科学计算工具numpy-ndarray的矩阵处理,索引切片,拼接,函数,数组转换以及nan等
轴(axis)
在numpy中可以理解为方向,使用0,1,2…数字表示,
对于一个一维数组,只有一个0轴,
对于二维数组(shape(2,2)),有0轴和1轴,
对于三维数组(shape(2,2, 3)),有0,1,2轴
有了轴的概念之后,我们计算会更加方便,比如计算一个2维数组的平均值,必须指定是计算哪个方向上面的数字的平均值
np.arange(0,10).reshape((2,5)), reshape中2表示0轴长度(包含数据的条数)为2, 1轴长度为5, 2X5一共10个数据
索引与切片
1. 一维数组的索引与切片(与Python的列表索引功能相似)
# 一维数组
arr1 = np.arange(10)
print(arr1)
print(arr1[2:5])
运行结果
[0 1 2 3 4 5 6 7 8 9]
[2 3 4]
2. 多维数组的索引与切片:
arr[r1:r2, c1:c2]
arr[1,1] 等价 arr[1][1]
[:] 代表某个维度的数据
# 多维数组
arr2 = np.arange(12).reshape(3,4)
print(arr2)
print(arr2[1])
print(arr2[0:2, 2:])
print(arr2[:, 1:3])
运行结果
[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
[4 5 6 7]
[[2 3]
[6 7]]
[[ 1 2]
[ 5 6]
[ 9 10]]
3. 条件索引
布尔值多维数组:arr[condition],condition也可以是多个条件组合。
注意,多个条件组合要使用 & | 连接,而不是Python的 and or。
# 条件索引
# 找出 data_arr 中 2005年后的数据
data_arr = np.random.rand(3,3)
print(data_arr)
year_arr = np.array([[2000, 2001, 2000],
[2005, 2002, 2009],
[2001, 2003, 2010]])
is_year_after_2005 = year_arr >= 2005
print(is_year_after_2005, is_year_after_2005.dtype)
filtered_arr = data_arr[is_year_after_2005]
print(filtered_arr)
#filtered_arr = data_arr[year_arr >= 2005]
#print(filtered_arr)
# 多个条件
filtered_arr = data_arr[(year_arr <= 2005) & (year_arr % 2 == 0)]
print(filtered_arr)
运行结果:
[[ 0.53514038 0.93893429 0.1087513 ]
[ 0.32076215 0.39820313 0.89765765]
[ 0.6572177 0.71284822 0.15108756]]
[[False False False]
[ True False True]
[False False True]] bool
[ 0.32076215 0.89765765 0.15108756]
#[ 0.32076215 0.89765765 0.15108756]
[ 0.53514038 0.1087513 0.39820313]
numpy中数值的更改

numpy中布尔索引

numpy中的三元运算符
把小于10的替换为0,其他的为10

numpy中的clip(裁剪)

numpy中的nan和inf

numpy中nan的注意点

那么问题来了,在一组数据中单纯的把nan替换为0,合适么?会带来什么样的影响?
比如,全部替换为0后,替换之前的平均值如果大于0,替换之后的均值肯定会变小,所以更一般的方式是把缺失的数值替换为均值(中值)或者是直接删除有缺失值的一行
ndarray缺失值填充均值
t中存在nan值,如何操作把其中的nan填充为每一列的均值
代码:
# coding=utf-8
import numpy as np
def fill_ndaeeay(t1):
for i in range(t1.shape[1]): # 遍历每一列
temp_col = t1[:,i] # 当前的一列
nan_num = np.count_nonzero(temp_col != temp_col) # 数据不相等,说明有nan值
if nan_num !=0: # 不为0,说明当前这一列有nan
temp_not_nan_col = temp_col[temp_col==temp_col] # 当前一列不为nan的array
# 选中当前为nan的位置,把值赋值为不为nan的均值
temp_col[np.isnan(temp_col)] = temp_not_nan_col.mean()
return t1
if __name__ == '__main__':
t1 = np.arange(12).reshape(3, 4).astype('float')
t1[1, 2:] = np.nan
print(t1)
print('-'*66)
t1 = fill_ndaeeay(t1)
print(t1)
运行结果:
[[ 0. 1. 2. 3.]
