Linux设备驱动基础02:Linux内核模块
目录
1. 内核模块概述
1.1 引入原因
1.2 内核模块含义
1.3 内核模块构成
2. 内核模块操作命令
2.1 加载模块
2.2 卸载模块
2.3 查看模块信息
2.3.1 lsmod
2.3.2 modinfo
3. 简单内核模块程序分析
3.1 头文件包含
3.2 __init & __exit宏分析
3.3 module_init & module_exit宏分析
3.3.1 module_init
3.3.2 module_exit
4. 内核模块编译
5. 内核模块参数
5.1 概述
5.2 语法
5.3 模块参数示例
6. 内核模块导出符号 & 内核模块依赖
6.1 内核符号表
6.2 模块导出符号至内核符号表
6.3 导出符号示例
6.4 模块依赖关系
6.5 生成模块依赖关系
6.5.1 modprobe原理简析
6.5.2 验证步骤
7. 内核打印函数printk
7.1 内核环形缓冲区(ring buffer)
7.2 打印等级
7.2.1 printk函数可用打印等级
7.2.2 打印等级的作用
7.3 封装使用printk
8. 开发板上加载 / 卸载模块
8.1 重新编译模块
8.2 将模块拷贝到NFS根文件系统中
8.3 加载模块
8.4 卸载模块
9. 其他主题
9.1 应用程序与内核模块比较
9.2 模块声明与描述
9.3 模块的使用计数
9.4 内核模块编程的安全问题
1. 内核模块概述
1.1 引入原因
Linux作为单内核操作系统,具有如下特点,
优点:效率高,因为内核中各功能模块的交互通过直接的函数调用实现
缺点:扩展性差,如果要增加 / 删除 / 修改内核的某个功能,不得不重新编译整个内核然后重启系统
内核模块的引入就是为了弥补单内核操作系统的缺点,他可以在需要的时候动态地加载到内核,从而扩展内核的功能;也可以在不需要的时候动态卸载,从而减少内核功能并节约内存(需要内核配置模块可卸载选项)
1.2 内核模块含义
① 内核模块是Linux内核向外部提供的一个插口,其全称为动态可加载内核模块(Loadable Kernel Module,LKM)
② 内核模块是具有独立功能的程序,他可以被单独编译,但不能单独运行。他在运行时被链接到内核作为内核的一部分在内核空间运行
③ 内核模块便于驱动、文件系统等的二次开发
1.3 内核模块构成
① 模块加载函数(一般需要)
被module_init宏修饰的函数,在模块被加载时调用
② 模块卸载函数(一般需要)
被module_exit宏修饰的函数,在模块被卸载时调用
③ 模块许可证声明(一般需要)
否则加载内核时,会有内核被污染(kernel tainted)的警告并带来如下后果,
a. 某些调试功能被关闭(Disabling lock debugging due to kernel taint)
b. 内核中的某些功能函数不能够调用(内核中以GPL license导出的符号均不能使用)
④ 模块参数(可选)
模块参数是一种内核空间与用户空间的交互方式,只不过是用户空间 --> 内核空间单向的,他对应模块内部的全局变量
注意:如果设置合适的模块参数权限,用户态是可以在/sys文件系统中修改模块参数的,但是这种方法并不推荐
⑤ 模块导出符号(可选)
一个模块可以导出函数或变量供其它模块使用
⑥ 模块描述信息(可选)
包括内核作者、描述、别名等

