小白理解Kubernetes系列
初识Kubernetes
从本篇文章开始,记录Kubernetes的内容,Kubernetes相关的知识点包括十三个部分,分别是前世今生、组件说明、Pod概念、网络通讯方式、集群安装、资源清单、资源控制器、Service、存储、集群调度、集群安全机制、Helm、高可用。
本篇文章记录Kubernetes的前世今生、组件说明、Pod概念、网络通讯方式、集群安装五个部分的内容。
1. 前世今生
1.1. What is kubernetes?
Kubernetes简称K8s,因k和s之间有8个字母而得名。我们在学校学过,提供服务的几种分层结构有Iaas、Paas、Saas等,阿里云就是国内比较具有分量的Iaas平台之一;新浪云是国内较常用的Paas平台,号称免运维的云平台;我们比较常用的Office365就是Saas的一种,当我们想要使用Office套件时,不需要再经过长时间的安装,只需要访问B/S架构的平台去请求指定服务即可。
国内典型的Paas平台是新浪云,曾声称免运维的云平台,可以直接申请云平台去运行JAVA或PHP项目。最原始的Paas模式非常简单,用户下单申请一个云平台,平台官方在将任务指定给某个具体的运维人员;后来出现了一些运维工具,可以实现自动化帮我们完成一些环境的创建,但是这种工具离真正的自动化还有很远的距离;直到有一家名为Dotcloud的公司出现,主要提供Paas服务,旨在自动的去构建特定运行环境的封装体,也就是后来的Docker,于是Docker便成为Paas下一代的标准。
如果我想要搭建一个集群,包括多台nginx、tomcat、mysql等就会产生一定问题。Docker进行端口转换时,进行了一个DNet的转换,也就是需要防火墙去实现数据包转发,效率异常低下;同时,一台物理机上有可能装多台Docker,此时端口映射会非常杂乱。因此,有没有一个好的容器集群化方案?这个方案称为资源管理器,Kubernetes就是其中的一种。
1.2. Why kubernetes?
提及资源管理器,映入眼帘的是Apache的MESOS,它是Apache下开源的分布式资源管理框架,也被称为分布式系统的内核,曾被Twitter作为基础平台而盛行。直到2019年5月,Twitter宣布停止使用MESOS,改用Kubernetes,至此MESOS英雄迟暮。后来MESOS推出的版本,可以在自己平台上管理Kubernetes,效果未知。
另一个值得一提的资源管理器是Docker Swarm,提供Docker集群管理化方案。新版本的Docker已经将Swarm集成到Docker内部,使用docker swarm init即可创建一个docker 集群,在老版本中需要附加一些类似etcd的组件才可以实现。Docke Swarm非常轻量化,作为集群管理器只有几十兆的开销,那为什么不使用Docker Swarm,而是使用Kubernetes呢?原因就是,Docker Swarm相对于企业级应用来说,功能还是不够丰富。比如,想要实现一个滚动更新,回滚操作,需要手动定义操作流程。
众所周知,Goggle的borg资源管理器拥有10年的运行经验,很多公司可望不可及,而Google声明并不对外提供服务。随着Docker等技术的兴起,Google采用Go语言对Borg进行了重新编写,并开源给容器基金会,Kubernetes应运而生!
