手撕代码insightFace中的arcface_torch
背景介绍
搞人脸识别的同学基本都听过insightFace 的大名,在开源工程里面可以帮助大伙快速的建立自己的baseline , 代码玩儿的溜的同学说不一定一两天就玩儿通了.原始的insightface是mxnet实现的,但是现在工业界和学术的有非常多的人使用pytorch作为自己的开发平台,这就带来了一定的局部不适.终于最近insightFace基于pytorch实现了相关的算法,并公布了性能还不错的开源预训练模型,pytorch建议到1.6.0版本以上.感谢相关的开源作者做出的贡献.
那么这个工程能给你带来什么呢?
1.可以迅速建立一个baseline.如果是小公司没有人力去研究新的算法,设计新的loss,或者模型,根据吴恩达大神的80%数据20%算法原则,就无脑持续收集数据,不断训练模型就可以了.简单吧,愉快吧.
2.优秀的代码风格,还有简洁的算法实现,如果要拿他作为一个基准然后持续的研究新想法,新loss设计,新模型修改,都是一个不错的验证平台,各种对标的验证集,训练集,应有尽有,开箱即用,方便!
整体介绍:
说了这么多,废话就没了,来介绍一下整体工程,介于本篇文章着眼点在于代码分析,理论部分就尽量少一些,而且网上讲理论的文章太多了,同学你就自行度娘吧.工程主体结构如下:
.
├── README.md
├── backbones
│ ├── __init__.py
│ └── iresnet.py # backbone定义
├── config.py # 配置文件,使用什么数据集训练,验证,batchsize,学习率等
├── dataset.py # dataloader 的实现,并行加速异步缓存,
├── docs
│ ├── eval.md #
│ ├── install.md #
│ └── modelzoo.md #
├── eval
│ ├── __init__.py
│ └── verification.py
├── eval_ijbc.py
├── kill_all_distributed_python.sh
├── losses.py
├── partial_fc.py
├── requirement.txt
├── run.sh
├── train.py
├── trainNode0.sh
├── trainNode1.sh
├── trainNode2.sh
├── trainSingleNode.sh
└── utils
├── __init__.py
├── plot.py
├── utils_amp.py # 混合精度
├── utils_callbacks.py
├── utils_logging.py
└── utils_os.py我加了一些中文注解,方便童鞋门的理解,并快速开始玩儿自己的项目传送门如下:
https://github.com/leoluopy/pytorch_arcface_cosface_partialFC
有相关问题搜索知识星球号:1453755 【CV老司机】加入星球提问。扫码也可加入:

也可以搜索关注微信公众号: CV老司机

相关代码和详细资源或者相关问题,可联系牛先生小猪wx号: jishudashou
后面是一些详细的讲解.
数据加载dataloader:
dataloader其实是一个非常基础的训练组件,在数据量少的时候,怎么写都可以,也没啥区别。不过一旦数据量大了之后,比如达到千万级别后,硬盘IO的读写效率,数据预处理并行度都成为性能瓶颈。
下面的代码即是为了解决上面的问题,一种异步加载,个人认为是比较漂亮的写法。同时,这样封装后,dataloader的遍历方式并没有发生改变,这是十分可贵的一点。
主要的思路是: 1. Thread 内部自动加载数据至queue 2. 重载了 _iter 和 next_ 使得上层的接口保持不变。
主流程和关键点还有一个数据集的加速,平时我们的数据也就几万,多的时候几十万,或者几百万,人脸数据集目前最好的都达到千万级别如glint360k,就有36W的ID 和 1600W样子的图片,这么多的数据,对于磁盘访问,CPU和GPU的均衡是一个考验。同时为了做到pytorch上层接口的保持不变,insight face 做了一个挺漂亮的封装,重载了 _iter, _next_ , 并在dataloader的内部开起新线程异步不断加载数据到Queue , 外部使用相同接口迭代数据时,就直接从Queue中取,而不需要取得时候才着手数据前处理。迭代完成后,数据触发一个 StopIteration的信号结束迭代。
其他地方还有什么疑问,或者有什么探讨的地方,进知识星球提问吧。
class BackgroundGenerator(threading.Thread):
def __init__(self, generator, local_rank, max_prefetch=6):
super(BackgroundGenerator, self).__init__()
self.queue = Queue.Queue(max_prefetch)
self.generator = generator
self.local_rank = local_rank
self.daemon = True
self.start()
def run(self):
torch.cuda.set_device(self.local_rank)
for item in self.generator:
self.queue.put(item)
self.queue.put(None)
def next(self):
next_item = self.queue.get()
if next_item is None:
raise StopIteration
return next_item
def __next__(self):