2. 内核模块操作命令
2.1 加载模块
insmod 模块路径(绝对 / 相对)
modprobe 模块路径(绝对 / 相对)说明1:insmod运行简单流程
① 为模块分配内核内存
② 将模块代码和数据装入内存
③ 通过内核符号表解析模块中的内核引用
④ 调用模块初始化函数(用module_init宏修饰的函数)
说明2:如果insmod要加载的模块有依赖模块,且其依赖的模块尚未加载,那么该insmod操作将失败
说明3:modprobe在加载模块时会同时加载该模块所依赖的其他模块,modprobe是根据模块的外部引用寻找其依赖的模块。关于内核模块的依赖关系,后文有详细说明~~
说明4:在内核中可以使用request_module函数加载内核模块
request_module(module_name);
// 示例
request_module("char-major-%d-%d", MAJOR(dev), MINOR(dev));2.2 卸载模块
rmmod 模块名称
modprobe -r 模块名称说明1:modprobe -r 在卸载模块时会同时卸载该模块所依赖的其他模块
说明2:如果内核认为模块仍在使用状态,或内核被配置为禁止卸载模块,则无法rmmod该模块
2.3 查看模块信息
2.3.1 lsmod
功能:查看系统中加载的所有模块及模块间的依赖关系
关于Used和by的说明:

Used为本模块被使用的次数,by指出使用该模块的是哪些模块
说明1:lsmod命令实际是解析/proc/modules文件得出上述结果

说明2:内核中已加载的模块信息也存在于/sys/module目录下

使用tree -a命令可以查看每个模块目录的结构

2.3.2 modinfo
用法:
modinfo 模块路径(相对 / 绝对)功能:查看某个模块的详细信息

说明1:modinfo查看的模块信息有2个来源,
① 内核模块描述信息,这些信息编码在内核模块源码中
② 编译系统信息,这些信息在编译内核模块的过程中由编译系统添加
说明2:关于vermagic
内核镜像(e.g. zImage)和内核模块均有vermagic信息,只有二者一致,才能将内核模块动态加载
要想确保模块与内核的vermagic一致,就需要保证编译内核 & 编译模块的内核源码树一致
内核的vermagic保存在源码的include/linux/vermagic.h中,是一系列宏定义的拼接

3. 简单内核模块程序分析

3.1 头文件包含
注意:和应用编程不同,内核编程所包含的头文件均来自内核源码;应用编程所包含的头文件一般由编译器提供
3.2 __init & __exit宏分析
![]()
![]()

根据上述宏定义,__init宏就是将模块初始化函数链接到.ini.text段;__exit宏就是将模块退出清理函数链接到.init.exit段。将这类函数链接到指定位置,可以便于控制这部分内存的释放节约空间
① .init.text段所在内存在模块被加载后将被释放
② .exit.init段所在内存在模块被编译进内核或者内核不允许卸载模块时将被释放;如果可动态卸载模块,在模块卸载后,这部分内存将被释放
补充:除了__init & __exit用于修饰加载 & 卸载函数,还有__initdata & __exitdata可用于修饰加载 & 卸载过程中使用到的数据,他们会被分别链接到.init.data & .exit.data段
3.3 module_init & module_exit宏分析
hello_init和hello_exit分别是该模块的初始化函数和退出清理函数,而这两个函数,也用module_init宏和module_exit宏修饰,下面分析一下这两个宏
3.3.1 module_init

分析module_init宏的注释可知:
① 所修饰函数的性质
模块初始化入口点,每个模块只能有一个
② 模块初始化函数调用时机
a. 如果该模块编译进内核(builtin),在调用do_initcalls函数时调用
b. 如果该模块可动态加载,在模块加载时调用
我们继续将__initcall宏展开,
__initcall宏:
![]()
device_initcall宏:

__define_initcall宏:


回顾一下宏的调用过程:
module_init(hello_init)
--> __initcall(hello_init)
--> device_initcall(hello_init)
--> __define_initcall("6", hello_init, 6)所以__define_initcall 宏展开后就是:
static initcall_t __initcall_hello_init_6 __used
__attribute__((__section__(".initcall""6"".init"))) = hello_init也就是定义了一个函数指针__initcall_hello_init_6,将其指向hello_init函数,并被链接到.inicall6.init 段
从中可以看出,模块初始化函数即使重名也不会导致问题,因为此处均用static修饰了定义的全局函数指针变量(已上机验证)
小结一下__int宏和module_init宏的作用和关系:
__init宏将模块初始化函数链接到.init.text段,目的是及时释放这部分内存
module_init宏定义了一个全局函数指针变量,指向该模块的初始化函数,这个指针本身也被链接到指定区域(.initcall6.init),目的是在内核启动或模块加载时调用模块初始化函数

