NLP_基于酒店评论的情感分析
文章目录
- 1、自然语言处理概述
-
- NLP意义与难点
- 2、NLP核心问题与主要应用
-
- 2.1 核心问题
- 2.2 主要应用
- 3、NLP中机器学习与深度学习方法
-
- 3.1 NLP的机器学习与深度学习方法
- 3.2 典型应用的解决效果
- 4、NLP应用:基于评论情感分析的酒店挑选
-
- 4.1 基础知识及项目背景
- 4.2 解决方案
-
- A. 数据读取
- B. 机器学习解决方案
- C. 深度学习解决方案
- 5、项目书写
本文主要是对《AI工程师(自然语言处理)体验课》课程的笔记整理
讲师:寒小阳
1、自然语言处理概述
定义:自然语言处理(Natural Language Processing),简称NLP,是一种利用计算机为工具对人类特有的书面形式和口头形式的自然语言的信息进行各种类型处理和加工的技术
任务:通过处理和理解语言,来构建执行某些任务的系统
地位:人工智能与语言学的交叉学科,是人工智能的一个重要分支
- 跟计算机视觉、语音等构成人工智能不同研究领域
- 也被叫做计算语言学
- 基于机器学习和深度学习可以解决很多NLP问题
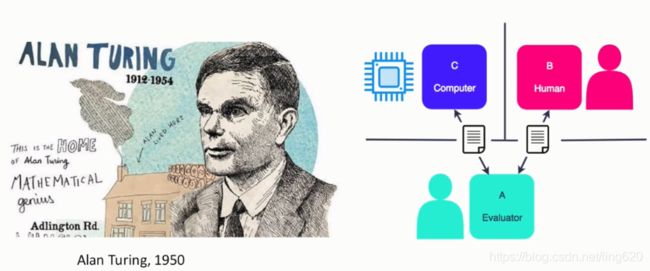
Turing Test(图灵测试):自然语言理解是人工智能的根本问题
自然语言处理的层级
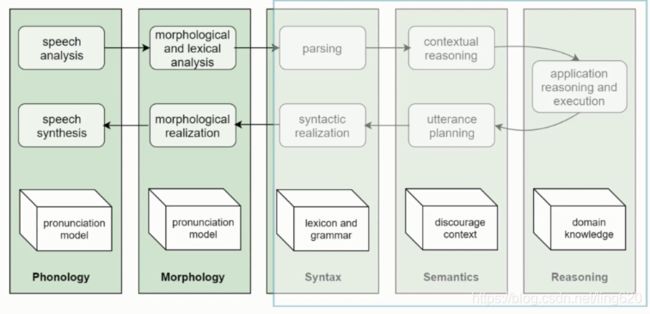
从左到右: 声音、词态学、语句结构,上层语义,高级应用如文本推理
NLP意义与难点
- 逻辑性强
- 依赖于强大知识库

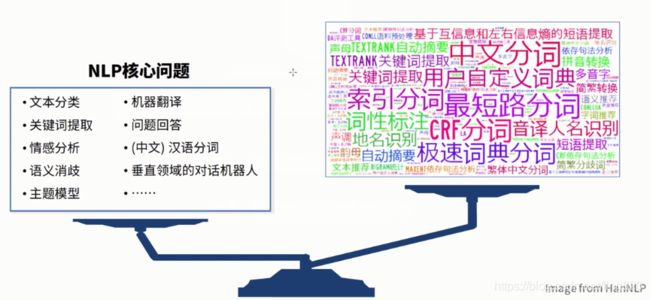
2、NLP核心问题与主要应用
2.1 核心问题
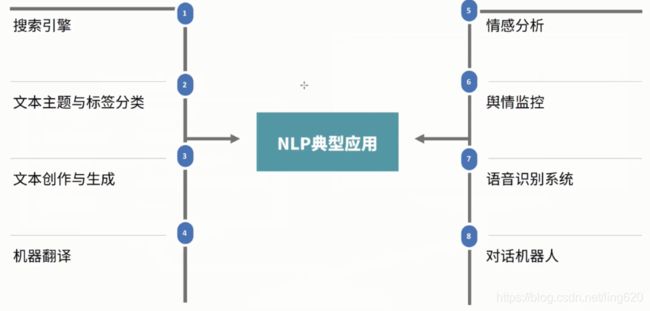
2.2 主要应用
- 搜索引擎
- 文本主题与标签分类
- 文本创作与生成
- 机器翻译
- 情感分析与舆情监控
- 语音识别应用
- 聊天机器人:如
Siri
3、NLP中机器学习与深度学习方法
3.1 NLP的机器学习与深度学习方法
机器学习:人工对文本提取特征(预处理),稀疏表达
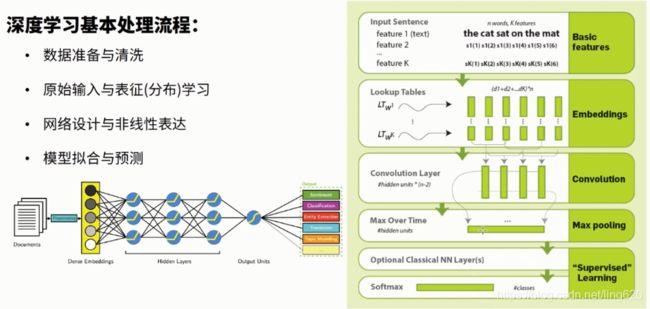
深度学习:端到端的学习,也叫做表示学习,稠密向量
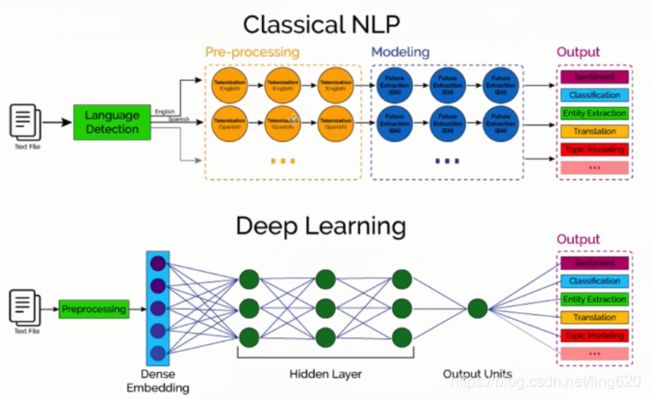
机器学习基本处理流程
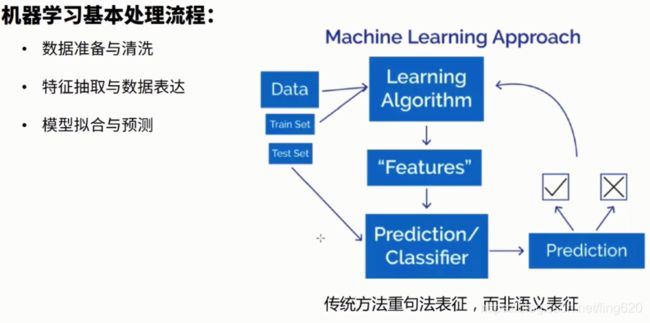
机器学习: 基于高维&稀疏的特征,如SVM,Logistic回归
深度学习:基于密集向量
3.2 典型应用的解决效果

4、NLP应用:基于评论情感分析的酒店挑选
4.1 基础知识及项目背景
项目名称: 酒店评论情感分析
情感分析:(也称为意见挖掘)是指用自然语言处理、文本挖掘以及计算机语言学等方法来识别和提取原素材中的主观信息。
具体表示就是,给你一段文本,用情感分析的自动化方法获取这一段内容中表达的情感色彩是什么?
通过爬虫技术获取到酒店的评论内容
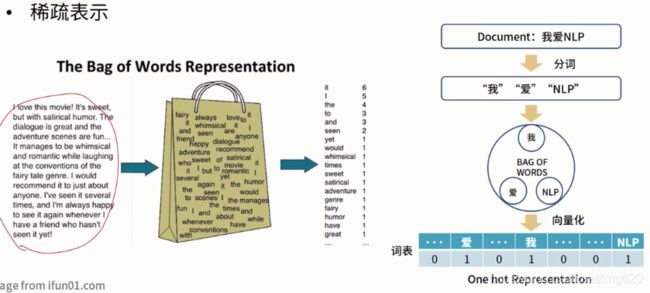
传统机器学习文本表示:词袋模型
用稀疏向量去表示文本,也叫“独热向量”
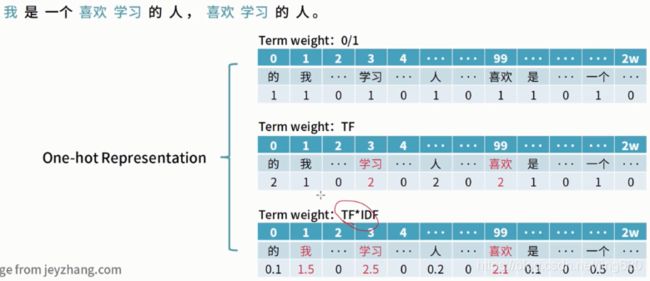
深度学习文本表示:词嵌入(词向量)