return self.next()
def __iter__(self):
return self
class DataLoaderX(DataLoader):
def __init__(self, local_rank, **kwargs):
super(DataLoaderX, self).__init__(**kwargs)
self.stream = torch.cuda.Stream(local_rank)
self.local_rank = local_rank
def __iter__(self):
self.iter = super(DataLoaderX, self).__iter__()
self.iter = BackgroundGenerator(self.iter, self.local_rank)
self.preload()
return self
def preload(self):
self.batch = next(self.iter, None)
if self.batch is None:
return None
with torch.cuda.stream(self.stream):
for k in range(len(self.batch)):
self.batch[k] = self.batch[k].to(device=self.local_rank,
non_blocking=True)
def __next__(self):
torch.cuda.current_stream().wait_stream(self.stream)
batch = self.batch
if batch is None:
raise StopIteration
self.preload()
return batch
class MXFaceDataset(Dataset):
def __init__(self, root_dir, local_rank):
super(MXFaceDataset, self).__init__()
self.transform = transforms.Compose(
[transforms.ToPILImage(),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5]),
])
self.root_dir = root_dir
self.local_rank = local_rank
path_imgrec = os.path.join(root_dir, 'train.rec')
path_imgidx = os.path.join(root_dir, 'train.idx')
self.imgrec = mx.recordio.MXIndexedRecordIO(path_imgidx, path_imgrec, 'r')
s = self.imgrec.read_idx(0)
header, _ = mx.recordio.unpack(s)
if header.flag > 0:
self.header0 = (int(header.label[0]), int(header.label[1]))
self.imgidx = np.array(range(1, int(header.label[0])))
else:
self.imgidx = np.array(list(self.imgrec.keys))
def __getitem__(self, index):
idx = self.imgidx[index]
s = self.imgrec.read_idx(idx)
header, img = mx.recordio.unpack(s)
label = header.label
if not isinstance(label, numbers.Number):
label = label[0]
label = torch.tensor(label, dtype=torch.long)
sample = mx.image.imdecode(img).asnumpy()
if self.transform is not None:
sample = self.transform(sample)
return sample, label
def __len__(self):
return len(self.imgidx)下面是实际调用的时候,初始化方式,良好的封装后,接口保持一致。挺美 S .
trainset = MXFaceDataset(root_dir=cfg.rec, local_rank=local_rank)
train_sampler = torch.utils.data.distributed.DistributedSampler(
trainset, shuffle=True)
train_loader = DataLoaderX(
local_rank=local_rank, dataset=trainset, batch_size=cfg.batch_size,
sampler=train_sampler, num_workers=0, pin_memory=True, drop_last=True)训练验证可选的各种数据集和配置:
agedb_30.bin calfw.bin cfp_ff.bin cfp_fp.bin cplfw.bin lfw.bin vgg2_fp.bininsightface 对于验证还是挺友好的,上面的数据集都可以来验证,常见的 lfw , agedb, cplfw , cpfp_fp 都在里面。不用自己挨个去下载,并写评估代码,舒服!
train.idx train.rec 训练集的 glint 1600W , ms1m 这些数据集都在,也很方便!