[ 4. 5. nan nan]
[ 8. 9. 10. 11.]]
------------------------------------------------------------------
[[ 0. 1. 2. 3.]
[ 4. 5. 6. 7.]
[ 8. 9. 10. 11.]]
元素计算函数
1.ceil(): 向上最接近的整数,参数是 number 或 array
2.floor(): 向下最接近的整数,参数是 number 或 array
3.rint(): 四舍五入,参数是 number 或 array
4.isnan(): 判断元素是否为 NaN(Not a Number),参数是 number 或 array
5.multiply(): 元素相乘,参数是 number 或 array
6.divide(): 元素相除,参数是 number 或 array
7.abs():元素的绝对值,参数是 number 或 array
8.where(condition, x, y): 三元运算符,x if condition else y
示例代码(1、2、3、4、5、6、7):
# randn() 返回具有标准正态分布的序列。
arr = np.random.randn(2,3)
print(arr)
print(np.ceil(arr))
print(np.floor(arr))
print(np.rint(arr))
print(np.isnan(arr))
print(np.multiply(arr, arr))
print(np.divide(arr, arr))
print(np.where(arr > 0, 1, -1))
运行结果
# print(arr)
[[-0.75803752 0.0314314 1.15323032]
[ 1.17567832 0.43641395 0.26288021]]
# print(np.ceil(arr))
[[-0. 1. 2.]
[ 2. 1. 1.]]
# print(np.floor(arr))
[[-1. 0. 1.]
[ 1. 0. 0.]]
# print(np.rint(arr))
[[-1. 0. 1.]
[ 1. 0. 0.]]
# print(np.isnan(arr))
[[False False False]
[False False False]]
# print(np.multiply(arr, arr))
[[ 5.16284053e+00 1.77170104e+00 3.04027254e-02]
[ 5.11465231e-03 3.46109263e+00 1.37512421e-02]]
# print(np.divide(arr, arr))
[[ 1. 1. 1.]
[ 1. 1. 1.]]
# print(np.where(arr > 0, 1, -1))
[[ 1 1 -1]
[-1 1 1]]
元素统计函数
1.np.mean(), np.sum():所有元素的平均值,所有元素的和,参数是 number 或 array
2.np.max(), np.min():所有元素的最大值,所有元素的最小值,参数是 number 或 array
3.np.std(), np.var():所有元素的标准差,所有元素的方差,参数是 number 或 array
4.np.argmax(), np.argmin():最大值的下标索引值,最小值的下标索引值,参数是 number 或 array
5.np.cumsum(), np.cumprod():返回一个一维数组,每个元素都是之前所有元素的 累加和 和 累乘积,参数是 number 或 array
6.多维数组默认统计全部维度,axis参数可以按指定轴心统计,值为0则按列统计,值为1则按行统计。
示例代码:
arr = np.arange(12).reshape(3,4)
print(arr)
print(np.cumsum(arr)) # 返回一个一维数组,每个元素都是之前所有元素的 累加和
print(np.sum(arr)) # 所有元素的和
print(np.sum(arr, axis=0)) # 数组的按列统计和
print(np.sum(arr, axis=1)) # 数组的按行统计和
运行结果:
# print(arr)
[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
# print(np.cumsum(arr)) # 累加和
[ 0 1 3 6 10 15 21 28 36 45 55 66]
# print(np.sum(arr)) # 所有元素的和
66
# print(np.sum(arr, axis=0)) # 0表示对数组的每一列的统计和
[12 15 18 21]
# print(np.sum(arr, axis=1)) # 1表示数组的每一行的统计和
[ 6 22 38]

元素判断函数
np.any(): 至少有一个元素满足指定条件,返回True
np.all(): 所有的元素满足指定条件,返回True
