YOLO系列入门:yolov1、yolov2、yolov3、yolov4、yolov5、yolov6、yolov7
文章目录
- YOLO的每个版本都是基于前一版本进行更新,故需要先理解初始版本。
- 前言:评价指标
-
- (1)指标:IOU
- (2)指标:Precision(精度)、Recall(召回率)
- (3)指标:mAP
- 一、开山之作:yolov1
-
- (1.1)简介
- (1.2)网络模型
-
- 备注:连续使用两个全连接层的作用?
- (1.3)损失函数(四部分组成)
- (1.4)NMS非极大值抑制
- (1.5)性能表现
- 二、更快更强:yolov2
-
- (2.1)性能表现
- (2.2)网络模型(Darknet-19)
- (2.3)改进之处
-
- (2.3.1)加入批标准化(Batch Normalization,BN)
- (2.3.2)使用高分辨率图像,微调分类模型。
- (2.3.3)聚类提取先验框(Anchor Box)
- (2.3.4)相对偏移量计算 —— 在当前网格中进行相对位置的微调
- (2.3.5)Fine-Grained Features(细粒度特性)
- (2.3.6)Multi-Scale多尺度检测(yolov2版)
- 三、巅峰之作:yolov3
-
- (3.1)性能表现
- (3.2)网络模型(Darknet-53)
- (3.3)改进之处
-
- (3.3.1)Multi-Scale多尺度检测(yolov3版)
- (3.3.2)多标签分类:softmax()改成logistic()
- 四、大神接棒:yolov4
-
- (4.1)性能表现
- (4.2)网络模型(CSPDarknet53)
-
- (4.2.1)跨阶段部分网络(Cross Stage Partial Networks,CSPNet)
- (4.2.2)空间金字塔池化网络(Spatial Pyramid Pooling Network,SPPNet)
- (4.2.3)空间注意力机制(Spatial Attention Module,SAM)
- (4.2.4)路径聚合网络(Path Aggregation Network,PANet)
- (4.2.5)Mish激活函数
- (4.3)改进之处
-
- (4.3.1)马赛克(Mosaic)数据增强 + CutMix数据增强
- (4.3.2)自对抗训练(Self-Adversarial Training,SAT)
- (4.3.3)改进的Dropout(DropBlock)
- (4.3.4)标签平滑(Label Smoothing)
- (4.3.5)CIoU损失函数
- (4.3.6)DIoU-NMS
- 五、横空出世:YOLOv5
-
- (5.1)性能表现
- (5.2)网络模型(YOLOv5s)
-
- (5.2.1)Backbone(特征提取模块)
- (5.2.1)EfficientNet
- (5.3)改进之处
- 六、昙花一现:YOLOv6
- 七、谁与争锋:YOLOv7
-
- (7.1)性能表现
- (7.2)网络模型
- (7.3)改进之处
-
- (7.3.1)RepVGG(最大改进)
- (7.3.2)正样本分配策略
- (7.3.3)相对偏移量计算(yolov5/v7版)
- (7.3.4)辅助头(auxiliary head)+主头(lead head)
- 参考文献
YOLO的每个版本都是基于前一版本进行更新,故需要先理解初始版本。
前言:评价指标
(1)指标:IOU

(2)指标:Precision(精度)、Recall(召回率)

(3)指标:mAP

一、开山之作:yolov1
论文地址:You Only Look Once: Unified, Real-Time Object Detection
官方代码:https://github.com/pjreddie/darknet
(1.1)简介
在yolov1提出之前,双阶段(two-stage)的R-CNN系列算法在目标检测领域独占鳌头。
2016年,单阶段(one-stage)的YOLO(You Only Look Once) 初出茅庐。可以在图像中找出特定物体,并识别种类和位置。
备注:FPS是指视频每秒传输的帧数。例如:FPS=45 表示为45帧/秒。帧数愈多,所显示的动作就会越流畅。


