面向 Kubernetes 设计误区

Kubernetes 设计模式
![]()
Kubernetes 是一个具有普遍意义的容器编排工具,它提供了一套基于容器构建分布式系统的基础依赖,其意义等同于 Linux 在操作系统中的地位,可以认为是分布式的操作系统。
自定义资源
Kubernetes 提供了 Pod、Service、Volume 等一系列基础资源定义,为了更好提供扩展性,CRD 功能是在 1.7 版本被引入。
用户可以根据自己的需求添加自定义的 Kubernetes 对象资源(CRD)。值得注意的是,这里用户自己添加的 Kubernetes 对象资源都是 native 的都是一等公民,和 Kubernetes 中自带的、原生的那些 Pod、Deployment 是同样的对象资源。在 Kubernetes 的 API Server 看来,它们都是存在于 etcd 中的一等资源。同时,自定义资源和原生内置的资源一样,都可以用 kubectl 来去创建、查看,也享有 RBAC、安全功能。用户可以开发自定义控制器来感知或者操作自定义资源的变化。
Operator
在自定义资源基础上,如何实现自定义资源创建或更新时的逻辑行为,Kubernetes Operator 提供了相应的开发框架。Operator 通过扩展 Kubernetes 定义 Custom Controller,list/watch 对应的自定义资源,在对应资源发生变化时,触发自定义的逻辑。
Operator 开发者可以像使用原生 API 进行应用管理一样,通过声明式的方式定义一组业务应用的期望终态,并且根据业务应用的自身特点进行相应控制器逻辑编写,以此完成对应用运行时刻生命周期的管理并持续维护与期望终态的一致性。

通俗的理解
CRD 是 Kubernetes 标准化的资源扩展能力,以 Java 为例,int、long、Map、Object 是 Java 内置的类,用户可以自定义 Class 实现类的扩展,CRD 就是 Kubernetes 中的自定义类,CR 就是对应类的一个 instance。
Operator 模式 = 自定义类 + 观察者模式,Operator 模式让大家编写 Kubernetes 的扩展变得非常简单快捷,逐渐成为面向 Kubernetes 设计的标准。
Operator 提供了标准化的设计流程:
使用 SDK 创建一个新的 Operator 项目;
通过添加自定义资源(CRD)定义新的资源 API;
指定使用 SDK API 来 watch 的资源;
自定义 Controller 实现 Kubernetes 协调(reconcile)逻辑。
有了锤子,看到的只有钉子
![]()
我们团队(KubeOne 团队)一直在致力于解决复杂中间件应用如何部署到 Kubernetes,自然也是 Operator 模式的践行者。经历了近 2 年的开发,初步解决了中间件在各个环境 Kubernetes 的部署,当前中间也走了很多弯路,踩了很多坑。
KubeOne 内核也经历 3 个大版本的迭代,前 2 次开发过程基本都是 follow Operator 标准开发流程进行开发设计。遵循一个标准的、典型的 Operator 的设计过程,看上去一切都是这么的完美,但是每次设计都非常痛苦,践行 Operator 模式之后,最值得反思和借鉴的就是”有了锤子,看到的只有钉子,简单总结一下就是 4 个一切:
一切设计皆 YAML;
一切皆合一;
一切皆终态;
一切交互皆 cr。
误区1:一切设计皆 YAML
![]()
Kubernetes 的 API 是 YAML 格式,Operator 设计流程也是让大家首先定义 CRD,所以团队开始设计时直接采用了 YAML 格式。
案例
根据标准化流程,团队面向 YAML 设计流程大体如下:
先根据已知的数据初步整理一个大而全的 YAML,做一下初步的分类,例如应用大概包含基础信息,依赖服务,运维逻辑,监控采集等,每个分类做一个子部分。
开会讨论具体的内容是否能满足要求,结果每次开会都难以形成共识。
-
因为总是有新的需求满足不了,在讨论A时,就有人提到 B、C、D,不断有新的需求;
每个部分的属性非常难统一,因为不同的实现属性差异较大;
理解不一致,相同名字但使用时每个人的理解也不同。
由于工期很紧,只能临时妥协,做一个中间态,后面再进一步优化。
后续优化升级,相同的流程再来一遍,还是很难形成共识。
这是第 2 个版本的设计:
apiVersion: apps.mwops.alibaba-inc.com/v1alpha1
kind: AppDefinition
metadata:
labels:
app: "A"
name: A-1.0 //chart-name+chart-version
namespace: kubeone
spec:
appName: A //chart-name
version: 1.0 //chart-version
type: apps.mwops.alibaba-inc.com/v1alpha1.argo-helm
workloadSettings: //注 workloadSettings 标识type应该使用的属性
- name: "deployToK8SName"
value: ""
- name: "deployToNamespace"
value: ${resources:namespace-resource.name}
parameterValues: //注 parameterValues标识业务属性
- name: "enableTenant"
value: "1"
- name: "CPU"
value: "1"
- name: "MEM"
value: "2Gi"
- name: "jvm"
value: "flag;gc"
- name: vip.fileserver-edas.ip
