transform.normalize
transform.Normalize()
1.归一化函数
CLASS torchvision.transforms.Normalize(mean, std, inplace=False)
用均值和标准差归一化张量图像。此转换不支持PIL Image。给定n个通道的mean:(mean[1],…,mean[n])和std: (std[1],..,std[n]),这个变换将使输入torch的每个通道归一化。即output[channel] = (input[channel] - mean[channel]) / std[channel]
参数:
mean:(sequence)每个通道的均值序列
std: (sequence)每个通道的标准差序列
inplace:(bool,可选)bool值,使该操作就地执行
返回:
归一化张量图像 (返回类型 type)
作用:
要将图像三个通道的数据 整理到 [-1,1] 之间 ,可以加快模型的收敛
对图像张量的每一个数据进行如下公式操作:output[channel] = (input[channel] - mean[channel]) / std[channel],
实例代码:
# 归一化操作
normalize = transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5]) # 归一化的mean\std需要自己计算再传入
img = Image.open("./data/train/Cat/1.jpg")
# img.show()
img_mat = np.array(img) # 得到图片的像素矩阵
print(img_mat[0][0][0]) # 输出三通道图像的第一个像素值 36
img_transform = transforms.ToTensor()
img_tensor = img_transform(img) # 将图片变成张量
print(img_tensor.shape) # 输出张量的维度 3阶张量 torch.Size([3, 281, 300]) CHW
print(img_tensor[0][0][0]) # 输出三阶张量的第一个元素 tensor(0.1412) 0-1之间
img_tensor_normalize = normalize(img_tensor)
print(img_tensor_normalize[0][0][0]) # 得到归一化之后的三阶张量中的第一个元素 tensor(-0.7176) [-1,1]之间
# 运算公式: output[channel] = (input[channel] - mean[channel]) / std[channel]
# output = (0.1412 - 0.5)/0.5 = -0.71766
运行结果:
36
torch.Size([3, 281, 300])
tensor(0.1412)
tensor(-0.7176)
Normalize 的参数中的0.5 表示把数据标准化到-1 和 1 之间, 一般用在ToTensor()之后,ToTensor可以把图片的数据标准到0到1之间,再通过Normalize (1 -> (1-0.5)/0.5 = 1, (0 -0.5)/0.5 = -1)转换为-1 到 1之间。三通道中Normalize里面一般是Normalize((0.5,0.5,0.5),(0.5,0.5,0.5)),表示将三个通道都标准化,因此标准化一个通道只需要写一个(0.5,)即可
注意:
normalize = transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
在上述的两个参数中的0.5是一种近似,如果要精确就需要进行计算,这里对应的通道分别为 RGB
一个通道中的mean求法:例如有两张图片,求解R通道的mean,
计算过程: 将两张图片中所有像素点R通道的值相加,除以像素点总数
std标准差求解方法:标准差就是开了方的方差
也是3个通道分开算,
比如算R通道的, 这里X就为所有像素点 各自的R值,再减去R均值
然后平方;
然后20000个像素点相加,然后求平均除以20000,
得到R的方差,再开方得标准差。
1.若使用自己创建的数据集最好计算mean std
2.若你用了常见的数据集比如VOC或者COCO之类的,但是用的是自己的网络结构,即pytorch上没有可选的预训练模型那么可以使用 一个pytorch上给的通用的统计值:
mean=[0.485, 0.456, 0.406],std=[0.229, 0.224, 0.225]
数据增强:
数据增强又称为数据增广,数据扩增,它是对训练集进行变换,使训练集更丰富,从而让模型更具泛化能力
2.深度学习时为什么需要对图像进行归一化
特征归一化、标准化是数据预处理的重要技术,有时甚至可以决定算法是否能很好的工作
归一化的必要性:(一些简单的了解,其他需要看论文)
- 特征间的单位(尺度)可能不同,比如身高和体重,比如摄氏度和华氏度,比如房屋面积和房间数,一个特征的变化范围可能是[1000, 10000],另一个特征的变化范围可能是[−0.1,0.2],在进行距离有关的计算时,单位的不同会导致计算结果的不同,尺度大的特征会起决定性作用,而尺度小的特征其作用可能会被忽略,为了消除特征间单位和尺度差异的影响,以对每维特征同等看待,需要对特征进行归一化
- 原始特征下,因尺度差异,其损失函数的等高线图可能是椭圆形,梯度方向垂直于等高线,下降会走
Z字型路线,而不是指向local minimum。通过对特征进行zero-mean and unit-variance变换后,其损失函数的等高线图更接近圆形,梯度下降的方向震荡更小,收敛更快加快模型收敛,如下图所示:
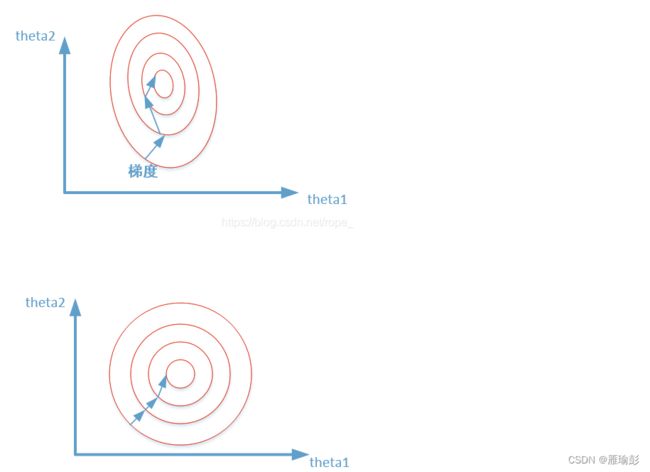
- 图像标准化是将数据通过去均值,实现中心化,根据凸优化理论和数据概率分布的相关知识,数据中心化符合数据分布规律,更容易取得训练之后的泛化效果
3.统计自己数据集的mean和std函数
方法1:
存在一个疑问,我找的数据集中既有单通道的图像也有三通道的图像,那么我如何同时对其进行处理呢?像我下面的程序中(因为单通道的图像少)所以我直接将单通道的图像进行丢弃,只计算三通道图像的mean和std,最后统一丢到ImageFolder或者dataset中进行变换
"""
求图像的mean\std
不太正确的求解方法
"""
import os
from PIL import Image
import numpy as np
import tqdm
def main():
# 数据集通道数
img_channels = 3
# 数据集路径
img_dir = "data/val/Dog"
