毕业设计之进销存管理系统 —— 一步步搭建自己的框架及系统
目录
- 一、系统展示
- 1.登录页面
- 2.admin登录后的主页
- 3.菜单管理
- 4.角色管理>新增角色
- 5.用户管理
- 6.添加商品
- 7.仓库管理
- 8.供应商管理
- 9.采购订单管理
- 10.采购订单导出
- 11.库存查看
- 12.采购统计
- 二、系统需求分析
- 1.问题分析
- 2.系统模块结构
- 3.系统总体流程
- 三、开发环境简介
- 1.maven
- 2.Intellij IDEA
- 3.ExtJs
- 四、底层架构设计
- 1.规范
- 2.架构设计
- 五、数据库与实体设计
- 六、系统功能实现
- 1.创建工程
- 2.系统配置
- 3.模块分层
- 七、系统的调试与部署
- 1.测试
- 2.部署
- 八、总结
- 九、附件
大学四年,即将毕业!
大学期间的最后一篇博客,总结分享下我做的毕业设计。我选的论文命题为《燃气管网设备仪器进销存管理系统之后台设计》,由于我们专业只有我一个走技术路线,所以,我一个人完成了整个系统的设计及开发,总耗时近一个月,最终获得优的成绩。
这里不讨论论文,不写具体实现细节,主要讲如何一步步搭建自己的系统框架及系统实现,分享下自己的心得,新手可以互相学习,大牛们就当看作本人抛砖引玉啦!!
博客最后会附上系统开发相关的所有文件但不包括毕业论文,本文已大体包含了论文的内容!
回到顶部
一、系统展示
1.登录页面
2.admin登录后的主页

3.菜单管理
4.角色管理>新增角色

5.用户管理
6.添加商品

7.仓库管理
8.供应商管理
9.采购订单管理

10.采购订单导出
11.库存查看

12.采购统计
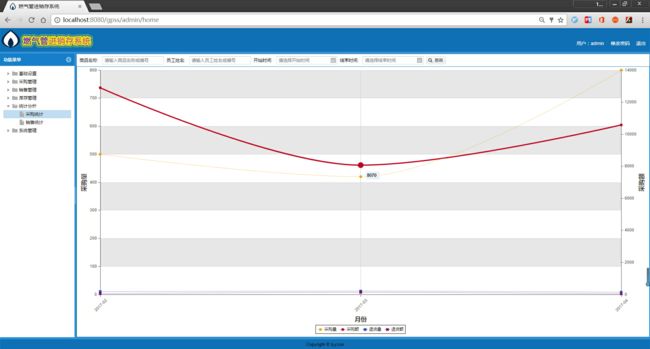
回到顶部
二、系统需求分析
上面简单的展示了完成后的系统测试截图,你可以下载war包部署到自己的tomcat上看,下面开始进入正文。
开发一个(简单)系统,我想首要做的就是进行系统需求分析,弄清楚你为什么要做这个系统,这个系统有哪些功能模块,每个功能具体实现些什么功能。
当然,我这里的主要目的是完成毕业设计,交出毕业论文。但我并没有简单的只是为了完成一个毕业设计而去开发这个系统。主要想法是以开发这套进销存管理系统为例,详细说明一个系统从确认需求、技术选型、架构设计、系统实现到测试部署的整个开发过程。综合运用自己平时所学的知识、技术,及实习获得的经验等,去完整且较好的实现一个系统。搭建一个基础系统框架,形成一定规范,以后在此基础上做开发,可以省去很多诸如搭建框架、加入依赖、配置等工作。
这次开发所做的主要工作及意义如下:
①学会站在用户的角度分析用户需求,完成需求分析设计等。
②熟练使用各种类相关开发、设计工具,及开源软件。
③熟练掌握Spring+SpringMVC+Hibernate+ExtJs的开发技术。
④熟练使用maven构建工具。
⑤站在企业的角度,试着搭建自己的一个底层基础框架。
⑥建立完整的燃气管进销存管理系统,进行测试并分析结果。
⑦将系统部署到互联网上,以实现真正的web应用。
1.问题分析
首先,对系统进行需求分析,首先需要了解的就是什么是进销存系统,进销存系统也称为供应链管理系统,最基本的内容就是采购、库存、销售、退货管理。进销存系统是对企业生产经营中采购、入库、销售进行跟踪管理,从采购单开始,到商品入库,商品销售出库,每一步都跟踪记录。有效解决企业的分销管理等业务问题。那么燃气管进销存系统有何不同呢,其实进销存系统已经具备了一般商品的进销存功能,燃气管就是一种商品。以此为出发点,开始着手设计系统功能模块。
2.系统模块结构
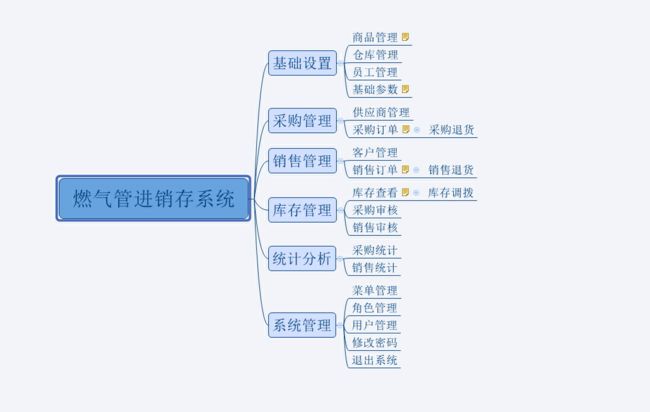
系统分为6大模块,分别是基础设置、采购管理、销售管理、库存管理、统计分析、系统管理。系统设置的角色有admin、采购员、销售员、库存管理员等。
系统模块结构(使用xmind设计):
3.系统总体流程
系统的一个整体流程,从初次使用开始,系统设置一个超级管理员(admin),拥有系统的所有权限。admin登录系统,设置角色(系统管理员,采购员,销售员,库存管理员),分配对应的权限。然后进入用户管理,录入系统用户。一般管理员登录系统,录入基础数据;采购员需要录入供应商,采购单,退货单;销售员则需录入销售单,退货单。库存管理员就需要在库存管理中进行采购审核和销售审核,采购审核通过则商品入库,增加库存;销售审核通过则商品出库,减少库存。管理员还可以查看每月的采购统计和销售统计。
系统总体流程(使用visio设计):