value: ${resources:fileserver_edas.ip}
- name: DB_NAME
valueFromConfigMap:
name: ${resources:rds-resource.cm-name}
expr: ${database}
- name: DB_PASSWORD
valueFromSecret:
name: ${instancename}-rds-secret
expr: ${password}
- name: object-storage-endpoint
value: ${resources:object-storage.endpoint}
- name: object-storage-username
valueFromSecret:
name: ${resources:object-storage.secret-name}
expr: ${username}
- name: object-storage-password
valueFromSecret:
name: ${resources:object-storage.secret-name}
expr: ${password}
- name: redis-endpoint
value: ${resources:redis.endpoint}
- name: redis-password
value: ${resources:redis.password}
resources:
- name: tolerations
type: apps.mwops.alibaba-inc.com/tolerations
parameterValues:
- name: key
value: "sigma.ali/is-ecs"
- name: key
value: "sigma.ali/resource-pool"
- name: namespace-resource
type: apps.mwops.alibaba-inc.com/v1alpha1.namespace
parameterValues:
- name: name
value: edas
- name: fileserver-edas
type: apps.mwops.alibaba-inc.com/v1alpha1.database.vip
parameterValues:
- name: port
value: 21,80,8080,5000
- name: src_port
value: 21,80,8080,5000
- name: type
value: ClusterIP
- name: check_type
value: ""
- name: uri
value: ""
- name: ip
value: ""
- name: test-db
type: apps.mwops.alibaba-inc.com/v1alpha1.database.mysqlha
parameterValues:
- name: name
value: test-db
- name: user
value: test-user
- name: password
value: test-passwd
- name: secret
value: test-db-mysqlha-secret
- name: service-slb
type: apps.mwops.alibaba-inc.com/v1alpha1.slb
mode: post-create
parameterValues:
- name: service
value: "serviceA"
- name: annotations
value: "app:a,version:1.0"
- name: external-ip
value:
- name: service-resource2
type: apps.mwops.alibaba-inc.com/v1alpha1.service
parameterValues:
- name: second-domain
value: edas.console
- name: ports
value: "80:80"
- name: selectors
value: "app:a,version:1.0"
- name: type
value: "loadbalance"
- name: service-dns
type: apps.mwops.alibaba-inc.com/v1alpha1.dns
parameterValues:
- name: domain
value: edas.server.${global:domain}
- name: vip
value: ${resources:service-resource2.EXTERNAL-IP}
- name: dns-resource
type: apps.mwops.alibaba-inc.com/v1alpha1.dns
parameterValues:
- name: domain
value: edas.console.${global:domain}
- name: vip
value: “127.0.0.1”
- name: cni-resource
type: apps.mwops.alibaba-inc.com/v1alpha1.cni
parameterValues:
- name: count
value: 4
- name: ip_list
value:
- name: object-storage
type: apps.mwops.alibaba-inc.com/v1alpha1.objectStorage.minio
parameterValues:
- name: namespace
