mmcv拓展cuda算子入门篇
文章目录
- 前言
- 1、整体目录结构
- 1、roi_align_cuda_kernel.cu
- 2、核函数的声明和动态分发
- 3、roi_align.cpp借助c++调用核函数
- 4、pybind绑定--Python调用c++
- 5、roi_align.py
- 总结
前言
本篇主要介绍mmcv中ops文件夹下算子的拓展流程,由于本人也是菜鸡,许多代码细节看不懂。仅能说个大概,若有疑问或者感兴趣,欢迎讨论:+q2541612007,一起共同进步。
1、整体目录结构
mmcv中的ops如下图所示:在本文中,为了便于读者从易到难理解拓展流程,我会倒叙进行讲解并以roi_align算子为例进行讲解。
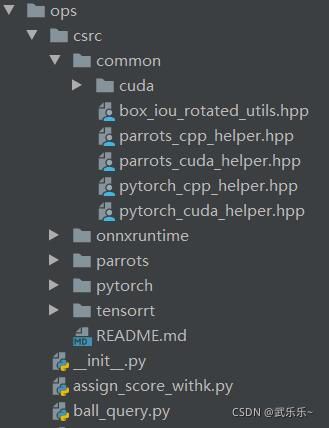
本文只关注common和pytorch文件夹内容,因为parrots和onnx和tensorrt我不懂。其中common实现的是核函数以及一些常用头文件(比如.hpp那些文件);pytorch包括cuda核函数声明以及cpp封装核函数以及完成Python中绑定;最后其余.py文件就是继承自Function类的pytorch调用核函数的文件了。
1、roi_align_cuda_kernel.cu
本节代码就是最底层roi_align模块的最底层cuda代码的实现。在common/cuda/roi_align_cuda_kernel.cu文件内。核心就是用cuda实现了roi_align的forward和backward两个核函数,此处cuda的代码我不详细说了,后续有空会写写。这两个核函数的名字分别为== roi_align_forward_cuda_kernel和roi_align_backward_cuda_kernel==。
/*** Forward ***/
template <typename T>
__global__ void roi_align_forward_cuda_kernel()
/*** Backward ***/
template <typename T>
__global__ void roi_align_backward_cuda_kernel()
2、核函数的声明和动态分发
在pytorch/cuda/roi_align_cuda.cu主要声明上节中的两个核函数,并动态分发出去(我不懂这个,欢迎大佬指点)。此处还是属于cuda代码部分。
#include "pytorch_cuda_helper.hpp"
#include "roi_align_cuda_kernel.cuh" // 导入定义的核函数
//核函数声明
void ROIAlignForwardCUDAKernelLauncher(Tensor input, Tensor rois, Tensor output,
Tensor argmax_y, Tensor argmax_x,
int aligned_height, int aligned_width,
float spatial_scale, int sampling_ratio,
int pool_mode, bool aligned) {
int output_size = output.numel();
int channels = input.size(1);
int height = input.size(2);
int width = input.size(3);
at::cuda::CUDAGuard device_guard(input.device());
cudaStream_t stream = at::cuda::getCurrentCUDAStream();
//动态分发机制
AT_DISPATCH_FLOATING_TYPES_AND_HALF(
input.scalar_type(), "roi_align_forward_cuda_kernel", [&] {
roi_align_forward_cuda_kernel<scalar_t>
<<<GET_BLOCKS(output_size), THREADS_PER_BLOCK, 0, stream>>>(
output_size, input.data_ptr<scalar_t>(),
rois.data_ptr<scalar_t>(), output.data_ptr<scalar_t>(),
argmax_y.data_ptr<scalar_t>(), argmax_x.data_ptr<scalar_t>(),
aligned_height, aligned_width,
static_cast<scalar_t>(spatial_scale), sampling_ratio, pool_mode,
aligned, channels, height, width);
});
AT_CUDA_CHECK(cudaGetLastError());
}
// 核函数Launcher声明
void ROIAlignBackwardCUDAKernelLauncher(Tensor grad_output, Tensor rois,
Tensor argmax_y, Tensor argmax_x,
Tensor grad_input, int aligned_height,
int aligned_width, float spatial_scale,
int sampling_ratio, int pool_mode,
bool aligned) {
int output_size = grad_output.numel();
int channels = grad_input.size(1);
int height = grad_input.size(2);
int width = grad_input.size(3);
at::cuda::CUDAGuard device_guard(grad_output.device());
cudaStream_t stream = at::cuda::getCurrentCUDAStream();
// 动态分发出去
