CVPR2019 无监督异常检测/定位数据集:MVTec AD
《MVTec AD:A Comprehensive Real-World Dataset for Unsupervised Anomaly Detection》
简介
MVTec AD是MVtec公司提出的一个用于异常检测的数据集,发布于2019CVPR。与之前的异常检测数据集不同,该数据集模仿了工业实际生产场景,并且主要用于unsupervised anomaly detection。数据集为异常区域都提供了像素级标注,是一个全面的、包含多种物体、多种异常的数据集。
训练集中只包含正常样本,测试集中包含正常样本与缺陷样本,因此需要使用无监督方法学习正常样本的特征表示,并用其检测缺陷样本。这是符合现实的做法,因为异常情况不可预知并无法归纳。
数据集包含不同领域中的五种纹理以及十种物体,下图分别展示了这几类图片的正常样本与缺陷样本,以及缺陷样本中的缺陷特写。
论文介绍
2. Related Work
该段主要介绍了异常检测数据集以及用于异常检测的方法
Dataset:主要有两类
① 异常图片分类,也就是说模型只需要输出该图片是否为异常样本。有种构造数据集的方法是在ImageNet上选出一部分类别图像作为训练集,用其他类别的图像作为测试集,但是因异常样本本身就已经属于不同类别,在它上面验证的方法无法评价其好坏。因此《Object-Centric Anomaly Detection by Attribute-Based Reasoning》从Pascal VOC中选取六类物体图片作为正常,然后在网上搜索一批该类别中奇形怪状的样本作为缺陷样本。尽管异常数据更接近训练数据模式,但异常检测还是基于整个图像,而不是发现图像中的异常部分(没有定位异常区域);
② 异常区域分割,不仅需要判断是否异常,还需要找出异常区域。a) NanoTwice: 45张灰度图,5个无缺陷图像进行训练,剩余40张异常图像(包含灰尘或斑点等,只有一种纹理); b) DAGM: 包含10类缺陷(人工生成的灰度纹理,其缺陷以椭圆形式被弱注释),每类包括1000个正常区域用于训练,150个缺陷样本用于测试。
Nano Twice只包含单种缺陷纹理,无法准确验证方法性能;DAGM标注是粗糙的,并且是人工生成的缺陷,无法反映真实世界应用。
Methods:主要有以下四类
① 生成对抗模型,训练时生成器生成假图像,以对抗的方式欺骗鉴别器。对于异常检测,模型在潜在空间中搜索样本(可迷惑鉴别器的样本,满足训练集分布),如果能找到一个合适的匹配即为正常,反之异常。对于异常分割,将重建图像与原始输入逐像素进行比较即可。
代码性文章为:Unsupervised Anomaly Detection with Generative Adversarial Networks to Guide Marker Discovery
② 卷积自编码器,这是无监督异常检测中用的最多的方法。训练时自编码器通过潜在空间(latent space)重构正常样本,在测试时如果测试样本与训练样本分布不同,那么无法重现样本,这样可以检测出样本是否异常。然后通过对比输入样本与重构样本的像素级差异可以发现异常区域。
卷积自编码器CAE有很多变体,比如VAE变分自编码器,但是目前有论文提出从VAE或者其他深度生成模型获得的概率可能无法对训练数据的真实可能性(true likelihood)进行建模。
③ 基于预训练神经网络特征,上面两种方法都是试图从提供的训练数据中学习特征表示,但目前有些方法直接使用某个训练好的CNN(在一个单独的图像分类任务上进行训练)的特征提取器来进行异常检测。
代表工作:Anomaly Detection in Nanofibrous Materials by CNN-Based Self-Similarity
④ 传统方法,针对正常样本设计人工特征提取器。例如,通过高斯混合模型GMM建模特征分布,对于提取出来的特征在GMM获得较低概率的样本将会被认为是缺陷样本。
3. Dataset Description
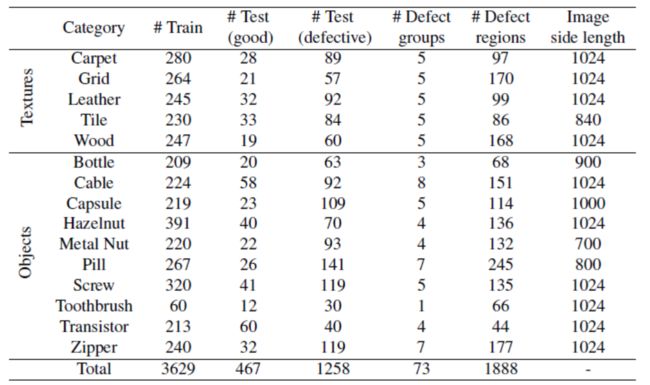
如上表与第一节的图例所示,数据集一共包含15个类别,其中3629张图片用于训练与验证,1725张用于测试,其中训练集只包含正常样本。其中5类为纹理类数据,包含规律的纹路(毛毯、网格)以及随机纹路(皮革、瓷砖、木材);剩下的10类为物体类数据,包含刚性的、特定外观的物体(瓶,金属螺母),可变形物体(电缆)或包括自然变化物体(榛子),并且某部分获取的物体处于大致对齐位置(e.g. 牙刷,胶囊和药丸),其他为随机摆放(e.g. 金属螺母,螺丝和榛子)。测试集中包含73种不同的异常,例如物体表面缺陷(e.g.划痕,凹痕)、结构缺陷(e.g.物体出现部分扭曲)或者由于缺少某些物体组成部件而表现出来的缺陷。
所有图像的尺寸在700x700 ~ 1024x1024之间,其中网格、拉链以及螺丝为灰度单通道图像。数据集为所有的缺陷区域均提供了像素级标注区域,总共包含接近1900个标注区域。
4. Benchmark
选取第2节所介绍的一些SOTA方法在该数据集上进行验证,作为未来方法的Baseline。
具体的模型参数设置与训练细节,可以参照原文,这里不再叙述
进行评估的模型包含AnoGAN、L2/SSIM CAE、CNN feature dictionary、GMM-based Texture Inspection Model以及Variation Model。
数据增广:对于纹理类的图片,对提取出的矩形Patch进行随机裁剪+旋转;对于物体类图片,应用随机平移+旋转。对某些类别图片进行额外的旋转操作,最后每一类包含10000个训练patch。
评价指标:分类任务采用准确率;分割任务采用IoU,以及引入阈值无关的指标:AUC,其中TPR表示被正确识别为异常类像素的百分比,TNR表示被错误识别为异常类像素的百分比。
在评估的模型中,除了GMM可以提供一个阈值,其他模型的阈值都需要设。关于阈值的设定,作者明确定义了一种方法:从训练集中随机抽取一批数据作为验证集,在这上面确定阈值。
具体做法:首先对每一类定义一个最小缺陷区域(minimum defect area),在模型输出的异常图(Anomaly Map)中如果有连通区域大于该区域就会被识别为异常区域。然后在验证集(全为正常样本)上提高阈值,直到异常图中的连通区域刚好都小于定义的缺陷区域(即验证集中没有被误识别的样本),就以该阈值作为测试的阈值。
测试结果:异常分类与分割的测试结果分别为以下两张表所示
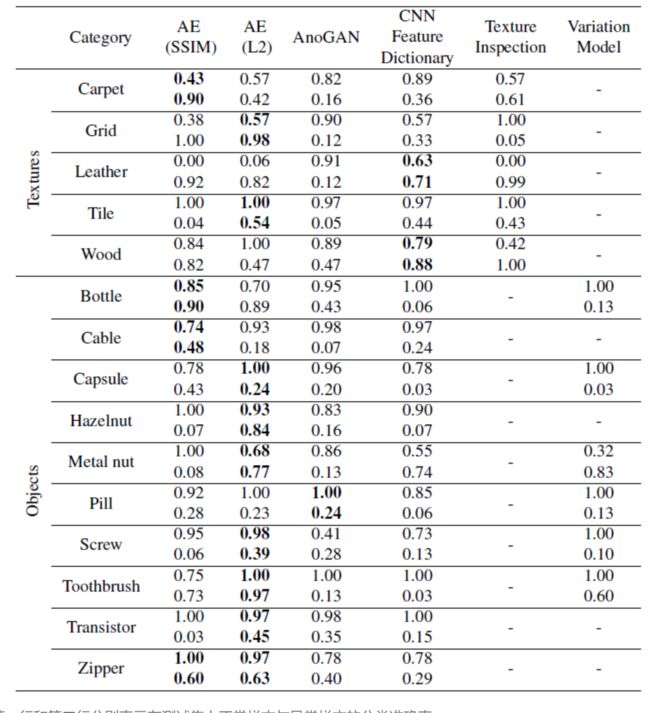
第一行和第二行分别表示在测试集上正常样本与异常样本的分类准确率
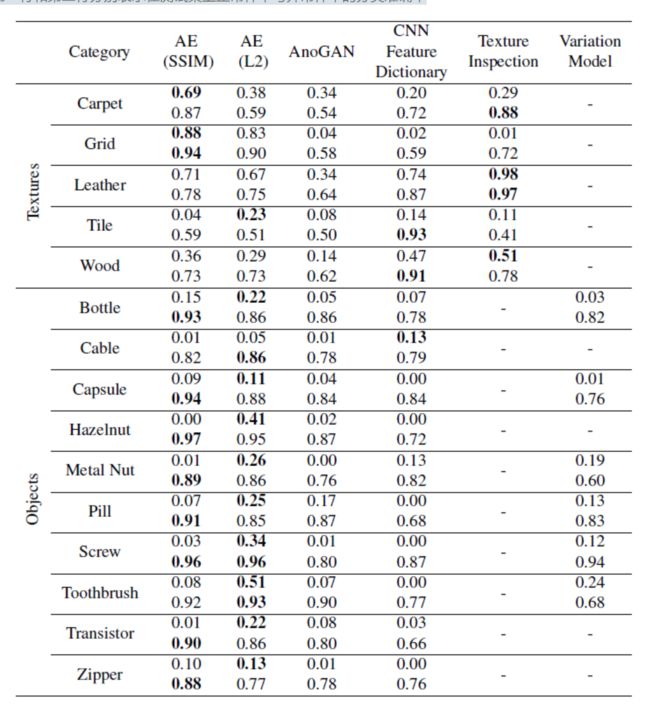
第一行和第二行分别表示在测试集上的IoU以及AUC
从测试集结果来看,所选取的这些代表性方法中没有一个在所有类别上都表现的很好。
具体实验的分析这里也不过多赘述,只提一个结论:AUC与Overlap(IoU)没有重合,这也凸显出在无异常样本上确定阈值是非常困难的,这也就说明无监督异常检测的可发展空间之大。

上图给了一些可视化结果,具体分析课件原文4.4节