1.3. How kubernetes Works?
Kubernetes从资源消耗、开源、弹性伸缩、负载均衡等几个方面,着手设计和改进,成为其迅速流行的重要原因。
- 资源消耗:Kubernetes使用Golang开发,资源占用非常小,资源占用轻量级,功能强大;
- 开源:Kubernetes是一个开源项目,不收费;
- 弹性伸缩:扩展节点和更新节点很容易;
- 负载均衡:Kubernetes实现了模块内部的负载均衡,不需要搭建调度器,并且负载均衡框架使用了ipvs框架。
2. 组件
Kubernetes基于Google的Borg系统实现,底层架构和borg系统有很多相似之处。
3. Pod
Pod是Kubernetes管理的最小单位,分为自主式Pod和控制器管理的Pod。同一个Pause里既共享网络又共享存储。
4. 网络通讯方式
5. 部署Kubernetes
实践过程中,将会一步步操作部署Kubernetes,总体上分为两个步骤进行:前期准备和集群安装。
5.1. 前期准备
- k8s-master01、k8s-worker01、k8s-worker02
- Harbor(暂时没用到)
- Router软路由(暂时没用到)
由于虚拟机会使用dhcp方式分配ip,每次启动虚拟机,其ip地址会发生变化,因此需要配置虚拟机为静态IP。目标是,给每个虚拟机分配完ip后,仍然可以保证虚拟机ping通外网,如www.baidu.com。主要是通过修改/etc/sysconfig/network-scripts/ifcfg-ens33来完成。
5.2. 集群安装
一主多架构的集群,部署过程中最容易出现问题的是Master节点。建议在操作时,先实际部署一台单Master的节点,待kube-system 命名空间下所有pod都能正常running后,再配置从节点,运行join命令加入集群。
5.2.1 配置Master节点和Worker节点
- 设置主机名
hostnamectl set-hostname k8s-master01
hostnamectl set-hostname k8s-worker01
# 切到master节点下
vim /etc/hosts
# 修改内容
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.40.128 k8s-master01
192.168.40.129 k8s-worker01
# 将该文件复制到从服务器
scp /etc/hosts root@k8s-worker01:/etc/hosts
hosts文件是linux系统中负责ip地址与域名快速解析的文件。hosts文件可以配置主机ip与对应的主机名,在局域网或者internet上,每台主机与其他主机通信时,通过ip地址唯一标识自己的身份,但是ip地址不方便记忆,于是可以在hosts文件中配置主机的名字(域名)。
- 关闭防火墙,设置iptables。
# 安装依赖包(主节点和从节点)
yum install -y conntrack ntpdate ntp ipvsadm ipset jq iptables curl sysstat libseccomp wget git
# 关闭防火墙(主节点和从节点)
systemctl stop firewalld && systemctl disable firewalld
# 设置防火墙为iptables,并设置空规则(主节点和从节点),docker升级等涉及网络转发依赖iptables
yum -y install iptables-services && systemctl start iptables && systemctl enable iptables
iptables -F && service iptables save # 清空iptables
Iptables 是集成在 Linux 内核中的包过滤防火墙系统。使用 iptables 可以添加、删除具体的过滤规则,iptables 默认维护着 4 个表和 5 个链,所有的防火墙策略规则都被分别写入这些表与链中。
- 关闭虚拟内存
# 关闭虚拟内存
swapoff -a && sed -i '/ swap / s/^\(.*\)$/#\1/g' /etc/fstab
k8s内存不足时,操作系统层面会使用虚拟内存技术,用硬盘来扩充逻辑内存,会影响k8s效率,为了不影响k8s效率需要关闭swap。
- 关闭selinux。
# 关闭selinux
setenforce 0 && sed -i 's/^SELINUX=.*/SELINUX=disabled/' /etc/selinux/config
SELinux全称(Security-Enhanced Linux),安全增强型 Linux。它是一个 Linux 内核模块,也是 Linux 的一个安全子系统,由美国国家安全局开发。它的主要作用:最大限度地减小系统中服务进程可访问的资源(最小权限原则)。有的软件对于selinux的安全规则支持不够好,就会建议在安装前把selinux先关闭。
- 调整时区
# 调整时区
timedatectl set-timezone Asia/Shanghai
timedatectl set-local-rtc 0
systemctl restart rsyslog
systemctl restart crond
- 配置linux日志
# 关闭系统不需要的服务
systemctl stop postfix && systemctl disable postfix
mkdir /var/log/journal
mkdir /etc/systemd/journald.conf.d
cat > /etc/systemd/journald.conf.d/99-prophet.conf << EOF
[Journal]
Storage=persistent # 持久化到磁盘
Compress=yes #压缩历史日志
SyncIntervalSec=5m
RateLimitInterval=30s
RateLimitBurst=1000
SystemMaxUse=10G
SystemMaxFileSize=200M
MaxRetentionSec=2week
ForwardToSyslog=no
EOF
systemctl restart systemd-journald
- 升级内核版本
# 升级系统内核版本
# 加载下载源
rpm -Uvh http://www.elrepo.org/elrepo-release-7.0-3.el7.elrepo.noarch.rpm
# 查看可下载的版本
yum --disablerepo="*" --enablerepo="elrepo-kernel" list available
# 下载
yum --enablerepo=elrepo-kernel install -y kernel-lt
