19 【RTK Query】
19 【RTK Query】
1.目前前端常见的发起 ajax 请求的方式
- 1、使用原生的
ajax请求 - 2、使用
jquery封装好的ajax请求 - 3、使用
fetch发起请求 - 4、第三方的比如
axios请求 - 5、
angular中自带的HttpClient
就目前前端框架开发中来说我们在开发vue、react的时候一般都是使用fetch或axios自己封装一层来与后端数据交互,至于angular肯定是用自带的HttpClient请求方式,但是依然存在几个致命的弱点,
- 1、对当前请求数据不能缓存,
- 2、一个页面上由多个组件组成,但是刚好有遇到复用相同组件的时候,那么就会发起多次
ajax请求
针对同一个接口发起多次请求的解决方法,目前常见的解决方案
- 1、使用
axios的取消发起请求,参考文档 - 2、
vue中还没看到比较好的方法 - 3、在
rect中可以借用类似react-query工具对请求包装一层 - 4、对于
angular中直接使用rxjs的操作符shareReplay
2.RTK Query 概述
RTK不仅帮助我们解决了state的问题,同时,它还为我们提供了RTK Query用来帮助我们处理数据加载的问题。RTK Query是一个强大的数据获取和缓存工具。在它的帮助下,Web应用中的加载变得十分简单,它使我们不再需要自己编写获取数据和缓存数据的逻辑。
rtk-query是redux-toolkit里面的一个分之,专门用来优化前端接口请求,目前也只支持在react中使用。
RTK Query 是一个强大的数据获取和缓存工具。它旨在简化在 Web 应用程序中加载数据的常见情况,无需自己手动编写数据获取和缓存逻辑。
RTK Query 是一个包含在 Redux Toolkit 包中的可选插件,其功能构建在 Redux Toolkit 中的其他 API 之上。
Web应用中加载数据时需要处理的问题:
- 根据不同的加载状态显示不同UI组件
- 减少对相同数据重复发送请求
- 使用乐观更新,提升用户体验
- 在用户与UI交互时,管理缓存的生命周期
这些问题,RTKQ都可以帮助我们处理。首先,可以直接通过RTKQ向服务器发送请求加载数据,并且RTKQ会自动对数据进行缓存,避免重复发送不必要的请求。其次,RTKQ在发送请求时会根据请求不同的状态返回不同的值,我们可以通过这些值来监视请求发送的过程并随时中止。
我们将 createAsyncThunk 与 createSlice 一起使用,在发出请求和管理加载状态方面仍然需要进行大量手动工作。我们必须创建异步 thunk,发出实际请求,从响应中提取相关字段,添加加载状态字段,在 extraReducers 中添加处理程序以处理 pending/fulfilled/rejected 情况,并实际编写正确的状态更新。
在过去的几年里,React 社区已经意识到 “数据获取和缓存” 实际上是一组不同于 “状态管理” 的关注点。虽然你可以使用 Redux 之类的状态管理库来缓存数据,但用例差异较大,因此值得使用专门为数据获取用例构建的工具。
RTK Query 在其 API 设计中添加了独特的方法:
- 数据获取和缓存逻辑构建在 Redux Toolkit 的
createSlice和createAsyncThunkAPI 之上 - 由于 Redux Toolkit 与 UI 无关,因此 RTK Query 的功能可以与任何 UI 层一起使用
- API 请求接口是提前定义的,包括如何从参数生成查询参数和转换响应以进行缓存
- RTK Query 还可以生成封装整个数据获取过程的 React hooks ,为组件提供
data和isFetching字段,并在组件挂载和卸载时管理缓存数据的生命周期 - RTK Query 提供“缓存数据项生命周期函数”选项,支持在获取初始数据后通过 websocket 消息流式传输缓存更新等用例
- 我们有从 OpenAPI 和 GraphQL 模式生成 API slice 代码的早期工作示例
- 最后,RTK Query 完全用 TypeScript 编写,旨在提供出色的 TS 使用体验
rtk-query的使用环境,必须是react版本大于 17,可以使用hooks的版本,因为使用rtk-query的查询都是hooks的方式,如果你项目简单redux都未使用到,本人不建议你用rtk-query,可能直接使用axios请求更加的简单方便。
3.基础开发流程
后面这些案例后端接口返回格式都是
{ "code":200, "data":[] }
- 创建一个store文件夹
- 创建一个index.ts做为主入口
- 创建一个festures/api文件夹用来装所有的API Slice
- 创建一个sudentApiSlice.js文件,并导出简单的加减方法
3.1 定义 API Slice
使用 RTK Query,管理缓存数据的逻辑被集中到每个应用程序的单个“API Slice”中。就像每个应用程序只有一个 Redux 存储一样,我们现在有一个Slice 用于 所有 我们的缓存数据。
我们将从定义一个新的 sudentApiSlice.js 文件开始。由于这不是特定于我们已经编写的任何其他“功能”,我们将添加一个新的 features/api/ 文件夹并将 sudentApiSlice.js 放在那里。让我们填写 API Slice 文件,然后分解里面的代码,看看它在做什么:
features/api/sudentApiSlice.js
// 从特定于 React 的入口点导入 RTK Query 方法
import { createApi, fetchBaseQuery } from '@reduxjs/toolkit/dist/query/react'
// 上面这个引入的会自动创建钩子
// import { createApi } from '@reduxjs/toolkit/query'
// 定义我们的单个 API Slice 对象
//createApi() 用来创建RTKQ中的API对象
// RTKQ的所有功能都需要通过该对象来进行
// createApi() 需要一个对象作为参数
export const sudentApiSlice = createApi({
reducerPath: 'studentApi', // Api的标识,不能和其他的Api或reducer重复
// 指定查询的基础信息,发送请求使用的工具
baseQuery: fetchBaseQuery({
// 我们所有的请求都有以 “/api 开头的 URL
baseUrl: 'http://localhost:8080/api',
}),
// “endpoints” 代表对该服务器的操作和请求
endpoints: builder => ({
// `getStudents` endpoint 是一个返回数据的 “Query” 操作
getStudents: builder.query({
// 请求的 URL 是“/api/all/student”
query: () => '/all/student',
}),
}),
})
// Api对象创建后,对象中会根据各种方法自动的生成对应的钩子函数
// 通过这些钩子函数,可以来向服务器发送请求
// 钩子函数的命名规则 getStudents --> useGetStudentsQuery
export const { useGetStudentsQuery } = sudentApiSlice
上例是一个比较简单的Api对象的例子,我们来分析一下,首先我们需要调用createApi()来创建Api对象。这个方法在RTK中存在两个版本,一个位于@reduxjs/toolkit/dist/query下,一个位于@reduxjs/toolkit/dist/query/react下。react目录下的版本会自动生成一个钩子,方便我们使用Api。如果不要钩子,可以引入query下的版本,当然我不建议你这么做。
createApi()需要一个配置对象作为参数,配置对象中的属性繁多,我们暂时介绍案例中用到的属性:
reducerPath
用来设置reducer的唯一标识,主要用来在创建store时指定action的type属性,如果不指定默认为api。
baseQuery
用来设置发送请求的工具,就是你是用什么发请求,RTKQ为我们提供了fetchBaseQuery作为查询工具,它对fetch进行了简单的封装,很方便,如果你不喜欢可以改用其他工具,这里暂时不做讨论。
fetchBaseQuery
简单封装过的fetch调用后会返回一个封装后的工具函数。需要一个配置对象作为参数,baseUrl表示Api请求的基本路径,指定后请求将会以该路径为基本路径。配置对象中其他属性暂不讨论。
endpoints
Api对象封装了一类功能,比如学生的增删改查,我们会统一封装到一个对象中。一类功能中的每一个具体功能我们可以称它是一个端点。endpoints用来对请求中的端点进行配置。
endpoints是一个回调函数,可以用普通方法的形式指定,也可以用箭头函数。回调函数中会收到一个build对象,使用build对象对点进行映射。回调函数的返回值是一个对象,Api对象中的所有端点都要在该对象中进行配置。
对象中属性名就是要实现的功能名,比如获取所有学生可以命名为getStudents,根据id获取学生可以命名为getStudentById。属性值要通过build对象创建,分两种情况:
查询:build.query({})
增删改:build.mutation({})
例如:
getStudents: builder.query({
// 请求的 URL 是“/api/all/student”
query: () => '/all/student',
}),
先说query,query也需要一个配置对象作为参数。配置对象里同样有n多个属性,现在直说一个,query方法。注意不要搞混两个query,一个是build的query方法,一个是query方法配置对象中的属性,这个方法需要返回一个子路径,这个子路径将会和baseUrl拼接为一个完整的请求路径。比如:getStudets的最终请求地址是:
http://localhost:8080/api + /all/student = http://localhost:8080/api/all/student
可算是介绍完了,但是注意了这个只是最基本的配置。RTKQ功能非常强大,但是配置也比较麻烦。不过,熟了就好了。
上例中,我们创建一个Api对象studentApi,并且在对象中定义了一个getStudents方法用来查询所有的学生信息。如果我们使用react下的createApi,则其创建的Api对象中会自动生成钩子函数,钩子函数名字为useXxxQuery或useXxxMutation,中间的Xxx就是方法名,查询方法的后缀为Query,修改方法的后缀为Mutation。所以上例中,Api对象中会自动生成一个名为useGetStudentsQuery的钩子,我们可以获取并将钩子向外部暴露。
export const {useGetStudentsQuery} = studentApi;
3.2 配置 Store
我们现在需要将 API Slice 连接到我们的 Redux 存储。我们可以修改现有的 store.js 文件,将 API slice 的 cache reducer 添加到状态中。此外,API slice 会生成需要添加到 store 的自定义 middleware。这个 middleware 必须 被添加——它管理缓存的生命周期和控制是否过期。
store/index.js
import { configureStore } from '@reduxjs/toolkit'
import { sudentApiSlice } from './features/api/sudentApiSlice'
// configureStore创建一个redux数据
const store = configureStore({
// 合并多个Slice
reducer: {
[sudentApiSlice.reducerPath]: sudentApiSlice.reducer,
},
middleware: getDefaultMiddleware => getDefaultMiddleware().concat(sudentApiSlice.middleware),
})
export default store
我们可以在 reducer 参数中重用 sudentApiSlice.reducerPath 字段作为计算键,以确保在正确的位置添加缓存 reducer。
我们需要在 store 设置中保留所有现有的标准 middleware,例如“redux-thunk”,而 API slice 的 middleware 通常会在这些 middleware 之后使用。我们可以通过向 configureStore 提供 middleware 参数,调用提供的 getDefaultMiddleware() 方法,并在返回的 middleware 数组的末尾添加 sudentApiSlice.middleware 来做到这一点。
store创建完毕同样要设置Provider标签,这里不再展示。
3.3 在组件中使用 Query Hooks
接下来,我们来看看如果通过studentApi发送请求。由于我们已经将studentApi中的钩子函数向外部导出了,所以我们只需通过钩子函数即可自动加载到所有的学生信息。比如,现在在App.js中加载信息可以这样编写代码:
import React from 'react'
import { useGetStudentsQuery } from './store/features/api/sudentApiSlice'
export default function App() {
const { data:studentsRes, isLoading, isSuccess, isError, error } = useGetStudentsQuery()
let content
if (isLoading) {
content = '正在加载中'
} else if (isSuccess) {
content = studentsRes.data.map(stu => (
{stu.name} ---
{stu.age} ---
{stu.sex}
))
} else if (isError) {
content = error.toString()
}
return {content}
}
我们能够用对 useGetStudentsQuery() 的单个调用来替换多个 useSelector 调用和 useEffect 调度。
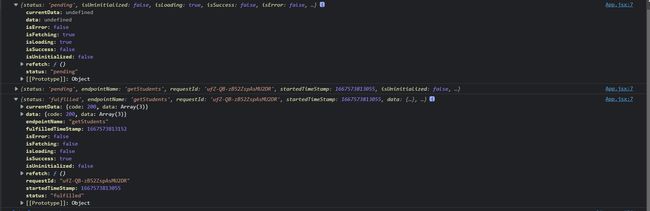
直接调用useGetStudentsQuery()它会自动向服务器发送请求加载数据,每个生成的 Query hooks 都会返回一个包含多个字段的“结果”对象,包括:
data– 来自服务器的实际响应内容。 在收到响应之前,该字段将是 “undefined”。currentData– 当前的数据isUninitialized– 如果为true则表示查询还没开始data:来自服务器的实际响应内容。 在收到响应之前,该字段将是 “undefined”。isLoading: 一个 boolean,指示此 hooks 当前是否正在向服务器发出 第一次 请求。(请注意,如果参数更改以请求不同的数据,isLoading将保持为 false。)isFetching: 一个 boolean,指示 hooks 当前是否正在向服务器发出 any 请求isSuccess: 一个 boolean,指示 hooks 是否已成功请求并有可用的缓存数据(即,现在应该定义 data)isError: 一个 boolean,指示最后一个请求是否有错误error: 一个 serialized 错误对象refetch函数,用来重新加载数据
从结果对象中解构字段是很常见的,并且可能将 data 重命名为更具体的变量,例如 studentRes 来描述它包含的内容。然后我们可以使用状态 boolean 和 data/error 字段来呈现我们想要的 UI。 但是,如果你使用的是 TypeScript,你可能需要保持原始对象不变,并在条件检查中将标志引用为 result.isSuccess,以便 TS 可以正确推断 data 是有效的。
这是最终效果:
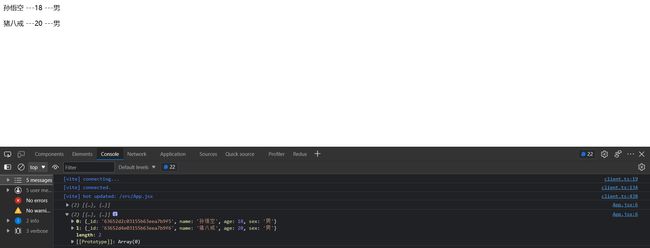
4.传递参数
4.1 定义接收参数
features/api/sudentApiSlice.js
这里定义了一个新的接口,通过id获取学生信息
// 从特定于 React 的入口点导入 RTK Query 方法
import { createApi, fetchBaseQuery } from '@reduxjs/toolkit/dist/query/react'
export const sudentApiSlice = createApi({
reducerPath: 'studentApi',
baseQuery: fetchBaseQuery({
baseUrl: '/api',
}),
endpoints: builder => ({
getStudentById: builder.query({
// 从query方法这里接收参数
query: sutId => `/student/${sutId}`,
}),
}),
})
export const { useGetStudentsQuery, useGetStudentByIdQuery } = sudentApiSlice
4.2 传递参数
App.jsx
import React from 'react'
import { useGetStudentByIdQuery } from './store/features/api/sudentApiSlice'
export default function App() {
let stuId = '63652d2c03155b63eea7b9f5'
const {
data: studentRes,
isLoading,
isSuccess,
isError,
error,
} = useGetStudentByIdQuery(stuId)
let content
if (isLoading) {
content = '正在加载中'
} else if (isSuccess) {
content = (
{studentRes.data.name} ---{studentRes.data.age} ---{studentRes.data.sex}
)
} else if (isError) {
content = error.toString()
}
return {content}
}
useGetPostQuery这个钩子接收的第一个参数传递到query方法,使用起来很简单

5.转换响应
请求接口可以定义一个 transformResponse 处理程序,该处理程序可以在缓存之前提取或修改从服务器接收到的数据。我们可以有 transformResponse: (responseData) => responseData.data,它只会缓存实际的 student 对象,而不是整个响应体。
features/api/sudentApiSlice.js
getStudentById: builder.query({
query: sutId => `/student/${sutId}`,
transformResponse:(responseData, meta, arg)=>{
console.log(responseData);
return responseData.data
}
}),
对于上一个案例中通过id获取学生信息的接口,加一个transformResponse方法,我们来看看他接受到的参数responseData是什么
![]()
可以看到responseData这个参数就是我们的响应体
在使用的过程中,发现这个方法类似于响应拦截器。
我们在App.jsx中看看useGetStudentByIdQuery这个钩子函数返回的data有什么变化
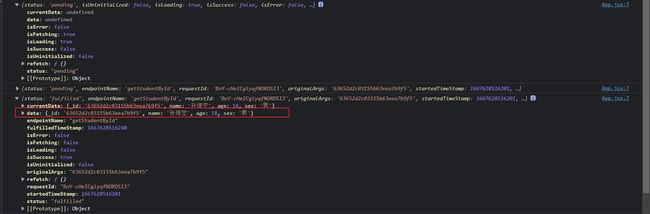
6.RTK Query 缓存简单介绍
后面在介绍缓存的灵活使用
6.1 什么是相同查询
RTK Query 会将查询查询参数序列化为字符串,并将相同钩子、相同参数的查询视为相同的查询,他们将共享一个请求与缓存数据。
因此,下面两个调用返回结果相同(即使在不同的组件中):
useGetXXXQuery({ a: 1, b: 2 }) // 订阅 + 1
useGetXXXQuery({ b: 2, a: 1 }) // 订阅 + 1
// ...
这是因为:
- 他们使用相同的查询:GetXXX
- 查询参数的序列化结果相同:
'{"a":1,"b":2}'
你不需要担心嵌套或是字段顺序,或是不同对象不同引用会被认为是不同的查询,因为 RTK Query 已经在默认的序列化函数中处理了相关用例。同时,你也可以提供自己的序列化函数。
6.2 引用计数与垃圾回收
当在组件中使用某个查询时,该查询的引用计数会 + 1,当该组件被卸载时,引用计数会 -1。当一个查询的引用计数为 0 时,说明没有任何组件在使用这个查询。此时,经过 keepUnusedDataFor(默认为 30 )秒后,如果缓存仍为被使用过,那么他将被从缓存中移除。
6.3 缓存初体验
缓存的配置
store/index.js
// configureStore创建一个redux数据
const store = configureStore({
// 合并多个Slice
reducer: {
[sudentApiSlice.reducerPath]: sudentApiSlice.reducer,
},
middleware: getDefaultMiddleware => getDefaultMiddleware().concat(sudentApiSlice.middleware),
})
export default store
其实就是在这个store配置这个中间件,一开始就配好了。
来看看实际效果
先改写下上面的案例
App.jsx
import React, { useState } from 'react'
import StudentA from './StudentA'
import StudentB from './StudentB'
export default function App() {
const [tab, setTab] = useState(0)
let content
switch (tab) {
case 0:
content = '首页'
break
case 1:
content =
{content}
)
}
StudentA.jsx
import React from 'react'
import { useEffect } from 'react'
import { useGetStudentByIdQuery } from './store/features/api/sudentApiSlice'
export default function Student() {
let stuId = '63652d2c03155b63eea7b9f5'
const { data: studentRes, isLoading, isSuccess, isError, error } = useGetStudentByIdQuery(stuId)
let content
if (isLoading) {
content = '正在加载中'
} else if (isSuccess) {
content = (
{studentRes.data.name} ---{studentRes.data.age} ---{studentRes.data.sex}
)
} else if (isError) {
content = error.toString()
}
useEffect(() => {
console.log('渲染了')
}, [])
return (
<>
组件StudentA
{content}
)
}
StudentB.jsx
import React from 'react'
import { useEffect } from 'react'
import { useGetStudentByIdQuery } from './store/features/api/sudentApiSlice'
export default function Student() {
let stuId = '63652d2c03155b63eea7b9f5'
const { data: studentRes, isLoading, isSuccess, isError, error } = useGetStudentByIdQuery(stuId)
let content
if (isLoading) {
content = '正在加载中'
} else if (isSuccess) {
content = (
{studentRes.data.name} ---{studentRes.data.age} ---{studentRes.data.sex}
)
} else if (isError) {
content = error.toString()
}
useEffect(() => {
console.log('渲染了')
}, [])
return (
<>
组件StudentB
{content}
)
}
我们把学生信息抽离成两个组件,里面除了标题都是一样的,在App.jsx中设置了个三个按钮控制显示隐藏
切换到StudentA组件

切换到StudentB组件
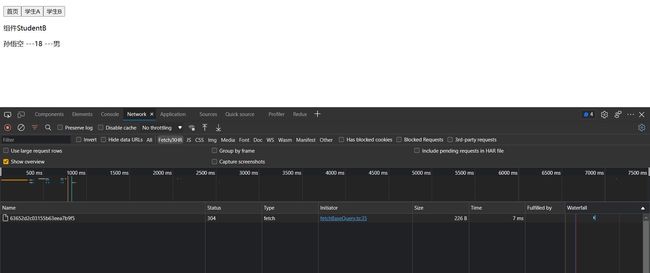
可以看到切换到StudentB组件并没有重新发起请求,这就是缓存生效了。
RTK Query 允许多个组件订阅相同的数据,并且将确保每个唯一的数据集只获取一次。 在内部,RTK Query 为每个请求接口 + 缓存键组合保留一个 action 订阅的引用计数器。如果组件 A 调用 useGetStudentByIdQuery(stuId),则将获取该数据。如果组件 B 挂载并调用 useGetStudentByIdQuery(stuId),则请求的数据完全相同。两种钩子用法将返回完全相同的结果,包括获取的 “data” 和加载状态标志。
当活跃订阅数下降到 0 时,RTK Query 会启动一个内部计时器。 如果在添加任何新的数据订阅之前计时器到期,RTK Query 将自动从缓存中删除该数据,因为应用程序不再需要该数据。但是,如果在计时器到期之前添加了新订阅,则取消计时器,并使用已缓存的数据而无需重新获取它。
在这种情况下,我们的 student 数据。因此,RTK Query 取消了计时器并继续使用相同的缓存数据,而不是从服务器获取数据。
默认情况下,未使用的数据会在 60 秒后从缓存中删除,但这可以在根 API Slice 定义中进行配置,也可以使用 keepUnusedDataFor 标志在各个请求接口定义中覆盖,该标志指定缓存生存期 秒。
features/api/sudentApiSlice.js
getStudentById: builder.query({
// 从query方法这里接收参数
query: sutId => `/student/${sutId}`,
keepUnusedDataFor: 60, // 设置数据缓存的时间,单位秒 默认60s
}),
7.mutation 请求接口
我们已经看到了如何通过定义查询请求接口从服务器获取数据,但是向服务器发送更新呢?
RTK Query 让我们定义 mutation 请求接口 来更新服务器上的数据。让我们添加一个可以让我们添加新学生的 Mutation。
7.1 添加新的 Mutations 后请求接口
添加 Mutation 请求接口与添加查询请求接口非常相似。 最大的不同是我们使用 builder.mutation() 而不是 builder.query() 来定义请求接口。 此外,我们现在需要将 HTTP 方法更改为“POST”请求,并且我们还必须提供请求的正文。
features/api/sudentApiSlice.js
import { createApi, fetchBaseQuery } from '@reduxjs/toolkit/dist/query/react'
export const sudentApiSlice = createApi({
reducerPath: 'studentApi',
baseQuery: fetchBaseQuery({
baseUrl: '/api',
}),
endpoints: builder => ({
getStudents: builder.query({
query: () => '/all/student',
}),
getStudentById: builder.query({
query: sutId => `/student/${sutId}`
}),
addNewStudent: builder.mutation({
query: student => ({
url: '/student',
method: 'POST',
// 将整个post对象作为请求的主体
body: student,
}),
}),
}),
})
export const { useGetStudentsQuery, useGetStudentByIdQuery, useAddNewStudentMutation } =
sudentApiSlice
这里我们的 query 选项返回一个包含 {url, method, body} 的对象。 由于我们使用 fetchBaseQuery 来发出请求,body 字段将自动为我们进行 JSON 序列化。
与查询请求接口一样,API slice 会自动为 Mutation 请求接口生成一个 React hooks - 在本例中为 useAddNewPostMutation。
7.2 在组件中使用 Mutation Hooks
每当我们单击“添加”按钮时,我们以前得调度了一个异步 thunk 来添加。 为此,它必须导入 useDispatch 和 addNewPost thunk。 Mutation hooks 取代了这两者,并且使用模式非常相似。
import React, { useState } from 'react'
import { useAddNewStudentMutation } from './store/features/api/sudentApiSlice'
export default function Home() {
const [name, setName] = useState('')
const [age, setAge] = useState(0)
const [sex, setSex] = useState('')
// 获取添加的钩子,useMutation的钩子返回的是一个数组
// 数组中有两个东西,第一个是操作的触发器,第二个是结果集
const [addNewStudent, { isLoading }] = useAddNewStudentMutation()
const canSubmit = [name, age, sex].every(() => true) && !isLoading
const onAddStuClicked = async () => {
if (!canSubmit) return
try {
await addNewStudent({ name, age, sex }).unwrap()
setName('')
setAge(0)
setSex('')
} catch (err) {
console.error('Failed to add student: ', err)
}
}
return (
首页
)
}
Mutation hooks 返回一个包含两个值的数组:
- 第一个值是触发函数。当被调用时,它会使用你提供的任何参数向服务器发出请求。这实际上就像一个已经被包装以立即调度自身的 thunk。
- 第二个值是一个对象,其中包含有关当前正在进行的请求(如果有)的元数据。这包括一个
isLoading标志以指示请求是否正在进行中。
我们可以用 useAddNewStudentMutation hooks 中的触发函数和 isLoading 标志替换现有的 thunk 调度和组件加载状态,组件的其余部分保持不变。
与 thunk 调度一样,我们使用初始 post 对象调用 addNewStudent。 这会返回一个带有.unwrap()方法的特殊 Promise ,我们可以 await addNewStudent().unwrap() 使用标准的 try/catch 块来处理任何潜在的错误。

8.useQuery Hook 参数
查询钩子需要两个参数:(queryArg?, queryOptions?)
参数将被传递到底层回调以生成URL。queryArg query
该对象接受几个可用于控制数据获取行为的附加参数:queryOptions
- skip - 允许查询“跳过”为该渲染运行。默认为
false - pollingInterval - 允许查询按提供的时间间隔(以毫秒为单位指定)自动重新获取。默认为*(关闭)*
0 - selectFromResult - 允许更改钩子的返回值以获取结果的子集,针对返回的子集进行渲染优化。
- refetchOnMountOrArgChange - 允许强制查询始终在挂载时重新取回迁(何时提供)。允许在自上次查询同一缓存(当设置为
true)以来已经过去了足够的时间(以秒为单位)时强制查询重新获取。默认为truenumberfalse - refetchOnFocus - 允许在浏览器窗口重新获得焦点时强制查询重新获取。默认为
false - refetchOnReconnect - 允许在重新获得网络连接时强制查询重新获取。默认为
false
8.1 条件提取
默认为false。一旦挂载组件,查询钩子就会自动开始获取数据。但是,在某些用例中,您可能希望延迟获取数据,直到某些条件变为真。RTK 查询支持条件提取以启用该行为。
如果要阻止查询自动运行,可以在钩子中使用参数skip
跳过示例
const Pokemon = ({ name, skip }) => {
const { data, error, status } = useGetPokemonByNameQuery(name, {
skip,
});
return (
{name} - {status}
);
};
- 如果查询缓存了数据:
- 缓存的数据将不会在初始加载时使用,并且将忽略来自任何相同查询的更新,直到删除条件
skip - 查询的状态为
uninitialized - 初始加载后设置的 ifis,将使用缓存结果
skip: false
- 缓存的数据将不会在初始加载时使用,并且将忽略来自任何相同查询的更新,直到删除条件
- 如果查询没有缓存数据:
- 查询的状态为
uninitialized - 使用开发工具查看查询时,查询将不存在于该状态
- 查询不会在装载时自动获取
- 当添加具有相同查询的其他组件时,查询不会自动运行
- 查询的状态为
这里我想演示的例子是如果我们给钩子函数传递的参数是一个undefined,这个时候发起请求是会报错的,我们可以使用skip来来跳过这次无法进行的请求。
import React from 'react'
import {useGetStudentByIdQuery} from "./store/features/api/sudentApiSlice"
const StudentForm = (props) => {
// 调用钩子来加载数据
const {data:stuData, isSuccess, isFetching} = useGetStudentByIdQuery(props.stuId, {
skip:!props.stuId
})
...
}
export default StudentForm;
这里如果父组件传过来的stuId是个undefined,那么这次就不会发起请求了。
8.2 轮询
默认值为0。轮询使您能够通过使查询按指定的时间间隔运行来产生“实时”效果。若要为查询启用轮询,请以毫秒为单位的间隔将值传递给钩子
import React from 'react'
import { useGetPokemonByNameQuery } from './services/pokemon'
export const Pokemon = ({ name }: { name: string }) => {
// 每过3s会自动调用一次这个钩子函数
const { data, status, error, refetch } = useGetPokemonByNameQuery(name, {
pollingInterval: 3000,
})
return {data}
}
8.3 从查询结果中选择数据
selectFromResult允许您以高性能方式从查询结果中获取特定段。使用此功能时,除非所选项的基础数据已更改,否则组件不会重新呈现。如果所选项是较大集合中的一个元素,它将忽略对同一集合中元素的更改。
AllStudent.jsx
import React from 'react'
import { useGetStudentsQuery } from './store/features/api/sudentApiSlice'
export default function App() {
const {
data: studentsRes,
isLoading,
isSuccess,
isError,
error,
} = useGetStudentsQuery(null, {
selectFromResult: result => {
console.log(result)
return result
},
})
let content
if (isLoading) {
content = '正在加载中'
} else if (isSuccess) {
content = studentsRes.data.map(stu => (
{stu.name} ---
{stu.age} ---
{stu.sex}
))
} else if (isError) {
content = error.toString()
}
return {content}
}
先看这个selectFromResult方法的参数是什么
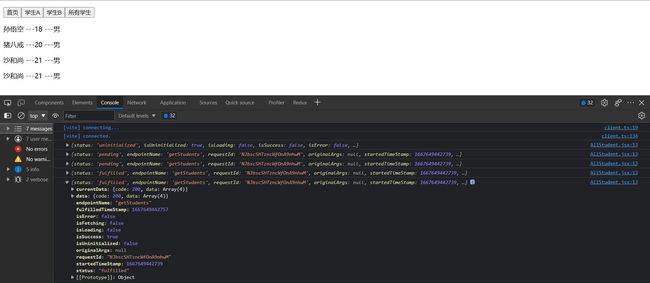
这里我们可以对学生数据进行过滤
selectFromResult: result => {
let res = result.data
if (res) {
result.data = {
...res,
data: res.data.filter(stu => stu.age > 20),
}
}
return result
},

8.4 refetchOnMountOrArgChange
默认为false。此设置允许您控制缓存结果是否已经可用 RTK 查询将仅提供缓存的结果,或者是否应该设置为 或 自上次成功查询结果以来已经过去了足够的时间。
false- 除非查询尚不存在*,否则*不会导致执行查询。true- 在添加查询的新订阅者时,将始终重新获取。行为与调用回调或传入操作创建者相同。number- 值以秒为单位。如果提供了一个数字,并且缓存中存在现有查询,它将比较当前时间与上次实现的时间戳,并且仅在经过足够时间时才重新获取。
如果同时指定此选项skip: true,则在 false 之前不会对其进行计算。
const {
data: studentsRes,
isLoading,
isSuccess,
isError,
error,
} = useGetStudentsQuery(null, {
refetchOnMountOrArgChange:false
})
注意
fetchBaseQuery |Redux Toolkit (redux-toolkit.js.org)
您可以在
createApi中全局设置此项refetchOnMountOrArgChange,但您也可以覆盖默认值,并通过传递给每个单独的钩子调用或类似地通过 passingwhen 调度启动操作来获得更精细的控制。createApi
8.5 refetchOnFocus
默认值为false。此设置允许您控制 RTK 查询是否在应用程序窗口重新获得焦点后尝试重新获取所有订阅的查询。
如果同时指定此选项skip: true,则在 false 之前不会对其进行计算。
注意:要求已调用安装程序侦听器。
注意
fetchBaseQuery |Redux Toolkit (redux-toolkit.js.org)
您可以在
createApi中全局设置中此项refetchOnFocus,但也可以覆盖默认值,并通过传递给每个单独的钩子调用或在调度启动操作时进行更精细的控制。如果您指定手动分派查询的时间,RTK 查询将无法自动为您重新获取。
想使用还得为store添加一个配置才行
store/index.js
import { configureStore } from '@reduxjs/toolkit'
import { setupListeners } from '@reduxjs/toolkit/query'
// configureStore创建一个redux数据
const store = configureStore({
...
})
// 设置以后,将会支持 refetchOnFocus refetchOnReconnect
setupListeners(store.dispatch)
export default store
然后我们看下效果
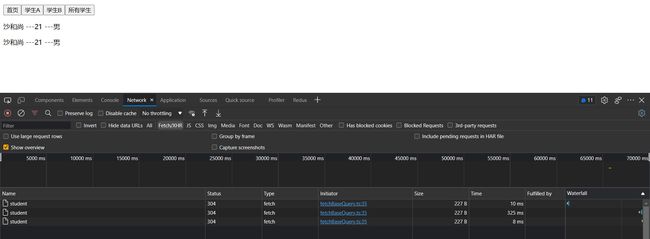
从devtool回来点一下网页会重新发一次请求,然后从别的网站点回来也会重新发起请求。
8.6 refetchOnReconnect
默认值为false,此设置允许您控制 RTK 查询在重新获得网络连接后是否尝试重新获取所有订阅的查询。
如果同时指定此选项skip: true,则在 false 之前不会对其进行计算。
注意:要求已调用安装程序侦听器。
注意
您可以在
createApi中全局设置此项refetchOnReconnect,但也可以覆盖默认值,并通过传递给每个单独的钩子调用或在调度启动操作时进行更精细的控制。如果您指定手动分派查询的时间,RTK 查询将无法自动为您重新获取。
track: false
9.刷新缓存数据
当我们点击添加学生时,我们可以在浏览器 DevTools 中查看 Network 选项卡,确认 HTTP POST 请求成功。 但是,如果我们回到所有学生组件,新的学生信息并不会被展示出来。我们在内存中仍然有相同的缓存数据。
我们需要告诉 RTK Query 刷新其缓存的学生列表,以便我们可以看到我们刚刚添加的新学生信息。
9.1 手动刷新
第一个选项是手动强制 RTK Query 重新获取给定请求接口的数据。Query hooks 结果对象包含一个 “refetch” 函数,我们可以调用它来强制重新获取。 我们可以暂时将“重新获取学生列表”按钮添加到
AllStudent.jsx
import React from 'react'
import { useGetStudentsQuery } from './store/features/api/sudentApiSlice'
export default function App() {
const {
data: studentsRes,
isLoading,
isSuccess,
isError,
error,
refetch,
} = useGetStudentsQuery()
let content
if (isLoading) {
content = '正在加载中'
} else if (isSuccess) {
content = studentsRes.data.map(stu => (
{stu.name} ---
{stu.age} ---
{stu.sex}
))
} else if (isError) {
content = error.toString()
}
return (
{content}
)
}
首先先从首页添加一个学生数据,然后回到所有学生组件
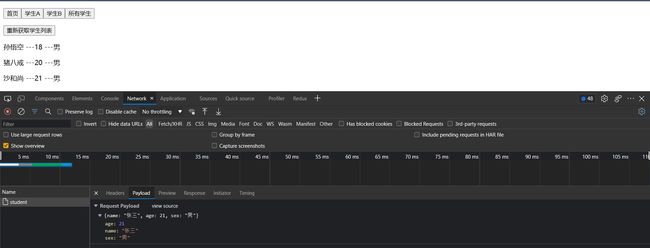
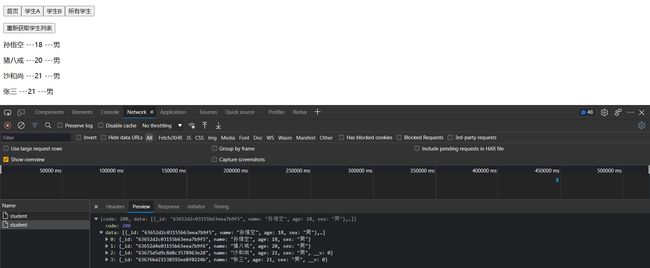
这个时候由于有缓存,用的还是之前的数据,我们使用reFetch方法来强制刷新数据
9.2 缓存失效自动刷新-数据标签
有时需要让用户手动单击以重新获取数据,但对于正常使用而言绝对不是一个好的解决方案。
我们知道我们的服务器拥有所有帖子的完整列表,包括我们刚刚添加的帖子。 理想情况下,我们希望我们的应用程序在 Mutation 请求完成后自动重新获取更新的帖子列表。 这样我们就知道我们的客户端缓存数据与服务器所拥有的数据是同步的。
RTK Query 让我们定义查询和 mutations 之间的关系,以启用自动数据重新获取,使用标签。标签是一个字符串或小对象,可让你命名某些类型的数据和缓存的 无效 部分。当缓存标签失效时,RTK Query 将自动重新获取标记有该标签的请求接口。
基本标签使用需要向我们的 API slice 添加三条信息:
- API slice 对象中的根
tagTypes字段,声明数据类型的字符串标签名称数组,例如'student' - 查询请求接口中的 “providesTags” 数组,列出了一组描述该查询中数据的标签
- Mutation 请求接口中的“invalidatesTags”数组,列出了每次 Mutation 运行时失效的一组标签
我们可以在 API slice 中添加一个名为 'student' 的标签,让我们在添加新帖子时自动重新获取 getStudents 请求接口:
features/api/sudentApiSlice.js
import { createApi, fetchBaseQuery } from '@reduxjs/toolkit/dist/query/react'
export const sudentApiSlice = createApi({
reducerPath: 'studentApi',
baseQuery: fetchBaseQuery({
baseUrl: '/api',
}),
tagTypes: ['student'],
endpoints: builder => ({
getStudents: builder.query({
query: () => '/all/student',
providesTags: [{ type: 'student', id: 'LIST' }],
}),
addNewStudent: builder.mutation({
query: student => ({
url: '/student',
method: 'POST',
// 将整个post对象作为请求的主体
body: student,
}),
invalidatesTags: [{ type: 'student', id: 'LIST' }],
}),
}),
})
export const { useGetStudentsQuery,useAddNewStudentMutation } = sudentApiSlice
这就是我们所需要的! 现在,如果我们单击添加学生,然后回到AllStudent组件重新发起请求,渲染新的数据
请注意,这里的文字字符串 'student' 没有什么特别之处。 我们可以称它为“Fred”、“qwerty”或其他任何名称。 它只需要在每个字段中使用相同的字符串,以便 RTK Query 知道“当发生这种 Mutation 时,使列出相同标签字符串的所有请求接口无效”。
10.小总结
- RTK Query 是 Redux Toolkit 中包含的数据获取和缓存解决方案
- RTK Query 为你抽象了管理缓存服务器数据的过程,无需编写加载状态、存储结果和发出请求的逻辑
- RTK Query 建立在 Redux 中使用的相同模式之上,例如异步 thunk
- RTK Query 对每个应用程序使用单个 “API slice”,使用
createApi定义- RTK Query 提供与 UI 无关和特定于 React 的
createApi版本 - API slice 为不同的服务器操作定义了多个“请求接口”
- 如果使用 React 集成,API slice 包括自动生成的 React hooks
- RTK Query 提供与 UI 无关和特定于 React 的
- 查询请求接口允许从服务器获取和缓存数据
- Query Hooks 返回一个 “data” 值,以及加载状态标志
- 查询可以手动重新获取,或者使用标签自动重新获取缓存失效
- Mutation 请求接口允许更新服务器上的数据
- Mutation hooks 返回一个发送更新请求的“触发”函数,以及加载状态
- 触发函数返回一个可以解包并等待的 Promise