神经网络卷积层Conv2d的使用
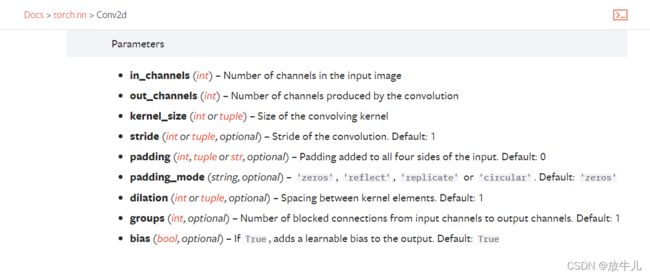
in_channels是输入的图片的channel数;out_channels是输出的通道数 ;kernel_size用来设置卷积核的大小,卷积核的初值是某个分布中的采样,随着训练的进行,值是不断变化的;stride是步径,卷积核移动的格数;padding是输入的外围拼接的大小。
out_channels取决于卷积核的数量,卷积核也有in_channels参数,该参数取决于需要进行卷积操作的数据的channels。例如,6*6*3的图片样本,使用3*3*3的卷积核,输入图片的channel为3,则卷积核的in_channels也为3,卷积就是对应27个数相乘后求和,依次进行,得到了4*4*1的结果,则out_channels为1,若使用两个卷积核,则4*4*2的结果,out_channels为2。
import torchvision
from torch import nn
from torch.nn import Conv2d
from torch.utils.data import DataLoader
dataset = torchvision.datasets.CIFAR10("./dataset", False, transform=torchvision.transforms.ToTensor(), download=True)
dataloader = DataLoader(dataset, batch_size=64)
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.conv1 = Conv2d(in_channels=3, out_channels=6, kernel_size=3)
def forward(self, x):
return self.conv1(x)上面创建好了数据集以及神经网络的框架,对数据集进行训练:
model = Model()
for data in dataloader:
imgs, targets = data
output = model(imgs)#因为已经转换为tensor类型数据,所以可以直接传入。
print(output.shape)
print(imgs.shape)运行结果为:
torch.Size([64, 6, 30, 30])
torch.Size([64, 3, 32, 32])
torch.Size([64, 6, 30, 30])
torch.Size([64, 3, 32, 32])... ...
因为dataloader的batch_size为64,out_channels设置为6,输入的图片大小为32*32,而kernel_size(卷积核)为3,则根据卷积运算过程可知输出的大小为30*30,所以输入为64*3*32*32,输出为64*6*30*30。实现图片的可视化,因为add_images函数有形状要求:
Shape:
img_tensor: Default is :math:`(N, 3, H, W)`. If ``dataformats`` is specified, other shape will be
accepted. e.g. NCHW or NHWC.
通道数只能为3,所以需要先进行形状的转换,在进行可视化:
model = Model()
writer = SummaryWriter("logs")
step = 0
for data in dataloader:
imgs, targets = data
output = model(imgs)#因为已经转换为tensor类型数据,所以可以直接传入。
writer.add_images("input", imgs, step)
output = torch.reshape(output, [-1, 3, 30, 30])
writer.add_images("output", output, step)
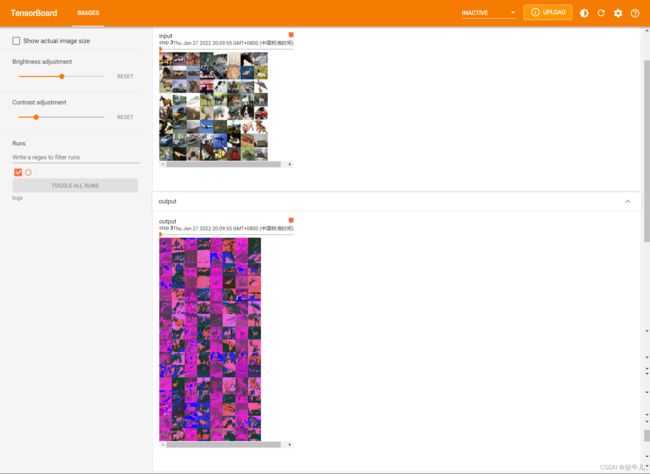
step += 1reshape的第一个参数-1表示根据其他数据自行调整。原来的6通道变为3通道,而30*30没有变化,那么就是batch_size进行了两两拼接,变为了原来的2倍。接着打开Tensorboard进行查看:
比如说常用的vgg16:
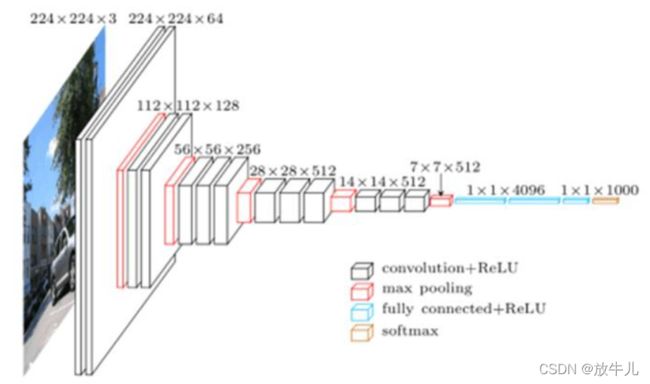
开头输入in_channels为3,经一次转换后,out_channels为64,224*224没有发生变化,是因为设置了padding参数,形状大小的计算可以由公式得到:
