一文简要了解词义消歧与实体消歧
每天给你送来NLP技术干货!
来自:AI算法小喵
写在前面
最近刚开始调研实体消歧方面的相关工作,这里先开一个头吧。希望大家可以通过这篇简要的文章对实体消歧任务本身有一个基本的认识。
1. 背景:词义消歧与实体消歧
1.1 词义消歧
自然语言文本中存在着大量的多义词,而多义词的存在也会影响人对文本的语义理解,让人对文本的意思产生混淆。
词义消岐(Word Sense Disambiguation,简称WSD) 是NLP中一个非常基本的任务,旨在确定多义词在具体语境中的确切意义。
在词义消歧中,同一词语的不同义项会作为候选词。我们需要在所有候选词中找到与文本中目标词语最接近的那个义项。这里“义项”指的是词是词典中的某个具体表示。
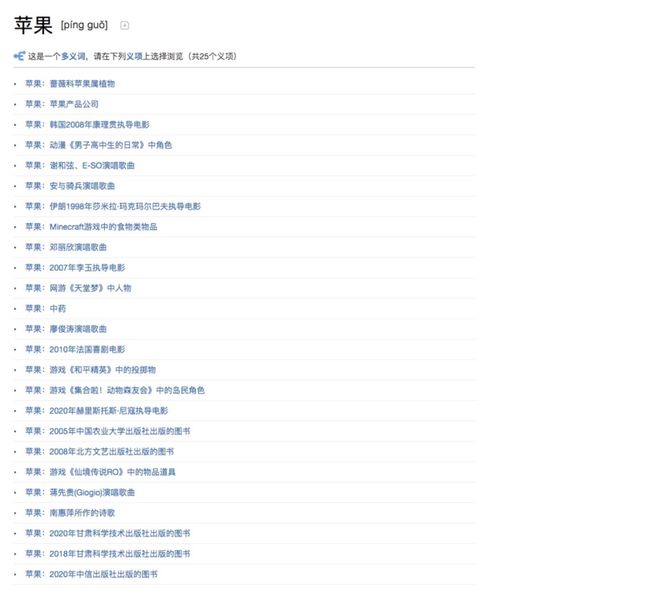
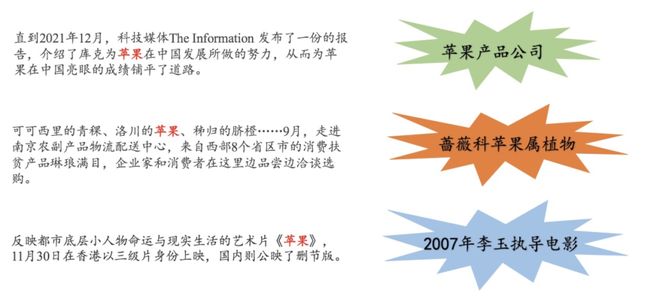
如上图所示,「苹果」在百度百科中共有25个义项,单说「苹果」我们可能并不知道说的是「苹果公司」还是「水果里的苹果」。但结合具体的上下文语境,我们就可以很好地对「苹果」消歧,从而明确「苹果」的具体含义:
1.2 实体消歧
实体链指/实体链接(Entity Linking,简称 EL) 在知识图谱构建、信息检索和问答系统等领域具有广泛的应用价值。
实体链指的主要目标是识别上下文中的实体指称具体指代现实世界中的哪一个实体,也就是将实体指称项映射到知识库中的相应实体上去。
具体而言,实体链指一般包括实体识别、候选实体获取、实体消歧这三个主要环节。之所以需要实体消歧,而不是直接将实体识别的结果放入知识图谱的原因主要有两方面:
多样性(即多词同义):同一实体在文本中会有不同的指称。比如:甜瓜、安东尼、和瓜哥都指美国职业篮球运动员卡梅隆·凯恩·安东尼。
歧义性(即一词多义):相同的实体指称在不同的上下文中可以指不同的实体。比如:迈克尔·乔丹可能指美国篮球运动员,也可能指爱尔兰政治家等。
1.3 总结
从以上说明来看,其实词义消歧与实体消歧具有一定相似性, 二者的目的都是处理文本中词汇歧义的问题. 主要区别在于:
在词义消歧中的词义通常是固定的, 可根据目标词在词典中的义项来列举;
在实体消歧中, 实体词义无法列举,所以需要前序步骤候选实体获取;
此外,实体词的词义数目大于普通词,这个主要还是跟知识库的量级相关。
2. 相关论文
这里我们主要给大家推荐两篇近期发表的论文:
词义消歧:《ESC: Redesigning WSD with Extractive Sense Comprehension》
实体消歧:《ExtEnD: Extractive Entity Disambiguation》
两篇论文的模型都非常简单,个人觉得关键或者说亮点主要在于他们对问题的转换。其实,从这两篇论文的名字就能看出端倪:都是将消歧问题转换成了抽取式问题。
2.1 EXTENE 实体消歧
论文名称:《ExtEnD: Extractive Entity Disambiguation》
论文链接:https://aclanthology.org/2022.acl-long.177.pdf
代码地址:https://github.com/SapienzaNLP/extend.