AT_DISPATCH_FLOATING_TYPES_AND_HALF(
grad_output.scalar_type(), "roi_align_backward_cuda_kernel", [&] {
roi_align_backward_cuda_kernel<scalar_t>
<<<GET_BLOCKS(output_size), THREADS_PER_BLOCK, 0, stream>>>(
output_size, grad_output.data_ptr<scalar_t>(),
rois.data_ptr<scalar_t>(), argmax_y.data_ptr<scalar_t>(),
argmax_x.data_ptr<scalar_t>(), grad_input.data_ptr<scalar_t>(),
aligned_height, aligned_width,
static_cast<scalar_t>(spatial_scale), sampling_ratio, pool_mode,
aligned, channels, height, width);
});
AT_CUDA_CHECK(cudaGetLastError());
}
3、roi_align.cpp借助c++调用核函数
上述完成动态分发后,需要用.cpp完成包装核函数,在pytorch/roi_align.cpp下:
// Copyright (c) OpenMMLab. All rights reserved
#include "pytorch_cpp_helper.hpp"
#ifdef MMCV_WITH_CUDA
//”启动核函数“的声明(命名方式为核函数的大写加一个Launcher)
void ROIAlignForwardCUDAKernelLauncher(Tensor input, Tensor rois, Tensor output,
Tensor argmax_y, Tensor argmax_x,
int aligned_height, int aligned_width,
float spatial_scale, int sampling_ratio,
int pool_mode, bool aligned);
void ROIAlignBackwardCUDAKernelLauncher(Tensor grad_output, Tensor rois,
Tensor argmax_y, Tensor argmax_x,
Tensor grad_input, int aligned_height,
int aligned_width, float spatial_scale,
int sampling_ratio, int pool_mode,
bool aligned);
//此处用roi_align_forwar_cuda对启动核函数进行封装。
void roi_align_forward_cuda(Tensor input, Tensor rois, Tensor output,
Tensor argmax_y, Tensor argmax_x,
int aligned_height, int aligned_width,
float spatial_scale, int sampling_ratio,
int pool_mode, bool aligned) {
ROIAlignForwardCUDAKernelLauncher(
input, rois, output, argmax_y, argmax_x, aligned_height, aligned_width,
spatial_scale, sampling_ratio, pool_mode, aligned);
}
void roi_align_backward_cuda(Tensor grad_output, Tensor rois, Tensor argmax_y,
Tensor argmax_x, Tensor grad_input,
int aligned_height, int aligned_width,
float spatial_scale, int sampling_ratio,
int pool_mode, bool aligned) {
ROIAlignBackwardCUDAKernelLauncher(
grad_output, rois, argmax_y, argmax_x, grad_input, aligned_height,
aligned_width, spatial_scale, sampling_ratio, pool_mode, aligned);
}
#endif
// 底下是cpu版本的Launcher
void ROIAlignForwardCPULauncher(Tensor input, Tensor rois, Tensor output,
Tensor argmax_y, Tensor argmax_x,
int aligned_height, int aligned_width,
float spatial_scale, int sampling_ratio,
int pool_mode, bool aligned);
void ROIAlignBackwardCPULauncher(Tensor grad_output, Tensor rois,
Tensor argmax_y, Tensor argmax_x,
Tensor grad_input, int aligned_height,
int aligned_width, float spatial_scale,
int sampling_ratio, int pool_mode,
bool aligned);
//cpp对cpu版本的Launcher进行封装
void roi_align_forward_cpu(Tensor input, Tensor rois, Tensor output,
Tensor argmax_y, Tensor argmax_x, int aligned_height,
int aligned_width, float spatial_scale,
