【论文笔记_知识蒸馏】Interactive Knowledge Distillation for image classification

摘要
知识提炼(KD)是一个标准的师生学习框架,在训练有素的大型教师网络的指导下,培养一个轻量级的学生网络。互动教学作为一种有效的教学策略,在学校得到了广泛的应用,以激发学生的学习动机。在互动教学中,教师不仅提供知识,而且对学生的反应给予建设性的反馈,以提高学生的学习成绩。在这项工作中,我们提出了交互式知识提炼(IAKD)来利用交互式教学策略进行有效的知识提炼。在提取过程中,教师网络和学生网络之间的交互是通过交换操作实现的:用教师网络中相应的块随机替换学生网络中的块。通过这种方式,我们直接涉及到教师强大的特征转换能力,从而大大提高了学生网络的性能。在典型的师生网络环境下进行的实验表明,在不同的图像分类数据集上,IAKD训练的学生网络比传统的知识提取方法训练的学生网络具有更好的性能。
1.介绍
基于以上讨论,我们试图使蒸馏过程互动,教师网络真正参与引导学生网络。具体来说,学生首先自己提取特征,然后教师用其强大的特征转换能力改进弱特征,最后学生继续基于改进后的特征提取深层特征。更好的特征对于更好的分类性能至关重要,并且可以为学生的学习过程[20—22]提供良好的基础。如图1所示,我们的交互蒸馏没有强迫学生模仿教师的表现空间,而是直接涉及到教师对学生强大的特征转换能力。因此,学生可以充分利用改进后的功能,更好地利用其在相关任务中的潜力。
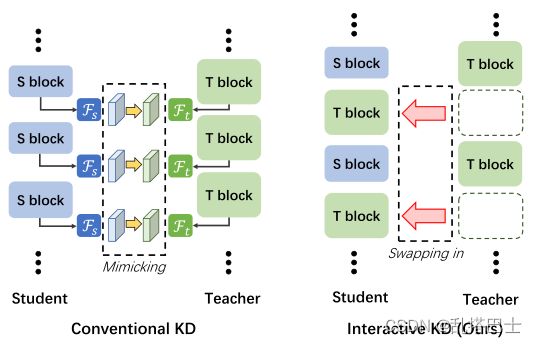
图1。我们提出的交互式知识提取方法与传统的非交互式知识提取方法之间的差异。”S block“表示学生块,'T block”表示教师块。Fs和Ft分别表示学生和教师知识的定义,不同的方法有很大不同。
本文提出了一种简单而有效的知识提取方法——交互式知识提取(IAKD)。在IAKD中,我们在蒸馏阶段随机交换教师网络中的块,以替换学生网络中的块。每一组交换的教师模块响应前一个学生模块的输出,并提供特征映射来激励下一个学生模块,这比替换的学生模块可以提供的特征映射更好。此外,教师模块中的随机交换使教师能够以多种不同的方式引导学生。与其他传统的知识提取方法相比,我们提出的方法没有刻意强迫学生的知识与教师的知识相似。因此,我们不需要额外的蒸馏损失来驱动知识蒸馏过程,因此不需要超参数来平衡任务特定损失和蒸馏损失。此外,我们的IAKD方法的蒸馏过程是高效的。这是因为我们的IAKD摒弃了繁琐的知识转换过程,并摆脱了传统知识提取方法中普遍存在的对整个教师网络的特征提取。实验结果表明,我们提出的方法有效地提高了学生的学习成绩,这证明了学生可以从与教师的互动中受益。
2.相关工作
3.提出的方法
3.1传统的知识蒸馏
3.2交互式知识蒸馏
为了实现学生网络和教师网络之间的交互,我们的IAKD在每个步骤中随机交换教师块以替换学生块。作为交换块的教师模块可以响应上一个学生模块的输出,然后提供更好的功能来激励下一个学生模块。为了让所有学生模块完全参与蒸馏过程,在每个训练步骤之后,我们将替换的学生模块放回其在学生网络中的原始位置。由于更换的学生模块返回,学生的体系结构在下一次交换操作中保持一致。

