梯度提升Adaboost
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.metrics import accuracy_score, classification_report, roc_curve, auc
from sklearn.neighbors import KNeighborsClassifier
from sklearn.ensemble import AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.svm import SVC
from sklearn.model_selection import train_test_split, GridSearchCV, learning_curve
from sklearn.pipeline import Pipeline
from sklearn import ensemble
import warnings
warnings.filterwarnings('ignore')
读取数据
# 读入数据,查看数据集
df = pd.read_csv(r'UCI_Credit_Card.csv')
df.shape
df.info()
RangeIndex: 30000 entries, 0 to 29999
Data columns (total 25 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 ID 30000 non-null int64
1 LIMIT_BAL 30000 non-null float64
2 SEX 30000 non-null int64
3 EDUCATION 30000 non-null int64
4 MARRIAGE 30000 non-null int64
5 AGE 30000 non-null int64
6 PAY_0 30000 non-null int64
7 PAY_2 30000 non-null int64
8 PAY_3 30000 non-null int64
9 PAY_4 30000 non-null int64
10 PAY_5 30000 non-null int64
11 PAY_6 30000 non-null int64
12 BILL_AMT1 30000 non-null float64
13 BILL_AMT2 30000 non-null float64
14 BILL_AMT3 30000 non-null float64
15 BILL_AMT4 30000 non-null float64
16 BILL_AMT5 30000 non-null float64
17 BILL_AMT6 30000 non-null float64
18 PAY_AMT1 30000 non-null float64
19 PAY_AMT2 30000 non-null float64
20 PAY_AMT3 30000 non-null float64
21 PAY_AMT4 30000 non-null float64
22 PAY_AMT5 30000 non-null float64
23 PAY_AMT6 30000 non-null float64
24 default.payment.next.month 30000 non-null int64
dtypes: float64(13), int64(12)
memory usage: 5.7 MB
数据集:信用卡违约数据,包含30000条记录和25个变量,
因变量表示用户在下个月的信用卡还款中是否存在违约情况(1表示违约、0表示不违约),
自变量包含性别、教育水平、年龄、婚姻状况、信用额度、6个月的历史还款状态、账单金额以及还款金额。
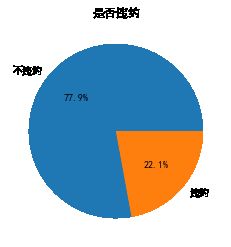
绘制标签比例饼图
df.rename(columns={'default.payment.next.month': 'y'}, inplace=True)
# 将横纵坐标轴标准化,为确保绘制的饼图为圆形
plt.axes(aspect='equal')
# 统计客户是否违约的频数
counts = df.y.value_counts()
# 绘制饼图
plt.rcParams['font.sans-serif'] = ['SimHei'] # 显示中文
plt.pie(x=counts, # 绘图数据
labels=pd.Series(counts.index).map({0: '不违约', 1: '违约'}),
autopct='%.1f%%' # 设置百分比的格式,保留一位小数
)
plt.title('是否违约')
# 保存图形
plt.savefig('是否违约饼图.png', dpi=300)
# 显示图形
plt.show()
建模训练预测
# 排除数据集中的ID变量和因变量,剩余的数据用作自变量 X
X = df.drop(['ID', 'y'], axis=1)
y = df.y
# 数据拆分
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=1234)
# 构建Adaboost算法的类
Adaboost1 = AdaBoostClassifier()
# 算法在训练数据集上的拟合
Adaboost1.fit(X_train, y_train)
# 算法在测试数据集上的预测
pred1 = Adaboost1.predict(X_test)
# 返回模型预测的结果
print('模型的准确率为:\n', accuracy_score(y_test, pred1))
print('模型的评估报告:\n', classification_report(y_test, pred1))
模型的准确率为:
0.8125333333333333
模型的评估报告:
precision recall f1-score support
0 0.83 0.96 0.89 5800
1 0.68 0.32 0.44 1700
accuracy 0.81 7500
macro avg 0.75 0.64 0.66 7500
weighted avg 0.80 0.81 0.79 7500
print 之后的参数说明:
- precision 精度 = TP / (TP + FP)
- recall 召回率 = TP / (TP + TN)
- f1-score F1值 是上面两个的调和平均值
- support 为每个标签出现的次数
- accuracy = 分类正确的样本个数 / 分类的所有样本的个数
- macro avg = 宏平均 :所有类的F1值取一个算术平均就得到了Macro-average
- weight avg 加权平均
使用默认参数得到模型准确率为81.25%;预测客户违约(y=1)的精准率为68%,覆盖率为32%;预测客户不违约的精准率为83%,覆盖率为96;
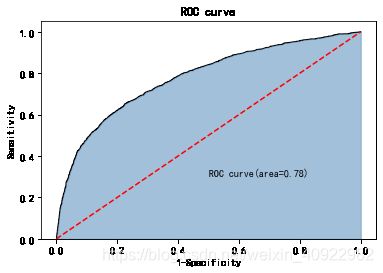
绘制ROC曲线
# 计算客户违约的概率值,用于生成ROC曲线
y_score = Adaboost1.predict_proba(X_test)[:,1]
fpr, tpr, threshold = roc_curve(y_test, y_score)