int sampling_ratio, int pool_mode, bool aligned) {
ROIAlignForwardCPULauncher(input, rois, output, argmax_y, argmax_x,
aligned_height, aligned_width, spatial_scale,
sampling_ratio, pool_mode, aligned);
}
void roi_align_backward_cpu(Tensor grad_output, Tensor rois, Tensor argmax_y,
Tensor argmax_x, Tensor grad_input,
int aligned_height, int aligned_width,
float spatial_scale, int sampling_ratio,
int pool_mode, bool aligned) {
ROIAlignBackwardCPULauncher(grad_output, rois, argmax_y, argmax_x, grad_input,
aligned_height, aligned_width, spatial_scale,
sampling_ratio, pool_mode, aligned);
}
// 创建了一个统一接口,有cuda版本编译cuda版本,没有则编译cpu。统一将cuda和cpu封装成一个接口
// roi_align_forward和roi_align_backward。
void roi_align_forward(Tensor input, Tensor rois, Tensor output,
Tensor argmax_y, Tensor argmax_x, int aligned_height,
int aligned_width, float spatial_scale,
int sampling_ratio, int pool_mode, bool aligned) {
if (input.device().is_cuda()) {
#ifdef MMCV_WITH_CUDA
CHECK_CUDA_INPUT(input);
CHECK_CUDA_INPUT(rois);
CHECK_CUDA_INPUT(output);
CHECK_CUDA_INPUT(argmax_y);
CHECK_CUDA_INPUT(argmax_x);
roi_align_forward_cuda(input, rois, output, argmax_y, argmax_x,
aligned_height, aligned_width, spatial_scale,
sampling_ratio, pool_mode, aligned);
#else
AT_ERROR("RoIAlign is not compiled with GPU support");
#endif
} else {
CHECK_CPU_INPUT(input);
CHECK_CPU_INPUT(rois);
CHECK_CPU_INPUT(output);
CHECK_CPU_INPUT(argmax_y);
CHECK_CPU_INPUT(argmax_x);
roi_align_forward_cpu(input, rois, output, argmax_y, argmax_x,
aligned_height, aligned_width, spatial_scale,
sampling_ratio, pool_mode, aligned);
}
}
void roi_align_backward(Tensor grad_output, Tensor rois, Tensor argmax_y,
Tensor argmax_x, Tensor grad_input, int aligned_height,
int aligned_width, float spatial_scale,
int sampling_ratio, int pool_mode, bool aligned) {
if (grad_output.device().is_cuda()) {
#ifdef MMCV_WITH_CUDA
CHECK_CUDA_INPUT(grad_output);
CHECK_CUDA_INPUT(rois);
CHECK_CUDA_INPUT(argmax_y);
CHECK_CUDA_INPUT(argmax_x);
CHECK_CUDA_INPUT(grad_input);
roi_align_backward_cuda(grad_output, rois, argmax_y, argmax_x, grad_input,
aligned_height, aligned_width, spatial_scale,
sampling_ratio, pool_mode, aligned);
#else
AT_ERROR("RoIAlign is not compiled with GPU support");
#endif
} else {
CHECK_CPU_INPUT(grad_output);
CHECK_CPU_INPUT(rois);
CHECK_CPU_INPUT(argmax_y);
CHECK_CPU_INPUT(argmax_x);
CHECK_CPU_INPUT(grad_input);
roi_align_backward_cpu(grad_output, rois, argmax_y, argmax_x, grad_input,
aligned_height, aligned_width, spatial_scale,
sampling_ratio, pool_mode, aligned);
}
}
本部分主要用cpp对核函数进行封装,在cpp中调用Launcher函数,但是roi_align有cuda版本和cpu版本,但为了统一接口,mmcv将二个版本统一成一个接口:roi_align_forward和roi_align_backward。 根据实际情况决定调用cpu或者gpu。