# 设置开机从新内核启动
grub2-set-default "CentOS Linux(4.4.182-1.el7.elrepo.x86_64) 7 (Core)"
# reboot
uname -r
- 开启Netfilter
# Kube-proxy 开启ipvs的前置条件
modprobe br-netfilter
cat > /etc/sysconfig/modules/ipvs.modules << EOF
#!/bin/bash
modprobe -- ip_vs
modprobe -- ip_vs_rr
modprobe -- ip_vs_wrr
modprobe -- ip_vs_sh
modprobe -- nf_conntrack_ipv4
EOF
# 给bash脚本文件赋权限,并执行
chmod 755 /etc/sysconfig/modules/ipvs.modules && bash /etc/sysconfig/modules/ipvs.modules
# 打印被引导的模块
lsmod | grep -e ip_vs -e nf_conntrack_ipv4
关于ipvs的介绍,参考自ipvs
问题:这里遇到 nf_conntrack_ipv4模块不存在的问题,排查过程如下
# **nf_conntrack_ipv4模块不存在的问题,排查过程如下**
# 1. 查看当前内核启动顺序
awk -F\' '$1=="menuentry " {print $2}' /etc/grub2.cfg
grub2-set-default 1
reboot
uname -r
# 2. 查看当前系统默认内核,为4.4,(猜想,Linux内核执行顺序为,grub2-set-default " ",然后依次是awk -F\' '$1=="menuentry " {print $2}' /etc/grub2.cfg)
grub2-editenv list
modprobe工具可以智能的添加和删除一个模块,它能够通过配置的一些预定义的规则解析出模块之间的依赖关系,并且自动加载依赖的模块。modprobe会从 /lib/modules/uname -r目录中查找要加载的模块以及对应的依赖规则,除了这个目录以外,modprobe还有一个配置目录/etc/modprobe.d,这个配置目录中是用户可以自定义的一些modprobe行为。
Netfilter/IPTables是Linux2.4.x之后新一代的Linux防火墙机制,是linux内核的一个子系统。Netfilter采用模块化设计,具有良好的可扩充性。其重要工具模块IPTables从用户态的iptables连接到内核态的Netfilter的架构中,Netfilter与IP协议栈是无缝契合的,并允许使用者对数据报进行过滤、地址转换、处理等操作。
ipvs称之为IP虚拟服务器(IP Virtual Server,简写为IPVS)。是运行在LVS下的提供负载平衡功能的一种技术。
- k8s配置文件
# 关闭
cat > kubernetes.conf << EOF
net.bridge.bridge-nf-call-iptables=1 # 开启网桥模式
net.bridge.bridge-nf-call-ip6tables=1 # 开启网桥模式
net.ipv4.ip_forward=1
net.ipv4_tcp_tw_recycle=0
vm.swappiness=0 # 禁止使用swap空间,只有当系统OOM时才允许使用它
vm.overcommit_memory=1 # 不检查物理内存是否够用
vm.panic_on_oom=0 # 开启OOM
fs.inotify.max_user_instances=8192
fs.inotify.max_user_watches=1048576
fs.file-max=52706963 # 开启文件的句柄数目
fs.nr_open=52706963 # 开启文件的具体打开数目
net.ipv6.conf.all.disable_ipv6=1 # 关闭ipv6协议
net.netfilter.nf_conntrack_max=2310720
EOF
cp kubernetes.conf /etc/sysctl.d/kubernetes.conf
5.2.2 安装Container Runtime(Docker为例)
sudo yum install -y yum-utils
sudo yum-config-manager \
--add-repo \
https://download.docker.com/linux/centos/docker-ce.repo
sudo yum install docker-ce docker-ce-cli containerd.io
mkdir /etc/docker
systemctl start docker
systemctl enable docker
cat > /etc/docker/daemon.json << EOF
{
"exec-opts":["native.cgroupdriver=systemd"],
"log-driver":"json-file",
"log-opts": {
"max-size":"100m"
}
}
EOF
# 查看docker cgroup
docker info | grep Cgrou
mkdir -p /etc/systemd/system/docker.service.d
systemctl daemon-reload && systemctl restart docker && systemctl enable docker
为了在Pods中运行容器,Kubernetes使用Container Runtime。默认情况下,Kubernetes使用Container Runtime接口(CRI)和我们选择的Container Runtime进行对接。
如果未指定Container Runtime,kubeadm会通过扫描已知的Unix域套接字自动尝试检测已安装的Container Runtime。
Container Runtime包括Docker、containerd、CRI-O。如果同时检测到Docker和containerd,则Docker优先。如果检测到其他两个或更多Container Runtime,则kubeadm退出并显示错误。
5.2.3 安装Kubeadm(主从配置)
- 导入阿里云源
cat <<EOF | sudo tee /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=http://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=0
repo_gpgcheck=0
gpgkey=http://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg
http://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
- 安装Kubernetes
yum install -y kubeadm kubectl kubelet
systemctl enable kubelet.service
- 生成配置文件(yaml格式配置文件)
# 生成配置文件到指定的目录
kubeadm config print init-defaults > init-config.yaml
# 列出kubernetes需要pull的镜像
kubeadm config images list --config init-config.yaml
# 可以根据配置文件统一拉取镜像:前提是能科学上网,否则还是手动下载镜像
kubeadm config images pull --config init-config.yaml
# 手动下载步骤如下
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/kube-proxy:v1.22.0
docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/kube-proxy:v1.22.0
docker rmi registry.cn-hangzhou.aliyuncs.com/google_containers/kube-proxy:v1.22.0
- 配置init-config.yaml
vim init-config.yaml
apiVersion: kubeadm.k8s.io/v1beta2
bootstrapTokens:
- groups:
- system:bootstrappers:kubeadm:default-node-token
token: abcdef.0123456789abcdef
ttl: 24h0m0s
usages:
- signing
- authentication
kind: InitConfiguration
localAPIEndpoint:
advertiseAddress: 192.168.40.128 # 修改这里的地址
bindPort: 6443
nodeRegistration:
criSocket: /var/run/dockershim.sock
name: k8s-master01 # 修改name
taints: null
---
apiServer:
timeoutForControlPlane: 4m0s
apiVersion: kubeadm.k8s.io/v1beta2
certificatesDir: /etc/kubernetes/pki
clusterName: kubernetes
controllerManager: {}
dns:
type: CoreDNS
etcd:
local:
dataDir: /var/lib/etcd
imageRepository: k8s.gcr.io
kind: ClusterConfiguration
kubernetesVersion: 1.21.0
networking:
dnsDomain: cluster.local
podSubnet: "10.244.0.0/16"
serviceSubnet: 10.96.0.0/12
scheduler: {}
# 增加这里的字段
---
apiVersion: kubeproxy.config.k8s.io/v1alpha1
kind: KubeProxyConfiguration
featureGates:
SupportIPVSProxyMode: true
mode: ipvs
- 执行k8s命令,初始化Master节点。
# 根据yaml文件,初始化主节点
kubeadm init --config=init-config.yaml | tee kubeadm-init.log
# 初始化成功!按照提示,创建.kube文件夹
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
# 至此,kubectl就可以使用了,但执行kubectl get node 状态为NotReady
kubectl get node
此时,执行kubectl get node命令时,可以看到主节点STATUS为NOTREADY。需要安装flannel网络组件。
- 安装flannel网络组件
# 安装flannel
mkdir install-k8s
cd install-k8s
mkdir plugin
cd plugin
mkdir flannel
cd flannel
# 获取kube-flannel yml配置脚本
wget https://github.com/coreos/flannel/raw/master/Documentation/kube-flannel.yml
# 安装flannel
kubectl create -f kube-flannel.yml
kubectl get pod -n kube-system # 多了flannel组件
# 至此,kuberctl就可以使用了,但执行kubectl get node 状态为Ready
kubectl get node
Flannel是CoreOS团队针对Kubernetes设计的一个网络规划服务,简单来说,它的功能是让集群中的不同节点主机创建的Docker容器都具有全集群唯一的虚拟IP地址。
在默认的Docker配置中,每个节点上的Docker服务会分别负责所在节点容器的IP分配。这样导致的一个问题是,不同节点上容器可能获得相同的内外IP地址。
Flannel的设计目的就是为集群中的所有节点重新规划IP地址的使用规则,从而使得不同节点上的容器能够获得“同属一个内网”且”不重复的”IP地址,并让属于不同节点上的容器能够直接通过内网IP通信。
Kube-proxy 是 kubernetes 工作节点上的一个网络代理组件,运行在每个节点上。Kube-proxy维护节点上的网络规则,实现了Kubernetes Service 概念的一部分 。它的作用是使发往 Service 的流量(通过ClusterIP和端口)负载均衡到正确的后端Pod。
- 将子节点加入集群
# 此时kubeadm-init.log日志文件中,会弹出加入子节点的方法
kubeadm join 192.168.40.128:6443 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:a88c5e190b9b85d53188836971265999358b360c6efdf4c7c24289c9b0fcf6f8
# 如果忘记token执行下面的命令
kubeadm token create --print-join-command
# 此时,可以看到子节点了
kubectl get node
kubectl get pod -n kube-system -o wide