3.3.2 module_exit

分析module_exit宏的注释可知:
① 所修饰函数的性质
模块离开入口点,每个模块只能有一个
② 模块退出清理函数调用时机
a. 如果该模块可动态加载,在卸载模块时调用
b. 如果编译进内核,该函数没有作用
![]()
![]()
可见对于模块退出清理函数也定义了一个全局函数指针变量,该指针被链接到.exitcall.exit段
4. 内核模块编译
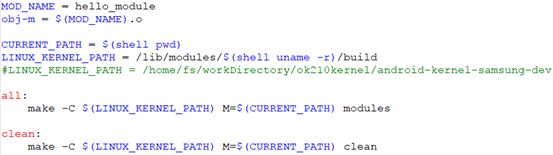
说明1:源码树依赖
上述Makefile中的LINUX_KERNEL_PATH变量用于指定编译内核模块时使用的源码树,所谓源码树就是经过配置编译之后的内核源码
说明2:模块目标
由于是编译为内核模块,所以目标必须是obj-m,该目标在内核的Makefile中定义

需要注意的是,编译模块的源文件名必须和模块目标名相同。比如此处目标名为hello_module.o,那么对应的源文件名必须是hello_module.c,否则编译不会成功
解释:obj-m = hello.o 的意思就是有一个模块要从目标文件hello.o 构造,而从该目标文件中构造出的模块名称为hello.ko
那如果一个模块有多个源文件怎么办 ? 此时可以使用module-objs来扩展
obj-m = module.o
module-objs = file1.o file2.o
说明3:编译命令解释
进入内核源码目录(由-C $(LINUX_KERNEL_PATH)指定),编译在内核源码树之外的一个目录(由M=$(CURRENT_PATH)指定)中的模块(由modules指定)
补充:如果不单独构建Makefile编译,也可以将模块源码拷贝到源码树目录(e.g. driver/),然后修改该目录下的Kconfig & Makefile实现编译
5. 内核模块参数
5.1 概述
内核模块的初始化函数在模块被加载时调用,但是该函数不接受参数。因此不便于在模块加载时对模块的行为进行控制(e.g. 在加载模块时向模块传递运行参数)
因此内核提供了模块参数机制,即在用户空间可以修改内核模块中全局变量的值。模块参数可以认为是一种单向(用户空间 --> 内核空间)的内核态 & 用户态交互机制
补充:如果将模块编译进内核(build-in),则无法使用内核模块参数
5.2 语法
module_param(参数名,参数类型,参数读/写权限);
module_param_array(数组名,数组元素类型,数组长,参数读/写权限);说明1:module_param宏定义在include/linux/moduleparam.h中,实现原理是定义struct kernel_param类型变量并链接到指定的段(__param段)


说明2:关于数组长度参数
2.6.0 ~ 2.6.10:需要将数组长度变量赋给"数组长"
2.6.10 之后:需要将数组长度变量的指针赋给"数组长",如果不需要保存实际输入的数组元素个数,可将"数组长"置为NULL
说明3:模块参数允许的参数类型
byte/short/ushort/int/uint/long/ulong/charp(字符指针)/bool/invbool(布尔的反)
模块编译时会将module_param/module_param_array中声明的类型与变量定义进行比较,判断是否一致。该检查是由module_param_named宏调用para_check_xxx函数族实现,该函数族会根据不同的参数类型调用不同函数检查参数的合法性
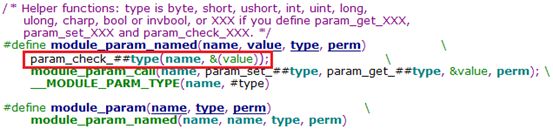