value: test-ns
- name: username
value: test-user
- name: password
value: test-password
- name: storage-capacity
value: 20Gi
- name: secret-name
value: minio-my-store-access-keys
- name: endpoint
value: minio-instance-external-service
- name: redis
type: apps.mwops.alibaba-inc.com/v1alpha1.database.redis
parameterValues:
- name: cpu
value: 500m
- name: memory
value: 128Mi
- name: password
value: i_am_a_password
- name: storage-capacity
value: 20Gi
- name: endpoint
value: redis-redis-cluster
- name: accesskey
type: apps.mwops.alibaba-inc.com/v1alpha1.accesskey
parameterValues:
- name: name
value: default
- name: userName
value: [email protected]
exposes:
- name: dns
value: ${resources:dns-resource.domain}
- name: db-endpoint
valueFromConfigmap:
name: ${resources:rds-resource.cm-name}
expr: ${endpoint}:3306/${database}
- name: ip_list
value: ${resources:cni-resource.ip_list}
- name: object-storage-endpoint
value: ${resources:object-storage.endpoint}.${resource:namespace-resource.name}
- name: object-storage-username
valueFromSecret:
name: ${resources:object-storage.secret-name}
expr: ${username}
- name: object-storage-password
valueFromSecret:
name: ${resources:object-storage.secret-name}
expr: ${password}
- name: redis-endpoint
value: ${resources:redis.endpoint}.${resource:namespace-resource.name}
- name: redis-password
value: ${resources:redis.password}
反思
这样的痛苦难以用语言表达,感觉一切都脱离了掌控,没有统一的判断标准,设计标准,公说公有理婆说婆有理,内容一直加,字段一直改。事不过三,第三次设计时,我们集体讨论反思为什么这么难形成共识?为什么每个人理解不同?为什么总是在改?
结论很一致,没有面向 YAML 的设计,只有面向对象的设计,设计语言也只有 UML,只有这些历经考验、成熟的设计方法论,才是最简单也是最高效的。
从上面那个一个巨大无比的 YAML 大家可以体会我们设计的复杂,但是这还是不是最痛苦的。最痛苦的是大家抛弃了原有的设计流程及设计语言,试图使用一个开放的 Map 来描述一切。当设计没有对象,也没有关系,只剩下 Map 里一个个属性,也就无所谓对错,也无所谓优劣。最后争来争去,最后不过是再加一个字段,争了一个寂寞。
适用范围
那 Operator 先设计 CRD,再开发 controller 的方式不正确吗?
答案:部分正确。
适用场景:与 Java Class 相同,简单对象不需要经过复杂的设计流程,直接设计 YAML 简单高效。
不适用场景:在设计一个复杂的体系时,例如:应用管理,包含多个对象且对象之间有复杂的关系,有复杂的用户故事,UML 和面向对象的设计就显得非常重要。
设计时只考虑 UML 和领域语言,设计完成后,CRD 可以认为是 Java 的 Class,或者是数据库的表结构,只是最终要实现时的一种选择。而且有很多对象不需要持久化,也不需要通过 Operator 机制触发对应的逻辑,就不需要设计 CRD,而是直接实现一个 controller 即可。
YAML 是接口或 Class 声明的一种格式化表达,常规 YAML 要尽可能小,尽可能职责单一,尽可能抽象。复杂的 YAML 是对简单 CRD 资源的一种编排结果,提供类似一站式资源配套方案。
在第 3 个版本及 PaaS-Core 设计时,我们就采取了如下的流程:
UML 用例图;
梳理用户故事;
基于用户故事对齐 Domain Object,确定关键的业务对象以及对象间关系;
需要 Operator 化的对象,每个对象描述为一个 CRD,当然 CRD 缺乏接口、继承等面向对象的能力,可以通过其他方式曲线表达;
不需要 Operator 化的对象,直接编写 Controller。
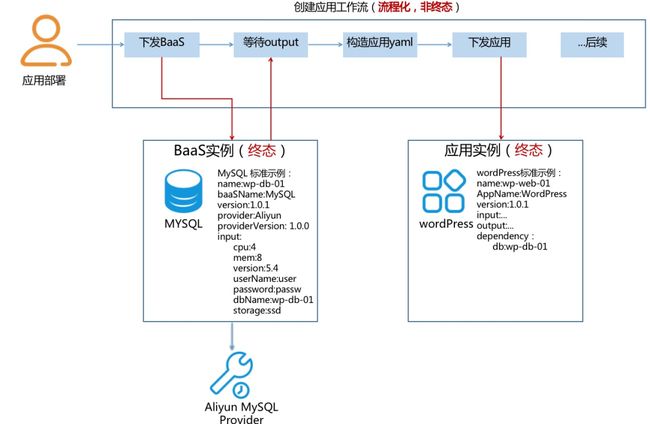
误区2:一切皆合一
![]()
为了保证一个应用的终态,或者为了使用 GitOps 管理一个应用,是否应该把应用相关的内容都放入一个 CRD 或一个 IAC 文件?根据 GitOps 设计,每次变更时需要下发整个文件?
