读书笔记-白话机器学习的数学
文章目录
- 回归
-
- 线性回归
-
- 步骤
- 公式
- 使用矩阵表示
- 优化算法
- 问题
- 扩展
- 分类
-
- 感知机
-
- 步骤
- 公式
- 逻辑回归
-
- 公式
- 线性不可分
- 扩展
- 正则化
-
- 公式
- 基础
-
- 模型评估
-
- 分类问题
- 正则化
-
- 过拟合
-
- 正则化
- 参考
- 待学习
回归
线性回归
步骤
- 训练数据,画图
- 预测函数和目标函数
- 初始值是随机的
- 最小二乘法
- 1 2 \frac{1}{2} 21 是方便计算加的
- 梯度下降法
- 学习率 η \eta η
- 复合函数微分的链式法则
- 参数更新表达式
- 演示程序
- 标准化
- 差值阈值,跳出训练
公式
预测函数:
f θ ( x ) = θ 0 + θ 1 x f_\theta(x)= \theta_0 + \theta_1x fθ(x)=θ0+θ1x
目标函数(误差函数):
E ( θ ) = 1 2 ∑ i = 1 n ( y ( i ) − f θ ( x ( i ) ) ) 2 E(\theta) = \frac{1}{2}\sum_{i=1}^{n}(y^{(i)} - f_\theta(x^{(i)}))^2 E(θ)=21i=1∑n(y(i)−fθ(x(i)))2
梯度下降法表达式:
θ 0 : = θ 0 − η ∂ E ∂ θ 0 \theta_0 := \theta_0 - \eta\frac{\partial E}{\partial \theta_0} θ0:=θ0−η∂θ0∂E
链式法则:
u = E ( θ ) v = f θ ( x ) ∂ u ∂ θ 0 = ∂ u ∂ v ⋅ ∂ v ∂ θ 0 u= E(\theta) \\ v = f_\theta(x) \\ \frac{\partial u}{\partial \theta_0} = \frac{\partial u}{\partial v}\cdot\frac{\partial v}{\partial \theta_0} u=E(θ)v=fθ(x)∂θ0∂u=∂v∂u⋅∂θ0∂v
参数更新表达式:
u u u 对 v v v 的微分
∂ u ∂ v = ∂ ∂ v ( 1 2 ∑ i = 1 n ( y ( i ) − v ) 2 ) = 1 2 ∑ i = 1 n ( ∂ ∂ v ( y ( i ) − v ) 2 ) = 1 2 ∑ i = 1 n ( ∂ ∂ v ( y ( i ) 2 + v 2 − 2 y ( i ) v ) ) = 1 2 ∑ i = 1 n ( 2 v − 2 y ( i ) ) = ∑ i = 1 n ( v − y ( i ) ) \frac{\partial u}{\partial v}=\frac{\partial}{\partial v}(\frac{1}{2}\sum_{i=1}^{n}(y^{(i)} - v)^2) \\ = \frac{1}{2}\sum_{i=1}^{n}(\frac{\partial}{\partial v}(y^{(i)} - v)^2) \\ = \frac{1}{2}\sum_{i=1}^{n}(\frac{\partial}{\partial v}(y^{(i)^2} + v^2 - 2y^{(i)}v)) \\ = \frac{1}{2}\sum_{i=1}^{n}(2v - 2y^{(i)}) \\ = \sum_{i=1}^{n}( v - y^{(i)}) ∂v∂u=∂v∂(21i=1∑n(y(i)−v)2)=21i=1∑n(∂v∂(y(i)−v)2)=21i=1∑n(∂v∂(y(i)2+v2−2y(i)v))=21i=1∑n(2v−2y(i))=i=1∑n(v−y(i))