子节点kubectl命令无法执行
# 主节点admin.conf拷贝到子节点
scp /etc/kubernetes/admin.conf root@k8s-worker01:/etc/kubernetes
# 子节点配置环境变量
echo "export KUBECONFIG=/etc/kubernetes/admin.conf" >> /etc/profile
source /etc/profile
如果子节点加入后,为not ready状态,执行kubectl get pod -n kube-system -o wide,发现结果如下

kubectl describe pod kube-proxy-x44pc -n kube-system查看log
[root@k8s-worker01 ~]# kubectl describe pod kube-proxy-x44pc -n kube-system
Name: kube-proxy-x44pc
Namespace: kube-system
Priority: 2000001000
Priority Class Name: system-node-critical
Node: k8s-worker01/192.168.223.21
Start Time: Fri, 06 Aug 2021 23:06:28 +0800
Labels: controller-revision-hash=55847b5bbd
k8s-app=kube-proxy
pod-template-generation=1
Annotations: <none>
Status: Pending
IP: 192.168.223.21
IPs:
IP: 192.168.223.21
Controlled By: DaemonSet/kube-proxy
Containers:
kube-proxy:
Container ID:
Image: k8s.gcr.io/kube-proxy:v1.22.0
Image ID:
Port: <none>
Host Port: <none>
Command:
/usr/local/bin/kube-proxy
--config=/var/lib/kube-proxy/config.conf
--hostname-override=$(NODE_NAME)
State: Waiting
Reason: ContainerCreating
Ready: False
Restart Count: 0
Environment:
NODE_NAME: (v1:spec.nodeName)
Mounts:
/lib/modules from lib-modules (ro)
/run/xtables.lock from xtables-lock (rw)
/var/lib/kube-proxy from kube-proxy (rw)
/var/run/secrets/kubernetes.io/serviceaccount from kube-api-access-sg5mc (ro)
Conditions:
Type Status
Initialized True
Ready False
ContainersReady False
PodScheduled True
Volumes:
kube-proxy:
Type: ConfigMap (a volume populated by a ConfigMap)
Name: kube-proxy
Optional: false
xtables-lock:
Type: HostPath (bare host directory volume)
Path: /run/xtables.lock
HostPathType: FileOrCreate
lib-modules:
Type: HostPath (bare host directory volume)
Path: /lib/modules
HostPathType:
kube-api-access-sg5mc:
Type: Projected (a volume that contains injected data from multiple sources)
TokenExpirationSeconds: 3607
ConfigMapName: kube-root-ca.crt
ConfigMapOptional: <nil>
DownwardAPI: true
QoS Class: BestEffort
Node-Selectors: kubernetes.io/os=linux
Tolerations: op=Exists
node.kubernetes.io/disk-pressure:NoSchedule op=Exists
node.kubernetes.io/memory-pressure:NoSchedule op=Exists
node.kubernetes.io/network-unavailable:NoSchedule op=Exists
node.kubernetes.io/not-ready:NoExecute op=Exists
node.kubernetes.io/pid-pressure:NoSchedule op=Exists
node.kubernetes.io/unreachable:NoExecute op=Exists
node.kubernetes.io/unschedulable:NoSchedule op=Exists
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 50m default-scheduler Successfully assigned kube-system/kube-proxy-x44pc to k8s-worker01
Warning FailedCreatePodSandBox 46m kubelet Failed to create pod sandbox: rpc error: code = Unknown desc = failed pulling image "k8s.gcr.io/pause:3.5": Error response from daemon: Get "https://k8s.gcr.io/v2/": context deadline exceeded (Client.Timeout exceeded while awaiting headers)
Warning FailedCreatePodSandBox 45m (x2 over 49m) kubelet Failed to create pod sandbox: rpc error: code = Unknown desc = failed pulling image "k8s.gcr.io/pause:3.5": Error response from daemon: Get "https://k8s.gcr.io/v2/": dial tcp 64.233.189.82:443: i/o timeout (Client.Timeout exceeded while awaiting headers)
