「NLP入门系列」8. 使用机器学习进行文本分类
来源 | Natural Language Processing for Beginners
作者 | AI Publishing
翻译 | 悉尼没睡醒
校对 | gongyouliu
编辑 | auroral-L
全文共2789字,预计阅读时间35分钟。
第八章 使用机器学习进行文本分类
1. IMDB 电影情感分析
1.1 导入库
1.2 导入数据集
1.3 数据清理
1.4 将文本转为数字
1.5 训练模型
1.6 评估模型效果
1.7 对于单个事例的预测
2. 垃圾与非垃圾信息的分类
2.1 导入库
2.2 导入数据
2.3 数据清理
2.4 将文本转为数字
2.5 训练模型
2.6 评估模型效果
2.7 对于单个事例的预测
文本分类是自然语言处理最常用的应用之一。文本分类是基于文档内容将推文、消息、电子邮件或文章形式的文本文档分类为预定义类别的过程。文本分类有多种应用。例如,谷歌使用文本分类技术自动将垃圾邮件与原始电子邮件分开。同样,许多公司使用文本分类通过分析他们的推文或 Facebook 帖子来寻找对其产品的公众情绪。
在本章中,你将学习如何使用机器学习技术进行文本分类。在下一章中,你将看到如何使用深度学习技术进行文本分类。所以,让我们开始吧。
1. IMDB电影情感分析
你将在本章中学习的第一个文本分类应用是 IMDB 电影情感分析。该数据集将包含对 IMDB 的公开评论(www.imdb.com),我们的任务是将电影评论分类为正面或负面意见。那么让我们开始吧。
第一步是导入所需的库。
1.1 导入库

此任务的数据集位于 Resources/Datasets 文件夹中,名称为“imdb.reviews.csv”。以下脚本将 CSV 文件导入你的应用程序并打印数据集的前五行。
1.2 导入数据集
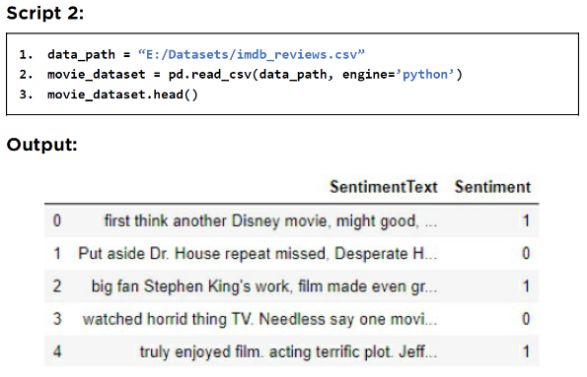
从输出中,你可以看到数据集包含 SentimentText 和 Sentiment 两列。前者包含关于电影的文字评论,而后者包含用户对相应电影的意见。在情绪栏中,1 表示正面意见,而 0 表示负面意见。
让我们看看数据集中的行数。

输出展示了这个数据集包含25000条记录。

接下来,我们可以使用饼图输出正面和负面用户评论的分布,如下所示:

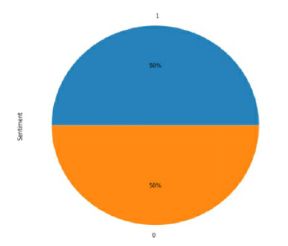
饼图显示一半的评论是正面的,而另一半包含负面的评论。
1.3 数据清理
在我们根据训练数据实际训练机器学习模型之前,我们需要从文本中删除特殊字符和数字。删除特殊字符和数字会在文本中创建空格,这些空格也需要删除。
在清理数据之前,我们首先将数据分为文本评论和用户情绪。

以下脚本定义了一个 clean_text() 方法,该方法接受一个文本字符串并返回一个去除了数字、特殊字符和多个空格的字符串。文本清理的过程已经在第4章详细解释过。