v v v 对 θ 0 \theta_0 θ0 的微分
∂ v ∂ θ 0 = ∂ ∂ θ 0 ( θ 0 + θ 1 x ) = 1 \frac{\partial v}{\partial \theta_0} = \frac{\partial}{\partial \theta_0}(\theta_0 + \theta_1x) \\ = 1 ∂θ0∂v=∂θ0∂(θ0+θ1x)=1
u u u 对 θ 0 \theta_0 θ0 的微分
∂ u ∂ θ 0 = ∂ u ∂ v ⋅ ∂ v ∂ θ 0 = ∑ i = 1 n ( v − y ( i ) ) ⋅ 1 = ∑ i = 1 n ( f θ ( x ( i ) ) − y ( i ) ) \frac{\partial u}{\partial \theta_0} = \frac{\partial u}{\partial v}\cdot\frac{\partial v}{\partial \theta_0} \\ = \sum_{i=1}^{n}( v - y^{(i)})\cdot 1\\ = \sum_{i=1}^{n}( f_\theta(x^{(i)}) - y^{(i)}) ∂θ0∂u=∂v∂u⋅∂θ0∂v=i=1∑n(v−y(i))⋅1=i=1∑n(fθ(x(i))−y(i))
θ 0 \theta_0 θ0 的参数更新表达式:
θ 0 : = θ 0 − η ∑ i = 1 n ( f θ ( x ( i ) ) − y ( i ) ) \theta_0 := \theta_0 - \eta\sum_{i=1}^{n}( f_\theta(x^{(i)}) - y^{(i)}) θ0:=θ0−ηi=1∑n(fθ(x(i))−y(i))
同理, θ 1 \theta_1 θ1 的参数更新表达式:
θ 1 : = θ 1 − η ∑ i = 1 n ( f θ ( x ( i ) ) − y ( i ) ) x ( i ) \theta_1 := \theta_1 - \eta\sum_{i=1}^{n}( f_\theta(x^{(i)}) - y^{(i)})x^{(i)} θ1:=θ1−ηi=1∑n(fθ(x(i))−y(i))x(i)
使用矩阵表示
预测函数:
f θ ( x ) = θ 0 + θ 1 x f_\theta(x)= \theta_0 + \theta_1x fθ(x)=θ0+θ1x
使用向量表示:
θ ⃗ = [ θ 0 θ 1 ] x ( i ) ⃗ = [ 1 x ( i ) ] \vec{\theta} = \begin{bmatrix} \theta_0 \\ \theta_1\end{bmatrix} \qquad \vec{x^{(i)}} = \begin{bmatrix} 1 \\ x^{(i)} \end{bmatrix} θ=[θ0θ1]x(i)=[1x(i)]
优化算法
- 最速梯度下降法的缺点
- 计算量大
- 容易陷入局部最优解
- 随机梯度下降
- 随机选择一个训练数据来更新参数
- 最速下降法更新一次,随机梯度下降法可以更新 n 次
- 小批量梯度下降法
- 随机选择 m 个训练数据来更新参数
问题
为什么要使用梯度下降法,直接求导不行吗?
- 确定不了导数为 0 的时候,是最大值还是最小值
- 计算机更擅长循环迭代的方式求解
- 多元表达式无法直接求解
为什么使用标准化?
- 提升模型精度
- 提升收敛速度
- 不改变原始数据的分布
为什么是用 python 作为 AI 的主流语言?
- 广泛的库和框架选择
- 平台独立性
学习率如何决定?