说明4:模块参数读写权限
该读写权限体现在/sys文件系统中,相关宏定义在include/linux/stat.h中

5.3 模块参数示例

如果加载模块时不传递参数,将使用模块内定义的缺省值

如果加载模块时传递参数,将使用传递的参数值
![]()

注意1:在传递参数book_name时,字符串中包含空格无法识别,需要转义
注意2:传递给数组的各个元素间用逗号分隔
说明:模块参数文件
如果模块包含参数,在/sys/module/模块名 目录下会有parameters目录,其中的文件就是各模块参数
![]()

6. 内核模块导出符号 & 内核模块依赖
6.1 内核符号表
/proc/kallsyms文件为内核符号表,他记录了内核符号及符号所在的内存地址
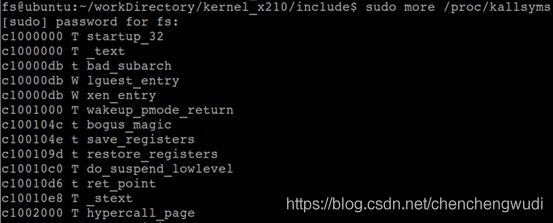
说明1:读取该文件内容必须使用sudo权限,否则显示的内存地址均为0
说明2:由于内核在32bit的虚拟地址空间使用3 ~ 4GB的内存空间,因此这些地址均 > c0000000(3GB)
说明3:内核符号表中的符号标志含义
T External text
t Local text
D External initialized data
d Local initialized data
B External zeroed data
b Local zeroed data
A External absolute
a Local absolute
U External undefined
G External small initialized data
g Local small initialized data
I Init section
S External small zeroed data
s Local small zeroed data
R External read only
r Local read only
C Common
E Small common
6.2 模块导出符号至内核符号表
目的:导出本模块的符号供内核其他模块使用
语法:
EXPORT_SYMBOL(符号名);
EXPORT_SYMBOL_GPL(符号名); // 导出的符号只能供GPL模块使用说明:其他模块使用被导出的符号时,只需提前使用extern声明即可
补充:extern解决编译问题,EXPORT_SYMBOL解决链接问题
分析:EXPORT_SYMBOL宏的实现
![]()


假设我们导出一个函数add_integer,尝试将其展开(简化了CRC那步)可得:
EXPORT_SYMBOL(add_integer) --->
__EXPORT_SYMBOL(add_integer, "") --->
extern typeof(add_integer) add_integer; \
static const char __kstrtab_add_integer[] \
__attribute__((section("__ksymtab_strings"), aligned(1))) \
= "add_integer"; \
static const struct kernel_symbol __ksymtab_add_integer\
__attribute__((section("__ksymtab"), unused)) \
= { (unsigned long)&add_integer, __kstrtab_add_integer }
从展开的结果看,首先定义了字符数组保存要导出符号的名字(该字符数组被链接到__ksymtab_strings段),然后定义了kernel_symbol结构体类型变量并将其链接到__ksymtab段。在kernel_symbol结构体中,value成员存储的是要导出符号的地址,name 存储的是要导出符号的名字字符串
从实现过程中可以看出,模块导出的符号必须是全局唯一的,否则__ksymtab段中就会有多个struct kernel_symbol结构体,虽然value成员不同,但是name成员相同,链接时会报错
讨论:内核中为何广泛使用指定链接段
从实现功能的角度,将一类变量链接到指定的段的效果,使用全局数组保存也能实现,但是使用指定链接段有如下优势,
① 无需预先指定数组大小,完全在链接过程中自己确定
② 可以动态管理指定链接段的内存,比如在不再需要时将其释放。但是全局数组都是链接到.data段(当然也可以链接到指定段,但是固定大小的问题依然无法解决),无法动态释放
6.3 导出符号示例