示例代码:
arr = np.random.randn(2,3)
print(arr)
print(np.any(arr > 0))
print(np.all(arr > 0))
运行结果:
[[ 0.05075769 -1.31919688 -1.80636984]
[-1.29317016 -1.3336612 -0.19316432]]
True
False
元素去重排序函数
np.unique():找到唯一值并返回排序结果,类似于Python的set集合
示例代码:
arr = np.array([[1, 2, 1], [2, 3, 4]])
print(arr)
print(np.unique(arr))
运行结果:
[[1 2 1]
[2 3 4]]
[1 2 3 4]
数组的拼接(不是数值加减)

数组的行列交换
如果每一列的意义不同,这个时候应该交换某一组的数的列,让其和另外一列相同

ndarray数组的维数转换
二维数组直接使用转换函数:transpose()
高维数组转换要指定维度编号参数 (0, 1, 2, …),注意参数是元组
转置是一种变换,对于numpy中的数组来说,就是在对角线方向交换数据,目的也是为了更方便的去处理数据,转置和交换轴的效果一样
arr = np.random.rand(2,3) # 2x3 数组
print(arr)
print(arr.transpose()) # 转换为 3x2 数组
arr3d = np.random.rand(2,3,4) # 2x3x4 数组,2对应0,3对应1,4对应2
print(arr3d)
print(arr3d.transpose((1,0,2))) # 根据维度编号,转为为 3x2x4 数组
# print(t3.T) # 转置效果相同
# print(t3.swapaxes(1,0)) # 转置效果相同
运行结果:
# 二维数组转换
# 转换前:
[[ 0.50020075 0.88897914 0.18656499]
[ 0.32765696 0.94564495 0.16549632]]
# 转换后:
[[ 0.50020075 0.32765696]
[ 0.88897914 0.94564495]
[ 0.18656499 0.16549632]]
# 高维数组转换
# 转换前:
[[[ 0.91281153 0.61213743 0.16214062 0.73380458]
[ 0.45539155 0.04232412 0.82857746 0.35097793]
[ 0.70418988 0.78075814 0.70963972 0.63774692]]
[[ 0.17772347 0.64875514 0.48422954 0.86919646]
[ 0.92771033 0.51518773 0.82679073 0.18469917]
[ 0.37260457 0.49041953 0.96221477 0.16300198]]]
# 转换后:
[[[ 0.91281153 0.61213743 0.16214062 0.73380458]
[ 0.17772347 0.64875514 0.48422954 0.86919646]]
[[ 0.45539155 0.04232412 0.82857746 0.35097793]
[ 0.92771033 0.51518773 0.82679073 0.18469917]]
[[ 0.70418988 0.78075814 0.70963972 0.63774692]
[ 0.37260457 0.49041953 0.96221477 0.16300198]]]
# coding:utf-8
import numpy as np
us_file_path = './youtube_video_data/US_video_data_numbers.csv'
uk_file_path = './youtube_video_data/GB_video_data_numbers.csv'
t1 = np.loadtxt(us_file_path,delimiter=',',dtype='int',unpack=True) # unpack=1 转置
t2 = np.loadtxt(us_file_path,delimiter=',',dtype='int')
# print(t1)
# print('*'*100)
print(t2)
print('*'*100)
# 取行
print(t2[1])
print(t2[1,:]) # 逗号前边表示行,后边表示列,取第一行,不限制列.
# 取连续的多行
print(t2[2:])
print(t2[2:,:]) # 从第二行开始取多行
# # 取不连续的多行
print(t2[[2,8,10]])
print('*'*100)
print(t2[[2,8,10],:]) # 取2,8,10行
# 取列
print(t2[:,0]) # 取第一列,不限制行.逗号前边表示行,逗号后边表示列,冒号表示不限制.