Warning FailedCreatePodSandBox 44m kubelet Failed to create pod sandbox: rpc error: code = Unknown desc = failed pulling image "k8s.gcr.io/pause:3.5": Error response from daemon: Get "https://k8s.gcr.io/v2/": context deadline exceeded
Warning FailedCreatePodSandBox 37m (x4 over 44m) kubelet Failed to create pod sandbox: rpc error: code = Unknown desc = failed pulling image "k8s.gcr.io/pause:3.5": Error response from daemon: Get "https://k8s.gcr.io/v2/": dial tcp 64.233.189.82:443: i/o timeout
Warning FailedCreatePodSandBox 4m31s (x73 over 49m) kubelet Failed to create pod sandbox: rpc error: code = Unknown desc = failed pulling image "k8s.gcr.io/pause:3.5": Error response from daemon: Get "https://k8s.gcr.io/v2/": net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers)
需要在子节点手动下载镜像,执行命令如下
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/kube-proxy:v1.22.0
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/pause:3.5
docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/kube-proxy:v1.22.0
docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/pause:3.5 k8s.gcr.io/pause:3.5
docker rmi registry.cn-hangzhou.aliyuncs.com/google_containers/kube-proxy:v1.22.0
docker rmi registry.cn-hangzhou.aliyuncs.com/google_containers/pause:3.5

5.2.4 问题
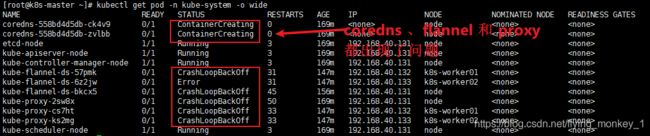
问题排查
kubectl logs kube-proxy-2sw8x -n kube-system
通过log工具查看pod的日志内容是排查问题最常用,也是最方便的方法,可以很快定位到问题的根源。kubectl get cscontroller manager和scheller都是unhealthy状态。

解决:
[root@k8s-master manifests]# vim /etc/kubernetes/manifests/kube-scheduler.yaml
[root@k8s-master manifests]# vim /etc/kubernetes/manifests/kube-controller-manager.yaml
# 搜索port=0,把这一行注释掉
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
labels:
component: kube-scheduler
tier: control-plane
name: kube-scheduler
namespace: kube-system
spec:
containers:
- command:
- kube-scheduler
- --authentication-kubeconfig=/etc/kubernetes/scheduler.conf
- --authorization-kubeconfig=/etc/kubernetes/scheduler.conf
- --bind-address=127.0.0.1
- --kubeconfig=/etc/kubernetes/scheduler.conf
- --leader-elect=true
# - --port=0
image: k8s.gcr.io/kube-scheduler:v1.21.0
重启kubelet
systemctl restart kubelet
查看10251端口和10252端口使用情况
[root@k8s-master manifests]# netstat -tunlp | grep 10251
tcp6 0 0 :::10251 :::* LISTEN 105510/kube-schedul
[root@k8s-master manifests]# netstat -tunlp | grep 10252
tcp6 0 0 :::10252 :::* LISTEN 96371/kube-controll
重启后,所有cs都变为healthy状态了
[root@k8s-master manifests]# kubectl get cs
Warning: v1 ComponentStatus is deprecated in v1.19+
NAME STATUS MESSAGE ERROR
controller-manager Healthy ok
scheduler Healthy ok
etcd-0 Healthy {"health":"true"}
kube-proxy一直处于CrashLoopBackoff状态

解决

通过kubectl logs kube-proxy-zcmcb -n kube-system发现kube-proxy无法识别SupportIPVSProxyMode这个字段,官方给出的解决办法是在配置配置文件中添加如下配置

问题是,现在已经集群初始化成功了,重置集群的做法是非常不可取的。通过kubectl -n kube-system get pod kube-proxy-zcmcb -o yaml命令,查看kube-pxory的资源清单可以知道, kube-proxy的配置文件是通过configmap方式挂载到容器中的,因此我们只需要对应修改configmap中的配置内容,就可以将无效字段删除。