编译加载该模块,然后搜索内核符号表

结合上面对EXPORT_SYMBOL宏的分析,是不是发现内核符号表中的项目很眼熟~.~
r:Local read only
T:External text
需要使用add_integer函数的模块,只要在使用前声明一下即可:
extern int add_integer(int a, int b);6.4 模块依赖关系
我们首先编写一个使用add_interger的内核模块

编译该模块后,使用nm命令查看模块目标文件的符号表(.ko文件本质就是ELF格式文件)

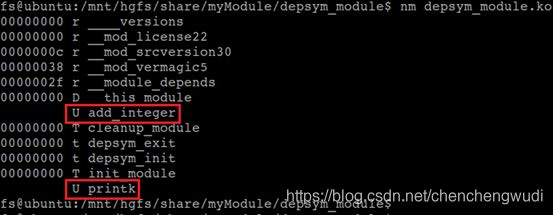
可见depsym.ko模块中的add_integer & printk的符号类型均为U,即External undefined(外部未定义)
在加载depsym_module.ko模块时,加载程序会处理上述未定义符号(在__ksymtab段搜未定义符号索)。如果找到,则将获得的地址填充在被加载模块的相应段中,这样符号的地址就可以确定;如果找不到,则报错退出
因此要加载depsym_module.ko,需要先加载expsym_module.ko,否则将无法解决未定义符号问题。因此使用导出符号的模块将会依赖导出符号的模块,同样地卸载时也要注意顺序问题,先卸载使用导出符号的模块
![]()

小结:这种处理未定义符号的方式相当于把链接过程推后,进行了动态链接,和应用程序使用动态库函数的原理类似
特别注意:有依赖关系的模块编译
当2个模块存在依赖关系时,如果单独编译,即使加载顺序正确也会加载失败,而且在编译依赖模块时会有警告

此时expsym_module模块已经加载
![]()

问题原因:depsym_module在编译时在内核符号表中找不到add_integer项,且完全不知道expsym_module的存在
其实这点是不太合理的,毕竟depsym_module.ko所需的符号已经被其他模块导出了,详情见下文的补充
解决方案:将depsym_module & expsym_module放在一起编译
验证:注意对Makefile的修改

![]()
补充:分开编译ko加载的bug
当expsym_module.ko和depsym_module.ko分开编译,且expsyn_module.ko先加载的情况下,返回的报错是-22
depsym_module: Unknown symbol add_integer (err -22)其实这是2.6.26之后版本的一个bug,且该bug不会被修复(但是在实际工作的嵌入式项目中使用的4.9.84版本内核没有发现该问题),可参考如下链接:
编译驱动指定额外的Module.symvers文件 - hello.world - 博客园
解决方案:在编译depsym_module.ko时使用KBUILD_EXTRA_SYMBOLS指定expsym_module.ko中Module.symvers的绝对路径
我们先来看下depsym_module.ko目录下Module.symvers文件的内容,
![]()
其实该文件只有一行,就是本模块导出的符号信息
对depsym_module的Makefile做如下修改,
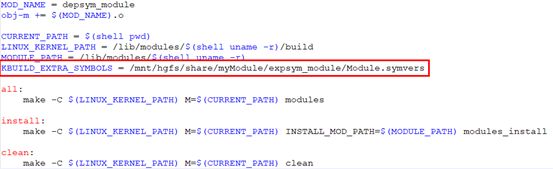
此时单独编译出的depsym_module.ko即可加载了,且编译过程中没有警告信息
6.5 生成模块依赖关系
在上述验证中均是手动处理模块间的依赖关系,但是我们知道使用modprobe命令加载内核模块时,该命令可以自己处理内核依赖项
6.5.1 modprobe原理简析
① modprobe依赖/lib/modules/$(uname -r)目录下的modules.dep.bin文件分析模块的依赖关系(modules.dep文件为描述模块依赖关系的文本文件)