4、pybind绑定–Python调用c++
我们用c++实现的代码要想在Python中调用,需要用到pybind完成二者绑定。绑定的代码在mmcv中ops/csrc/pytorch/pybind.cpp文件中,贴下对应的代码。
//c++中两个函数声明
void roi_align_forward(Tensor input, Tensor rois, Tensor output,
Tensor argmax_y, Tensor argmax_x, int aligned_height,
int aligned_width, float spatial_scale,
int sampling_ratio, int pool_mode, bool aligned);
void roi_align_backward(Tensor grad_output, Tensor rois, Tensor argmax_y,
Tensor argmax_x, Tensor grad_input, int aligned_height,
int aligned_width, float spatial_scale,
int sampling_ratio, int pool_mode, bool aligned);
// pybind完成绑定,用Python调用c++
PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
m.def("roi_align_forward", &roi_align_forward, "roi_align forward",
py::arg("input"), py::arg("rois"), py::arg("output"),
py::arg("argmax_y"), py::arg("argmax_x"), py::arg("aligned_height"),
py::arg("aligned_width"), py::arg("spatial_scale"),
py::arg("sampling_ratio"), py::arg("pool_mode"), py::arg("aligned"));
m.def("roi_align_backward", &roi_align_backward, "roi_align backward",
py::arg("grad_output"), py::arg("rois"), py::arg("argmax_y"),
py::arg("argmax_x"), py::arg("grad_input"), py::arg("aligned_height"),
py::arg("aligned_width"), py::arg("spatial_scale")}
其含义就是将第三节的cpp文件封装的两个api: roi_align_forward和roi_align_backward利用Python进行封装,封装名字为 roi_align_forward和roi_align_backward。
5、roi_align.py
贴下核心代码:
import torch
import torch.nn as nn
from torch.autograd import Function
from torch.autograd.function import once_differentiable
from torch.nn.modules.utils import _pair
from ..utils import deprecated_api_warning, ext_loader
ext_module = ext_loader.load_ext('_ext',
['roi_align_forward', 'roi_align_backward'])
class RoIAlignFunction(Function):
@staticmethod
def forward(ctx,
input,
rois,
output_size,
spatial_scale=1.0,
sampling_ratio=0,
pool_mode='avg',
aligned=True):
ext_module.roi_align_forward(
input,
rois,
output,
argmax_y,
argmax_x,
aligned_height=ctx.output_size[0],
aligned_width=ctx.output_size[1],
spatial_scale=ctx.spatial_scale,
sampling_ratio=ctx.sampling_ratio,
pool_mode=ctx.pool_mode,
aligned=ctx.aligned)
ctx.save_for_backward(rois, argmax_y, argmax_x)
return output
@staticmethod
@once_differentiable
def backward(ctx, grad_output):
return grad_input, None, None, None, None, None, None
roi_align = RoIAlignFunction.apply
前四节完成后,执行setup.py会生成编译好的.so的可执行文件,而mmcv统一用ext_module来调用这些文件。在pytorch中ROIAlign通过继承Function类然后实现forward和backward方法后,内部调用的方法就是pybind中绑定好的roi_align_forward和roi_align_backward。从而实现pytorch调用cuda的
总结
上述分析了mmcv中的调用cuda全流程,当然,我们目的肯定是能够自己拓展算子。以下是GitHub上mmcv拓展流程mmcv的readme。链接打不开我这截了图:
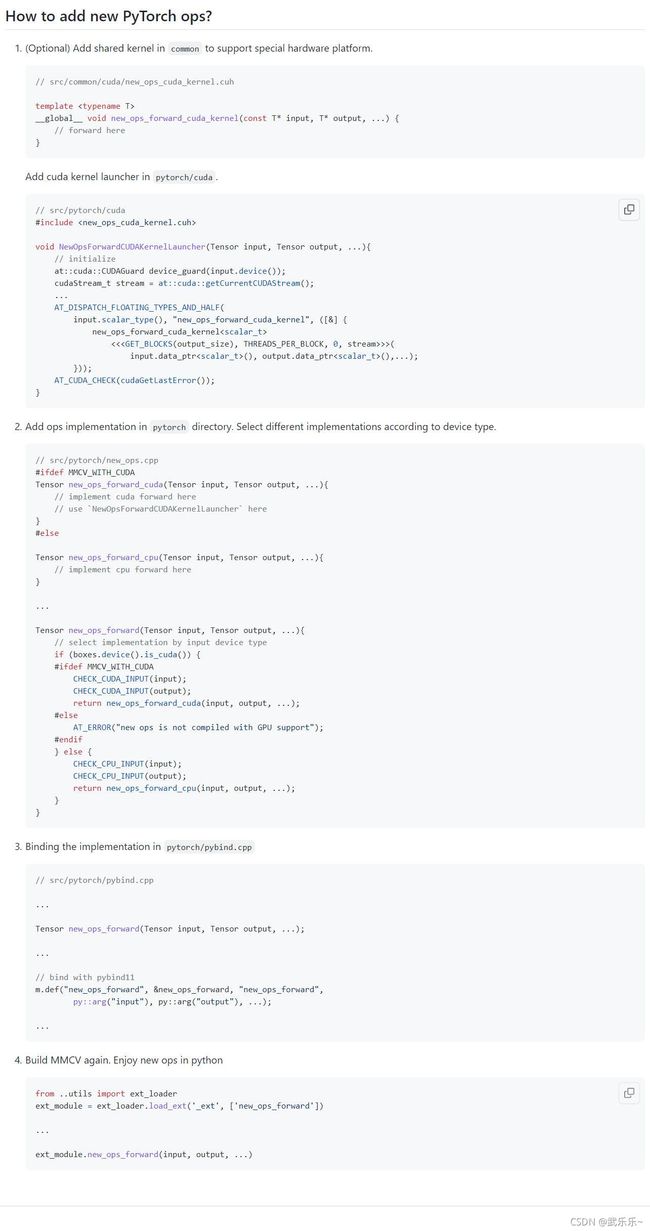
好多代码细节我也没看懂,若想一起交流,若有问题欢迎+vx:wulele2541612007,拉你进群探讨交流。.