以稠密向量的形式去表征词与词之间的向量关系
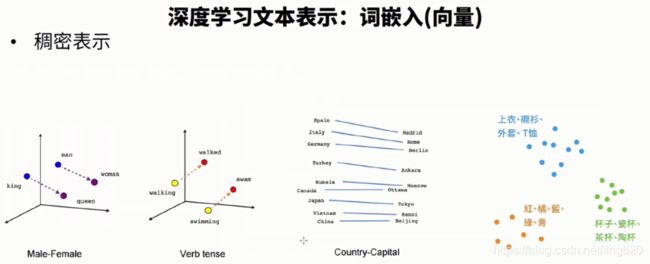
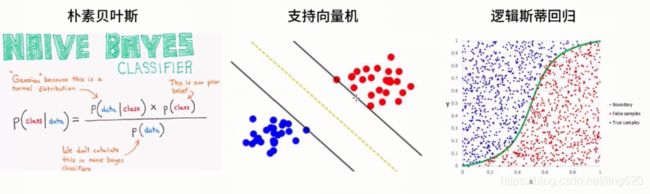
4.2 解决方案
机器学习解决方案:
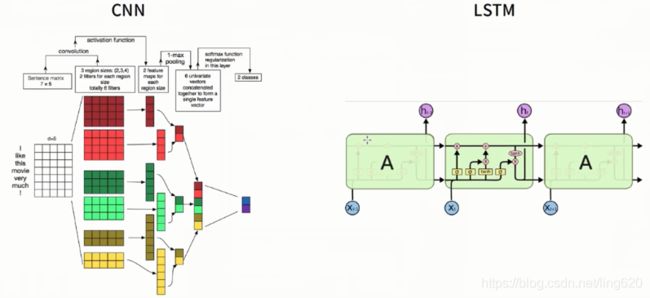
深度学习解决方案:
模块导入
import warnings
warnings.filterwarnings("ignore")
import jieba
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib
matplotlib.rcParams['figure.figsize'] = (10, 5)
from wordcloud import WordCloud
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.naive_bayes import MultinomialNB
A. 数据读取
从网络上爬取了部分酒店的评论数据,用于这个场景的模型构建。
stopwords = []
for line in open("./stopwords.txt"):
stopwords.append(line.strip())
def read_file(fi, sentiment, stopwords, words, sentences):
for line in open(fi):
try:
segs = jieba.lcut(line.strip())
segs = [word for word in segs if word not in stopwords and len(word) > 1]
words.extend(segs)
sentences.append((segs, sentiment)) # tuple
except:
print(line)
continue
words = []
sentences = []
sentiment = 1
read_file('./pos.txt', sentiment, stopwords, words, sentences)
sentiment = 0
read_file('./neg.txt', sentiment, stopwords, words, sentences)
B. 机器学习解决方案
# ML
x, y = zip(*sentences)
x = [" ".join(sentences) for sentences in x]
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=1, test_size=0.1)
# feature extract
vec = CountVectorizer(ngram_range=(1, 2), max_features= 1000)
vec.fit(x_train)
def get_feature(x):
vec.transform(x)
classifier = MultinomialNB()
classifier.fit(vec.transform(x_train), y_train)
# 测试
classifier.score(vec.transform(x_test), y_test)