② 而depmod命令可用于更新modules.dep.bin文件

需要注意的是,depmod只会处理/lib/modules/version目录下的模块,所以我们还需要把编译生成的模块拷贝到该目录
③ modules_install目标用于拷贝模块
在内核源码树下运行make help可以获取编译内核相关命令的帮助,其中module_install目标可用于拷贝模块

因此我们对Makefile进行修改,增加install目标

在make & make install之后,expsym_module.ko & depsym_module.ko将被拷贝到指定目录

6.5.2 验证步骤
根据上述分析,要想使用modprobe安装模块需要完成如下步骤,
① 拷贝内核模块
执行sudo make install即可(实际会执行内核Makefile的modules_install目标)
② 更新模块间依赖关系
sudo depmod此时/lib/modules/$(uname -r)目录下的modules.dep & modules.dep.bin文件中将会新增模块的依赖关系
![]()
③ 安装模块
sudo modprobe depsym_module由于依赖关系已经写入modules.dep文件,所以只要指定模块名即可,无需路径(有路径反而不对,因为modprobe真的只是解析模块依赖文件~~)
④ 卸载模块
sudo modprobe -r depsym_module此时depsym_module & expsym_module均会被卸载
7. 内核打印函数printk
7.1 内核环形缓冲区(ring buffer)
printk会将内核信息输出到ring buffer,所以就导致2 个问题:
① 输出的信息控制台不一定可见
② 如果塞入的消息过多,就会将之前的消息冲掉
说明:使用dmesg可以直接打印ring buffer 中的信息
7.2 打印等级
7.2.1 printk函数可用打印等级

驱动程序常用等级为,
KERN_ERR:用来报告硬件错误
KERN_DEBUG:用来打印调试信息
7.2.2 打印等级的作用
/proc/sys/kernel/printk文件记录了系统的默认打印等级

他们分别是:
控制台日志级别:优先级高于该值的消息将被打印到控制台
默认的消息日志级别:将用该优先级打印没有设置优先级的消息
最低的控制台日志级别:控制台日志级别可被设置的最小值(即最高优先级)
默认的控制台日志级别:控制台日志级别的默认值,即第1个参数的默认值
注意:经过验证,在Ubuntu上设置打印等级没有生效,但是开发板上可以生效
参考资料:
/proc/sys/kernel/printk 打印log设置_June_Hou的博客-CSDN博客
7.3 封装使用printk



说明:在编写驱动时使用dev_dbg可以方便地打印出更多与设备相关的信息。
注意:printk 不能打印浮点数
8. 开发板上加载 / 卸载模块
8.1 重新编译模块
关键:修改Makefile,重新指定模块依赖的代码树

重新指定代码树后,之所以能够直接编译出能够在开发板上运行的模块,是因为该代码树的Makefile中指定了ARCH和CROSS_COMPILE
![]()
8.2 将模块拷贝到NFS根文件系统中

8.3 加载模块
8.4 卸载模块
卸载模块时有如下报错:
![]()
原因:rmmod时需要在/lib/modules目录下有对应Linux版本号的目录,而目前的NFS根文件系统中没有
在Ubuntu虚拟机的/lib/modules目录下就有相关版本号目录,