❤️ yolo核心思想:把目标检测转变成一个回归问题。将整个图像作为网络的输入,仅仅经过一个神经网络,得到边界框的位置信息及其所属的类别。
(1.2)网络模型
备注:yolov1的输入图像大小固定为448×448,与全连接层的输出大小有关。训练时:224×224;测试时:448×448。 原因:224×224×3 相比448×448×3相差四倍,其像素点大幅度降低,减少对计算机的性能要求。


备注:连续使用两个全连接层的作用?
第一个全连接层作用:将卷积得到的分布式特征映射到样本标记空间。即把该输入图像的所有卷积特征整合到一起。
第二个全连接层作用:将所有神经元得到的卷积特征进行维度转换,最后得到与目标检测网络输出维度相同的维度。
【小问题思考】两个全连接层连用 1x1卷积作用

(1.3)损失函数(四部分组成)
损失函数由四个部分组成:
- (1)位置误差:对每个网格的两个边界框,提取IOU最大的一个,并计算其预测值与真实值的位置误差。其中,对w和h取根号计算,以避免物体大小因素对结果的影响。
- (2)置信度误差(obj):前景误差。 计算IOU大于置信度阈值的边界框与真实值的误差。若存在多个满足要求的边界框,则进行非极大值抑制。
我们希望前景框的误差趋近于1。- (3)置信度误差(noobj):背景误差。 若边界框的IOU小于置信度阈值或IOU=0,则该边界框属于背景。背景框远远大于前景框,故
对背景框误差设置阈值(如:0.1),降低背景框误差对损失函数的影响。我们希望背景框的误差趋近于0。- (4)分类误差:计算预测的分类标签与真实标签的误差。

(1.4)NMS非极大值抑制
非极大值抑制可以用来修正多重检测目标,能增加2~3%的mAP。
即在检测结果中,若存在多个检测框的IOU大于置信度阈值,通过非极大值抑制最后只取一个框。如下图:五个框中只取最大值(置信度=0.98)的预测框。

(1.5)性能表现
优点
- (1)YOLO检测速度非常快。标准版本的YOLO可以每秒处理 45 帧图像,极速版本可以每秒处理 150 帧图像,完全满足视频的实时检测要求;而对于欠实时系统,在保证准确率的情况下,速度也快于其他方法。
- (2)YOLO 实时检测的平均精度是其他实时监测系统的两倍。
- (3)迁移能力强,能运用到其他的新的领域(比如:艺术品目标检测)。
局限
- (1)YOLO对相互靠近的物体,以及很小的群体检测效果不好,这是因为一个网格只预测了2个框,并且都只属于同一类。
- (2)由于损失函数的问题,位置误差是影响检测效果的主要原因,尤其是对于物体大小因素的处理,还有待加强。(原因:对于一大一小两个边界框而言,对更小边界框的误差影响更大)
二、更快更强:yolov2
论文地址:YOLO9000: Better, Faster, Stronger
官方代码:http://pjreddie.com/darknet/yolo/
- 2017年,提出了yolov2和yolo9000,yolo9000能够实时检测超过9000种物体,主要检测网络还是yolov2。yolov2的整体网络架构和基本思想没有变化,重点解决yolov1召回率和定位精度方面的不足。相比其它的检测器,速度更快、精度更高、可以适应多种尺寸的图像输入。
- yolov1是利用全连接层直接预测Bounding Box的坐标。而yolov2借鉴了Faster R-CNN的思想,引入Anchor机制;利用K-means聚类的方法在训练集中聚类计算出更好的Anchor模板,大大提高了算法的召回率;同时结合图像细粒度特征,将浅层特征与深层特征相连,有助于对小尺寸目标的检测。
(2.1)性能表现
随着yolov2的每一步改进,mAP值持续上升。