如上图所示,EXTEND 将实体消歧任务转换为了抽取式任务,或者说MRC类任务。具体地:
将含有目标实体指称项的文本当作Query;
将知识库中对应的所有候选实体及其描述当作Context;
二者拼接然后预测Answer的Span(start\end prediction,start-end matching),这里的Answer就是在知识库中目标实体指称实际关联的实体。
好了,这就是 EXTEND 论文的核心思想。是不是感觉模型已经跃然纸上了,整体上应该和我们之前在 一文详解关系抽取模型 CasRel、实体识别LEAR论文阅读笔记、 实体识别BERT-MRC论文阅读笔记中介绍过的模型类似。
2.2 ESC 词义消歧
论文名称:《ESC: Redesigning WSD with Extractive Sense Comprehension》
论文链接:https://aclanthology.org/2021.naacl-main.371.pdf
代码地址:https://github.com/SapienzaNLP/esc
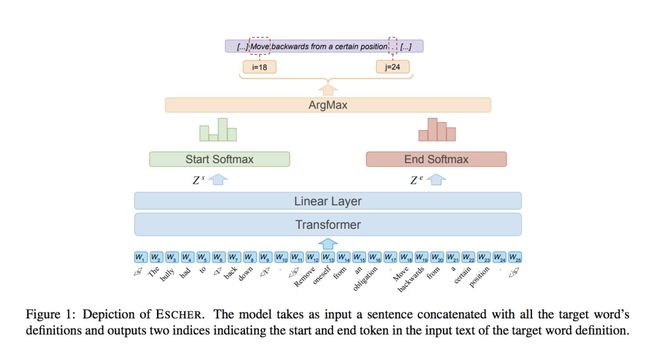
ESC 的模型架构和 EXTEND 是相似的。整体上首先将输入的上下文和目标词的所有义项拼接,模型的输出则是目标词真正义项的起始和终止位置。
2.3 总结
论文的具体细节就不在本文里赘述了,大家可根据链接下载原文阅读。此外,两篇论文都公布了源码,大家也可以快速利用源码在一些开源数据上进行实验。
当然也有一些相关比赛,比如百度:实体链指[1]目前就还在进行中:
我目前看到的几个还是比较一致的做法,打分➕排序:
比如实体链指比赛方案分享[2]: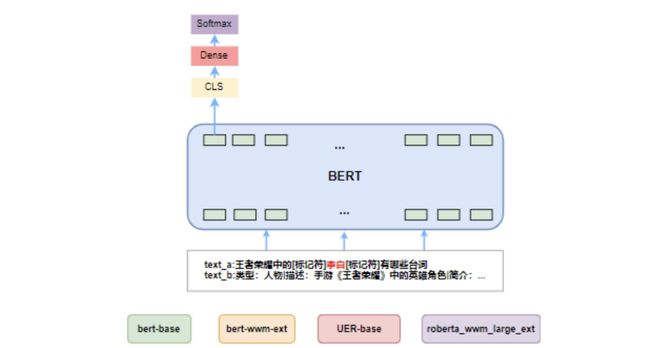
CCKS&百度 2019中文短文本的实体链指 第一名解决方案[3]: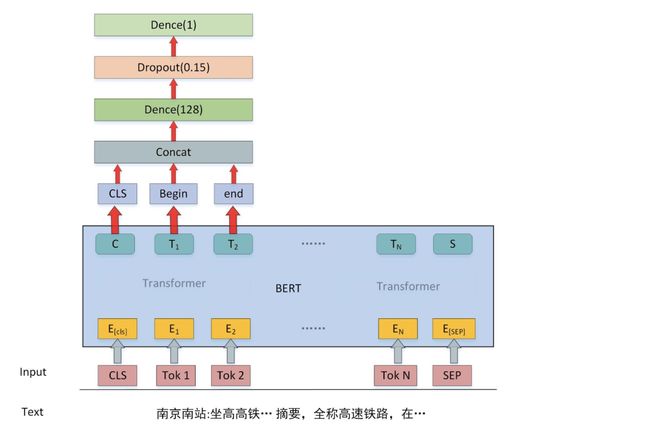
大家可以将论文的模型适配到中文场景下,然后尝试在这个比赛的实体消歧环节使用,看看效果如何。
还是一样,如果本文对你有帮助的话,欢迎点赞&在看&分享,这对我继续分享&创作优质文章非常重要。感谢!
参考资料
[1]
百度:实体链指: https://aistudio.baidu.com/aistudio/competition/detail/83/0/introduction
[2]实体链指比赛方案分享: https://aistudio.baidu.com/aistudio/projectdetail/1331020?channelType=0&channel=0
[3]CCKS&百度 2019中文短文本的实体链指 第一名解决方案: https://github.com/panchunguang/ccks_baidu_entity_link
论文解读投稿,让你的文章被更多不同背景、不同方向的人看到,不被石沉大海,或许还能增加不少引用的呦~ 投稿加下面微信备注“投稿”即可。
最近文章
EMNLP 2022 和 COLING 2022,投哪个会议比较好?
一种全新易用的基于Word-Word关系的NER统一模型
阿里+北大 | 在梯度上做简单mask竟有如此的神奇效果
ACL'22 | 快手+中科院提出一种数据增强方法:Text Smoothing
下载一:中文版!学习TensorFlow、PyTorch、机器学习、深度学习和数据结构五件套! 后台回复【五件套】
下载二:南大模式识别PPT 后台回复【南大模式识别】投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注呦
整理不易,还望给个在看!