案例
案例1:应用 WordPress,需要依赖一个 MySQL,终态如何定义?
apiVersion: apps.mwops.alibaba-inc.com/v1alpha1
kind: AppDefinition
metadata:
labels:
app: "WordPress"
name: WordPress-1.0 //chart-name+chart-version
namespace: kubeone
spec:
appName: WordPress //chart-name
version: 1.0 //chart-version
type: apps.mwops.alibaba-inc.com/v1alpha1.argo-helm
parameterValues: //注 parameterValues标识业务属性
- name: "enableTenant"
value: "1"
- name: "CPU"
value: "1"
- name: "MEM"
value: "2Gi"
- name: "jvm"
value: "flag;gc"
- name: replicas
value: 3
- name: connectstring
valueFromConfigMap:
name: ${resources:test-db.exposes.connectstring}
expr: ${connectstring}
- name: db_user_name
valueFromSecret:
....
resources:
- name: test-db //创建一个新的DB
type: apps.mwops.alibaba-inc.com/v1alpha1.database.mysqlha
parameterValues:
- name: cpu
value: 2
- name: memory
value: 4G
- name: storage
value: 20Gi
- name: username
value: myusername
- name: password
value: i_am_a_password
- name: dbname
value: wordPress
exposes:
- name: connectstring
- name: username
- name: password
exposes:
- name: dns
value: ...
上方的代码是 wordPress 应用的终态吗?这个文件包含了应用所需要的 DB 的定义和应用的定义,只要一次下发就可以先创建对应的数据库,再把应用拉起。
案例2:每次变更时,直接修改整个 yaml 的部分内容,修改后直接下发到 Kubernetes,引起不必要的变更。例如:要从 3 个节点扩容到 5 个节点,修改上面 YAML 文件的 replicas 之后,需要下发整个 YAML。整个下发的 YAML 经过二次解析成底层的 StatefulSet 或 Deployment,解析逻辑升级后,可能会产生不符合预期的变化,导致所有 Pod 重建。
反思
先回答第一个问题,上方 YAML 文件不是应用的终态,而是一个编排,此编排包含了 DB 的定义和应用的定义。应用的终态只应该包含自己必须的依赖引用,而不包含依赖是如何创建的。因为这个依赖引用可以是新创建的,也可以是一个已有的,也可以是手工填写的,依赖如何创建与应用终态无关。
apiVersion: apps.mwops.alibaba-inc.com/v1alpha1
kind: AppDefinition
metadata:
labels:
app: "WordPress"
name: WordPress-1.0 //chart-name+chart-version
namespace: kubeone
spec:
appName: WordPress //chart-name
version: 1.0 //chart-version
name: WordPress-test
type: apps.mwops.alibaba-inc.com/v1alpha1.argo-helm
parameterValues: //注 parameterValues标识业务属性
- ....
resources:
- name: test-db-secret
value: "wordPress1Secret" //引用已有的secret
exposes:
- name: dns
value: ...
创建一个应用,就不能先创建 db,再创建应用吗?
可以的,多个对象之间依赖是通过编排实现的。编排有单个应用创建的编排,也有一个复杂站点创建的编排。以 Argo 为例:
apiVersion: argoproj.io/v1alpha1
kind: Workflow
metadata:
generateName: wordPress-
spec:
templates:
- name: wordPress
steps:
# 创建db
- - name: wordpress-db
template: wordpress-db
arguments:
parameters: [{name: wordpress-db1}]
# 创建应用
- - name:
template: wordpress
arguments:
parameters: [{db-sercet: wordpress-db1}]
针对第 2 个案例,是否每次交互都需要下发全部完整的 YAML?