回到顶部
回到顶部
三、开发环境简介
需求确定了,就要进入具体的开发阶段,首先确定开发这个系统综合用到哪些技术、开发工具等。
简单说下这个系统的开发环境:
开发平台:windows 8.1
Java版本:jdk 1.8
项目管理工具:Maven
开发工具:Intellij IDEA
数据库:MySql 5.1
服务器:Tomcat 8.5
开发框架:Spring4 + SpringMVC + Hibernate5
前端框架:ExtJs 4.2 + Jsp
建模工具:PowerDesigner、Visio
1.maven
Maven是Apache软件基金会组织维护的一款自动化构建工具,专注服务于Java平台的项目构建和依赖管理。它提供了中央仓库,能帮我们自动下载构件和第三方的开源类库。你只需要在你的项目中以坐标的方式依赖一个jar包,maven就会自动从中央仓库下载,并同时下载这个jar包所依赖的其他jar包,以及可以下载源码进行阅读。使用maven后每个jar包本身只在本地仓库中保存一份,极大的节约了存储空间,让项目更轻巧,更避免了重复文件太多而造成的混乱。同时maven可以替我们自动的将当前jar包所依赖的其他所有jar包全部导入进来,无需人工参与,节约了大量的时间和精力。使用maven,只需要一条简单的命令,就可以自动完成清理、编译、测试、打包、部署的整个过程。我们的项目一般会分为开发环境和生产环境,不同环境对应不同的配置文件,使用maven,你就可以配置两个环境,打包的时候指定运行的环境,就可以将对应的配置文件替换,以此减少手工操作及可能带来的失误操作等。
2.Intellij IDEA
IDEA是java语言开发的集成环境,Intellij被公认为最好的Java开发工具之一。IDEA在代码自动提示、重构、调试、各类版本工具(maven、svn等)整合等方面都是比较强的。本人是在实习期间转用idea开发的,之前一直使用eclipse,相比eclipse,idea在调试、代码自动提示等方面更显优势。项目在idea中有一个更友好的目录结构,尤其是多工程项目。当然,eclipse比idea更容易上手,使用idea可以提高你的开发速度,但前提是你需要记住大量的快捷键。使用idea的调试功能,比如,你只需要按快捷键Alt+F8,然后输入表达式,就可以快速求值;在调试的时候,idea会在变量的后面以不同的颜色显示变量的值,你就可以很清楚的知道调试的每一步,非常方便。使用好IDEA能在很大程度上提高我们的开发速度。
3.ExtJs
ExtJs可以用来开发富客户端的ajax应用,是用javascript写的与后台技术无关的前端ajax框架,主要用于创建前端用户界面,拥有强大的数据处理功能,以及图表统计等。同时,ExtJs拥有很多个性化的主题供你选择,是开发后台管理系统的一个不错的选择。
回到顶部
回到顶部
四、底层架构设计
在进行进销存系统的设计和编码之前,首先设计一个自己的底层框架,这个底层框架在之后可以作为其它具体项目开发的一个基础,从而不必每次开发项目时,都去做很多重复的工作。这个底层框架主要包括一个开发的规范,以及一些通用的工具类等,更重要的是分类别引入各个框架,如Spring、Hibernate、各个配置文件等。同时,如果以后在开发中,增加的一些新功能,还可以往这个底层中添加,不断的去完善。
1.规范
在进行框架设计之前,为了使软件开发过程顺畅、提高代码的可靠性,可读性和可维护性等,首先需要确定的就是开发规范了,俗话说,没有规矩不成方圆,软件开发亦是如此。下面列出一些简单的需要遵守的规范。
1.1基础规范
首先需要遵守的是一些基础规范。一般来说,公司会将域名作为所有命名的一个基础,比如文件名、包名等等。因此我申请了一个域名[www.lyyzoo.com]作为个人域名。然后将D:/lyyzoo-repo作为开发的根目录,即个人代码仓库,以后所有的项目都会建到这个目录下。所有的项目开发使用maven来管理项目,因此目录结构是标准的maven规范目录。
maven约定的目录结构:

