YOLO相关问题
网络:
YOLO v1深入理解
YOLOv2 / YOLO9000 深入理解
YOLOv3 深入理解
Yolo三部曲解读——Yolov3
一文读懂YOLO V5 与 YOLO V4
深入浅出Yolo系列核心基础完整讲解汇总
目标检测之YOLO算法:YOLOv1,YOLOv2,YOLOv3 YOLOv4,YOLOv5详解汇总
1、YOLOV2相对YOLOV1的改进
Yolo v2相比yolo v1更快,而且更准。它有以下几点改进:
1、batch normalization:使用了BatchNorm,不再使用droput让网络更容易拟合。
2、使用高分辨率图像微调分类模型:在预训练的ImageNet模型上,使用更高分辨率图片对模型进行fine-tune,得到了更好的分类器。
3、采用先验框:使用了anchor,去除了yolo v1中的全连接层,此处借鉴了faster rcnn的anchor策略,全部改为卷积层来预测边界框。
4、聚类提取先验框尺度:使用了维度聚类的方法(以iou为距离度量,对先验框进行kmeans聚类),获得了更好的先验框,让网络得到了更好的预测结果。
5、多尺度训练,使用了不同尺寸的图片进行训练,使网络可以适应不同分辨率大小的数据。
6、约束预测边框的位置:直接预测物体中心相对于所处网格的坐标。
7、passthrough层检测细粒度特征: 跳过连接,融合不同尺度的特征。多尺度训练
2、YOLOV3相对YOLOV2的改进
Yolo v3相比于yolo v2精度更高,速度稍有下降。它主要在以下几个方面进行了改进:
1、特征提取网络采用了残差结构,并且层数更多。
2、Yolo v3在3个尺度上进行检测,依次检测大、中、小物体。
相比于Yolov2,Yolov3加深了网络,并且采用了3种尺度进行检测,使用了更多的anchor,速度明显更慢(推理时间为29ms),但精度却提升了不少(mAP-50达到了55.3),并且对于小目标的检测,效果更好。
3、YOLO V2 的边框回归:
约束预测边框的位置:
Faster rcnn 边框回归参考:Bounding-box regression详解(边框回归)_ytusdc的博客-CSDN博客_边界盒回归
简化成如下公式:
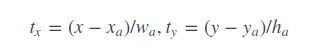
其位置预测公式为:

![]() 是预测边框的中心
是预测边框的中心![]() 是先验框(anchor)的中心点坐标
是先验框(anchor)的中心点坐标
![]() 是先验框(anchor)的宽和高,
是先验框(anchor)的宽和高,
![]() 是要学习的参数, 也就是位置偏移量
是要学习的参数, 也就是位置偏移量
首先 ,
,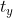 代表相对于预设固定值的偏移量。由于,的取值没有任何约束,因此预测边框的中心可能出现在任何位置:举个栗子,
代表相对于预设固定值的偏移量。由于,的取值没有任何约束,因此预测边框的中心可能出现在任何位置:举个栗子,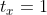 就会把box向右移动一个预定
就会把box向右移动一个预定 的距离,
的距离, 就会把box向左移动一个预定的距离。因此每个位置预测的边界框可以落在图片任何位置,这导致模型的不稳定性。
就会把box向左移动一个预定的距离。因此每个位置预测的边界框可以落在图片任何位置,这导致模型的不稳定性。
所以,YOLOv2弃用了上面这种预测offset的方式,而是沿用YOLOv1的方法,就是预测边界框中心点相对于对应cell左上角位置的相对偏移值,为了将边界框中心点约束在当前cell中,使用sigmoid函数处理偏移值,这样预测的偏移值在(0,1)范围内(每个cell的尺度看做1),由于sigmoid函数的处理,边界框的中心位置会约束在当前cell内部,防止偏移过多。公式如下:宽高回归采用指数的形式,防止出现负值




4、YOLOV2 相对于 YOLOV1 在Anchor Boxes 上的改进
在YOLOv1中,输入图片最终被划分为 7x7的 网格,每个单元格预测2个边界框。YOLOv1最后采用的是全连接层直接对边界框进行预测,其中边界框的宽与高是相对整张图片大小的,而由于各个图片中存在不同尺度和长宽比(scales and ratios)的物体,YOLOv1在训练过程中学习适应不同物体的形状是比较困难的,这也导致YOLOv1在精确定位方面表现较差。
YOLO通过全联接层直接预测bounding box坐标,而Faster R-CNN中RPN通过卷积层预测anchor的偏移和置信度,因为预测层是卷积层,预测偏移而不是坐标使得网络更易于学习。YOLO v2没有预测偏移量,沿用YOLO方法,但是采用卷积层,预测与网格位置相关的坐标
YOLOv2借鉴了Faster R-CNN中RPN网络的先验框(anchor boxes,prior boxes,SSD也采用了先验框)策略。RPN对CNN特征提取器得到的特征图(feature map)进行卷积来预测每个位置的边界框以及置信度(是否含有物体),并且各个位置设置不同尺度和比例的先验框,所以RPN预测的是 groundtruth 边界框相对于先验框的offsets值,采用先验框使得模型更容易学习。所以YOLOv2移除了YOLOv1中的全连接层而采用了卷积和anchor boxes来预测边界框。为了使检测所用的特征图分辨率更高,移除其中的一个pool层。
YOLOv2最后得到的特征图是 13 x 13 的,维度是奇数,这样特征图恰好只有一个中心位置。
为什么希望是维度是奇数?