目前只能通过反复尝试来找到合适的值
扩展
- 多重回归
- 对参数进行标准化,校验时需要使用相同的平均数和标准差
- 多项式回归
分类
感知机
- 只能处理线性可分的情况
- 可以处理三维以上的数据
步骤
- 训练数据,画图
- 矩形为横向还是纵向
- 预测函数和目标函数
- x ⃗ \vec{x} x 和 w ⃗ \vec{w} w为向量
- 内积正负说明相似程度
- 无目标函数
- 参数更新表达式
- 寻找使权重向量成为法线向量的直线
- 通过向量的相加实现权重的更新
- 演示程序
- 指定训练次数
公式
预测函数(判别函数):
f w ( x ) = { 1 ( w ⋅ x ≥ 0 ) − 1 ( w ⋅ x < 0 ) f_\bold{w}(\bold{x}) = \begin{cases} 1 & (\bold{w \cdot x} \geq 0) \\ -1 & (\bold{w \cdot x} < 0) \\ \end{cases} fw(x)={1−1(w⋅x≥0)(w⋅x<0)
参数更新表达式:
w : = { w + y ( i ) x ( f w ( x ( i ) ) ≠ y ( i ) ) w \bold{w} := \begin{cases} \bold{w} + y^{(i)}\bold{x} & (f_\bold{w}(\bold{x}^{(i)}) \neq y^{(i)}) \\ \bold{w} \\ \end{cases} w:={w+y(i)xw(fw(x(i))=y(i))
逻辑回归
- y 值使用 0 和 1 处理更加方便
- 训练数据
- 线性可分
- 同感知机
- 预测函数
- θ T x = 0 \bold{\theta}^T\bold{x} = 0 θTx=0 时,值为 0.5
- 函数值在(0,1)范围内
- θ T x = 0 \bold{\theta}^T\bold{x} = 0 θTx=0 时的直线称为决策边界
- 目标函数
- 似然函数,Likelihood
- 派
- 求使目标函数最大化的参数 θ \bold{\theta} θ
- 参数更新表达式
- l o g ( 1 − v ) log(1-v) log(1−v) 同样使用复合函数求导公式进行微分
- 指定训练次数
公式
sigmoid函数:
σ ( x ) = 1 1 + e − x \sigma(x) = \frac{1}{1+e^{-x}} σ(x)=1+e−x1
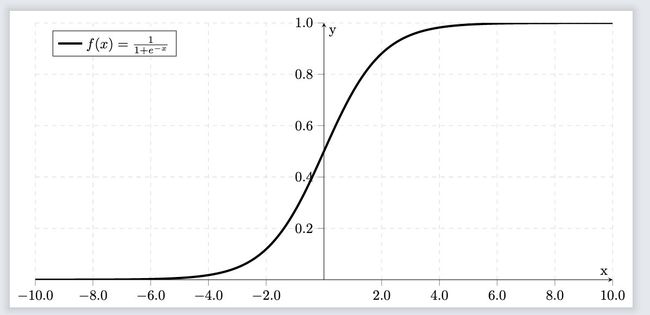
常用导数:
( e x ) ′ = e x ( e − x ) ′ = − e − x (e^x)' = e^x \\ (e^{-x})' = -e^{-x} (ex)′=ex(e−x)′=−e−x
sigmoid函数微分:
σ ′ ( x ) = − ( 1 + e − x ) ′ ( 1 + e − x ) 2 = e − x ( 1 + e − x ) 2 = 1 1 + e − x − 1 ( 1 + e − x ) 2 = σ ( x ) ( 1 − σ ( x ) ) \sigma'(x) = -\frac{(1 + e^{-x})'}{(1+e^{-x})^2} \\ = \frac{e^{-x}}{(1+e^{-x})^2} \\ = \frac{1}{1+e^{-x}} - \frac{1}{(1+e^{-x})^2} \\ = \sigma(x)(1 - \sigma(x)) σ′(x)=−(1+e−x)2(1+e−x)′=(1+e−x)2e−x=1+e−x1−(1+e−x)21=σ(x)(1−σ(x))
预测函数:
f θ ( x ) = 1 1 + exp ( − θ T x ) θ T x = ( θ 0 x 0 + θ 1 x 1 + … + θ n x n ) f_\bold{\theta}(\bold{x}) = \frac{1}{1+\exp(-\bold{\theta}^T\bold{x})}\\ \bold{\theta}^T\bold{x} = (\theta_0x_0 + \theta_1x_1 + \ldots + \theta_nx_n) fθ(x)=1+exp(−θTx)1θTx=(θ0x0+θ1x1+…+θnxn)
阈值函数:
y = { 1 ( θ T x ≥ 0 ) 0 ( θ T x < 0 ) y = \begin{cases} 1 & (\bold{\theta}^T\bold{x} \geq 0) \\ 0 & (\bold{\theta}^T\bold{x} < 0)\\ \end{cases} y={10(θTx≥0)(θTx<0)