解决方法:在NFS根文件系统中添加该目录

验证:添加该目录后,可以正常卸载模块

9. 其他主题
9.1 应用程序与内核模块比较
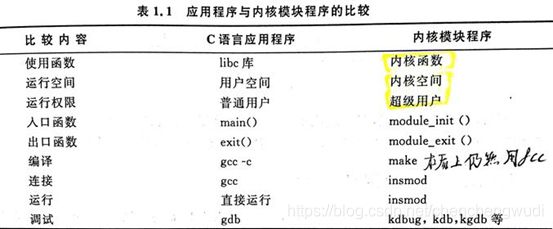
说明1:应用程序大多执行任务;而内核模块只是预先注册自己,以便服务于将来的某个请求,然后其初始化函数结束
说明2:应用程序退出时,可以不进行资源的释放和清理工作(虽然不是个好习惯~~);但模块的退出函数必须撤销初始化函数所做的一切,否则在系统重启之前未释放的资源会残留在系统中
一般模块加载函数 & 卸载函数工作内容如下,
| 模块加载函数 |
模块卸载函数 |
| 注册了XXX |
注销XXX(e.g. 字符设备编号) |
| 动态申请内存 |
释放该内存 |
| 申请硬件资源(e.g. 中断、DMA通道、 I/O端口、I/O内存等) |
释放硬件资源 |
| 开启硬件 |
关闭硬件 |
其中卸载函数释放资源的顺序和加载函数申请资源的顺序相反,这样才能保证资源的安全释放
说明3:应用程序的链接过程能够解析外部引用从而使用适当的函数库;但模块仅仅被链接到内核,因此只能调用内核导出的那些函数,而不存在任何可链接的函数库
实际上内核是运行在libc库之下的,所以还链接个毛线~~
说明4:应用程序中的段错误是无害的,并且可以用调试器追踪源代码;但内核错误即使不影响整个系统,也至少会kill当前进程
说明5:应用程序在虚拟内存中布局,有很大的栈空间;内核栈则很小,且要和整个内核空间的调用链共享(如果需要大的结构,应该动态分配)
9.2 模块声明与描述
MODULE_AUTHOR(author); // 模块作者
MODULE_DESCRIPTION(description); // 模块描述
MODULE_VERSION(version_string); // 模块版本
MODULE_ALIAS(alternate_name); // 模块别名上面4项最终都是调用__MODULE_INFO宏将模块相关信息链接到.modinfo段
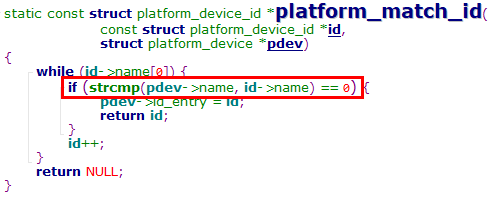
MODULE_DEVICE_TABLE(table_info); // 模块设备表对于USB、PCI等设备驱动,通常会创建一个MODULE_DEVICE_TABLE,以表明该驱动模块所支持的设备

在platform总线的.match函数中会使用.id_table字段进行设备和驱动的匹配

补充:后续引入的设备树机制与上述实现思路一致,只是BSP配置信息不再以源文件形式存在于内核源码中,而是引入了专门的dts文件
9.3 模块的使用计数
Linux 2.6 内核提供了2个管理模块使用计数的接口
// 用于增加模块使用计数;若返回0,表示调用失败,即希望使用的设备没有加载或
// 正在加载中
int try_module_get(struct module *module);// 用于减少模块使用计数
void module_put(struct module *module);说明1:这两个模块使用计数管理接口在实现上考虑了SMP与PREEMPT机制的影响
说明2:模块管理计数一般不需要驱动工程师维护,原因我们说明一下,这涉及到模块使用计数是如何被使用的~~

Linux 2.6内核的不同设备中均包含了struct module *owner字段,用来指向管理此设备的模块。
① 当使用该设备时,内核调用try_module_get(dev->owner) 增加模块使用计数。这样在设备使用过程中,管理该设备的模块就无法被卸载
② 当不再使用该设备时,内核调用module_put(dev->owner) 减少模块使用计数。只有当设备不再被使用时,管理该设备的模块才可以被卸载。
说明:由于驱动开发工程师开发的就是这个owner模块,所以很少自己维护模块使用计数,模块使用计数一般由总线驱动或这类设备共用的核心模块维护
9.4 内核模块编程的安全问题
① 任何从用户进程得到的输入只有经过内核严格验证后才能使用。
② 任何从内核得到的内存都必须在提供给用户进程或设备之前清零或者以其他方式初始化,否则可能发生信息泄露(e.g. 数据和密码等)