1.2代码规范
①命名
> 所有的命名需要见名之意,尽量保证通过变量名得知变量的含义,需要注释的地方尽量添加注释。
> 包命名全小写,通过域名倒写+模块的形式,如:com.lyyzoo.service
> 类命名采用Pascal名法,大写字母开头,每个单词首字母大写。
> 方法名采用Camel命名法,小写字母开头,每个单词首字母小写;getter和setter使用Lombok自动生成,只需添加@Data注解即可。
> 变量名采用Camel命名法,小写字母开头,每个单词首字母大写。变量名不宜过长,可采用首字母缩写的形式,但要见名之意。
> 常量名全大写,每个单词之间使用”_”分隔。
②分层
项目以功能模块划分,不同项目建立不同的工程,使用maven的依赖进行管理。包的基本分层有controller(控制层)、service(业务层)、dao(数据访问层)、entity(模型层)。
2.架构设计
2.1模块结构
整个项目的底层着重是一些通用的、基础的东西,整合到一起,以便于以后重用。首先,创建一个名为lyyzoo的maven工程,lyyzoo将作为底层的根目录。lyyzoo下有两个主要的子模块,分别为lyyzoo-base和lyyzoo-starter,lyyzoo-base是基础模块,用于一些简单的Java及JavaEE程序;lyyzoo-starter则是JavaEE相关,会依赖于lyyzoo-base,同时引入了Spring、Hibernate等第三方框架。然后在各个模块中添加具体的子模块。以后开发中需要用到哪个模块,在依赖中添加那个模块即可。
底层模块结构图:
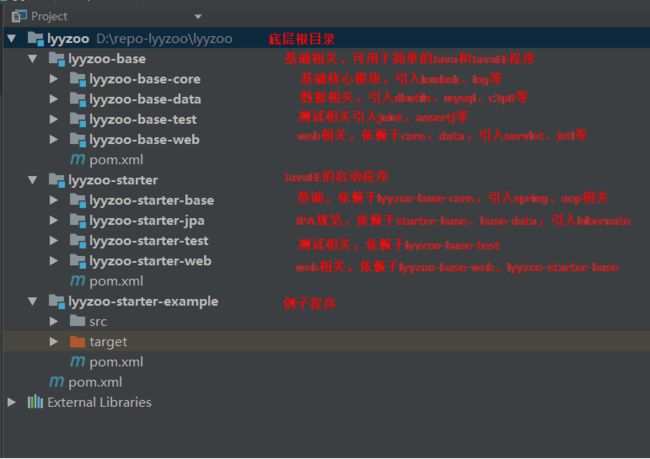
以下是各个POM之间的关系:
① lyyzoo > pom.xml