(2.2)网络模型(Darknet-19)
Darknet-19采用了19个卷积层,5个池化层。
- (1)取消yolov1的两个全连接层。yolov1的依据全连接层直接预测 Bounding Boxes 的坐标值。 而yolov2采用 Faster R-CNN 的方法,只用卷积层与 Region Proposal Network 来预测 Anchor Box 偏移量与置信度,而不是直接预测坐标值。
- (2)添加了五个最大池化层(2的5次方)。最终的输出大小:输入图像(h,w)转换为(h / 32,w / 32)。
- (3)yolov2的实际输入图像大小为416×416,而不是448×448(416/32=13、448/32=14)。因为我们希望最后得到的是奇数值,有实际的中心点。最终得到13×13的输出。与yolov1的7×7相比,可以预测更多的先验框。
- (4)基于VGG的思想,大部分的卷积核都是3×3,一方面权重参数少,一方面感受野比较大;且采用降维的思想,将1×1的卷积核置于3×3之间,在保持整体网络结构的同时减少权重参数。并且每一次池化后,下一层卷积核的通道数 = 池化输出的通道 × 2。
- (5)在网络模型的最后,而增加了一个全局平均池化层。

Darknet-19 与 yolov1、VGG16网络的性能对比
- (1)VGG-16: 大多数检测网络框架都是以VGG-16作为基础特征提取器,它功能强大,准确率高,但是计算复杂度较大,所以速度会相对较慢。因此YOLOv2的网络结构基于该方面进行改进。
- (2)yolov1: 基于GoogLeNet的自定义网络,比VGG-16的速度快,但是精度稍不如VGG-16。
- (3)Darknet-19: 速度方面,处理一张图片仅需要55.8亿次运算,相比于VGG的306.9亿次,速度快了近6倍。精度方面,在ImageNet上的测试精度为:top1准确率为72.9%,top5准确率为91.2%。
(2.3)改进之处
(2.3.1)加入批标准化(Batch Normalization,BN)
最终约提升2%的mAP。
具体操作: 在每一个卷积层后面都加入BN,对数据进行预处理操作(如:统一格式、均衡化、去噪等)。
优点:解决梯度消失和爆炸问题,起到一定的正则化效果(yolov2不再使用dropout),获得更好的收敛速度。
(2.3.2)使用高分辨率图像,微调分类模型。
最终约提升4%的mAP。
背景:yolov1训练时的分辨率:224×224;测试时:448×448。
具体操作:yolov2保持yolov1的操作不变,但在原训练的基础上又加上了(10个epoch)的448×448高分辨率样本进行微调,使网络特征逐渐适应 448×448 的分辨率;然后再使用 448×448 的样本进行测试,缓解了分辨率突然切换造成的影响。
(2.3.3)聚类提取先验框(Anchor Box)
最终约提升7%的recall达到88%,但降低了0.3%的mAP。
- ❤️ yolov1边界框都是手工设定的,通过直接对边界框的(x,y,w,h)位置进行预测,方法简单但训练困难,很难收敛。
- ❤️ Faster R-CNN共有9种先验框:分三个不同的scale(大中小),每个scale的(h,w)比例分为:1:1、1:2、2:1。
- ❤️ yolov2引入先验框机制。 但由于Faster R-CNN中先验框的大小和比例是按经验设定的,不具有很好的代表性。故yolov2对训练集中所有标注的边界框先进行聚类分析(比如:5类),然后获取每一类的中心值即实际的(w,h)比值作为先验框,该值与真实值更接近,使得网络在训练时更容易收敛。
备注1:yolov1将图像拆分为7×7个网格,每个网格grid只预测2个边界框,共7×7×2=98个。
备注2:yolov2将图像拆分为13×13个网格,在Faster R-CNN的9种先验框基础上,将所有的边界框13×13×9=1521进行K-means聚类,最终选择最优参数k=5。即yolov2的每个网格grid只预测5个边界框,共13×13×5=845个。