未知数据 x \bold{x} x是横向图像的概率:
P ( y = 1 ∣ x ) = f θ ( x ) P(y=1|\bold{x}) = f_\bold{\theta}(\bold{x}) P(y=1∣x)=fθ(x)
目标函数:
L ( θ ) = ∏ i = 1 n P ( y ( i ) = 1 ∣ x ( i ) ) y ( i ) P ( y ( i ) = 0 ∣ x ( i ) ) 1 − y ( i ) L(\bold{\theta}) = \prod_{i=1}^n P(y^{(i)}=1|\bold{x}^{(i)})^{y^{(i)}}P(y^{(i)}=0|\bold{x}^{(i)})^{1-y^{(i)}} L(θ)=i=1∏nP(y(i)=1∣x(i))y(i)P(y(i)=0∣x(i))1−y(i)
对数似然函数:
log L ( θ ) = log ∏ i = 1 n P ( y ( i ) = 1 ∣ x ( i ) ) y ( i ) P ( y ( i ) = 0 ∣ x ( i ) ) 1 − y ( i ) = ∑ i = 1 n ( log P ( y ( i ) = 1 ∣ x ( i ) ) y ( i ) + log P ( y ( i ) = 0 ∣ x ( i ) ) 1 − y ( i ) ) = ∑ i = 1 n ( y ( i ) log P ( y ( i ) = 1 ∣ x ( i ) ) + ( 1 − y ( i ) ) log P ( y ( i ) = 0 ∣ x ( i ) ) ) = ∑ i = 1 n ( y ( i ) log P ( y ( i ) = 1 ∣ x ( i ) ) + ( 1 − y ( i ) ) log ( 1 − P ( y ( i ) = 1 ∣ x ( i ) ) ) ) = ∑ i = 1 n ( y ( i ) log f θ ( x ( i ) ) + ( 1 − y ( i ) ) log ( 1 − f θ ( x ( i ) ) ) ) \log L(\bold{\theta}) = \log \prod_{i=1}^n P(y^{(i)}=1|\bold{x}^{(i)})^{y^{(i)}}P(y^{(i)}=0|\bold{x}^{(i)})^{1-y^{(i)}} \\ = \sum_{i=1}^n(\log P(y^{(i)}=1|\bold{x}^{(i)})^{y^{(i)}} + \log P(y^{(i)}=0|\bold{x}^{(i)})^{1-y^{(i)}}) \\ = \sum_{i=1}^n(y^{(i)}\log P(y^{(i)}=1|\bold{x}^{(i)}) + (1-y^{(i)})\log P(y^{(i)}=0|\bold{x}^{(i)})) \\ = \sum_{i=1}^n(y^{(i)}\log P(y^{(i)}=1|\bold{x}^{(i)}) + (1-y^{(i)})\log(1-P{(y^{(i)}=1|\bold{x}^{(i)})})) \\ = \sum_{i=1}^n(y^{(i)}\log f_\bold{\theta}(\bold{x}^{(i)}) + (1-y^{(i)})\log(1-{f_\bold{\theta}(\bold{x}^{(i)})})) logL(θ)=logi=1∏nP(y(i)=1∣x(i))y(i)P(y(i)=0∣x(i))1−y(i)=i=1∑n(logP(y(i)=1∣x(i))y(i)+logP(y(i)=0∣x(i))1−y(i))=i=1∑n(y(i)logP(y(i)=1∣x(i))+(1−y(i))logP(y(i)=0∣x(i)))=i=1∑n(y(i)logP(y(i)=1∣x(i))+(1−y(i))log(1−P(y(i)=1∣x(i))))=i=1∑n(y(i)logfθ(x(i))+(1−y(i))log(1−fθ(x(i))))
复合函数:
u = log L ( θ ) v = f θ ( x ) u = \log L(\bold{\theta}) \\ v = f_\bold{\theta}(\bold{x}) u=logL(θ)v=fθ(x)
参数更新表达式:
u u u 对 v v v的微分
