xgboost算法_第七章 xgboost算法-深入了解xgboost
3.1 算法原理
对一个机器学习工程师而言,对一个算法知其然可以构建有价值的应用,而知其所以然可以了解模型构建的本质。下面我们来一窥究竟xgboost算法的底层原理,在进一步介绍之前我们有必要对以下几个知识点进行准备,一是cart树,二是导数,三是最优化,看起来好像很枯燥很高深的样子,不要怕,每一部分我们都从简说明。
3.1.1 cart树
有监督学习的数据集一般有属性(x1, x2......xn)和预测目标y组成,这样的数据集是一个二维表,选择一个属性并且按某种标准将其分裂,如此重复下去,直到满足某种条件停下来,这样就生成了一棵树。根据y的类型分为分类树和回归树,根据属性选择和分裂的标准可分为id3, c4.5, cart树,我们只说cart的回归树部分。为了便于说明,我们列出一个小型数据集作参照。

这个简单的数据集是由两个属性age和blood_pressure来识别患心脏病的概率,cart算法的运算过程如下:
1)对属性age而言,将属性值排序,然后对于每个属性值进行试分裂,分裂后的每个子集计算其预测值,预测值被证明等于相应的heart_desease的平均值,比如当分裂点为60时,age>=60部分预测值hear_desease_pre = (0.9 + 0.8 + 0.7) / 3 = 0.8,age<60部分预测值heart_desease_pre = (0.6 + 0.5 + 0.3 + 0.4) / 4 = 0.45。
2)计算age该分裂节点时的样本损失,损失函数为平方差之和,其值为:
为了更清楚的说明这个过程,看下表:
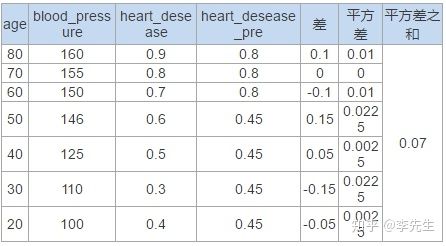
3) 穷举age的每个属性值得到不同的sse。
4) 选取sse最小值对应的分裂点为该属性age的最优分裂点,此时的sse为属性age的最优sse。
5) 针对前四步的方法遍历其它的所有属性得到每个属性的最优分裂点和最优sse。
6) 比较所有属性的最优sse选取最小sse对应的属性作为最优属性进行分裂。
7) 重复前6步的过程直到满足停止条件。停止条件为:树深度、叶节点的样本数量,其中树深度越深则代表学习的规则越细,训练准确率越高,但不是越深越好,过深的树结构会导致过拟和,所以要合理控制树深度。叶节点的样本数量则反应规则的统计性,如果太小则规早不一定有适用性,同样会过拟和,而过大则有可能学习的树太简单,合理控制是最好的决策。
8)前7步可以生长成一棵树,为了将cart算法完整描述,最后一步是需要对树进行剪枝,剪枝同样是为平衡训练精度和过拟和,这里不再详述。
3.1.2 导数
之所以介绍导数是因为它是最优化的基础,在介绍导数之前,让我们先看一看什么是极限,先上一个公式和一个图,当x无限逼近a时,f(x)逼近函数值A。
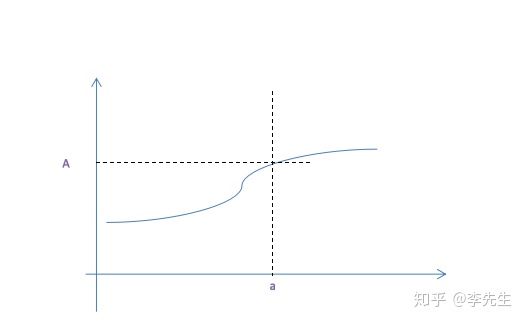
导数就是当自变量x在无限逼近a时,f(x) - f(a) / x - a 的极限,用公式表达如下:
从几何上来理解一维函数相当于函数在点x=a处的斜率,从物理上可以理解为速度等。
3.1.3 最优化
我们所说的最优化是指函数的最优化,即穷取自变量的所有情况时,函数的最大值或最小值,机器学习里一般是对目标函数求最小值。实际运行过程中我们又不可能穷举所有的变量,这对计算机来说也是不可实现的,多亏了数学家总结了一套套的求解办法,下面我们主要介绍一下机器学习中极其常用的一种最优化算法,梯度下降算法。
我们从泰勒公式说起,泰勒公式表达的是函数中某值附近的函数用某值来逼近的事情,具体为:
这个是一阶秦勒展开,其中f1(a)为x=a的一阶导数,R1(x)为前一项(x-a)的高阶无穷小,也意味着可以忽略R1(x)的存在,再看前面两项,第一项f(a)为确定的函数值,第二项为两个向量,其中f1(a)为确定的向量,(x-a)的方向随x而变,(x-a)与f1(a)夹角为0度时,函数值最大,这时f(x)朝着值增大最快的方向前进,(x-1)与f1(a)夹角为180度时,函数值最小,这时f(x)朝着值减小最快的方向前进,至此我们就得出了最流行的一句话,当函数自变量沿着负梯度方向下降时,函数值下降最快,这就是梯度下降法的主要原理,好了,听起来似乎也没有那么难吧?有了这些知识储备我们就可以更深入的去了解xgboost背后的原理。
3.1.4 算法全貌
现在我们终于开始去了解xgboost算法的构建过程,我们遵循机器学习模型的主要架构来说,即分为模型组织方式和模型求解。
1)模型
对于xgboost来说模型组织方式即为多棵树相加,每一棵树都是cart回归树的形式,用代数表示为:

其中m代表总共m棵树,ft(x)代表每一棵树的函数决策,yi帽代表预测值,yi代表实际值,下图更形象地表示这个迭加过程。

其中
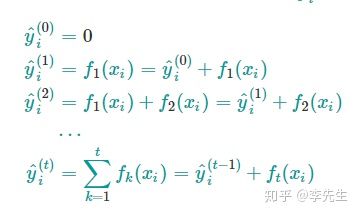
对每一棵树可以用如下代数公式来表示:
其中q(xi)代表树结构,输入xi通过q映射到树的某一个叶节点,假设树的叶节点的个数为T,w代表叶节点的值,也就该树的预测值。其它的符号也说明一下,gi代表某个样本的损失函数在上一棵树的一阶梯度值,hi代表某个样本的损失函数在上一棵树的二阶梯度值。下图可以形象地表示这些描述。

2) 求解
求解的过程在xgboost就是将以上的每一棵树的函数计算出来,具体一点就是将每一棵树的树结构以及相应叶节点的预测值求解出来, 为此我们先构造目标函数,然后最优化目标函数,可以得到每棵树的解,但是同时优化多棵树,难度较大。这时候可以一棵一棵来求解,具体为每求解一棵树后可以将预测值进行累加,这样当前待求解的树之前的树都是常量,只需要把重心放在当前的树求解上即可。具体的步骤如下:
a. 确定目标函数
目标函数由损失函数和正则项组成,损失函数是预测值和实际值的函数,该函数衡量二者的差异,显而易见差异越小,则预测的越精准,其对应的解越合理,以下为目标函数的具体公式:
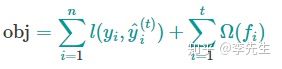
b. 二阶泰勒展开
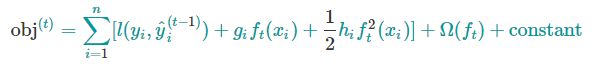
c. 加上正则项并变形
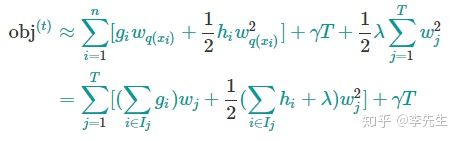
d. 得到
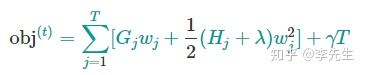
e. 求导得到最优解
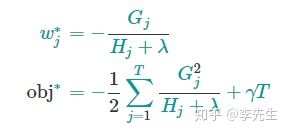
f. 如果二叉树,在分叉前后的损失下降(也可以理解为信息增益)为:
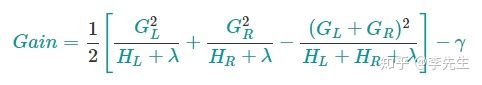
至此我们就得到这棵树的分裂准则和预测值,然后通过决策树的一般方法进行生成树结构和叶节点的值。
3.2 详尽的参数介绍
好了,现在我们对xgboost有了全面深刻的认识,接下来把所有的参数进行详细研究。参数一般分为三种类型,通用参数,迭代器参数,学习任务参数。通用参数适用于任何情况,迭代器参数依每一种迭代器的特点而不同,最常用的是树参数,学习任务参数依学习任务类型不同而不同,学习任务可分为分类和回归任务。
3.2.1 通用参数
- booster[defula=gbtree]
迭代器类型,全集是(gbtree, gblinear, dart), gbtree和dart都属于树类型, gblinear属于线性组合类型
- n_estimators
迭代器个数
- verbosity[default=1]
打印输出的日志级别,全集是(0, 1, 2, 3),分别代表(silent, warning, info, debug),其中silent代表什么也不输出,warning代表会输出警告信息,info代表会打印每一棵树的信息,debug除了每棵树的信息外还有重要步骤的执行时间。
3.2.2 迭代器参数
树
- eta [default=0.3, alias: learning_rate]
代表学习率的意思,每一棵树的预测值乘以学习率然后再相加,这样可以降低每一棵树的影响,从而降低过拟和。
- gamma [default=0, alias: min_split_loss]
代表损失下降的最小值,损失下降可以理解为类似信息增益的概念,当小于该值的时候意味着在此处进行分裂,给树带来的区分度效果有限,同时又增加了树的复杂度。
- max_depth [default=6]