传统K-means聚类方法使用标准的欧氏距离,将导致大的box会比小的box产生更多的误差。而yolo的目的是使得先验框与真实框有更大的IOU值,故自定义距离公式。
距离公式:计算每一类的中心值对应的先验框centroids与真实框box的距离。即计算IOU=(先验框与真实框的交集)除以(先验框与真实框的并集)。IOU越大,越相关,则距离越小,反之亦然。备注:数据均已采用批标准化处理。
左图:x轴表示k的个数,y轴表示平均IOU值。紫色与黑色分别表示两个不同的数据集(形状相似)。综合考虑精确度和运算速度后,yolov2最终取k=5个先验框。
右图:k=5个先验框的图形化显示。

(2.3.4)相对偏移量计算 —— 在当前网格中进行相对位置的微调
背景:已知先验框的位置为(x,y,w,h),现在得到的预测边界框为(tx,ty,tw,th),即系统判定需要在先验框位置的基础上进行一定的偏移,进而可以得到更真实的位置。故需要将预测的偏移量加到先验框中(x+tx,y+ty,w+tw,h+th)。
问题:由于模型刚开始训练时,网络参数都是随机初始化,虽然进行了批标准化但是参数的基数比较大,将导致预测的边界框加上偏移量之后到处乱飘。
yolov2的本质:在当前网格中进行相对位置的微调。
下图参数说明:
- (Cx,Cy):表示当前网格的左上角位置坐标。
- (tx,ty,tw,th):表示预测的结果在当前网格相对位置的偏移量。
- σ(tx):表示对漂移量 tx 取sigmoid函数,得到(0~1)之间的值。即预测边框的蓝色中心点被约束在蓝色背景的网格内。约束边框位置使得模型更容易学习,且预测更为稳定。
- e的tw次方:是由于预测时取的log()对数值,故计算位置时进行还原。
- (bx,by,bw,bh):表示当前预测结果在特征图位置(即预处理后得到的13×13网格)。

(2.3.5)Fine-Grained Features(细粒度特性)
背景:
- 由于Faster R-CNN有大中小三种尺度scale的经验框,最终将对应得到小中大三种感受野。
- 感受野越大,其在原图像中对应的尺度越大,导致其对尺度较小的目标不敏感,故无法兼顾考虑小尺度目标。
- 备注:高分辨率(尺度大) - 感受野小;低分辨率(尺度小) - 感受野大。
yolov2需要同时考虑三种不同的感受野,通过不同层的特征融合实现。具体操作:通过添加一个passthrough Layer,把高分辨率的浅层特征(26×26×512)进行拆分,叠加到低分辨率的深层特征(13×13×1024)中,然后进行特征融合(13×13×3072),最后再检测。(在yolov1中,FC起到全局特征融合的作用)。
目的:提高对小目标的检测能力。

(2.3.6)Multi-Scale多尺度检测(yolov2版)
背景:由于实际检测数据的输入图像大小不一,若都裁剪为相同大小,最后检测结果将有所下降。
限制:由于yolov2只有卷积层,故对输入图像大小没有限制;而yolov1由于有全连接层,故输入图像大小固定。
具体操作:训练模型每经过一定迭代之后,可以进行输入图像尺度变换。如:每迭代100次,输入图像尺寸大小增加10%。(备注:输入图像大小必须可以被32整除)

三、巅峰之作:yolov3
论文地址:YOLOv3: An Incremental Improvement
官网代码:https://github.com/yjh0410/yolov2-yolov3_PyTorch
(3.1)性能表现
x轴表示预测一张图片所需要的时间;y轴为mAP。原点的x轴坐标为50
由图可得:youlov3的检测速度和mAP值都强高于其他方法。

(3.2)网络模型(Darknet-53)
Darknet-53网络架构:
(1)由53个卷积层构成,包括1×1和3×3的卷积层,卷积省时省力速度快效果好,对于分析物体特征最为有效。每个卷积层之后包含一个批量归一化层和一个Leaky ReLU,加入这两个部分的目的是为了防止过拟合。
(2)没有全连接层,可以对应任意大小的输入图像。
(3)没有池化层,通过控制卷积层conv的步长stride达到下采样的效果,需要下采样时stride=2;否则stride=1;
(4)除此之外,Darknet-53中还使用了类似ResNet结构。

