知识追踪入门系列-论文资料汇总
Paper : 知识追踪相关论文
下载论文和代码见reference第一个链接
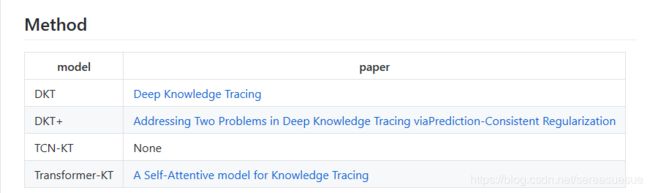
- Deep Knowledge Tracing:
首次提出将RNN用于知识追踪,并能够基于复杂的知识联系进行建模(如构建知识图谱)
- Deep Knowledge Tracing and Dynamic Student Classification for Knowledge Tracing(DKT-DSC)
跟第一篇论文比较相似,都用到了 LSTM,不同的是这篇论文还考虑了将学生进行分类,在进行预测的时候也有不同,
- How Deep is Knowledge Tracing
探究DKT利用到的统计规律并拓展BKT,从而使BKT拥有能够与DKT相匹配的能力
- Going Deeper with Deep Knowledge Tracing
对DKT和PFA,BKT进行了模型比较,对DKT模型能碾压其他两种模型的结果进行了怀疑并加以论证,进一步讨论了原论文能够得出上述结果的原因,对进一步使用DKT模型提供了参考。
- Incorporating Rich Features Into Deep Knowledge Tracing
对DKT使用上进行数据层扩展,扩展学生和问题层的数据输入,包括结合自动编码器对输入进行转换
- Addressing Two Problems in Deep Knowledge Tracing viaPrediction-Consistent Regularization
指出DKT模型现存缺点:对输入序列存在重构问题和预测结果的波动性,进而对上述问题提出了改善方法
- Exercise-Enhanced Sequential Modeling for Student Performance Prediction
将题面信息引入,不仅作为输入送入模型,而且将题目编码后的向量计算cosine相似度作为atention的socre
- A Self-Attentive model for Knowledge Tracing 使用Transformer应用于知识追踪
- 《Knowledge Tracing Machines: Factorization Machines for Knowledge Tracing》
使用传统的机器学习方法 FM 进行知识追踪,想法很独特,发表于 AAAI-2019
- 《Dynamic Key-Value Memory Networks for Knowledge Tracing》
使用键值对记忆网络进行知识追踪,重点学习记忆网络是如何动态更新的
- 《Knowledge Tracing with Sequential Key-Value Memory Networks》 使用了改进过的LSTM 和记忆网络进行知识追踪
Graphic neural network for knowledge tracing 该论文首次将图神经网络应用于知识追踪,
reference:https://github.com/sulingling123/Knowledge_Tracing
论文阅读笔记 https://sulingling123.github.io/2019/08/06/深度知识追踪/
未完待续。。。。。。
有关DKT实现找到了pytorch版本的具体实现
模型代码已经发布在github上,可点击这里查看和下载具体代码。
或者可以直接通过如下命令直接下载到本地:
git clone https://github.com/chsong513/DeepKnowledgeTracing-DKT-Pytorch.git
具体运行和使用方法参考GitHub项目上ReadMe。
项目结构-DKT
在DKT文件夹下包括两个文件夹:KTDataset和KnowledgeTracing。

数据集-KTDataset

KTDataset文件夹下有6个常用的知识追踪数据集,数据都已经处理成三行格式:
第一行:答题数
第二行:题目编号
第三行:答题结果,0表示错,1表示对
举例:
Note:可根据需要,按照数据格式自行添加新的数据集。
模型结构-KnowledgeTracing
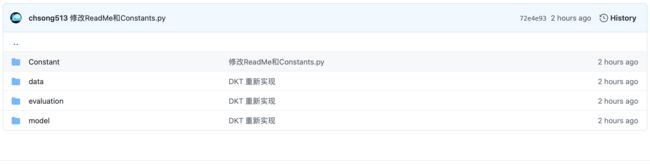
模型的整个流程都在KnowledgeTracing目录下,包括模型、参数设置、数据处理、模型训练和评估,分别在四个子目录下:model, Constant,data,evaluation。
参数设置-Constant
Constant下主要设置一些参数和超参数,超参数也分为四大块:数据集存储路径、数据集、题目数、模型超参数。
数据集存储路径
1 |
Dpath = '../../KTDataset' |
数据集:一共包括6个数据集
1 2 3 4 5 6 7 8 |
datasets = {
'assist2009' : 'assist2009',
'assist2015' : 'assist2015',
'assist2017' : 'assist2017',
'static2011' : 'static2011',
'kddcup2010' : 'kddcup2010',
'synthetic' : 'synthetic'
}
|
题目数:表示每个数据集里面题目的数量
1 2 3 4 5 6 7 8 |
numbers = {
'assist2009' : 124,
'assist2015' : 100,
'assist2017' : 102,
'static2011' : 1224,
'kddcup2010' : 661,
'synthetic' : 50
}
|
模型超参数:主要包括所用数据集、输入输出维度、学习率、最大步长、学习周期等。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
DATASET = datasets['static2011'] NUM_OF_QUESTIONS = numbers['static2011'] # the max step of RNN model MAX_STEP = 50 BATCH_SIZE = 64 LR = 0.002 EPOCH = 1000 #input dimension INPUT = NUM_OF_QUESTIONS * 2 # embedding dimension EMBED = NUM_OF_QUESTIONS # hidden layer dimension HIDDEN = 200 # nums of hidden layers LAYERS = 1 # output dimension OUTPUT = NUM_OF_QUESTIONS |
模型实现-model
模型在model目录下的RNNModel.py文件中实现,模型实际上就是一个简单的LSTM网络,其结构跟DKT原文中所讲述的结构一致,在LSTM模型最后添加了一个线性层和一个sigmoid激活函数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
class DKT(nn.Module):
def __init__(self, input_dim, hidden_dim, layer_dim, output_dim):
super(DKT, self).__init__()
self.hidden_dim = hidden_dim
self.layer_dim = layer_dim
self.output_dim = output_dim
self.rnn = nn.RNN(input_dim, hidden_dim, layer_dim, batch_first=True,nonlinearity='tanh')
self.fc = nn.Linear(self.hidden_dim, self.output_dim)
self.sig = nn.Sigmoid()
def forward(self, x):
h0 = Variable(torch.zeros(self.layer_dim, x.size(0), self.hidden_dim))
out,hn = self.rnn(x, h0)
res = self.sig(self.fc(out))
return res
|
数据处理-data
在data目录下包括三个文件:readdata.py、DKTDataSet.py、dataloader.py。它们的作用分别是定义数据的读取、pytorch框架下的数据集定义、以及pytorch框架下的dataloader的构造。
readata: 在readata.py文件中,定义了一个类:DataReader,从名字可以看出这是一个用来读取数据的类。其中包含两个函数getTrainData()和getTestData(),分别是用来读取训练数据和测试数据。两个函数的定义其实一模一样,只是名字不一样用来区分训练和测试数据,这样的写法有些冗余,后面会再做一些优化。
1 2 3 4 5 6 7 8 9 10 11 |
class DataReader():
def __init__(self, path, maxstep, numofques):
self.path = path
self.maxstep = maxstep
self.numofques = numofques
def getTrainData(self):
...
def getTestData(self):
...
|