以下脚本调用 clean_text() 方法并预处理数据集中的所有用户评论。

1.4 将文本转为数字
在第 7 章中,你学习到我们需要先将文本文档转换为数字,然后才能将机器学习技术应用于文本文档。在这方面,你学习了各种技术,即 Bag of Words、TF-IDF、Word Embeddings 等。在本节中,你将使用 TF-IDF 技术将文本转换为数字。在下一章中,你将使用词嵌入方法。
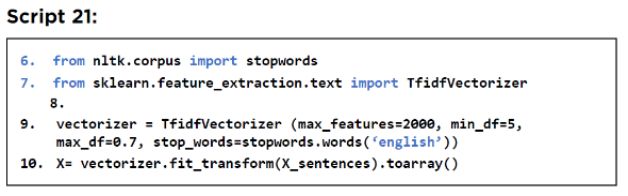
以下脚本将文本转换为数字。此处,max_features 属性指定最多应使用 2,000 个出现次数最多的词来创建特征词典。这里的 min_df 属性指定只包含在所有文档中出现至少五次的单词。Max_df 定义不包括出现在超过 70% 的文档中的词。

文本数据已被处理。现在,我们可以在文本上训练我们的机器学习模型。
1.5 训练模型
我们将开发一个有监督的文本分类模型,因为在数据集中,我们已经有了公众情绪(即意见)。我们将我们的数据分为训练集和测试集。该算法将使用训练数据学习文本评论和意见之间的关系,因为文本评论和相应的意见都在训练数据集中给出。
一旦机器学习模型在训练数据上得到训练,测试数据(仅包括文本评论)将作为模型的输入。然后,该模型将预测所有文本评论的未知情绪。
然后将预测的情绪与测试数据中的实际情绪进行比较,以评估文本分类模型的效果。
以下脚本将数据划分为训练集和测试集。

要训练机器学习模型,你将使用 RandomForestClassifier (https://bit.ly/2V1G0k0) 模型,这是最常用的机器学习分类模型之一。
RandomForestClassifier 类的 fit() 方法用于训练模型。

1.6 评估模型效果
一旦训练了监督机器学习模型,你就可以对测试数据进行预测。为此,你可以使用 RandomForestClassifer 的 predict() 方法。要将预测与实际输出进行比较,你可以使用混淆矩阵、准确率、召回率和 F1 度量。以下脚本评估模型效果。

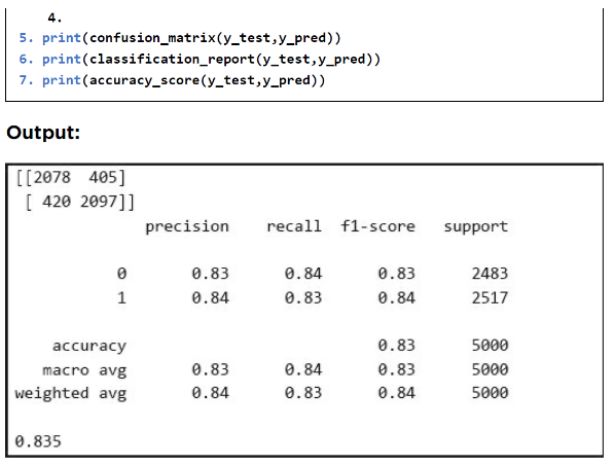
输出显示我们的模型在测试集上达到了 83.5% 的准确率。
1.7 对于单个事例的预测
现在,我们准备对新文本进行预测。首先使用相同的 TfidfVectorizer 将文本转换为数字形式,该 TfidfVectorizer 用于将文本转换为数字以训练模型。然后可以将文本的数字形式传递给分类器对象的 predict 方法以进行预测。在下面的脚本中,我们试图找到一个随机句子的情绪:“这部电影真的很好,我喜欢它。”


输出显示情绪为 1,这意味着我们的模型认为这是一个正面评价,实际上确实如此。
因此,我们可以说我们的文本分类模型做得很好。
2. 垃圾与非垃圾信息的分类
在上一节中,你看到了用于电影评论情感分析的文本分类示例。在本节中,你将看到我们如何使用文本分类进行垃圾和非垃圾邮件分类。非垃圾消息是原始和真实的消息,而垃圾邮件包含垃圾邮件信息,例如“尼日利亚公主向你提供 1000 万美元”。
非垃圾和垃圾邮件分类的过程与情感分析非常相似。
2.1 导入库
我们从导入库开始。