∂ u ∂ v = ∂ ∂ v ∑ i = 1 n ( y ( i ) log ( v ) ) + ( 1 − y ( i ) ) log ( 1 − v ) ) = ∑ i = 1 n ( y ( i ) v − 1 − y ( i ) 1 − v ) \frac{\partial u}{\partial v} = \frac{\partial }{\partial v}\sum_{i=1}^n(y^{(i)}\log(v)) + (1-y^{(i)})\log(1-{v})) \\ = \sum_{i=1}^n(\frac{y^{(i)}}{v} - \frac{1-y^{(i)}}{1-v}) \\ ∂v∂u=∂v∂i=1∑n(y(i)log(v))+(1−y(i))log(1−v))=i=1∑n(vy(i)−1−v1−y(i))
v v v 对 θ j \theta_j θj 微分
∂ v ∂ θ j = ∂ ∂ θ j 1 1 + exp ( − θ T x ) = v ( 1 − v ) ⋅ x j \frac{\partial v}{\partial \theta_j} = \frac{\partial }{\partial \theta_j}\frac{1}{1+\exp(-\bold{\theta}^T\bold{x})} \\ = v(1-v)\cdot x_j ∂θj∂v=∂θj∂1+exp(−θTx)1=v(1−v)⋅xj
u u u 对 θ j \theta_j θj 微分
∂ u ∂ θ j = ∂ u ∂ v ⋅ ∂ v ∂ θ j = ∑ i = 1 n ( y ( i ) v − 1 − y ( i ) 1 − v ) ⋅ v ( 1 − v ) ⋅ x j ( i ) = ∑ i = 1 n ( y ( i ) ( 1 − v ) − ( 1 − y ( i ) ) v ) x j ( i ) = ∑ i = 1 n ( y ( i ) − y ( i ) v − v + y ( i ) v ) x j ( i ) = ∑ i = 1 n ( y ( i ) − v ) x j ( i ) = ∑ i = 1 n ( y ( i ) − f θ ( x ) ) x j ( i ) \frac{\partial u}{\partial \theta_j} = \frac{\partial u}{\partial v}\cdot\frac{\partial v}{\partial \theta_j} \\ = \sum_{i=1}^n(\frac{y^{(i)}}{v} - \frac{1-y^{(i)}}{1-v}) \cdot v(1-v)\cdot x_j^{(i)} \\ = \sum_{i=1}^n(y^{(i)}(1-v) - (1-y^{(i)})v)x_j^{(i)} \\ = \sum_{i=1}^n(y^{(i)}-y^{(i)}v-v+y^{(i)}v)x_j^{(i)} \\ = \sum_{i=1}^n(y^{(i)}-v)x_j^{(i)} \\ = \sum_{i=1}^n(y^{(i)}-f_\bold{\theta}(\bold{x}))x_j^{(i)} ∂θj∂u=∂v∂u⋅∂θj∂v=i=1∑n(vy(i)−1−v1−y(i))⋅v(1−v)⋅xj(i)=i=1∑n(y(i)(1−v)−(1−y(i))v)xj(i)=i=1∑n(y(i)−y(i)v−v+y(i)v)xj(i)=i=1∑n(y(i)−v)xj(i)=i=1∑n(y(i)−fθ(x))xj(i)
θ j \theta_j θj 的参数更新表达式:
θ j = θ j + η ∑ i = 1 n ( y ( i ) − f θ ( x ) ) x j ( i ) \theta_j = \theta_j + \eta\sum_{i=1}^n(y^{(i)} - f_\bold{\theta}(\bold{x}))x_j^{(i)} θj=θj+ηi=1∑n(y(i)−fθ(x))xj(i)
θ j \theta_j θj 的参数更新表达式(和回归时保持一致):
θ j = θ j − η ∑ i = 1 n ( f θ ( x ) − y ( i ) ) x j ( i ) \theta_j = \theta_j - \eta\sum_{i=1}^n(f_\bold{\theta}(\bold{x}) - y^{(i)})x_j^{(i)} θj=θj−ηi=1∑n(fθ(x)−y(i))xj(i)
决策边界:
θ T x = θ 0 + θ 1 x 1 + θ 2 x 2 x 2 = − θ 0 + θ 1 x 1 θ 2 \bold{\theta}^T\bold{x} = \theta_0 + \theta_1x_1 + \theta_2x_2 \\ x_2 = - \frac{\theta_0 + \theta_1x_1}{\theta_2} θTx=θ0+θ1x1+θ2x2x2=−θ2θ0+θ1x1