答案:
编排是一次性的配置,编排文件下发一次之后,后续操作都是操作单个对象,例如:变更时,只会单独变更 wordPress,或单独变更 wordPressDB,而不会一次性同时变更 2 个对象。
单独变更应用时,是否需要下发整个终态 YAML,这个要根据实际情况进行设计,值得大家思考。后面会提出针对整个应用生命周期状态机的设计,里面有详细的解释。
适用范围
适用场景:CRD 或 IAC 定义时,单个对象的终态只应该包含自身及对依赖的引用。与面向对象的设计相同,我们不应该把所有类的定义都放到一个 Class 里面。
不适用场景:多个对象要一次性创建,并且需要按照顺序创建,存在依赖关系,需要通过编排层实现。
误区3:一切皆终态
![]()
体验了 Kubernetes 的终态化之后,大家在设计时言必称终态,仿佛不能用上终态设计,不下发一个 YAML 声明对象的终态就是落伍,就是上一代的设计。
案例
案例1:应用编排
还是以 WordPress 为例,将 WordPressDB 和 WordPress 放在一起进行部署,先部署 DB,再创建应用。示例 YAML 同上。
案例2:应用发布
应用第一次部署及后续的升级直接下发一个完整的应用 YAML,系统会自动帮你到达终态。但为了能够细粒度控制发布的流程,努力在 Deployment 或 StatefulSet 上下功夫,进行 partition 的控制,试图在终态里增加一点点的交互性。
反思
说到终态,必然要提到命令式、声明式编程,终态其实就是声明式最终的执行结果。我们先回顾一下命令式、终态式编程。
命令式编程
命令式编程的主要思想是关注计算机执行的步骤,即一步一步告诉计算机先做什么再做什么。
比如:如果你想在一个数字集合 collection(变量名)中筛选大于 5 的数字,你需要这样告诉计算机:
第一步,创建一个存储结果的集合变量 results;
第二步,遍历这个数字集合 collection;
第三步,一个一个地判断每个数字是不是大于 5,如果是就将这个数字添加到结果集合变量 results 中。
代码实现如下:
List results = new List();
foreach(var num in collection)
{
if (num > 5)
results.Add(num);
}
很明显,这个样子的代码是很常见的一种,不管你用的是 C、C++ 还是 C#、Java、Javascript、BASIC、Python、Ruby 等,你都可以以这个方式写。
声明式编程
声明式编程是以数据结构的形式来表达程序执行的逻辑。它的主要思想是告诉计算机应该做什么,但不指定具体要怎么做。
SQL 语句就是最明显的一种声明式编程的例子,例如:
SELECT * FROM collection WHERE num > 5
除了 SQL,网页编程中用到的 HTML 和 CSS 也都属于声明式编程。
通过观察声明式编程的代码我们可以发现它有一个特点是它不需要创建变量用来存储数据。
另一个特点是它不包含循环控制的代码如 for, while。
换言之:
命令式编程:命令“机器”如何去做事情(how),这样不管你想要的是什么(what),它都会按照你的命令实现。
声明式编程:告诉“机器”你想要的是什么(what),让机器想出如何去做(how)。
当接口越是在表达“要什么”,就是越声明式;越是在表达“要怎样”,就是越命令式。SQL就是在表达要什么(数据),而不是表达怎么弄出我要的数据,所以它就很“声明式”。
简单的说,接口的表述方式越接近人类语言——词汇的串行连接(一个词汇实际上是一个概念)——就越“声明式”;越接近计算机语言——“顺序+分支+循环”的操作流程——就越“命令式”。
越是声明式,意味着下层要做更多的东西,或者说能力越强,也意味着效率的损失。越是命令式,意味着上层对下层有更多的操作空间,可以按照自己特定的需求要求下层按照某种方式来处理。
简单的讲,Imperative Programming Language(命令式语言)一般都有 control flow, 并且具有可以和其他设备进行交互的能力。而 Declarative Programming language(声明式语言)一般做不到这些。
基于以上的分析,编排或工作流本质是一个流程性控制的过程,一般是一次性的过程,无需强行终态化,而且建站编排执行结束后,不能保持终态,因为后续会根据单个应用进行发布和升级。案例1是一个典型的编排,只是一次性的创建了 2 个对象 DB 和应用的终态。
应用发布其实是通过一个发布单或工作流,控制 2 个不同版本的应用节点和流量的终态化的过程,不应该是应用终态的一部分,而是一个独立的控制流程。

适用范围
声明式或终态设计。
适用场景:无过多交互,无需关注底层实现的场景,即把声明提供给系统后,系统会自动化达到声明所要求的状态,而不需要人为干预。
不适用场景:一次性的流程编排,有频繁交互的控制流程。
命令式和声明式本就是 2 种互补的编程模式,就像有了面向对象之后,有人就鄙视面向过程的编程,现在有了声明式,就开始鄙视命令式编程,那一屋!