主干模型:
实现的主干模型,其中效果最好的还是iresnet,那我们来唠唠这个模型是啥样。
参考实现主干模型仓库:https://github.com/iduta/iresnet/tree/master/models
论文: https://arxiv.org/abs/2004.04989

首先这个模型改进了模型的信息流。上图左边是原始的resnet模型,每一个block在信息轮流经过都有relu激活,以resnet50为例,卷积组是[3,4,6,3],那么由resblock带来的激活次数就是 16次。主信息路径被抑制的信号就太多了。为了探索这方面是否有相应的提高,iresnet在主干路径上只提供了四次的激活次数[多少组卷积组,就激活多少次,信号住路径激活],不再每个resblock都做相应的激活。
另外模型分析了,主干路劲信号,没有做零中心化,这样数据的学习效率以及最后能达到的最优效果或许会收到一定的影响。因此每组卷积组主干路径都加入了数据零中心化处理,每个resblock输入也额外做数据零中心化处理。
再有一点主信号流加入bn,我们从bn的公式也可以看出,这样模型就增强了通道之间权重重要性的学习能力。[ BN 公式减均值,除方差,乘以scale,加bias]为什么可以增强通道之间权重的重要性学习能力 , 搜索知识星球:牛小圈 提问进一步讨论。
原始ResNet:
class Bottleneck(nn.Module):
expansion = 4
def __init__(self, inplanes, planes, stride=1, downsample=None, norm_layer=None):
super(Bottleneck, self).__init__()
if norm_layer is None:
norm_layer = nn.BatchNorm2d
# Both self.conv2 and self.downsample layers downsample the input when stride != 1
self.conv1 = conv1x1(inplanes, planes)
self.bn1 = norm_layer(planes)
self.conv2 = conv3x3(planes, planes, stride)
self.bn2 = norm_layer(planes)
self.conv3 = conv1x1(planes, planes * self.expansion)
self.bn3 = norm_layer(planes * self.expansion)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stride = stride
def forward(self, x):
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
identity = self.downsample(x)
out += identity
out = self.relu(out)
return out对比一下上下resnet和 iresnet的实现区别,我们就可以看到,iresnet加入了一些条件控制流,控制bn和relu位置。so easy 是吧!
iresnet改进后:
class Bottleneck(nn.Module):
expansion = 4
def __init__(self, inplanes, planes, stride=1, downsample=None, norm_layer=None,
start_block=False, end_block=False, exclude_bn0=False):
super(Bottleneck, self).__init__()
if norm_layer is None:
norm_layer = nn.BatchNorm2d
# Both self.conv2 and self.downsample layers downsample the input when stride != 1
if not start_block and not exclude_bn0:
self.bn0 = norm_layer(inplanes)
self.conv1 = conv1x1(inplanes, planes)
self.bn1 = norm_layer(planes)
self.conv2 = conv3x3(planes, planes, stride)
self.bn2 = norm_layer(planes)
self.conv3 = conv1x1(planes, planes * self.expansion)
if start_block:
self.bn3 = norm_layer(planes * self.expansion)
if end_block:
self.bn3 = norm_layer(planes * self.expansion)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stride = stride
self.start_block = start_block
self.end_block = end_block
self.exclude_bn0 = exclude_bn0
def forward(self, x):
identity = x
if self.start_block:
out = self.conv1(x)
elif self.exclude_bn0:
out = self.relu(x)
out = self.conv1(out)
else:
out = self.bn0(x)
out = self.relu(out)
out = self.conv1(out)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
if self.start_block:
out = self.bn3(out)
if self.downsample is not None:
identity = self.downsample(x)
out += identity
if self.end_block:
out = self.bn3(out)
out = self.relu(out)
return out来盗一张图,下图以iresnet50为例子,解释了,iresnet重新组织的卷积组各个block的分布情况。从宏观上就比较清晰的了解了。大致就是这个套路 start block 中间夹 middle block ,尾巴跟一个 end block.