# 取连续的多列
print(t2[:,2:]) # 取第3列后的多列
# 取不连续的多列
print(t2[:,[0,2,3]])
# 取行和列,取第3行4列的值
print(t2[2,3])
# 取多行和多列,取第3行到第5行,第2列到第4列的结果
b = t2[2:5,1:4]
print(b)
# 取多个不相邻的点
# 选出来的位置是(0,0) (2,1) (2,3)即相同位置的数字结合为坐标点,前为行,后为列
c = t2[[0,2,2],[0,1,3]]
print(c)
print('*'*100)
t3 = np.loadtxt(uk_file_path,delimiter=',',dtype='int')
print(t3)
print('*'*100)
print(t3.transpose()) # 转置
print('*'*100)
print(t3.T) # 转置
print('*'*100)
print(t3.swapaxes(1,0)) # 转置
运行结果:
/home/ling/pytest/redis/conda/bin/python /home/ling/Desktop/Conda/conda/page74.py
[[4394029 320053 5931 46245]
[7860119 185853 26679 0]
[5845909 576597 39774 170708]
...
[ 142463 4231 148 279]
[2162240 41032 1384 4737]
[ 515000 34727 195 4722]]
****************************************************************************************************
[7860119 185853 26679 0]
[7860119 185853 26679 0]
[[5845909 576597 39774 170708]
[2642103 24975 4542 12829]
[1168130 96666 568 6666]
...
[ 142463 4231 148 279]
[2162240 41032 1384 4737]
[ 515000 34727 195 4722]]
[[5845909 576597 39774 170708]
[2642103 24975 4542 12829]
[1168130 96666 568 6666]
...
[ 142463 4231 148 279]
[2162240 41032 1384 4737]
[ 515000 34727 195 4722]]
[[5845909 576597 39774 170708]
[1338533 69687 678 5643]
[ 859289 34485 726 1914]]
****************************************************************************************************
[[5845909 576597 39774 170708]
[1338533 69687 678 5643]
[ 859289 34485 726 1914]]
[4394029 7860119 5845909 ... 142463 2162240 515000]
[[ 5931 46245]
[ 26679 0]
[ 39774 170708]
...
[ 148 279]
[ 1384 4737]
[ 195 4722]]
[[4394029 5931 46245]
[7860119 26679 0]
[5845909 39774 170708]
...
[ 142463 148 279]
[2162240 1384 4737]
[ 515000 195 4722]]
170708
[[576597 39774 170708]
[ 24975 4542 12829]
[ 96666 568 6666]]
[4394029 576597 170708]
****************************************************************************************************
[[7426393 78240 13548 705]
[ 494203 2651 1309 0]
[ 142819 13119 151 1141]
...
[ 109222 4840 35 212]
[ 626223 22962 532 1559]
[ 99228 1699 23 135]]
****************************************************************************************************
[[7426393 494203 142819 ... 109222 626223 99228]
[ 78240 2651 13119 ... 4840 22962 1699]
[ 13548 1309 151 ... 35 532 23]
[ 705 0 1141 ... 212 1559 135]]
****************************************************************************************************
[[7426393 494203 142819 ... 109222 626223 99228]
[ 78240 2651 13119 ... 4840 22962 1699]
[ 13548 1309 151 ... 35 532 23]
[ 705 0 1141 ... 212 1559 135]]
****************************************************************************************************
[[7426393 494203 142819 ... 109222 626223 99228]
[ 78240 2651 13119 ... 4840 22962 1699]
[ 13548 1309 151 ... 35 532 23]
[ 705 0 1141 ... 212 1559 135]]
numpy的更多方法
1.获取最大值最小值的位置
np.argmax(t,axis=0)
np.argmin(t,axis=1)
2.创建一个全0的数组: np.zeros((3,4))
3.创建一个全1的数组:np.ones((3,4))
4.创建一个对角线为1的正方形数组(方阵):np.eye(3)
In [6]: np.zeros((3,4))
Out[6]:
array([[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.]])
In [7]: np.ones((2,3))
Out[7]:
array([[1., 1., 1.],
[1., 1., 1.]])