线性不可分
- 多项式函数
- 决策边界为曲线
决策边界:
θ T x = θ 0 + θ 1 x 1 + θ 2 x 2 + θ 3 x 1 2 x 2 = − θ 0 + θ 1 x 1 + θ 3 x 1 2 θ 2 \bold{\theta}^T\bold{x} = \theta_0 + \theta_1x_1 + \theta_2x_2 + \theta_3x_1^2 \\ x_2 = - \frac{\theta_0 + \theta_1x_1 + \theta_3x_1^2}{\theta_2} θTx=θ0+θ1x1+θ2x2+θ3x12x2=−θ2θ0+θ1x1+θ3x12
扩展
- SVM 分类算法
- 其他分类算法
正则化
- 确定正则化项
- λ \lambda λ 表示正则化项影响程度
- 重定义目标函数
- 重定义参数更新表达式
公式
L2正则化项:
R ( θ ) = λ 2 ∑ j = 1 m θ j 2 R(\theta) = \frac{\lambda}{2}\sum_{j=1}^{m}\theta_j^2 R(θ)=2λj=1∑mθj2
目标函数:
E ( θ ) = 1 2 ∑ i = 1 n ( y ( i ) − f θ ( x ( i ) ) ) 2 + λ 2 ∑ j = 1 m θ j 2 E(\theta) = \frac{1}{2}\sum_{i=1}^{n}(y^{(i)} - f_\theta(\bold{x}^{(i)}))^2 + \frac{\lambda}{2}\sum_{j=1}^{m}\theta_j^2 E(θ)=21i=1∑n(y(i)−fθ(x(i)))2+2λj=1∑mθj2
参数更新表达式:
θ 0 : = θ 0 − η ( ∑ i = 1 n ( f θ ( x ( i ) ) − y ( i ) ) x j ( i ) ) θ j : = θ j − η ( ∑ i = 1 n ( f θ ( x ( i ) ) − y ( i ) ) x j ( i ) + λ θ j ) ) ( j > 0 ) \theta_0 := \theta_0 - \eta(\sum_{i=1}^{n}( f_\theta(\bold{x}^{(i)}) - y^{(i)})x_j^{(i)}) \\ \theta_j := \theta_j - \eta(\sum_{i=1}^{n}( f_\theta(\bold{x}^{(i)}) - y^{(i)})x_j^{(i)} + \lambda\theta_j)) \qquad (j>0) θ0:=θ0−η(i=1∑n(fθ(x(i))−y(i))xj(i))θj:=θj−η(i=1∑n(fθ(x(i))−y(i))xj(i)+λθj))(j>0)
基础
-
误差函数
- MSE(Mean Square Error, 均方误差), 1 n ∑ i = 1 n ( y ( i ) − f θ ( x ( i ) ) ) 2 \frac{1}{n}\sum_{i=1}^n(y^{(i)} - f_\bold{\theta}(\bold{x}^{(i)}))^2 n1∑i=1n(y(i)−fθ(x(i)))2
- SSE(The Sum Of Squares Due To Error, 和方差)
- RMSE(Root Mean Squared Error, 均方根误差)
-
容量
- batchsize:批大小
- iteration:1 个iteration 等于使用 batchsize 个样本训练一次
- epoch:1个epoch等于使用训练集中的全部样本训练一次
-
随机梯度下降法(Stochastic Gradient Descent,SGD)
模型评估
- 交叉验证:将数据按一定比例分为测试数据和训练数据,一般为 3:7 或者 2:8
- 数据的分配方法不能太极端
- 回归问题:均方误差
- 计算精确率和召回率时使用数据少的类别
- K 折交叉验证:需要确定一个合适的 K 值
- 学习曲线:通过学习曲线判断模型是过拟合还是欠拟合
- 高偏差(欠拟合):随着数据数量的增加,使用训练数据时的精度不断下降,使用测试数据时的精度不断上升
- 高方差(过拟合):随着数据数量的增加,使用训练数据时的精度缓慢,使用测试数据时的精度不断上升,但是达不到训练数据精度
分类问题
- 精度
A c c u r a c y = T P + T N T P + F P + F N + T N Accuracy = \frac{TP + TN}{TP + FP + FN + TN} Accuracy=TP+FP+FN+TNTP+TN