奇数大小的宽和高会使得每个特征图在划分cell的时候就只有一个center cell(比如可以划分成7*7或9*9个cell,center cell只有一个,如果划分成8*8或10*10的,center cell就有4个)。
为什么希望只有一个center cell呢?
因为大的object一般会占据图像的中心,所以希望用一个center cell去预测,而不是4个center cell去预测。
对于一些大物体,它们中心点往往落入图片中心位置,此时使用特征图的一个中心点去预测这些物体的边界框相对容易些。所以在YOLOv2设计中要保证最终的特征图有奇数个位置。
对于YOLOv1中,每一个cell预测类别,对应2个bounding box预测坐标和置信度。 每个cell都预测2个boxes,每个boxes包含5个值:(x, y, w, h, c) 前4个值是边界框位置与大小,最后一个值是置信度(confidence scores,包含两部分:含有物体的概率以及预测框与ground truth的IOU)。但是每个cell只预测一套分类概率值(class predictions,其实是置信度下的条件概率值),供2个boxes共享。
YOLOv2使用了anchor boxes之后,每个位置的每一个anchor box都直接单独预测一套分类类别概率值,4个坐标和置信度,这和SSD比较类似(但SSD没有预测置信度,而是把background作为一个类别来处理)。下面这张从知乎拿来的图更形象。

5、为什么YOLOv2和YOLOv3的anchor大小有明显区别?
在YOLOv2中,作者用最后一层feature map的相对大小来定义anchor大小。也就是说,在YOLOv2中,最后一层feature map大小为13X13,相对的anchor大小范围就在(0x0,13x13],如果一个anchor大小是9x9,那么其在原图上的实际大小是288x288.
而在YOLOv3中,作者又改用相对于原图的大小来定义anchor,anchor的大小为(0x0,input_w x input_h]。
所以,在两份cfg文件中,anchor的大小有明显的区别。如下是作者自己的解释:
So YOLOv2 I made some design choice errors, I made the anchor box size be relative to the feature size in the last layer. Since the network was down-sampling by 32. This means it was relative to 32 pixels so an anchor of 9x9 was actually 288px x 288px.
In YOLOv3 anchor sizes are actual pixel values. this simplifies a lot of stuff and was only a little bit harder to implement
6、损失函数
YOLOV3损失函数:

置信度误差和分类误差都使用二分类损失误差(BCE)。至于分类误差并未使用多分类交叉熵误差,原文是这样解释的,使用单独的逻辑分类器有助于网络在开放数据集上的表现,这些数据集内通常包含重叠的标签(比如人和男人),使用softmax就意味着每个预测框必须是确定的某一个类别,而使用多标签的方法可以更好对数据建模。定位误差使用平方根损失误差(MSE)。
另外,为了缓解背景框和前景框的不平衡问题(在所有的预测框中,前景框只有极少一部分),增加了额外两个参数λcoor和λnoobj,在Yolov1中λcoor=5,λnoobj=0.5,提高前景框定位误差的权重,降低背景框的权重。
7、在你的项目中为什么选用yolov5模型而不用v4?
yolov4和v5都是yolo系列性能非常优秀的算法,性能上不分伯仲,而且最近出来的scale yolov4更是达到了55的map。在项目中选择v5的原因是因为在v4、v5出来之前,就一直在用U版的yolov3,相对于原版的v3,做了很多改进,而V5是在这个hub的基础上改进的,用起来上手比较快,而且代码和之前的v3相似度很高,可以无缝对接以前的项目。另一方面,v5可选的模型比较多,在速度和精度上对比v4有一定的优势,而且模型采用半精度存储,模型很小,训练和推理上都很友好。通常用s或者m版本的基本上都可以满足项目需求。
比较官方一点的回答:
- 使用Pytorch框架,对用户非常友好,能够方便地训练自己的数据集,相对于YOLOV4采用的Darknet框架,Pytorch框架更容易投入生产。
- 代码易读,整合了大量的计算机视觉技术,非常有利于学习和借鉴。
- 不仅易于配置环境,模型训练也非常快速,并且批处理推理产生实时结果。
- 能够直接对单个图像,批处理图像,视频甚至网络摄像头端口输入进行有效推理。
- 能够轻松的将Pytorch权重文件转化为安卓使用的ONXX格式,然后可以转换为OPENCV的使用格式,或者通过CoreML转化为IOS格式,直接部署到手机应用端。
- 最后YOLO V5s高达140FPS的对象识别速度令人印象非常深刻,使用体验非常棒。
8、介绍yolov5中Focus模块的原理和作用
Focus模块,将W、H信息集中到通道空间,输入通道扩充了4倍,作用是可以使信息不丢失的情况下提高计算力。具体操作为把一张图片每隔一个像素拿到一个值,类似于邻近下采样,这样我们就拿到了4张图,4张图片互补,长的差不多,但信息没有丢失,拼接起来相当于RGB模式下变为12个通道,通道多少对计算量影响不大,但图像缩小,大大减少了计算量。
以Yolov5s的结构为例,原始640×640×3的图像输入Focus结构,采用切片操作,先变成320×320×12的特征图,再经过一次32个卷积核的卷积操作,最终变成320×320×32的特征图。
9、yolov4和v5均引入了CSP结构,介绍一下它的原理和作用
CSP结构是一种思想,它和ResNet、DenseNet类似,可以看作是DenseNet的升级版,它将feature map拆成两个部分,一部分进行卷积操作,另一部分和上一部分卷积操作的结果进行concate。主要解决了三个问题:1. 增强CNN的学习能力,能够在轻量化的同时保持着准确性;2. 降低计算成本;3. 降低内存开销。CSPNet改进了密集块和过渡层的信息流,优化了梯度反向传播的路径,提升了网络的学习能力,同时在处理速度和内存方面提升了不少。
强CNN学习能力的Backbone:CSPNet
10. SSD相比于YOLO做了哪些改进?
这里说的是SSD相对于YOLOv1的改进,因为现在SSD已经不更了,但是YOLO还如日中天,已经发展到v5,性能在目标检测算法里一骑绝尘。那么最原始的SSD相对于YOLOv1做了哪些改进呢?
- SSD提取了不同尺度的特征图来做检测,而YOLO在检测是只用了最高层的Feature maps;
- SSD引入了Faster-RCNN的anchor机制,采用了不同尺度和长宽比的先验框;
- SSD网络结构是全卷积,采用卷积做检测,YOLO用到了FC(全连接)层;
2. 介绍一下YOLOv3的原理?
yolov3采用了作者自己设计的darknet53作为主干网络,darknet53借鉴了残差网络的思想,与resnet101、resnet152相比,在精度上差不多的同时,有着更快的速度,网络里使用了大量的残差跳层连接,并且抛弃了pooling池化操作,直接使用步长为2的卷积来实现下采样。在特征融合方面,为了加强小目标的检测,引入了类似与FPN的多尺度特征融合,特征图在经过上采样后与前面层的输出进行concat操作,浅层特征和深层特征的融合,使得yolov3在小目标的精度上有了很大的提升。yolov3的输出分为三个部分,首先是置信度、然后是坐标信息,最后是分类信息。在推理的时候,特征图会等分成S x S的网格,通过设置置信度阈值对格子进行筛选,如果某个格子上存在目标,那么这个格子就负责预测该物体的置信度、坐标和类别信息。
8. 介绍一下yolov5
yolov5和v4都是在v3基础上改进的,性能与v4基旗鼓相当,但是从用户的角度来说,易用性和工程性要优于v4,v5的原理可以分为四部分:
输入端、backbone、Neck、输出端;输入端:针对小目标的检测,沿用了v4的mosaic增强,当然这个也是v5作者在他复现的v3上的原创,对不同的图片进行随机缩放、裁剪、排布后进行拼接;二是自适应锚框计算,在v3、v4中,初始化锚框是通过对coco数据集的进行聚类得到,v5中将锚框的计算加入了训练的代码中,每次训练时,自适应的计算不同训练集中的最佳锚框值;
backbone:沿用了V4的CSPDarkNet53结构,但是在图片输入前加入了Focus切片操作,CSP结构实际上就是基于Densnet的思想,复制基础层的特征映射图,通过dense block发送到下一个阶段,从而将基础层的特征映射图分离出来。这样可以有效缓解梯度消失问题,支持特征传播,鼓励网络重用特征,从而减少网络参数数量。在V5中,提供了四种不同大小的网络结构:s、m、l、x,通过depth(深度)和width(宽度)两个参数控制。
Neck:采用了SPP+PAN多尺度特征融合,PAN是一种自下而上的特征金字塔结构,是在FPN的基础上进行的改进,相对于FPN有着更好的特征融合效果。
输出端:沿用了V3的head,使用GIOU损失进行边框回归,输出还是三个部分:置信度、边框信息、分类信息。
9. 在你的项目中为什么选用yolov5模型而不用v4?
yolov4和v5都是yolo系列性能非常优秀的算法,性能上不分伯仲,而且最近出来的scale yolov4更是达到了55的map。在项目中选择v5的原因是因为在v4、v5出来之前,就一直在用U版的yolov3,相对于原版的v3,做了很多改进,而V5是在这个hub的基础上改进的,用起来上手比较快,而且代码和之前的v3相似度很高,可以无缝对接以前的项目。另一方面,v5可选的模型比较多,在速度和精度上对比v4有一定的优势,而且模型采用半精度存储,模型很小,训练和推理上都很友好。通常用s或者m版本的基本上都可以满足项目需求。
比较官方一点的回答:
-
使用Pytorch框架,对用户非常友好,能够方便地训练自己的数据集,相对于YOLOV4采用的Darknet框架,Pytorch框架更容易投入生产。
-
代码易读,整合了大量的计算机视觉技术,非常有利于学习和借鉴。
-
不仅易于配置环境,模型训练也非常快速,并且批处理推理产生实时结果。
-
能够直接对单个图像,批处理图像,视频甚至网络摄像头端口输入进行有效推理。
-
能够轻松的将Pytorch权重文件转化为安卓使用的ONXX格式,然后可以转换为OPENCV的使用格式,或者通过CoreML转化为IOS格式,直接部署到手机应用端。
-
最后YOLO V5s高达140FPS的对象识别速度令人印象非常深刻,使用体验非常棒。
10. 介绍yolov5中Focus模块的原理和作用
Focus模块,将W、H信息集中到通道空间,输入通道扩充了4倍,作用是可以使信息不丢失的情况下提高计算力。具体操作为把一张图片每隔一个像素拿到一个值,类似于邻近下采样,这样我们就拿到了4张图,4张图片互补,长的差不多,但信息没有丢失,拼接起来相当于RGB模式下变为12个通道,通道多少对计算量影响不大,但图像缩小,大大减少了计算量。
以Yolov5s的结构为例,原始640×640×3的图像输入Focus结构,采用切片操作,先变成320×320×12的特征图,再经过一次32个卷积核的卷积操作,最终变成320×320×32的特征图。

11.yolov4和v5均引入了CSP结构,介绍一下它的原理和作用;
CSP结构是一种思想,它和ResNet、DenseNet类似,可以看作是DenseNet的升级版,它将feature map拆成两个部分,一部分进行卷积操作,另一部分和上一部分卷积操作的结果进行concate。主要解决了三个问题:1. 增强CNN的学习能力,能够在轻量化的同时保持着准确性;2. 降低计算成本;3. 降低内存开销。CSPNet改进了密集块和过渡层的信息流,优化了梯度反向传播的路径,提升了网络的学习能力,同时在处理速度和内存方面提升了不少。
可以看deepsystem.ai的PPT,讲的很详细
https://docs.google.com/presentation/d/1aeRvtKG21KHdD5lg6Hgyhx5rPq_ZOsGjG5rJ1HP7BbA/pub?start=false&loop=false&delayms=3000&slide=id.p