In [8]: a = np.eye(4)
Out[8]: a
array([[1., 0., 0., 0.],
[0., 1., 0., 0.],
[0., 0., 1., 0.],
[0., 0., 0., 1.]])
In [10]: np.argmax(a,axis=0) # 0轴上最大值的位置
Out[10]: array([0, 1, 2, 3])
a[a==1]=-1
In [13]: a
Out[13]:
array([[-1., 0., 0., 0.],
[ 0., -1., 0., 0.],
[ 0., 0., -1., 0.],
[ 0., 0., 0., -1.]])
In [14]: np.argmin(a,axis=1) # 1轴上最小值的位置
Out[14]: array([0, 1, 2, 3])
numpy生成随机数

In [15]: np.random.randint(10,20,(4,5))
Out[15]:
array([[13, 14, 17, 18, 19],
[15, 19, 15, 15, 15],
[14, 19, 11, 18, 11],
[10, 18, 12, 17, 15]])
In [16]: np.random.uniform(10,20,(4,5))
Out[16]:
array([[13.8735799 , 14.3469212 , 11.17905123, 16.8659199 , 16.48542284],
[16.90367527, 10.17316314, 13.33271289, 14.11100472, 13.01829488],
[16.61154125, 15.0546829 , 11.66780979, 17.58511519, 10.3108681 ],
[17.00435094, 14.81664907, 16.48919784, 10.39592964, 17.50078188]])
numpy的注意点copy
1.a=b 完全不复制,a和b相互影响
2.a = b[:],视图的操作,一种切片,会创建新的对象a,但是a的数据完全由b保管,他们两个的数据变化是一致的,
3.a = b.copy(),复制,a和b互不影响
练习1,英美youtube视频数据
现在这里有一个英国和美国各自youtube1000多个视频的点击,喜欢,不喜欢,评论数量([“views”,“likes”,“dislikes”,“comment_total”])的csv。
现在希望把数据中两个国家的数据放在一起来研究分析,同时保留国家的信息(每条数据的国家来源),应该怎么办
数据来源:https://www.kaggle.com/datasnaek/youtube/data
# coding:utf-8
import numpy as np
# 通过loadtxt()读取本地csv文件
us_data = './youtube_video_data/US_video_data_numbers.csv'
uk_data = './youtube_video_data/GB_video_data_numbers.csv'
# 加载国家数据
us_data = np.loadtxt(us_data,delimiter=',',dtype=int)
uk_data = np.loadtxt(uk_data,delimiter=',',dtype=int)
print('-'*44,'usdata','-'*44)
print(us_data,us_data.shape)
print('-'*44,'ukdata','-'*44)
print(uk_data,uk_data.shape)
# 添加国家信息
# 构造全为0的数据
print('-'*44,'zeros_data','-'*44)
zeros_data = np.zeros((us_data.shape[0],1)).astype(int)
print(zeros_data,zeros_data.shape)
# 构造全为1的数据
print('-'*44,'ones_data','-'*44)
ones_data = np.ones((uk_data.shape[0],1)).astype(int)
print(ones_data,ones_data.shape)
# 分别添加一列全为0,1的数据
us_data = np.hstack((us_data,zeros_data))
uk_data = np.hstack((uk_data,ones_data))
print('-'*44,'usdata','-'*44)
print(us_data,us_data.shape)
print('-'*44,'ukdata','-'*44)
print(uk_data,uk_data.shape)
# 拼接两条数据
final_data = np.vstack((us_data,uk_data))
print('-'*44,'finaldata','-'*44)
print(final_data,final_data.shape)
运行结果
-------------------------------------------- usdata --------------------------------------------
[[4394029 320053 5931 46245]
[7860119 185853 26679 0]
[5845909 576597 39774 170708]
...
[ 142463 4231 148 279]
[2162240 41032 1384 4737]
[ 515000 34727 195 4722]] (1688, 4)
-------------------------------------------- ukdata --------------------------------------------
[[7426393 78240 13548 705]
[ 494203 2651 1309 0]
[ 142819 13119 151 1141]
...