图2。该混合网络图可以有效地实现所提出的交互式知识提取(IAKD)。具体而言,混合网络使教师块能够随机替换原始学生网络的学生块。FC表示完全连接的层。
用于在操作中交换的混合块:如图2所示,为了有效地实现这种交互策略,我们设计了一个双路径混合块,它由一个学生块(学生路径)和几个要交换的教师块(教师路径)组成。我们使用混合块替换学生网络中的原始学生块,形成一个混合网络。然而,教师和学生共享的块和层不会被混合块取代,因为共享部分具有相同的学习能力。混合块的数量取决于非共享学生块的数量。每个非共享学生块将与一个或多个非共享教师块配对,形成混合块。所有非共享的教师块将形成混合块。
对于混合网络中的第i个混合块,让ai∈{0,1}表示伯努利随机变量,该变量表示选择了学生路径(ai=1)还是教师路径(ai=0)。因此,第i混合块的输出可以表示为:
![]()
其中Hi和Hi+1表示第i个混合块的输入和输出。f S i(·)是学生区的功能。f Ti(·)是教师模块的嵌套函数。
如果ai=1,则选择学生路径,等式(2)简化为:
![]()
如果ai=0,则选择教师路径,等式(2)简化为: ![]()
这意味着混合模块退化为教师模块。接下来,我们将第i个混合块中选择学生路径的概率表示为pi=P(ai=1)。因此,每个学生模块随机被概率为(1-pi)的教师模块替换。交换的教师模块可以与学生模块交互,激发学生的潜力。
学生模块被教师模块以随机方式替换,这意味着教师可以在许多不同的情况下通过互动引导学生。相比之下,通过手动定义的方式在教师模块中进行交换,教师只能在有限的情况下指导学生。因此,为了尽可能多地遍历不同的情况,学生块以随机方式被教师块替换。此外,我们只假设交换的教师块可以输出语义相似但比原始学生块更好的特征图。我们不需要相同模式或相同深度的教师和学生网络。
蒸馏阶段:当图像特征通过每个混合块时,在蒸馏阶段随机选择路径。让我们考虑两种极端情况。第一个是所有混合块的pi=1。在每个混合块中选择学生路径,混合网络成为学生网络。第二个是所有混合块的pi=0。在这种情况下,选择所有教师路径,混合网络成为教师网络。在其他(0<pi<1)的情况下,输入随机通过每个混合块中的学生路径或教师路径。交换的教师模块与学生模块一起训练,因此它们可以响应上一个学生模块的输出,并进一步提供更好的功能来激励下一个学生模块。在蒸馏阶段之前,从预训练教师网络中相应的教师模块加载每个混合模块中教师模块的参数。在蒸馏过程中,这些参数被冻结,这意味着教师参数不会被更新,批次标准化层仍然使用小批次统计数据。每个混合块中的学生块和其他共享部分都随机初始化。混合网络Lh的优化损失函数可以表示为:
![]()
其中,γ(·,·)是任务特定的损失。y表示真实标签,^yh是混合网络的预测结果。在每一步中,只更新特征图经过的学生部分(共享部分被视为学生部分,因为它们是从头开始训练的)。
将公式(5)与公式(1)进行比较,我们可以看到我们提出的方法不需要额外的蒸馏损失来驱动知识蒸馏过程。因此,可以避免费力地搜索最优超参数来平衡任务特定损失和不同的蒸馏损失。此外,我们提出的方法不需要对教师网络进行复杂的知识转换和额外的正向计算,从而实现了一个高效的蒸馏过程(培训时间比较见第4.5节)。
测试阶段:由于知识提炼旨在提高学生网络的性能,我们测试整个学生网络,以检查学生是否能够实现性能改进。为了方便验证,我们在测试阶段将概率pi固定为1。在这种情况下,混合网络在测试阶段成为学生网络。同时,对于实际部署,直接使用笨重的混合网络是不合理的。我们可以通过将学生网络从混合网络中分离出来进行进一步推理来减少资源消耗的负担。
3.3. 概率表
教师网络和学生之间的互动水平由pi控制。pi值越小,表明学生网络与相应的教师模块的交互越多。为简单起见,我们假设p1=p2=…=pi=…=pB,其中B是混合块的数量。这表明每个混合块共享相同的交互规则。为了合适地使用交互机制,我们提出了三种pi变化的概率表:1)统一计划,2)线性增长计划和3)回顾计划。下面详细讨论这些概率表。
统一的时间表:最简单的概率表是固定pi=pstart ∈{0,1},适用于蒸馏阶段的所有epoch。这意味着交互级别不会改变。有关示意图,请参见图3a。
线性增长时间表:随着epoch的增加,教师网络可以像[24,18,19]那样较少地参与蒸馏过程,因为学生网络逐渐变得更强大,能够自行处理任务。因此,我们根据epoch数的函数设置pi的值,并提出一个简单的线性增长计划。在每个混合块中选择学生路径的概率线性增加;第一个历元为pi=pstart∈{0,1},最后一个历元为pi=1(见图3b)。线性增长时间表表明,随着知识蒸馏过程的进行,学生与教师之间的互动水平逐渐降低。生动地说,在早期,老师通过频繁的互动来教学生,而在后期,学生试图自己解决问题。
复习时间表:上述计划忽略了训练期间学习率的变化。当学习率降低时,优化算法会缩小参数搜索半径,以便进行更精确的调整。因此,当学习率降低时,我们将pi重置为pstart,以便教师可以与学生重新交流,以获得更好的指导。在学习率保持不变的区间内,概率从pi=pstart ∈{0,1}线性增加到pi=1。图3c表示出了示意图。我们把这种概率表称为复习表,因为它就像老师在完成一个单元后进行复习课,这样学生就可以更牢固地掌握知识。
不同概率计划的有效性将在第4.1节中进行实验验证。
4.实验
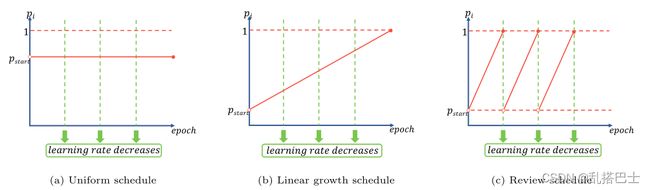
图3。具有不同概率计划的pi示意图。垂直绿色虚线表示学习率降低的时间。

表1.CIFAR-10和CIFAR-100上每个概率计划的最佳结果。括号中的数字代表获得相应结果时pstart的值。每个数据集的不同概率计划中的最佳性能以粗体显示。
由上图可知,复习时间表的效果优于线性增长时间表优于统一时间表。
详情见原文,还有许多其他实验对比结果在此未列出
5.结论
本文提出了一种简单而有效的知识提取方法——交互式知识提取(IAKD)。通过在每个步骤中随机交换教师块来替换学生块,我们实现了教师网络和学生网络之间的交互。为了合理利用精馏过程中的相互作用机制,我们提出了三种概率调度。我们的IAKD不需要额外的蒸馏损失来驱动蒸馏过程,并且是对传统知识蒸馏方法的补充。大量实验表明,所提出的IAKD可以提高学生网络在各种图像分类任务中的性能。我们提出的IAKD不是模仿教师的特征表示空间,而是直接利用教师强大的特征转换能力来激励学生,为知识提炼提供了一个新的视角。