", `ITCM.mem_r[8'h01]);
$display("ITCM 0x02: %h", `ITCM.mem_r[8'h02]);
$display("ITCM 0x03: %h", `ITCM.mem_r[8'h03]);
end
(3)运算功能
查阅指令手册,向指令存储器写入算术运算、逻辑运算、移位等操作指令,输出查看结果。(这一步在软件上调试也可)
(4)外设测试
较常用的spi,uart协议测试,可以有选择地测试
spi与flash的读写相关,程序可能会烧录到flash中,再上载至指令存储器运行;
uart与printf函数相关,也常用于开发板与上位机之间的数据传输。
(5)架构信息
有些寄存器会保存架构信息,版本信息,这些寄存器是可读不可写的,在regfile中查找对应寄存器并输出其预置的置即可;
也可以在程序中使用读寄存器命令,例如read_csr(a0)读取出寄存器a0的值,这类读取函数会以汇编的提前封装好,具体函数名到板级开发包中寻找。
简谈CPU、MCU、FPGA、SoC芯片异同之处_FPGA技术江湖的博客
微处理器系统
微处理器系统,囊括了各种类型的计算机,微控制器/单片机。世界上的微处理器系统的总数比人类总数还多得多。它的基本工作原理是用程序控制系统的行为。
微处理器系统的基本操作过程是中央处理器(Central Processing Unit, CPU)不断地从存储器取指并执行,实现对系统的全面管理。
一、CPU结构和功能CPU的结构(下图为CPU的结构)
- 控制器:完成指令的读入、寄存、译码和执行。
- 寄存器:暂存用于寻址和计算过程的产生的地址和数据。
- I/O控制逻辑:负责CPU中与输入/输出操作有关的逻辑。
- 算数逻辑运算单元(Arithmetic & Logic Unit, ALU):运算器核心,负责进行算术运算、逻辑运算和移位操作,用来进行数值计算和产生存储器访问地址。
CPU的功能:
与存储器之间交换信息。
和I/O设备之间交换信息。
为了使系统正常工作而接收和输出必要的信号,如复位信号、电源、输入时钟脉冲等。
二、微处理器系统的结构(下图为微处理器系统的结构)
CPU的外部特征就是数量有限的输入输出引脚。
| 数据总线 | 用于CPU和存储器或I/O接口之间传送数据,双向通信;数据总线的条数决定了CPU和存储器或I/O设备一次最多能交换数据的位数,是微处理器的位数的判据,例如:Intel 386DX、ARM Cortex-M3是32位微处理器;Intel采用了IA-64架构的处理器、PowerPC 970是64位处理器;类似地,还有更加古老的8位、16位处理器等。 |
| 地址总线 | CPU通过地址总线输出地址码用以选择某一存储单元或某一成为I/O端口的寄存器,单向通信;地址总线的条数决定了地址码的位数,进而决定了存储空间的大小,例如:地址总线宽度(条数)为8,则可以标记2^8 = 256个存储单元,若每个存储单元的字长为8 bit,则最大可以接入系统的存储空间为256kB。 |
| 控制总线 | 用来传送自CPU发出的控制信息或外设送到CPU的状态信息,双向通信; 微处理器系统的程序设计语言:程序设计语言(Programming Language),又称为编程语言,是用来定义计算机程序的,通过代码向处理机发出指令。编程语言让开发者能够准确地提供计算机所使用的数据,并精确地控制在不同情况下所应当采取的行动。最早的编程语言是在计算机发明之后产生的,当时是用来控制提花织布机及自动演奏钢琴的动作。在电脑领域已发明了上千不同的编程语言,而且每年仍有新的编程语言诞生。很多编程语言需要用指令方式说明计算的程序,而有些编程语言则属于声明式编程,说明需要的结果,而不说明如何计算。 |
机器语言:机器语言的每条语句即是处理器可以直接执行的一条指令,这些指令是以二进制0、1序列的形式表示,对应数字集成电路的高低电平。不同的处理器指令的机器代码各不相同,完成的具体功能也将不相同,按一种计算机的机器指令编写的程序,不能在另一种计算机上执行。 示例:(仅作为示例,不代表真实硬件的机器代码)
优点:汇编语句和机器语言一一对应,助记符与标号往往与实际意义相关,相比于机器语言,更加直观,容易理解,执行效率上类似。
缺点:不同的处理器指令集不同,移植性不好;即使完成简单的数据处理(如累加,简单排序等)所需的代码体积很大,处理实际问题所需的工作量夸张,成本高。
高级语言:使用接近于数学语言或人类语言的表达描述程序。
特点:相比于面向机器开发的机器语言和汇编语言,高级语言拥有较高的可读性,并且代码量大大减少;高级语言通常远离对硬件的直接操作,安全性较高,也有部分高级语言可以使用调用汇编语言的接口操控硬件;高级语言有很多成熟、易于使用、可移植的数据结构与算法,使开发流程大大简化,节省开发成本,易于维护;发展迅速,社区完备,可以很方便地求助,解决遇到的各种问题;已经有很多各具特色、用以解决不同领域问题且发展相当完备的高级语言供开发者选用,如:
适合初学者了解编程思想的Basic;
效率颇高,接近于硬件操控,适合系统、硬件驱动编程与嵌入式开发的C/C++;
跨平台、可移植特性优良的Java;
搭配Visual Studio可以快速开发项目的C#.NET;适合于数据分析、人工智能,越来越被青睐的Python;
Microsoft公司为未来的量子计算而开发的Q#,等等。
诸如MATLAB、HTML、JavaScript这样的用以在不同领域大显身手的语言亦可以称之为高级语言。 示例:加法运算。
[原创] 以DAC为例介绍AMS-Design数模混合电路仿真方法(含代码)