误区4:一切交互皆 cr
![]()
因为 Kubernetes 的 API 交互只能通过 YAML,导致大家的设计都以 cr 为中心,所有的交互都设计为下发一个 cr,通过 watch cr 触发对应的逻辑。
案例
调用一个 http 接口或 function,需要下发一个 cr;
应用 crud 都下发完整 cr;
反思
案例1:是否所有的逻辑都需要下发一个 cr?
下发 cr 其实做了比较多的事情,流程很长,效率并不高,流程如下:
通过 API 传入 cr,cr 保存到 etcd;
触发 informer;
controller 接收到对应的事件,触发逻辑;
更新 cr 状态;
清理 cr,否则会占用 etcd 存储;

如果需要频繁的调用对应的接口,尽量通过 SDK 直接调用。
案例2
Kubernetes 对 YAML 操作命令有 create、apply、patch、delete、get 等,但一个应用的生命周期状态机不只是这几个命令可以涵盖,我们比较一下应用状态机(上)和 YAML 状态机(下):
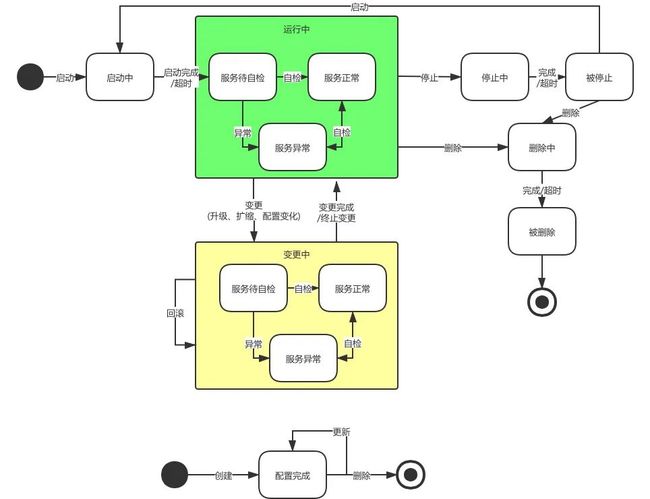
不同的有状态应用,在收到不同的指令,需要触发不同的逻辑,例如:MQ 在收到 stop 指令时,需要先停写,检查数据是否消费完成。如果只是通过 YAML 状态机是无法涵盖应用状态机相关的 event,所以我们必须打破下发 cr 的模式。对于应用来说,理想的交互方式是通过 event driven 应用状态机的变化,状态发生变换时触发对应的逻辑。
适用范围
适用场景:需要持久化,保持终态的数据。
不适用场景:
高频的服务调用,无需持久化的数据。
复杂状态机的驱动。
总结
![]()
Kubernetes 给我们打开了一扇门,带给了我们很多优秀的设计,优秀的理念,但是这些设计和理念也是有自己的适用的场景,并不是放之四海而皆准。我们不应该盲从,试图一切都要 follow Kubernetes 的设计和规则,而抛弃之前的优秀设计理念。
软件设计经历了 10 多年的发展,形成了一套行之有效的设计方法论,Kubernetes 也是在这些设计方法论的支持下设计出来的。取其精华去其糟粕,是我们程序员应该做的事情。
文章来源:阿里巴巴中间件,点击查看原文。
Kubernetes线下培训
![]()
本次培训在上海开班,基于最新考纲,通过线下授课、考题解读、模拟演练等方式,帮助学员快速掌握Kubernetes的理论知识和专业技能,并针对考试做特别强化训练,让学员能从容面对CKA认证考试,使学员既能掌握Kubernetes相关知识,又能通过CKA认证考试,学员可多次参加培训,直到通过认证。点击下方图片或者阅读原文链接查看详情。