也可以换成其他分类, 如SVM
C. 深度学习解决方案
通过构建LSTM实现情感分类
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
from keras.models import Sequential
from keras.layers import Dense, Embedding, LSTM
from sklearn.model_selection import train_test_split
import pandas as pd
tokenizer = Tokenizer(nb_words=2500, split=' ') # 保留2500个词
tokenizer.fit_on_texts(x)
X = tokenizer.texts_to_sequences(x)
X = pad_sequences(X)
# 设定embedding维度等超参数
embed_dim = 16
lstm_out = 100
batch_size = 32
# 构建LSTM网络
model = Sequential()
model.add(Embedding(2500, embed_dim, input_length=X.shape[1], dropout=0.2))
model.add(LSTM(lstm_out, dropout_U=0.2, dropout_W=0.2))
model.add(Dense(2, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
Y = pd.get_dummies(pd.DataFrame({'label': [str(target) for target in y]})).values
X_train, X_valid, Y_train, Y_valid = train_test_split(X, Y, test_size=0.1, random_state==2018)
# 拟合与训练模型
model.fit(X_train, Y_train, batch_size=batch_size, nb_epoch=10)
# 验证
score, acc = model.evaluate(X_valid, Y_valid, verbose=2, batch_size=batch_size)
print('Logloss损失: %.2f' %(score))
print('验证集的准确率 :%.2f'%(acc))
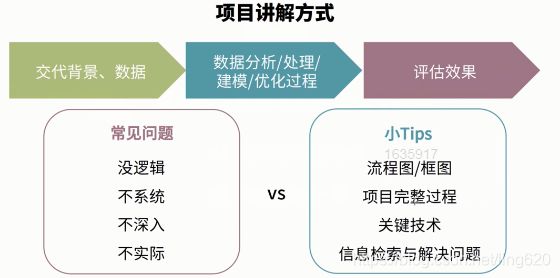
5、项目书写
- 项目背景:项目输入,输出,后续应用点
- 项目数据:数据来源
- 数据处理方法:是否有脏数据,如何处理脏数据,如何定义脏数据,是否有类别不均衡,如何解决,表示成什么形态
- 模型选择与建模过程:选择什么模型,如何调优
- 评估准则与效果:效果如何
- 模型优化与提升:
bad case分析,优化点有哪些
项目考核点:
- 体现问题解决能力
- 信息检索能力,用到新的方法,调研,探索,下一步优化方向
- 文本数据如何做预处理
- 如何清洗数据
- 对不均衡的类别如何处理
- 文本数据特征工程方式
- Word2vec/word embedding的理解
- CNN/LSTM技术细节
- 模型评估与过拟合解决方法