② lyyzoo-base > pom.xml
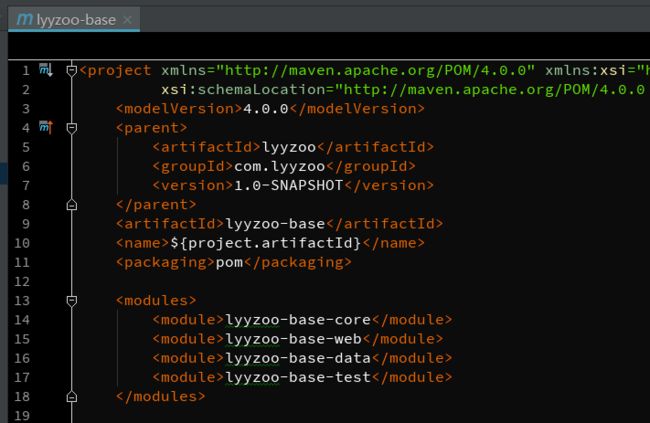
③ lyyzoo-starter > pom.xml
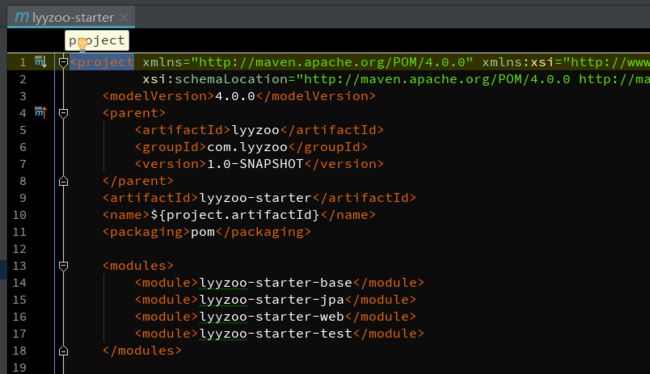
2.2依赖管理
结构建好后,就需要进行一些详细的依赖配置工作了,lyyzoo是所有模块的父类,所以在lyyzoo中需要添加公用的属性、依赖管理、maven插件等。
首先将所有的版本号提出来,放到
 View Code
View Code
接着,引入依赖管理,在lyyzoo中引入其它项目将会用到的所有三方jar包的依赖,所有的依赖都添加到
① 首先需要引入lyyzoo下的其它模块,如lyyzoo-base-core、lyyzoo-starter-base等模块。
View Code
② JDBC相关,相关jar包有c3p0,用于作数据库连接池;mysql驱动包;dbutils,对JDBC进行了简单的封装,使用起来简单方便。
View Code
③ 日志相关:
View Code
④ spring相关,包括了spring aop、spring mvc等。
View Code
⑤ hibernate相关:
View Code
所有的依赖添加好后,就需要为各个子模块添加具体的依赖了,根据每个子模块的功能,添加相关的依赖,而不是将所有的依赖一次性加入。这样我们就可以根据自己开发的项目的需要,添加模块依赖,而不是一次性加入所有jar包,避免冗余,增大项目的体积。下面以lyyzoo-base-data和lyyzoo-starter-jpa为例说明。
lyyzoo-base-data模块是基础数据相关,主要与数据库打交道,那么就需要引入mysql驱动、数据库连接池c3p0等,pom.xml如下:
View Code
lyyzoo-starter-jpa是Java持久化相关,所以主要引入hibernate相关的依赖,同时,starter-jpa会依赖base-data及starter-base,pom.xml如下:
View Code
2.3类结构
有了前面的基础之后,接下来进行重点的类结构设计。底层需要做的最重要的工作就是将一些通用的类抽象出来,以便于以后重用,从而提高开发效率。例如返回结果和分页类的封装、通用的工具类、JDBC相关的操作等。
说明一下,整个底层很大一部分是从之前实习的公司(这个就不说了)直接拿过来的,有些则更改了。相信我拿取的这部分代码并不会涉及机密问题,不用于商业用途,仅仅只是学习,应该没多大问题。
(1) lyyzoo-base-core
lyyzoo-base-core 目录结构:

lyyzoo-base-core是基础核心,封装了返回结果和加入了一些常用的工具类。
com.lyyzoo.bean包下封装了BaseBean和Result,BaseBean是Bean类的一个基础类,实现了序列化,重写了toString()方法,如下:
View Code
Result则封装了返回的结果,这里主要与ExtJs相对应,ExtJs进行ajax请求时,返回success=true,会进入success()方法;返回success=false,会进入failure()方法。同时,封装了返回消息、标识、错误信息等,便于前端拿到相应数据。
View Code
其它的主要是一些工具类,例如Arrays继承了org.apache.commons.lang3.ArrayUtils,使得Arrays具有了丰富的操作集合的工具。再如Dates,Dates里封装了大量的对日期操作的方法,比如格式化日期、获取某个日期当天的开始时间和结束时间等。
(2) lyyzoo-starter-base
lyyzoo-starter-base 目录结构:

lyyzoo-starter-base是web应用程序的一个基础,主要封装了基础实体类以及spring-base和日志的配置。实体的顶层是AbstractEntity
View Code
BaseEntity则继承AbstractEntity,BaseEntity作为其它实体的父类存在,BaseEntity定义了主键ID的生成策略。代码如下:
View Code
spring-base.xml是基础配置,主要配置了扫描系统的配置文件、注解等。
View Code
(3) lyyzoo-starter-jpa
lyyzoo-starter-jpa 目录结构:
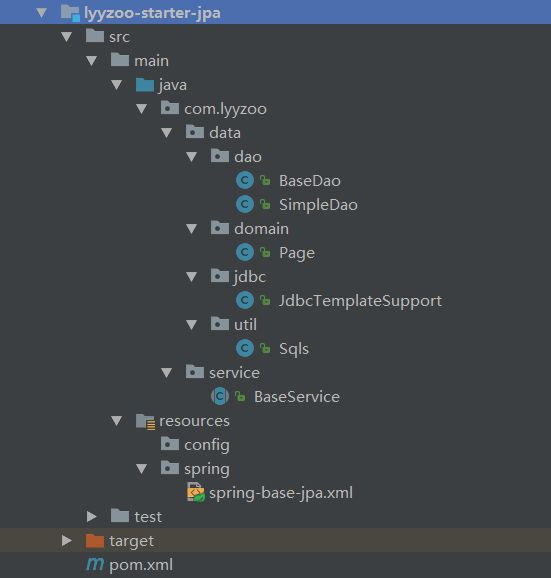
lyyzoo-starter-jpa集成了持久化相关的操作,配置等。
首先需要做持久化相关的配置(spring-base-jpa.xml),如数据源、SessionFactory、事务管理等。数据源使用c3p0,数据源相关配置如数据库驱动、地址等写到到配置文件中。配置Hibernate SessionFactory的同时,增加了JdbcTemplate。事务管理器使用Hibernate的事务管理。总的配置如下:
View Code
然后在com.lyyzoo.data.domain包下,Page封装了分页相关的属性,如当前页数据、页码、每页大小、总页数等。com.lyyzoo.data.util包下,Sqls封装了操作sql语句的工具,比如根据传入的查询语句,返回查询总数的sql语句。在com.lyyzoo.data.jdbc包下,JdbcTemplateSupport封装了比较复杂的查询,比如根据传入的参数、分页条件等,自动查询数据、总数并封装到Page里返回。com.lyyzoo.data.dao包下,SimpleDao封装了基于Hibernate SessionFactory的简单的增删改查操作,如save(),get()等方法。dao包下,BaseDao继承SimpleDao,并代理了JdbcTemplateSupport,使得BaseDao具有SimpleDao和JdbcTemplateSupport的功能,BaseDao则作为其它dao的一个父类存在。最后,在com.lyyzoo.service包下,BaseService代理了BaseDao,进行了进一步的封装,BaseService是其它service类的父类,其它service就可以直接调用save、get、page等内置方法。
(4) lyyzoo-starter-web
lyyzoo-starter-web自然跟web相关,在com.lyyzoo.web包下,BaseController作为controller类的父类,主要封装了返回结果集等信息。还有web相关配置,如视图解析器等内容:
View Code
(5) 类结构图
类结构图参考《底层类结构.vsd》

回到顶部
五、数据库与实体设计
在开始开发一个系统之前,首先需要做的就是根据需求分析设计系统的实体对象以及对应的数据库表结构,这是开发的基础。
根据前面的需求分析设计的功能模块,实体对象可以分为5个模块,分别是系统模块(system)、基础模块(base)、采购模块(purchase)、销售模块(sale)、库存模块(stock)。下面是实体清单:

有了清单之后,利用PowerDesigner进行数据库物理模型设计。由于拥有对数据库的完全控制权,所以不对表设置约束,所有的约束在程序代码中进行控制。下面列出各个实体的属性即对应的表,具体可参考《数据库物理模型.pdm》。物理模型设计完成后,创建名为gpss的数据库,然后创建各个表。
数据库模型:
回到顶部
六、系统功能实现
1.创建工程
需求分析做完了,技术没问题,底层架构也设计好了,数据库设计好了,前面的所有准备工作做完了,下面就要进行燃气管进销存系统的编码实现了。首先要做的工作就是创建工程,项目名拟为gpss,即燃气管进销存(Gas Purchase Sale Stock)的缩写,工程名则为lyyzoo-gpss。
在IDEA中创建lyyzoo-gpss的maven工程,继承lyyzoo。同时,在lyyzoo-gpss下创建两个子模块,分别为lyyzoo-gpss-base和lyyzoo-gpss-web,base模块包含了系统的dao、entity、service等层次,主要为java文件;web则包含了controller层、jsp、js等web相关资源文件。
lyyzoo-gpss目录结构:

lyyzoo-gpss > pom.xml:
View Code
lyyzoo-gpss-base主要是dao层、service层、model层的集成,所以需要依赖于底层lyyzoo-starter-jpa、lyyzoo-starter-web。
lyyzoo-gpss-base > pom.xml:
View Code
lyyzoo-gpss-web是web相关,是controller层所在。依赖于lyyzoo-gpss-base、lyyzoo-starter-base等。
lyyzoo-gpss-web > pom.xml:
View Code
2.系统配置
工程建好后,首要要做的就是系统的配置工作了,如web.xml,这应该算是web项目的起点了。进入lyyzoo-gpss-web/src/main/webapp/WEB-INF/web.xml,进行web的配置,主要的一些配置有加载系统的配置文件、Spring、字符过滤器、SpringMVC等配置。
一些基础的配置如下:
View Code
接着,配置系统将会用到的一些属性,如JDBC驱动、数据库用户名和密码等。在lyyzoo-gpss-web/src/main/resources/config下,创建config.properties配置文件,这个配置文件中的属性将会被底层spring配置的文件所引用。
比如JDBC的属性:
View Code
但是上面的配置只是本机的一个开发环境,如果我将项目发布到生产环境,那就至少需要重新修改数据库地址、用户名和密码。这样是比较麻烦的,所以,在lyyzoo-gpss-web/src/main/portable下创建两个xml文件,分别为开发环境和生产环境的:config-dev.xml和config-online.xml。
config-online.xml:
View Code
然后配置一个“不同环境打包”的maven插件——“portable-config-maven-plugin”,通过该插件,就可以在打包的时候加上需要打包的环境,例如指定online环境,在打包时就会将config-online.xml中的属性替换到config.properties里,这样一来就不必我们手动去替换了。配置好之后,我们在打包时可以使用命令[mvn clean package –Denv=online]打包线上环境的war包。
maven环境配置,在lyyzoo-gpss > pom.xml中配置两个环境:
View Code
不同环境打包插件(portable-config-maven-plugin)的配置:
View Code
3.模块分层
3.1 lyyzoo-gpss-base
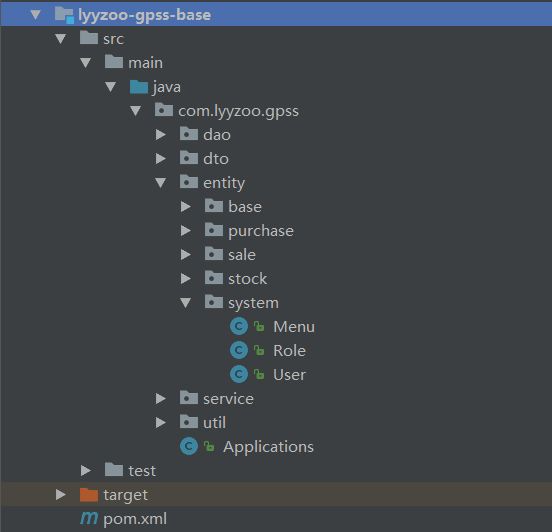
工程建好后,创建包的结构。按照一般的分层方式,分为dao层、entity层、service层,同时,每层下按模块划分为system、base、purchase、sale、stock。然后在entity下根据表设计创建实体类。
lyyzoo-gpss-base 目录结构:
3.2 lyyzoo-gpss-web
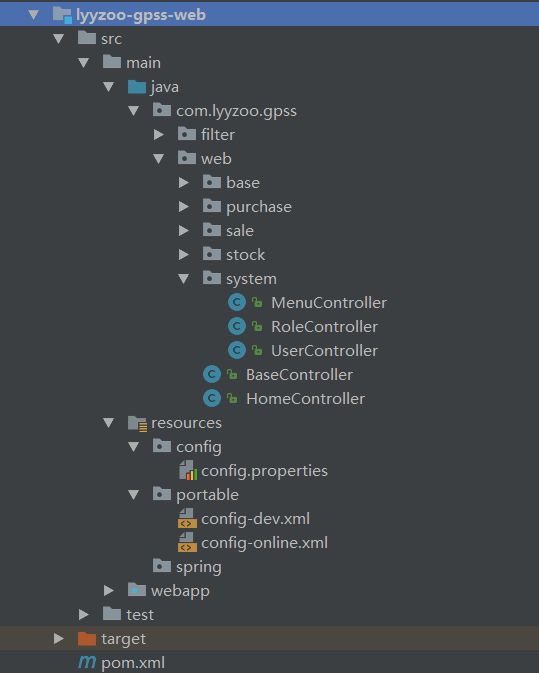
然后是lyyzoo-gpss-web模块,该模块主要是controller层,以及静态资源文件、jsp文件等。com.lyyzoo.gpss.web作为controller层的包,同样,在web下按系统模块划分。
lyyzoo-gpss-web 目录结构:
3.3 静态资源文件
lyyzoo-gpss-web/src/main/webapp/static作为静态文件的根目录,static/lib目录作为三方类库的根目录,如ExtJs、jQuery、其它的插件等。static/css是系统css文件的根目录;static/img是图片的根目录;static/js是系统js文件根目录,/js下同样按模块划分。
静态资源文件目录结构:

3.4 JSP文件
jsp文件不能直接让用户访问,需要放到/WEB-INF下,与配置的spring视图解析器相对应,所有的jsp文件放到/WEB-INF/view目录下,view目录下按模块划分,index.jsp是系统的登录页面。/WEB-INF/layout/目录下,将jsp中需要引入的一些资源等做了整合,如ExtJs的文件、meta描述信息、taglib等,整合后,jsp中如果需要引入整合jsp即可,可减少很多重复的工作。
taglib.jsp中引入了标签和设置了资源的路径:
View Code
meta.jsp中主要设置了一些meta描述信息和ICO图标:
View Code
extjs-neptune.jsp则引入了ExtJs相关的css和js文件,以及jQuery等:
View Code
WEB-INF目录结构:

3.4 登录实现举例
首先创建一个BaseController,BaseController继承底层的BaseController,增加了HttpSession,以及获取当前登录用户的方法,这样其它的controller继承该BaseController后,就可以非常方便的获得当前session和登录用户了。
BaseController代码如下:
View Code
创建HomeController作为登录和主页的处理器。主要包含的方法有访问登录页面,访问登录后的主页,以及登录处理等。Controller需要加上@Controller标注该类为controller,使用@RequestMapping()支持访问rest形式的地址访问。HomeController中注入UserService,用于处理用户登录相关的业务。
用户进入登录界面,jsp页面以的形式请求验证码,验证码使用工具类生成,以流的形式输出,生成的验证码保存到session中。用户输入登录账号、密码和验证码登录系统。首先前台会检测输入是否为空等,传到后台,从session中取出验证码判断验证码是否正确,不正确则刷新验证码并且需要用户重新输入验证码。验证码通过后,使用登录账号和密码查找数据库,如果有,则将该用户保存到session中,跳转到管理页面,登录成功。否则提示用户名或密码错误。
HomeController代码如下:
View Code
UserService中根据用户名和密码获取用户:
View Code
回到顶部
七、系统的调试与部署
1.测试
系统开发完成后,首先需要在本地整体测试,从登录开始,每个模块,每个功能,每个流程具体的去测试。
首先测试如果未登录,用户是不能访问管理页面的,直接在地址栏输入访问地址看是否跳转到登录页面。然后至少测试各个角色相关的账号登录是否正常,登录后,每个角色拥有的菜单是否显示正常。
其它模块的测试,使用各个角色对应的账号,登录系统,进行相应功能的测试。如管理员进入系统录入基础数据,商品信息、仓库信息等。采购管理员录入供应商信息,录入采购订单,提交审核。销售管理员录入客户信息,录入销售订单,提交审核。库存管理员审核采购订单,审核通过,则库存增加;审核销售订单,审核通过,则库存减少。查看库存信息,相应的操作之后,库存量是否正确。测试结果可查看系统测试截图。
系统容错性测试,主要是测试输入一些错误的数据类型以及超出范围的数值测试系统在异常条件下的行为。系统在这方面做得比较好,如果用户输入了一些非法的数据,会立即提醒用户输入正确的数据。首先会在前台判断用户输入的数据的合法性、是否必须输入等,数据传到后台后,还会在代码里判断一次数据是否正确,才会保存到数据库。而系统使用的Jdbc也能在一定程度上防止SQL注入等问题。如果系统发生一些无法预测的异常,也会以友好的界面提示用户,以便技术员及时维护系统。
总体来说,整个的测试过程比较顺利,也存在一些小问题,就立即修复了。功能全部实现了,该系统能满足一个基本的进销存流程,以后也还可以扩展。
2.部署
我这里使用磨泊云来部署项目,磨泊云使用简单且在一定限度内免费,部署测试比较合适。首先在磨泊云上创建名为gpss的Java应用,接着创建mysql服务,并将其绑定到该java应用,复制数据库连接到配置文件中。导出本地的gpss数据库,导入到创建的mysql应用里。然后在IDEA中使用mvn clean package –Denv=online命令打包线上环境的war包,将war包发布到磨泊云上。启动项目,然后访问,测试,一些都正常。可访问域名http://gpss.butterfly.mopaasapp.com/查看,由于没处理好ext的兼容性问题,建议使用谷歌浏览器查看。后面再学学如何部署到像阿里云等云上。
回到顶部
八、总结
通过自己一步步去设计完成这个燃气管进销存系统,让我对软件的架构、设计、框架、编码、以及各种工具的使用更加熟练,熟悉了软件的开发流程。这个系统更是大学四年所学知识的一个产物,从拿到论文命题开始,理解命题,查阅相关资料,进行需求分析,设计功能模块,设计数据库;然后结合自己在实习期的工作经验以及公司的架构设计,搭建了一个自己的底层。在这个底层的基础上进行系统的开发。
经过近一个月的毕业设计,掌握了软件开发各个方面的相关知识,熟悉了整个流程,也检验了自己大学四年的知识水平。显然也还是有很多不足的,比如该系统中虽然使用SSH框架,但其框架的原理实现上还有很多不明白。个人认为学习一定要知其然也要知其所以然,尤其对于技术,需要去了解它的底层原理,才能提高自己的能力。这些就在以后的工作中去逐渐提高。
写到这里就基本完了,大学四年的最后一篇博客,以后就是在工作中去学习了。
很开心,要离开学校了,可以去工作找money了;很忧伤,要离开学校了,一生中可能最舒适的时光就是大学时光了。
我很喜欢我的学校 —— 西南大学,坐落于缙云山下,环境优美、美女如云,哈哈!
回到顶部
九、附件
github地址:https://github.com/bojiangzhou/lyyzoo-gpss
论文地址:https://download.csdn.net/download/u013244234/10281005
最后,系统开发相关文件分享出来:燃气管网设备进销存系统
压缩包目录如下:

作者:bojiangzhou
出处:http://www.cnblogs.com/chiangchou/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。