- 精确率:当训练数据极不平衡时,在分类为 Positive 的数据中,分类正确的比例
P r e c i s i o n = T P T P + F P Precision = \frac{TP}{TP + FP} Precision=TP+FPTP
-
召回率:在 Positive 数据中,分类正确的比例
R e c a l l = T P T P + F N Recall = \frac{TP}{TP + FN} Recall=TP+FNTP -
一般来说,精确率和召回率会一个高一个低,不能取平均值
-
调和平均值F1值:
F m e a s u r e = 2 1 P r e c i s i o n + 1 R e c a l l F m e a s u r e = 2 ⋅ P r e c i s i o n ⋅ R e c a l l P r e c i s i o n + R e c a l l Fmeasure = \frac{2}{\frac{1}{Precision} + \frac{1}{Recall}} \\ \\ Fmeasure = \frac{2 \cdot Precision \cdot Recall}{Precision + Recall} Fmeasure=Precision1+Recall12Fmeasure=Precision+Recall2⋅Precision⋅Recall -
权重调和平均值F值:
F m e a s u r e = ( 1 + β 2 ) ⋅ P r e c i s i o n ⋅ R e c a l l β 2 ⋅ P r e c i s i o n + R e c a l l Fmeasure = \frac{(1 + \beta^2) \cdot Precision \cdot Recall}{\beta^2 \cdot Precision + Recall} Fmeasure=β2⋅Precision+Recall(1+β2)⋅Precision⋅Recall
正则化
过拟合
- 过拟合:只能拟合训练数据
- 避免过拟合
- 增加全部训练数据的数量(重要)
- 使用简单的模型,例:将预测函数从曲线变成直线
- 正则化
- 欠拟合:一般模型过于简单
正则化
- 防止参数变得过大,减少参数的影响,对参数进行惩罚
- 不对偏置项进行正则化
- λ \lambda λ 为正则化项影响程度
- 线性回归的正则化
E ( θ ) = 1 2 ∑ i = 1 n ( y ( i ) − f θ ( x ( i ) ) ) 2 R ( θ ) = λ 2 ∑ j = 1 m θ j 2 E(\theta) = \frac{1}{2}\sum_{i=1}^{n}(y^{(i)} - f_\theta(x^{(i)}))^2 \\ R(\theta) = \frac{\lambda}{2}\sum_{j=1}^{m}\theta_j^2 E(θ)=21i=1∑n(y(i)−fθ(x(i)))2R(θ)=2λj=1∑mθj2 - 分类函数的正则化,改变目标函数的符号将最大化问题转换为最小化问题
log L ( θ ) = − ∑ i = 1 n ( y ( i ) log f θ ( x ( i ) ) + ( 1 − y ( i ) ) log ( 1 − f θ ( x ( i ) ) ) ) + λ 2 ∑ j = 1 m θ j 2 \log L(\bold{\theta}) = -\sum_{i=1}^n(y^{(i)}\log f_\bold{\theta}(\bold{x}^{(i)}) + (1-y^{(i)})\log(1-{f_\bold{\theta}(\bold{x}^{(i)})})) + \frac{\lambda}{2}\sum_{j=1}^{m}\theta_j^2 logL(θ)=−i=1∑n(y(i)logfθ(x(i))+(1−y(i))log(1−fθ(x(i))))+2λj=1∑mθj2 - L1 正则化:被判定为不需要的参数为变为 0
R ( θ ) = λ ∑ j = 1 m ∣ θ j ∣ R(\theta) = \lambda\sum_{j=1}^{m}|\theta_j| R(θ)=λj=1∑m∣θj∣ - L2 正则化:抑制参数
R ( θ ) = λ 2 ∑ j = 1 m θ j 2 R(\theta) = \frac{\lambda}{2}\sum_{j=1}^{m}\theta_j^2 R(θ)=2λj=1∑mθj2
参考
- 数据集 Iris
待学习
- numpy
- Matplotlib Pyplot