iresnet另外一个贡献点是,修改了resnet中downsample的方式,大伙都知道随着卷积的深度加深,网络的特征图长宽会变小,特征图的通道会变多。在残差的跳层的过程中,有的resblock需要对主路径信号进行降采样,resnet原始的方法使用的是1x1的卷积stride 为2 , 这里实际就直接抛弃掉了一半的信息量。iresnet,发现这一情况后,将1x1卷积改为maxpooling ,这一改进提升了信息的利用率。下面是这一流程的方法配图:

downsample = nn.Sequential(
conv1x1(self.inplanes, planes * block.expansion, stride),
norm_layer(planes * block.expansion),
)
downsample = nn.Sequential(
nn.MaxPool2d(kernel_size=3, stride=stride, padding=1),
conv1x1(self.inplanes, planes * block.expansion),
norm_layer(planes * block.expansion),
)上面的pytorch的参考实现,在iresnet的官方实现有现成代码。
除了上述的改进,iresnet 还有另外的一点尝试,在有的数据集合上也能取得不错的效果,实际情况下,可以作为训练的一个备选方案。看下图,原始的resnet,特征图通道变化过程是,先压缩后扩张,因为数据太多了,如果不压缩显然计算量是不可接受的。iresnet的作者参考了mobilenet的思想把分组加入到了resblock的改进中,改变后的iresnet block先膨胀后压缩,膨胀时的卷积采样分组设计,也就是我们常说的depth wise 和 point wise .
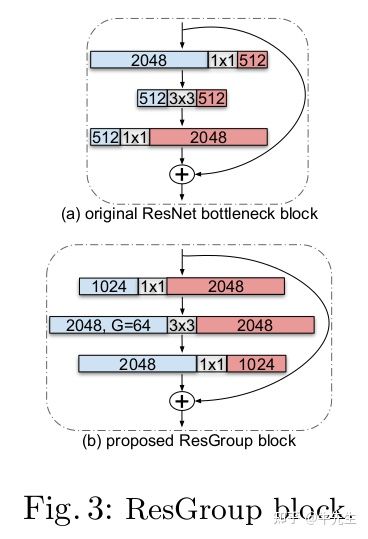

到了这里,上图做了参数和运算效率的对比,通过卷积分组的设计,作者得出的结论是,性能有相应的提升,但是参数量和计算速率没有明显的变化,参考上图的params以及FLOPS .
代码变动:
self.conv2 = conv3x3(planes, planes, groups=groups, stride=stride)Loss:
模型讲完了,我们开始介绍insight face 人脸识别的 loss 设计吧:
人脸识别的loss设计经过了若干年的发展,从最开始的softmax loss, 到centerloss ,到 triplet loss 再到现在的 arcface loss 和 circle , 类内距离和类间距离的训练都得到不小的优化。
总得来说arcface的优化核心思路是:通过对特征的二范数归一化,把特征都表示在一个超球面上,同时通过引入类与类之间的夹角margin,这样做的目的是:使得原本更加模糊的收敛区域变得更加明确:类内紧凑,类间远离。
class ArcFace(nn.Module):
def __init__(self, s=64.0, m=0.5):
super(ArcFace, self).__init__()
self.s = s
self.m = m
def forward(self, cosine: torch.Tensor, label):
index = torch.where(label != -1)[0]
m_hot = torch.zeros(index.size()[0], cosine.size()[1], device=cosine.device)
m_hot.scatter_(1, label[index, None], self.m)
cosine.acos_()
cosine[index] += m_hot
cosine.cos_().mul_(self.s)
return cosine上面是一个arcface的实现,非常简单。输入数据有 label 和cosine。 label是数据的真实标签:表示这个人的id是谁。 Cosine表示与各个ID人类中心的余弦相似度。他的流程是:
- 通过 label 得到 one-hot 标签。
- one-hot 标签转换为 margin大小
- cosine由数值表示转化为角度表示
- 角度表示加上margin大小
- 加了margin之后的cosine转换回数值表示
- 最后的数值再乘以scale. 乘以scale 的作用是方便后面求导得到更大的梯度,加快模型的收敛。
训练主流程:
接下来我们来讲讲训练的主流程是什么样的。看似复杂,其实也就那么几大块。下面的代码是主流程抠出来核心部分,来看看主流程:
- 初始化 gradScaler
- 混合精度训练的初始化,下一章详细聊聊
