机器学习交叉验证和网格搜索案例分析
目录
- 1 什么是交叉验证(cross validation)
-
- 1.1 分析
- 1.2 为什么需要交叉验证
- 2 什么是网格搜索(Grid Search)
- 3 交叉验证-网格搜索API:
- 4 鸢尾花案例增加K值调优
- 5 Facebook签到的位置预测
-
- 5.1 数据集介绍
- 5.2 步骤分析
- 5.3 代码实现
- 6 总结
1 什么是交叉验证(cross validation)
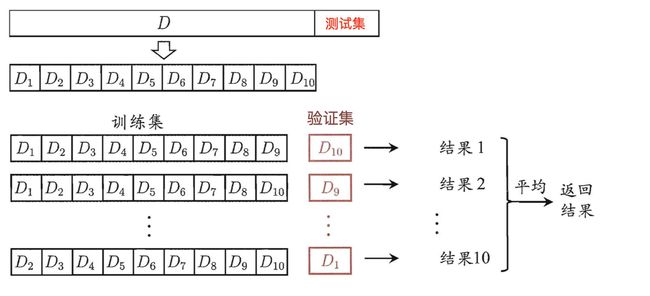
交叉验证:将拿到的训练数据,分为训练和验证集。以下图为例:将数据分成4份,其中一份作为验证集。然后经过4次(组)的测试,每次都更换不同的验证集。即得到4组模型的结果,取平均值作为最终结果。又称4折交叉验证。
1.1 分析
我们之前知道数据分为训练集和测试集,但是**为了让从训练得到模型结果更加准确。**做以下处理
- 训练集:训练集+验证集
- 测试集:测试集
1.2 为什么需要交叉验证
交叉验证目的:为了让被评估的模型更加准确可信
问题:这个只是让被评估的模型更加准确可信,那么怎么选择或者调优参数呢?
2 什么是网格搜索(Grid Search)
通常情况下,有很多参数是需要手动指定的(如k-近邻算法中的K值),这种叫超参数。但是手动过程繁杂,所以需要对模型预设几种超参数组合。每组超参数都采用交叉验证来进行评估。最后选出最优参数组合建立模型。

3 交叉验证-网格搜索API:
- sklearn.model_selection.GridSearchCV(estimator, param_grid=None,cv=None)
- 解释:对估计器的指定参数值进行详尽搜索
- 参数:
- estimator:估计器对象
- param_grid:估计器参数(dict){“n_neighbors”:[1,3,5]}
- cv:指定几折交叉验证
- 方法:
- fit:输入训练数据
- score:准确率
- 结果分析:
- bestscore__:在交叉验证中验证的最好结果
- bestestimator:最好的参数模型
- cvresults:每次交叉验证后的验证集准确率结果和训练集准确率结果
4 鸢尾花案例增加K值调优
- 使用GridSearchCV构建估计器
# 1、获取数据集
iris = load_iris()
# 2、数据基本处理 -- 划分数据集
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, random_state=22)
# 3、特征工程:标准化
# 实例化一个转换器类
transfer = StandardScaler()
# 调用fit_transform
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
# 4、KNN预估器流程
# 4.1 实例化预估器类
estimator = KNeighborsClassifier()
# 4.2 模型选择与调优——网格搜索和交叉验证
# 准备要调的超参数
param_dict = {"n_neighbors": [1, 3, 5]}
estimator = GridSearchCV(estimator, param_grid=param_dict, cv=3)
# 4.3 fit数据进行训练
estimator.fit(x_train, y_train)
# 5、评估模型效果
# 方法a:比对预测结果和真实值
y_predict = estimator.predict(x_test)
print("比对预测结果和真实值:\n", y_predict == y_test)
# 方法b:直接计算准确率
score = estimator.score(x_test, y_test)
print("直接计算准确率:\n", score)
- 然后进行评估查看最终选择的结果和交叉验证的结果
print("在交叉验证中验证的最好结果:\n", estimator.best_score_)
print("最好的参数模型:\n", estimator.best_estimator_)
print("每次交叉验证后的准确率结果:\n", estimator.cv_results_)
- 最终结果
比对预测结果和真实值:
[ True True True True True True True False True True True True
True True True True True True False True True True True True
True True True True True True True True True True True True
True True]
直接计算准确率:
0.947368421053
在交叉验证中验证的最好结果:
0.973214285714
最好的参数模型:
KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
metric_params=None, n_jobs=1, n_neighbors=5, p=2,
weights='uniform')
每次交叉验证后的准确率结果:
{'mean_fit_time': array([ 0.00114751, 0.00027037, 0.00024462]), 'std_fit_time': array([ 1.13901511e-03, 1.25300249e-05, 1.11011951e-05]), 'mean_score_time': array([ 0.00085751, 0.00048693, 0.00045625]), 'std_score_time': array([ 3.52785082e-04, 2.87650037e-05, 5.29673344e-06]), 'param_n_neighbors': masked_array(data = [1 3 5],
mask = [False False False],
fill_value = ?)
, 'params': [{'n_neighbors': 1}, {'n_neighbors': 3}, {'n_neighbors': 5}], 'split0_test_score': array([ 0.97368421, 0.97368421, 0.97368421]), 'split1_test_score': array([ 0.97297297, 0.97297297, 0.97297297]), 'split2_test_score': array([ 0.94594595, 0.89189189, 0.97297297]), 'mean_test_score': array([ 0.96428571, 0.94642857, 0.97321429]), 'std_test_score': array([ 0.01288472, 0.03830641, 0.00033675]), 'rank_test_score': array([2, 3, 1], dtype=int32), 'split0_train_score': array([ 1. , 0.95945946, 0.97297297]), 'split1_train_score': array([ 1. , 0.96 , 0.97333333]), 'split2_train_score': array([ 1. , 0.96, 0.96]), 'mean_train_score': array([ 1. , 0.95981982, 0.96876877]), 'std_train_score': array([ 0. , 0.00025481, 0.0062022 ])}
5 Facebook签到的位置预测

- 本次比赛的目的是预测一个人将要签到的地方。
- 为了本次比赛,创建了一个虚拟世界,其中包括10公里*10公里共100平方公里的约10万个地方。
- 对于给定的坐标集,您的任务将根据用户的位置,准确性和时间戳等预测用户下一次的签到位置。
- 数据被制作成类似于来自移动设备的位置数据。
- 请注意:您只能使用提供的数据进行预测。
5.1 数据集介绍
数据介绍:
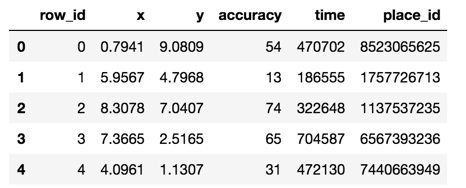
文件说明 train.csv, test.csv
row id:签入事件的id
x y:坐标
accuracy: 准确度,定位精度
time: 时间戳
place_id: 签到的位置,这也是你需要预测的内容
官网:
https://www.kaggle.com/c/facebook-v-predicting-check-ins
5.2 步骤分析
- 对于数据做一些基本处理(这里所做的一些处理不一定达到很好的效果,我们只是简单尝试,有些特征我们可以根据一些特征选择的方式去做处理)
- 1 缩小数据集范围 DataFrame.query()
- 2 选取有用的时间特征
- 3 将签到位置少于n个用户的删除
- 分割数据集
- 标准化处理
- k-近邻预测
具体步骤:
# 1.获取数据集
# 2.基本数据处理
# 2.1 缩小数据范围
# 2.2 选择时间特征
# 2.3 去掉签到较少的地方
# 2.4 确定特征值和目标值
# 2.5 分割数据集
# 3.特征工程 -- 特征预处理(标准化)
# 4.机器学习 -- knn+cv
# 5.模型评估
5.3 代码实现
- 1.获取数据集
# 1、获取数据集
facebook = pd.read_csv("./data/FBlocation/train.csv")
- 2.基本数据处理
# 2.基本数据处理
# 2.1 缩小数据范围
facebook_data = facebook.query("x>2.0 & x<2.5 & y>2.0 & y<2.5")
# 2.2 选择时间特征
time = pd.to_datetime(facebook_data["time"], unit="s")
time = pd.DatetimeIndex(time)
facebook_data["day"] = time.day
facebook_data["hour"] = time.hour
facebook_data["weekday"] = time.weekday
# 2.3 去掉签到较少的地方
place_count = facebook_data.groupby("place_id").count()
place_count = place_count[place_count["row_id"]>3]
facebook_data = facebook_data[facebook_data["place_id"].isin(place_count.index)]
# 2.4 确定特征值和目标值
x = facebook_data[["x", "y", "accuracy", "day", "hour", "weekday"]]
y = facebook_data["place_id"]
# 2.5 分割数据集
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=22)
- 3.特征工程–特征预处理(标准化)
# 3.特征工程--特征预处理(标准化)
# 3.1 实例化一个转换器
transfer = StandardScaler()
# 3.2 调用fit_transform
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
- 4.机器学习–knn+cv
# 4.机器学习--knn+cv
# 4.1 实例化一个估计器
estimator = KNeighborsClassifier()
# 4.2 调用gridsearchCV
param_grid = {"n_neighbors": [1, 3, 5, 7, 9]}
estimator = GridSearchCV(estimator, param_grid=param_grid, cv=5)
# 4.3 模型训练
estimator.fit(x_train, y_train)
- 5.模型评估
# 5.模型评估
# 5.1 基本评估方式
score = estimator.score(x_test, y_test)
print("最后预测的准确率为:\n", score)
y_predict = estimator.predict(x_test)
print("最后的预测值为:\n", y_predict)
print("预测值和真实值的对比情况:\n", y_predict == y_test)
# 5.2 使用交叉验证后的评估方式
print("在交叉验证中验证的最好结果:\n", estimator.best_score_)
print("最好的参数模型:\n", estimator.best_estimator_)
print("每次交叉验证后的验证集准确率结果和训练集准确率结果:\n",estimator.cv_results_)
6 总结
- 交叉验证【知道】
- 定义:
- 将拿到的训练数据,分为训练和验证集
- *折交叉验证
- 分割方式:
- 训练集:训练集+验证集
- 测试集:测试集
- 为什么需要交叉验证
- 为了让被评估的模型更加准确可信
- 注意:交叉验证不能提高模型的准确率
- 定义:
- 网格搜索【知道】
- 超参数:
- sklearn中,需要手动指定的参数,叫做超参数
- 网格搜索就是把这些超参数的值,通过字典的形式传递进去,然后进行选择最优值
- 超参数:
- api【知道】
- sklearn.model_selection.GridSearchCV(estimator, param_grid=None,cv=None)
- estimator – 选择了哪个训练模型
- param_grid – 需要传递的超参数
- cv – 几折交叉验证
- sklearn.model_selection.GridSearchCV(estimator, param_grid=None,cv=None)