kubectl edit cm kube-proxy -n kube-system
#在编辑模式中找到以下字段,删除后保存退出
featureGates:
SupportIPVSProxyMode: true
# 保存后,删除kube-proxy,重启,会重新创建kube-proxy
kubectl get pod -n kube-system
kubectl delete pod kube-proxy-zcmcb -n kube-system
systemctl restart kubelet
# 查看pod状态,大功告成
kubectl get pod -n kube-system
解决办法参考链接
kubeadm init或者kubeadm join时发生preflight错误
error execution phase preflight: [preflight] Some fatal errors occurred:
[ERROR FileContent--proc-sys-net-bridge-bridge-nf-call-iptables]: /proc/sys/net/bridge/bridge-nf-call-iptables contents are not set to 1
解决
echo "1">/proc/sys/net/bridge/bridge-nf-call-iptables
echo "1">/proc/sys/net/bridge/bridge-nf-call-ip6tables
5.3 测试
5.3.1 部署nginx
注意,使用kubeadm初始化的集群,出于安全考虑Pod,不会被调度到Master Node上,也就是说Master Node不参与工作负载。也就是说,如果集群中只有一个Master节点,没有worker节点的话,是不能部署nginx pod的。
kubectl create deployment nginx-deploy --image=nginx
kubectl expose deployment nginx-deploy --port=80 --type=NodePort
查看IP和端口号并测试
[root@k8s-master01 ~]# kubectl get pod,svc
NAME READY STATUS RESTARTS AGE
pod/nginx-deploy-8588f9dfb-zdbfg 1/1 Running 0 42m
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 140m
service/nginx-deploy NodePort 10.109.182.91 <none> 80:31085/TCP 83m
[root@k8s-master01 ~]# curl 192.168.65.131:31085
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
body {
width: 35em;
margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif;
}
</style>
</head>
<body>
<h1>Welcome to nginx!</h1>
<p>If you see this page, the nginx web server is successfully installed and
working. Further configuration is required.</p>
<p>For online documentation and support please refer to
<a href="http://nginx.org/">nginx.org</a>.<br/>
Commercial support is available at
<a href="http://nginx.com/">nginx.com</a>.</p>
<p><em>Thank you for using nginx.</em></p>
</body>
</html>
[root@k8s-master01 ~]# curl 192.168.65.130:31085
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
body {
width: 35em;
margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif;
}
</style>
</head>
<body>
<h1>Welcome to nginx!</h1>
<p>If you see this page, the nginx web server is successfully installed and
working. Further configuration is required.</p>
<p>For online documentation and support please refer to
<a href="http://nginx.org/">nginx.org</a>.<br/>
Commercial support is available at
<a href="http://nginx.com/">nginx.com</a>.</p>
<p><em>Thank you for using nginx.</em></p>
</body>
</html>
浏览器中输入地址,大功告成!注意,这里131是worker的地址,130是master的IP,不管通过master还是通过worker都可以请求到数据。


6. 安装dashboard
k8s和dashboard的版本适配可以查看 这里 截至到2020年8月7日,我使用的是v2.3.1版本,k8s使用的是v1.22.0。
我安装dashboard过程中踩了一下午的坑,最终 参考自这里
注意!访问dashboard ui 时,不要仅仅输入ip地址,一定要在ip地址前加上htps://前缀, https://192.168.xxx.xxx:xxx
6. 参考文献
[1] https://www.bilibili.com/video/BV1w4411y7Go?p=15
[2] https://blog.csdn.net/sjy_2010/article/details/113799045
[3] https://blog.csdn.net/rikeyone/article/details/80095639
[4] https://blog.csdn.net/huwh_/article/details/77899108