- 设置epoch , 作用采样规则
- insight face 使用Distributed Sampler,每个显卡各自单独采样,不同epoch 采样规则会更新
- 遍历数据集
- 模型推理,计算loss和 logits层梯度
- 梯度截断
- 做的事情就是把算出来的梯度除以,所以参数梯度的二范数。并设置最大梯度,防止训挂咯,还有加快训练收敛。
- 模型反向求导
- 这里求导是对logits求导,不像我们平时见到的loss.backward .属于分段式写法,为啥用这种写法呢? 因为partial fc将类中心存在不同的显卡,有卡与卡之间的同步过程计算图就被打断了,所以需要手工求导,分段编写这个流程
- 参数更新
- 超参更新,模型及日志callback
grad_scaler = MaxClipGradScaler(cfg.batch_size, 128 * cfg.batch_size, growth_interval=100) if cfg.fp16 else None
for epoch in range(start_epoch, cfg.num_epoch):
train_sampler.set_epoch(epoch)
for step, (img, label) in enumerate(train_loader):
global_step += 1
features = F.normalize(backbone(img))
x_grad, loss_v = module_partial_fc.forward_backward(label, features, opt_pfc, backbone)
if cfg.fp16:
features.backward(grad_scaler.scale(x_grad))
grad_scaler.unscale_(opt_backbone)
clip_grad_norm_(backbone.parameters(), max_norm=5, norm_type=2)
grad_scaler.step(opt_backbone)
grad_scaler.update()
else:
features.backward(x_grad)
# 梯度裁剪 , 求所有参数的二范数,如果大于max_norm ,都乘以 max_norm/所有参数的二范数
clip_grad_norm_(backbone.parameters(), max_norm=5, norm_type=2)
opt_backbone.step()
opt_pfc.step()
module_partial_fc.update()
opt_backbone.zero_grad()
opt_pfc.zero_grad()
loss.update(loss_v, 1)
callback_logging(global_step, loss, epoch, cfg.fp16, grad_scaler)
callback_verification(global_step, backbone)
callback_checkpoint(global_step, backbone, module_partial_fc)
scheduler_backbone.step()
scheduler_pfc.step()
dist.destroy_process_group()混合精度训练:

上文说到的混合精度训练,我们这里详细聊一聊他的运行流程原理是什么样子的。pytorch的原文介绍如上图所示,我们使用的pytorch的混合精度实现,也有nvidia的apex实现,有兴趣的可以瞧瞧,个人觉得pytorch自带这个也用得挺顺手。
混合精度的原理其实很简单,通过上面的官方文档阅读可以看到大致的流程和原理:
- 初始化scaler
- 通过平时大家的训练情况,可以得知越到训练接近于收敛的时候,模型梯度越小。如果是f16,因为表达能力有限,就容易出现下溢出。
- 这时候最容易想到最容易实现的方式就是在框架进行求导backward之前,首先将loss 乘以一个scale.这时候再求导backward,就一定程度抑制了下溢出
- 如果scale之后还是下溢出了,这次求导过程忽略,并增大 scale , 由参数 growth_interval 控制,scale在正常的训练过程会逐渐增大 , 因为越训练到后期下溢出可能性更大,越需要更大的scale .
from torch.cuda.amp import autocast as autocast, GradScaler
# 创建model,默认是torch.FloatTensor
model = Net().cuda()
optimizer = optim.SGD(model.parameters(), ...)
# 在训练最开始之前实例化一个GradScaler对象
scaler = GradScaler()
for epoch in epochs:
for input, target in data:
optimizer.zero_grad()
# 前向过程(model + loss)开启 autocast
with autocast():
output = model(input)
loss = loss_fn(output, target)
# Scales loss,这是因为半精度的数值范围有限,因此需要用它放大
scaler.scale(loss).backward()
# scaler.step() unscale之前放大后的梯度,但是scale太多可能出现inf或NaN
# 故其会判断是否出现了inf/NaN
# 如果梯度的值不是 infs 或者 NaNs, 那么调用optimizer.step()来更新权重,
# 如果检测到出现了inf或者NaN,就跳过这次梯度更新,同时动态调整scaler的大小
scaler.step(optimizer)
# 查看是否要更新scaler
scaler.update()上面是一个典型的混合精度训练的使用方法,是最基本的使用模式,求得loss, scale loss 然后backward. optimizer的step 操作也用scaler包装起来。
partialFC:
主流程的介绍我们已经看了,总结成一句话就是,分步求得loss到logits那一层的导数,然后对logits求导,随后截断梯度,随后更新模型。其中logits求导部分可以使用混合精度方式。
下面就着重介绍partial_FC的分段求得到logits那一层导数的流程如下【代码也放在下面】:
- 负样本中心采样 0.1 * 36W
- 显卡收集权重 【因为insightface各个人脸类中心放在各个不同的卡上,需要同步,上面一步的采样,也有同步过程】
- 推理计算logits 【这一步才用了 exp 归一化的写法,防止exp数据溢出】
- 计算arcfaceLoss 【对原始logits加工,本质上就是在求得的对于每个类中心相似度,首先转换为弧度表示,加上margin,加大训练难度,从而达到加大类间距离,缩小类内距离的目的】
- softmax loss 求loss
- softmax loss 求导 【因为模型的类中心存在不同的卡上,甚至是不同的机器上,因此要做一步单独的求 softmax loss导数,然后传入给logits再自动求导,导数的推导可以参考这里】
- 分段式logits 求导
def forward_backward(self, label, features, optimizer, backbone):
# norm_weight 本张卡的 中心权重, total_label 本个batch中所有数据标签[中心不在本卡的被标记为-1]
total_label, norm_weight = self.prepare(label, optimizer)
total_features = torch.zeros(
size=[self.batch_size * self.world_size, self.embedding_size], device=self.device)
dist.all_gather(list(total_features.chunk(self.world_size, dim=0)), features.data)
total_features.requires_grad = True
# 矩阵相乘得到cosine 相似度,含有负数项[乘-1的原因]
logits = self.forward(total_features, norm_weight)
# 加magin 并乘 scale
logits = self.margin_softmax(logits, total_label)
with torch.no_grad():
# 取响应最大的一个中心的权重 1/C, 最后维度为 B
max_fc = torch.max(logits, dim=1, keepdim=True)[0]
# 取多张卡中响应最大的中心权重 , 非选中样本, 因为乘以-1, 以及中心采用[0,0.0.1]正态分布初始化的原因,能被过滤掉
dist.all_reduce(max_fc, dist.ReduceOp.MAX)
# for numerical stability , this is a exp normalised implementation
logits_exp = torch.exp(logits - max_fc)
logits_sum_exp = logits_exp.sum(dim=1, keepdims=True)
dist.all_reduce(logits_sum_exp, dist.ReduceOp.SUM)
# calculate prob
logits_exp.div_(logits_sum_exp)
# get one-hot
grad = logits_exp
index = torch.where(total_label != -1)[0]
one_hot = torch.zeros(size=[index.size()[0], grad.size()[1]], device=grad.device)
one_hot.scatter_(1, total_label[index, None], 1)
# calculate loss , 公式为: softmax loss = -y * log(softmax(x))
loss = torch.zeros(grad.size()[0], 1, device=grad.device)
# 取标签位置的预计loss项
loss[index] = grad[index].gather(1, total_label[index, None])
# 多卡求和,loss项,合并在一起.
dist.all_reduce(loss, dist.ReduceOp.SUM)
loss_v = loss.clamp_min_(1e-30).log_().mean() * (-1)
# calculate grad
grad[index] -= one_hot
grad.div_(self.batch_size * self.world_size)
# 分段求导的写法,先求softmax 的导数存在grad中,然后传入logits的求导调用 ,
# 断点观察backbone.module.fc.weight.grad和total_features.grad,导数只到total_features.grad ,因为all_gather把计算图打断了,退出函数后,外面再接棒feature.backward()
# NOTE: optimizer.param_groups[0]['params'][0].grad 计算图没受到影响,会计算完毕.
logits.backward(grad)
if total_features.grad is not None:
# toal_feature的梯度已经计算过了,调用detach防止本个batch 中被再次计算.
total_features.grad.detach_()
x_grad: torch.Tensor = torch.zeros_like(features, requires_grad=True)
# feature gradient all-reduce
dist.reduce_scatter(x_grad, list(total_features.grad.chunk(self.world_size, dim=0)))
x_grad = x_grad * self.world_size
# backward backbone
return x_grad, loss_v如果这个项目对你有用,有所启发。