代表每棵树在生成时的最大深度,越深树越复杂,越容易过拟和,越浅树越简单,但是过简单会使预测能力不足,调整该值可以平衡偏差和方差。
- min_child_weight [default=1]
代表每个孩子节点的二阶导数之和的下限,二阶导数即前面理论推导的hi,该值可以代表样本的权重,而孩子节点的二阶导数之和即前面理论推导的Hj,控制该值的下限可以让树生成更有统计意义的规则,防止过拟和。
- max_delta_step [default=0]
该参数在逻辑回归任务中,当样本分布极不均衡时,可以起到平衡偏差方差的作用,常用值在[1, 10]。
- subsample [default=1]
训练样本的比例,迭代时随机的按比例选取样本,用来防止过拟和,每一次迭代都会重新随机的选取样本。
- colsample_bytree, colsample_bylevel, colsample_bynode [default=1]
这几个参数都是对于列的随机采样,其中colsample_bytree是树级别的采样,也是这三个中常有的参数。
- lambda [default=1, alias: reg_lambda]
代表L2正则项,可以影响预测值的大小,用来平衡偏差和方差。
- alpha [default=0, alias: reg_alpha]
代表L1正则项,可以影响树的叶节点个数,用来平衡偏差和方差。
- scale_pos_weight [default=1]
用以调节正负样本的权重,对非平衡类别有用,推荐值:负样本数量 / 正样本数量
线性迭代器
- lambda [default=0, alias: reg_lambda]
L2正则项,用以平衡偏差和方差。
- alpha [default=0, alias: reg_alpha]
L1正则项,用以平衡偏差和方差。
3.2.3 学习任务参数
- objective
目标函数,reg代表回归任务,binary代表二分类任务,multi代表多分类任务,rank代表排序任务。需要说明的是也可以自定义目标函数
reg:squarederror:误差平方
reg:squaredlogerror:对数误差平方
reg:logistic: 逻辑回归
binary:logistic:二分类逻辑回归,输出概率
binary:logitraw:二分类逻辑回归,输出logistic转化之前的分数
binary:hinge:hinge损失用于二分类,输出0或1
multi:softmax:softmax损失
multi:prob:softmax损失,输出概率
- base_score
迭代初始化分数,相当于前述中的yi(0),如果迭代次数足够多,这个参数的改变,对结果影响不大。
- eval_metric
验证集评估指标,该指标默认会根据目标函数自动选取,也可手工指定,需要说明的是也可以自定义评估指标。
rmse:差的平方再平均再开根号

rmsle:对数之差的平方再平均再开根号
mae:差的绝对值再平均

logloss:对数损失
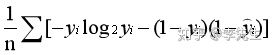
error:二分类错误率, #(wrong cases)/#(all cases),默认大于0.5为1,其余为0。
error@t:同上,不同的地方在于可以赋值t来指定阈值。
merror:多分类错误率,#(wrong cases)/#(all cases)
mlogloss:多分类对数损失
auc:roc曲线下的面积,衡量多个切分点下1和0的召回率情况。roc曲线x=1 - recall(0),y = recall(1)
- seed:随机序列种子
学习完本章以后,你应用明白xgboost算法背后的原理,包括模型组织和求解过程,并且对重要的参数有较深的理解。