[ 109222 4840 35 212]
[ 626223 22962 532 1559]
[ 99228 1699 23 135]] (1600, 4)
-------------------------------------------- zeros_data --------------------------------------------
[[0]
[0]
[0]
...
[0]
[0]
[0]] (1688, 1)
-------------------------------------------- ones_data --------------------------------------------
[[1]
[1]
[1]
...
[1]
[1]
[1]] (1600, 1)
-------------------------------------------- usdata --------------------------------------------
[[4394029 320053 5931 46245 0]
[7860119 185853 26679 0 0]
[5845909 576597 39774 170708 0]
...
[ 142463 4231 148 279 0]
[2162240 41032 1384 4737 0]
[ 515000 34727 195 4722 0]] (1688, 5)
-------------------------------------------- ukdata --------------------------------------------
[[7426393 78240 13548 705 1]
[ 494203 2651 1309 0 1]
[ 142819 13119 151 1141 1]
...
[ 109222 4840 35 212 1]
[ 626223 22962 532 1559 1]
[ 99228 1699 23 135 1]] (1600, 5)
-------------------------------------------- finaldata --------------------------------------------
[[4394029 320053 5931 46245 0]
[7860119 185853 26679 0 0]
[5845909 576597 39774 170708 0]
...
[ 109222 4840 35 212 1]
[ 626223 22962 532 1559 1]
[ 99228 1699 23 135 1]] (3288, 5)
Process finished with exit code 0
练习2.2016年美国总统大选民意调查数据统计:
项目地址:https://www.kaggle.com/fivethirtyeight/2016-election-polls
该数据集包含了2015年11月至2016年11月期间对于2016美国大选的选票数据,共27列数据
示例代码1 :
# loadtxt
import numpy as np
# csv 名逗号分隔值文件
filename = './presidential_polls.csv'
# 通过loadtxt()读取本地csv文件
data_array = np.loadtxt(filename, # 文件名
delimiter=',', # 分隔符
dtype=str, # 数据类型,数据是Unicode字符串
usecols=(0,2,3)) # 指定读取的列号
# 打印ndarray数据,保留第一行
print(data_array, data_array.shape)
运行结果
[["b'cycle'" "b'type'" "b'matchup'"]
["b'2016'" 'b\'"polls-plus"\'' 'b\'"Clinton vs. Trump vs. Johnson"\'']
["b'2016'" 'b\'"polls-plus"\'' 'b\'"Clinton vs. Trump vs. Johnson"\'']
...,
["b'2016'" 'b\'"polls-only"\'' 'b\'"Clinton vs. Trump vs. Johnson"\'']
["b'2016'" 'b\'"polls-only"\'' 'b\'"Clinton vs. Trump vs. Johnson"\'']
["b'2016'" 'b\'"polls-only"\'' 'b\'"Clinton vs. Trump vs. Johnson"\'']] (10237, 3)
示例代码2
import numpy as np
# 读取列名,即第一行数据
with open(filename, 'r') as f:
col_names_str = f.readline()[:-1] # [:-1]表示不读取末尾的换行符'\n'
# 将字符串拆分,并组成列表
col_name_lst = col_names_str.split(',')