# 使用assert 判断数据集路径是否存在,若存在程序继续向下执行,若不存在,最抛出异常:“image dir: '{img_dir}' does not exist.”
assert os.path.exists(img_dir), f"image dir: '{img_dir}' does not exist."
# 遍历数据集路径下 以.jpg为后缀的图片
img_name_list = [i for i in os.listdir(img_dir) if i.endswith(".jpg")]
# 累计mean和std,三个通道,这里是RGB,PIL库中的Image.open 默认RGB,cv2.imread是BGR
cumulative_mean = np.zeros(img_channels)
cumulative_std = np.zeros(img_channels)
# 统计数据集长度
print(f"INFO: {len(img_name_list)} imgs in total")
# tadm显示一个进度条 参数total为迭代次数 并且在 img_name_list 中找到图片的名字
for img_name in tqdm.tqdm(img_name_list,total=len(img_name_list)):
img_path = os.path.join(img_dir, img_name)
# 对数据集进行归一化 (对图片的像素矩阵每一个通道的值都除以255)单通道的图像也进行三通道转化
img = np.array(Image.open(img_path).convert("RGB")) / 255.
# 对每个维度进行统计,Image.open打开的是HWC格式,最后一维是通道数
# 注意在此处可能数据集中存在单通道的图像,需要进行判断
# if len(img.shape)==2 : # 处理单通道图像---丢弃(数量少)
# print(img_path)
# if len(img.shape)==3:
for d in range(3):
cumulative_mean[d] += img[:,:,d].mean() # 分别将将所有图片的每一个通道的值求均值再求和
cumulative_std[d] += img[:,:,d].std() # 分别将将所有图片的每一个通道的值求均标准差再求和
mean = cumulative_mean / len(img_name_list)
std = cumulative_std / len(img_name_list)
print(f"mean: {mean}")
print(f"std: {std}")
if __name__ == '__main__':
main()
运行结果:
>>INFO: 2913 imgs in total
100%|██████████| 2913/2913 [00:22<00:00, 129.05it/s]
mean: [0.4568465 0.44091866 0.40470575]
std: [0.236748 0.23291249 0.23822835]
方法2:(更简洁更正确建议使用)
**该程序可以同时对单通道与三通道图像进行求解,因为再使用ImageFolder对图像进行处理的时候,发现ImageFolder继承于DatasetFolder,而DatasetFolder类中的pil_loader()方法对所有图像都进行了转化通过PIL.Image中的convert("RGB")**方法将图像变成了三通道图像(单通道变化为三通道、三通道不变)
"""
求图像的mean、std
正确的求解方法
"""
from torchvision.transforms import ToTensor#用于把图片转化为张量
import numpy as np#用于将张量转化为数组,进行除法
from torchvision.datasets import ImageFolder#用于导入图片数据集
import tqdm
means = [0,0,0]
std = [0,0,0]#初始化均值和方差
transform=ToTensor()#可将图片类型转化为张量,并把0~255的像素值缩小到0~1之间
dataset=ImageFolder("./data/val/",transform=transform)#导入数据集的图片,并且转化为张量
num_imgs=len(dataset)#获取数据集的图片数量
for img,a in tqdm.tqdm(dataset,total=num_imgs,ncols = 100):#遍历数据集的张量和标签
for i in range(3):#遍历图片的RGB三通道
# 计算每一个通道的均值和标准差
means[i] += img[i, :, :].mean()
std[i] += img[i, :, :].std()
mean=np.array(means)/num_imgs
std=np.array(std)/num_imgs#要使数据集归一化,均值和方差需除以总图片数量
print(f"mean: {mean}")#打印出结果
print(f"std: {std}")
运行结果:
100%|██████████████████████████████████████████████████████████| 4881/4881 [00:13<00:00, 357.87it/s]
mean: [0.488723 0.45623815 0.4185311 ]
std: [0.22901899 0.22539699 0.22587197]
Tqdm 是一个快速,可扩展的Python进度条,可以在 Python 长循环中添加一个进度提示信息,用户只需要封装任意的迭代器 tqdm(iterator)
tqdm.tqdm()的参数如下:
iterable=None,
desc=None, 传入str类型,作为进度条标题(类似于说明)
total=None, 预期的迭代次数
leave=True,
file=None,
ncols=None, 可以自定义进度条的总长度
mininterval=0.1, 最小的更新间隔
maxinterval=10.0, 最大更新间隔miniters=None, ascii=None, unit='it',unit_scale=False, dynamic_ncols=False, smoothing=0.3,bar_format=None, initial=0, position=None, postfix 以字典形式传入 详细信息 例如 速度= 10,
实例代码:
dict = {"a":123,"b":456}
for i in tqdm(range(10),total=10,desc = "WSX",ncols = 100,postfix = dict):
time.sleep(0.1)
pass
输出结果:
![]()