# 计算AUC值
roc_auc = auc(fpr, tpr)
# 绘制面积图
plt.stackplot(fpr, tpr, color='steelblue', alpha=0.5, edgecolor='black')
# 添加边际线
plt.plot(fpr, tpr, color='black', lw=1)
# 添加对角线
plt.plot([0,1],[0,1], color='red', linestyle='--')
# 添加文本信息
plt.text(0.5, 0.3, 'ROC curve(area=%0.2f)' % roc_auc)
# 添加x轴与y轴标签
plt.xlabel('1-Specificity')
plt.ylabel('Sensitivity')
plt.title('ROC curve')
# 保存图片
plt.savefig('auc_roc.png', dpi=300)
# 显示图片
plt.show()
采取交叉验证寻找最合适参数以及特征筛选选出影响客户是否违约的因素
# 自变量的重要性排序
importance = pd.Series(Adaboost1.feature_importances_, index=X.columns)
importance.sort_values().plot(kind='barh')
plt.title('自变量重要性排序')
plt.savefig('自变量重要性排序.png', dpi=300)
plt.show()
predictors = list(importance[importance>0.02].index)
predictors
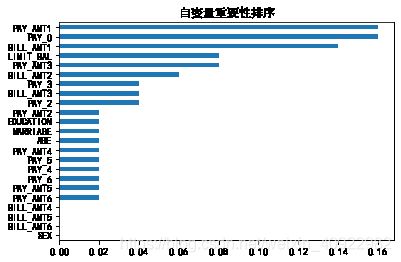
['LIMIT_BAL',
'PAY_0',
'PAY_2',
'PAY_3',
'BILL_AMT1',
'BILL_AMT2',
'BILL_AMT3',
'PAY_AMT1',
'PAY_AMT3']
通过网格搜索法选择基础模型所对应的合理参数组合
max_depth = [2,3,4,5,6]
#learning_rate = [0.01, 0.05, 0.1, 0.2, 0.3, 0.4, 0.5]
params1 = {'base_estimator__max_depth':max_depth}
base_model = GridSearchCV(estimator=ensemble.AdaBoostClassifier(base_estimator=DecisionTreeClassifier()),
param_grid=params1, scoring='roc_auc', cv=5, n_jobs=4, verbose=1)
base_model.fit(X_train[predictors], y_train)
# 返回参数的最佳组合和对应的AUC值
base_model.best_params_, base_model.best_score_
# 最优深度
optimal_max_depth=base_model.best_params_['base_estimator__max_depth']b
Fitting 5 folds for each of 5 candidates, totalling 25 fits
[Parallel(n_jobs=4)]: Using backend LokyBackend with 4 concurrent workers.
[Parallel(n_jobs=4)]: Done 25 out of 25 | elapsed: 16.6s finished
optimal_max_depth
2
通过网格搜索法选择提升树的合理参数组合
n_estimators = [100,200,300]
learning_rate = [0.01,0.05,0.1,0.2]
params2 = {'n_estimators':n_estimators,'learning_rate':learning_rate}
adaboost = GridSearchCV(estimator = ensemble.AdaBoostClassifier(base_estimator = DecisionTreeClassifier(max_depth = optimal_max_depth)),
param_grid= params2, scoring = 'roc_auc', cv = 5, n_jobs = 4, verbose = 1)
adaboost.fit(X_train[predictors] ,y_train)
# 返回参数的最佳组合和对应AUC值
adaboost.best_params_, adaboost.best_score_
optimal_n_estimators = adaboost.best_params_['n_estimators']
optimal_learning_rate = adaboost.best_params_['learning_rate']
Fitting 5 folds for each of 12 candidates, totalling 60 fits
[Parallel(n_jobs=4)]: Using backend LokyBackend with 4 concurrent workers.
[Parallel(n_jobs=4)]: Done 42 tasks | elapsed: 1.1min
[Parallel(n_jobs=4)]: Done 60 out of 60 | elapsed: 1.6min finished
print(optimal_n_estimators)
print(optimal_learning_rate)
300
0.05
使用最佳的参数组合构建AdaBoost模型
AdaBoost2 = ensemble.AdaBoostClassifier(base_estimator = DecisionTreeClassifier(max_depth = optimal_max_depth),
n_estimators = optimal_n_estimators, learning_rate = optimal_learning_rate)
# 算法在训练数据集上的拟合
AdaBoost2.fit(X_train[predictors],y_train)
# 算法在测试数据集上的预测
pred2 = AdaBoost2.predict(X_test[predictors])
# 返回模型的预测效果
print('模型的准确率为:\n',accuracy_score(y_test, pred2))
print('模型的评估报告:\n',classification_report(y_test, pred2))
模型的准确率为:
0.8156
模型的评估报告:
precision recall f1-score support
0 0.83 0.95 0.89 5800
1 0.69 0.34 0.46 1700
accuracy 0.82 7500
macro avg 0.76 0.65 0.67 7500
weighted avg 0.80 0.82 0.79 7500
模型准确率提高了 = 0.8156 - 0.8125 = 0.031
可以继续调优或者改选模型