# 使用的列名:结束时间,克林顿原始票数,川普原始票数,克林顿调整后票数,川普调整后票数
use_col_name_lst = ['enddate', 'rawpoll_clinton', 'rawpoll_trump','adjpoll_clinton', 'adjpoll_trump']
# 获取相应列名的索引号
use_col_index_lst = [col_name_lst.index(use_col_name) for use_col_name in use_col_name_lst]
# 通过genfromtxt()读取本地csv文件,
data_array = np.genfromtxt(filename, # 文件名
delimiter=',', # 分隔符
#skiprows=1, # 跳过第一行,即跳过列名
dtype=str, # 数据类型,数据不再是Unicode字符串
usecols=use_col_index_lst)# 指定读取的列索引号
# genfromtxt() 不能通过 skiprows 跳过第一行的
# ['enddate' 'rawpoll_clinton' 'rawpoll_trump' 'adjpoll_clinton' 'adjpoll_trump']
# 去掉第一行
data_array = data_array[1:]
# 打印ndarray数据
print(data_array[1:], data_array.shape)
运行结果:
[['10/30/2016' '45' '46' '43.29659' '44.72984']
['10/30/2016' '48' '42' '46.29779' '40.72604']
['10/24/2016' '48' '45' '46.35931' '45.30585']
...,
['9/22/2016' '46.54' '40.04' '45.9713' '39.97518']
['6/21/2016' '43' '43' '45.2939' '46.66175']
['8/18/2016' '32.54' '43.61' '31.62721' '44.65947']] (10236, 5)
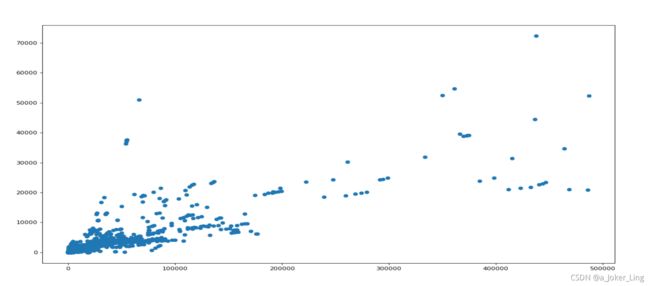
希望了解英国的youtube中视频的评论数和喜欢数的关系,应该如何绘制改图
代码:
# coding:utf-8
import numpy as np
from matplotlib import pyplot as plt
import matplotlib
us_file_path = './youtube_video_data/US_video_data_numbers.csv'
uk_file_path = './youtube_video_data/GB_video_data_numbers.csv'
# t1 = np.loadtxt(us_file_path,delimiter=',',dtype='int',unpack=True) # unpack=1 转置
t_uk = np.loadtxt(uk_file_path,delimiter=',',dtype='int')
t_uk = t_uk[t_uk[:,1]<=500000] # 选择喜欢数比500000小的数据
# 取评论的数据
t_uk_comments = t_uk[:,-1]
# 取喜欢的数据
t_uk_like = t_uk[:,1]
# 绘图
plt.figure(figsize=(20,8),dpi=80)
plt.scatter(t_uk_like,t_uk_comments)
plt.show()
运行结果:
英国youtube1000的数据结合之前的matplotlib绘制出评论数量的直方图
代码:
# coding:utf-8
import numpy as np
from matplotlib import pyplot as plt
import matplotlib
us_file_path = './youtube_video_data/US_video_data_numbers.csv'
uk_file_path = './youtube_video_data/GB_video_data_numbers.csv'
# t1 = np.loadtxt(us_file_path,delimiter=',',dtype='int',unpack=True) # unpack=1 转置
t_us = np.loadtxt(us_file_path,delimiter=',',dtype='int')
# 取评论的数据
t_us_comments = t_us[:,-1]
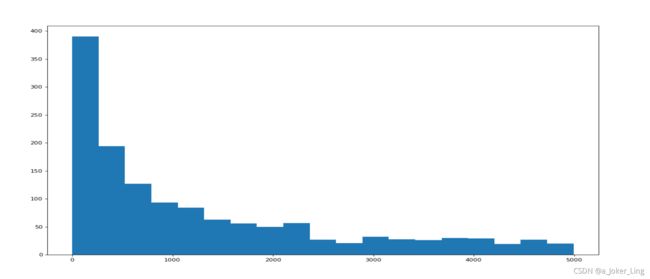
# 选择比5000小的数据
t_us_comments = t_us_comments[t_us_comments<=5000]
d = 250 # 组距
bin_nums = (t_us_comments.max()-t_us_comments.min())//d # 取组数
# print(bin_nums)
# 绘图
plt.figure(figsize=(20,8),dpi=80)
plt.hist(t_us_comments,bin_nums)
plt.show()
运行结果: