Pandas数据清洗常用函数
构造一个数据集,便于演示这些函数。
import pandas as pd
df = {'姓名': ['漩涡鸣人', '宇智波佐助', '旗木卡卡西', '春野樱', '宇智波鼬'],
'性别': ['男', '男', 'men', 'women', '男'],
'身份证': ['463895200003128433', '429475199912122345', '420934199110102311', '431085200005230122', '420953199509082345'],
'身高': ['low: 165_bad', 'low: 166_bad', 'high: 178_verygood', 'low: 160_bad', 'mid: 175_good'],
'家庭住址': ['木叶漩涡一族', '木叶宇智波一族', '木叶旗木一族', '木叶居民', '木叶宇智波一族'],
'电话号码': ['13434813546', '19748672895', '16728613064', '14561586431', '19384683910'],
'收入': ['1.0万', '1.1万', '2.0万', '8.5千', '2.5万']}
df = pd.DataFrame(df)
df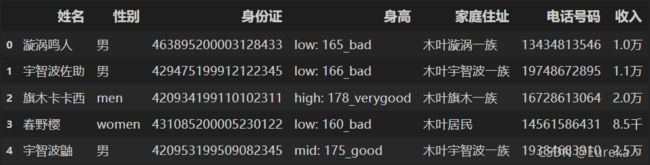
# cat函数——主要用于字符串的拼接
df['姓名'].str.cat(df['家庭住址'], sep='-'*3) 
# contains函数——判断某个字符串是否包含给定字符
df['家庭住址'].str.contains('木叶') 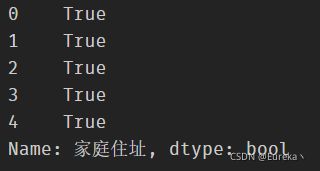
# startswith函数——判断某个字符串是否以给定字符串开头
df['姓名'].str.startswith('宇智波') 
# count函数——计算给定字符在字符串中出现的次数
df['电话号码'].str.count('3')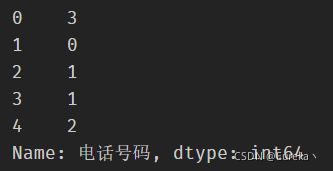
# get函数——获取指定位置的字符串
df['姓名'].str.get(-1) 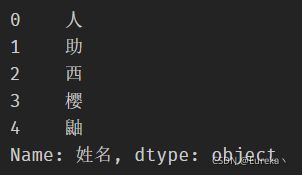
df['身高'].str.split(':')
df['身高'].str.split(':').str.get(0) 
# len函数——主要用于计算字符串长度
df['性别'].str.len() 
# pad、center函数——在字符串的左边、右边或左右两边添加给定字符
df['家庭住址'].str.pad(10, fillchar='*') 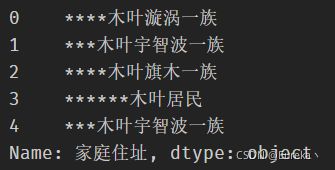
df['家庭住址'].str.pad(10, side='right', fillchar='*')
df['家庭住址'].str.center(10, fillchar='*') 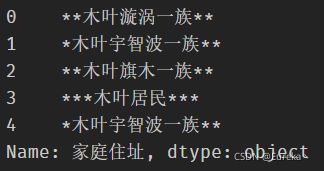
# repeat函数——主要用于重复字符串多少次
df['性别'].str.repeat(3)
# slice_replace函数——使用给定的字符串替换指定位置的字符
df['电话号码'].str.slice_replace(3, 7, '*'*4) 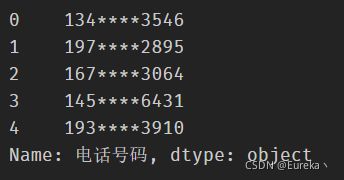
# replace函数——使用给定的字符(串)替换指定字符(串)
df['身高'].str.replace(':', ' -')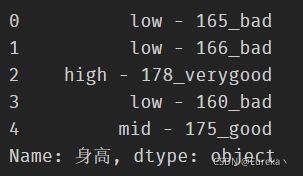
# split + expand参数——将一列扩展为多列
df[['身高描述', 'final身高']] = df['身高'].str.split(':', expand=True)
df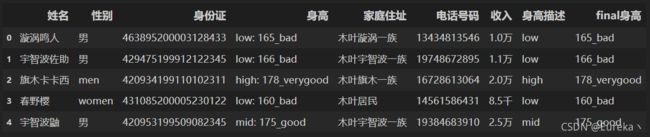
# split + join —— 类似于replace函数
df['身高'].str.split(':').str.join(' ?'*5) 
# strip函数——主要用于去除空白符、换行符
df['姓名'] = df['姓名'].str.strip()
df['姓名'].str.len() 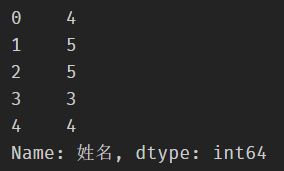
# findall函数——利用正则表达式,去字符串中匹配,返回查找结果的列表
df['身高'].str.findall('[a-zA-Z]+') 
# extract、extractall函数——接受正则表达式,抽取匹配的字符串(一定要加上括号)
df['身高'].str.extract('([a-zA-Z]+)') 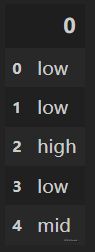
df['身高'].str.extractall('([a-zA-Z]+)') 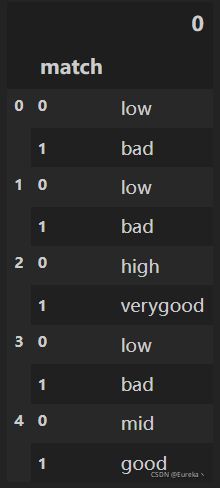
df['身高'].str.extract('([a-zA-Z]+).*?([a-zA-Z]+)', expand=True) 