2.2 导入数据
此任务的数据集可在此 Github 链接中找到:https://bit.ly/3djTeyX
该数据集也位于 Resources/Datasets 文件夹中,名称为 spam.csv。
以下脚本导入数据集并显示其前五行。
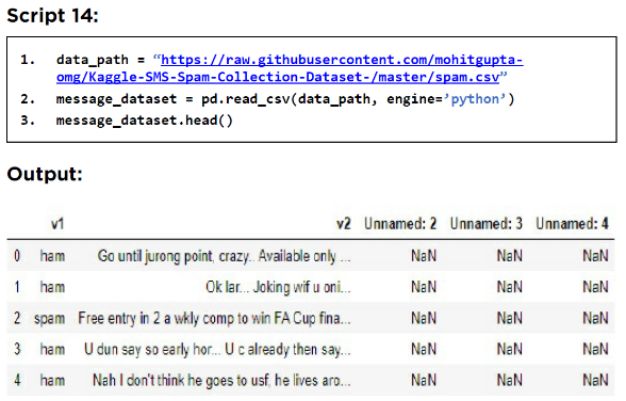
输出显示数据集包含五列。
但是,只有 v1 和 v2 列包含我们需要的数据。v1 列包含有关邮件是垃圾邮件还是非垃圾邮件的信息,而 v2 列包含邮件的文本。
以下脚本显示数据集中的总行数:


输出显示数据集包含 5,572 行。
由于我们只需要 v1 和 v2 列,我们将过滤这两列并删除剩余的列,如以下脚本所示:
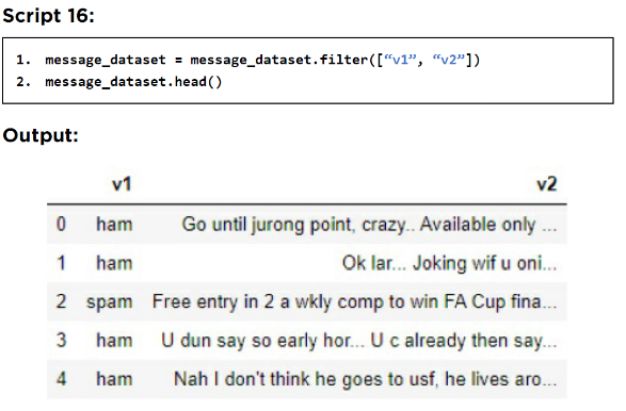
以下脚本绘制了非垃圾和垃圾邮件的分布。


输出显示 87% 的邮件是垃圾邮件,而只有 13% 的邮件是垃圾邮件。
2.3 数据清理
以下脚本将数据划分为特征和标签。
特征集由消息的文本内容组成,而标签对应于有关消息是垃圾邮件还是非垃圾邮件的信息。

以下脚本clean_text()定义了清洗文本消息的操作。
![]()

以下脚本清洗数据集中的所有消息。

2.4 将文本转为数字
正如我们在情感分析中所做的那样,我们也需要将文本转换为数字以进行非垃圾和垃圾邮件分类。以下脚本使用 TF-IDF 方法将文本转换为数字。
2.5 训练模型
数据现在已准备好用于训练机器学习模型。
但首先,我们需要将我们的数据分为训练集和测试集,下面的脚本就是这样做的。

最后,模型训练在以下脚本中进行。

2.6 评估模型效果
最后一步是对训练集进行预测并评估模型效果,这在以下脚本中完成:


输出显示,我们的模型在预测邮件是垃圾邮件还是非垃圾邮件时的准确率为 98.02%,这种效果是非常好的。
2.7 对于单个事例的预测
正如我们在情感分析中所做的那样,我们可以对单个句子进行预测。让我们从数据集中随机提取一个句子。

输出显示数据集中的句子编号 56 是垃圾邮件。句子的文本也显示在输出中。让我们将这句话传递给我们的 非垃圾 和垃圾邮件文本分类器,看看它的结果怎样:

该模型正确地将邮件分类为垃圾邮件。
延展阅读 – 机器学习与混淆矩阵
要了解有关 Scikit Learn 支持的机器学习算法的更多信息,请查看此链接:https://bit.ly/2YfKG7Q。
要了解有关混淆矩阵、准确性、F1、召回率和精度的更多信息,请查看此链接:https://bit.ly/3hW2JI6。