Darknet-53网络及在yolov3中的实际应用。可以看下面这张图:
- DBL:由一个卷积层、一个批量归一化层和一个Leaky ReLU组成的基本卷积单元。在Darknet-53中,共有53个这样的DBL,所以称其为Darknet-53。
- res unit:输入通过两个DBL后,再与原输入进行特征add,得到与原图像大小维度相同的图像;这是一种常规的残差单元。残差单元的目的是为了让网络可以提取到更深层的特征,同时避免出现梯度消失或爆炸。残差网络的特点:至少不比原来差。
- res(n):表示n个res unit。resn = Zero Padding + DBL + n × res unit 。
- y1、y2、y3: 分别表示yolov3的三种不同尺度输出(分别对应:大中小感受野)。
- concat1: (大中小感受野)将大感受野的特征图像进行上采样,得到与中感受野的特征图像相同大小,然后进行维度拼接,达到多尺度特征融合的目的。 为了加强算法对小目标检测的精确度
- concat2: (大中小感受野)将中感受野的特征图像进行上采样,得到与小感受野的特征图像相同大小,然后进行维度拼接,达到多尺度特征融合的目的。 为了加强算法对小目标检测的精确度
bounding box 与anchor box的输出区别- (1)Bounding box输出:框的位置(中心坐标与宽高),confidence以及N个类别。
- (2)anchor box输出:一个尺度即只有宽高。


(3.3)改进之处
(3.3.1)Multi-Scale多尺度检测(yolov3版)
前提:分辨率信息直接反映目标的像素数量。分辨率越高,像素数量越多,对细节表现越丰富。在目标检测中,语义信息主要用于区分前景(目标)和背景(非目标)。其不需要很多细节信息,分辨率大反而会降低语义信息。yolov3主要针对小目标检测的不足之处做出改进。
具体形式:在网络预测的最后某些层进行上采样+拼接操作。
(详细请看yolov3网络架构)
(3.3.2)多标签分类:softmax()改成logistic()
将yolov2的单标签分类改进为yolov3的多标签分类。即softmax()分类函数更改为logistic()分类器。
具体形式:逻辑分类器通过对每个类别都进行二分类,以实现多标签分类。使用sigmoid函数将特征图的结果约束在[0~1]之间,如果有一个或多个值大于设定阈值,就认定该目标框所对应的目标属于该类。多个值称为多标签对象。(如:一个人有woman、person、地球人等多个标签)

四、大神接棒:yolov4
论文地址:YOLOv4: Optimal Speed and Accuracy of Object Detection
官网代码:https://github.com/AlexeyAB/darknet
核心思想:yolov4筛选了一些从yolov3发布至今,被用在各式各样检测器上,能够提高检测精度的tricks,并加以组合及适当创新的算法,实现了速度和精度的完美平衡。虽然有许多技巧可以提高卷积神经网络CNN的准确性,但是某些技巧仅适合在某些模型上运行,或者仅在某些问题上运行,或者仅在小型数据集上运行。
主要调优手段:加权残差连接(WRC)、跨阶段部分连接(CSP)、跨小批量标准化(CmBN)、自对抗训练(SAT)、Mish激活、马赛克数据增强、CmBN、DropBlock正则化、CIoU Loss等等。经过一系列的堆料,终于实现了目前最优的实验结果:43.5%的AP(在Tesla V100上,MS COCO数据集的实时速度约为65FPS)。
(4.1)性能表现

(4.2)网络模型(CSPDarknet53)
CSPDarknet53网络及在yolov4中的实际应用。

yolov4的CSPDarknet53与yolov3的Darknet-53相比,主要区别:
- (1)将原来的Darknet53与CSPNet进行结合,形成Backbone网络。
- (2)采用SPPNet适应不同尺寸的输入图像大小,且可以增大感受野;
- (3)采用SAM引入空间注意力机制;
- (4)采用PANet充分利用了特征融合;
- (5)激活函数由MIsh替换Leaky ReLU; 在yolov3中,每个卷积层之后包含一个批归一化层和一个Leaky ReLU。而在yolov4的主干网络CSPDarknet53中,使用Mish替换原来的Leaky ReLU。
CSPDarknet53网络架构:

(4.2.1)跨阶段部分网络(Cross Stage Partial Networks,CSPNet)
背景: 2019年Chien-Yao Wang等人提出,用来解决网络优化中的重复梯度信息问题,在ImageNet dataset和MS COCO数据集上有很好的测试效果。且易于实现,在ResNet、ResNeXt和DenseNet网络结构上都能通用。
目的: 实现更丰富的梯度组合,同时减少计算量。
具体方式: 将基本层的特征图分成两部分:11、主干部分继续堆叠原来的残差块;22、支路部分则相当于一个残差边,经过少量处理直接连接到最后。

(4.2.2)空间金字塔池化网络(Spatial Pyramid Pooling Network,SPPNet)
论文地址:Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
yolov1背景:yolov1训练时的分辨率:224×224;测试时:448×448。
yolov2背景:yolov2保持yolov1的操作不变,但在原训练的基础上又加上了(10个epoch)的448×448高分辨率样本进行微调,使网络特征逐渐适应 448×448 的分辨率;然后再使用 448×448 的样本进行测试,缓解了分辨率突然切换造成的影响。
目的:使得网络模型的输入图像不再有固定尺寸 的大小限制。通过最大池化将不同尺寸的输入图像变得尺寸一致。
优点:增大感受野。
如图是SPP中经典的空间金字塔池化层。

(4.2.3)空间注意力机制(Spatial Attention Module,SAM)
具体方式: yolov4采用改进的SAM方法
优化历程: CBAM(Convolutional Block AM) -> SAM(Spatial Attention Module) -> 改进的SAM
优化原因:
(1)由于CBAM计算比较复杂且耗时,而yolo的出发点是速度,故只计算空间位置的注意力机制。
(2)常规的SAM最大值池化层和平均池化层分别作用于输入的feature map,得到两组shape相同的feature map,再将结果输入到一个卷积层。 过程过于复杂,yolo采取直接卷积进行简化。
- CBAM与SAM的区别:
- 特征图注意力机制(Channel Attention Module):在Channel维度上,对每一个特征图(channel)加一个权重,然后通过sigmoid得到对应的概率值,最后乘上输入图像,相当于对输入图像的特征图进行加权,即注意力。❤️
如:32×32×256,对256个通道进行加权。- 空间注意力机制(Spatial Attention Module):在Spatial维度上,对每一个空间位置(Spatial)加一个权重,然后通过sigmoid得到对应的概率值,最后乘上输入图像,相当于对输入图像的所有位置特征进行加权,即注意力。❤️
如:32×32×256,对任意空间位置进行加权。

- SAM与改进的SAM的区别:

(4.2.4)路径聚合网络(Path Aggregation Network,PANet)
论文地址(FPNet):Feature Pyramid Networks for Object Detection
论文地址(PANet):Path Aggregation Network for Instance Segmentation
背景: PANet发表于CVPR2018,其是COCO2017实例分割比赛的冠军,也是目标检测比赛的第二名。
具体方式: yolov4采用改进的PANet方法
优化历程: FPNet(Feature Pyramid Networks) -> PANet(Path Aggregation Network) -> 改进的PAN
优化原因:
- (1)FPNet网络采取自上而下的方式,将高层特征逐层与中高层、中层、中底层、低层特征进行融合。缺点是无法自下而上融合,而PANet的优化了该部分不足,详见示意图的(b)部分。
- (2)FANet采用特征相加的融合方式,而yolo采用特征拼接的融合方式。加法可以得到一个加强版的特征图,但特征权重不大于1,而拼接可能得到大于1的特征图。
FPNet示意图

PANet示意图
- (a)FPNet:通过 融合高层特征 来提升目标检测的效果。
- (b)Bottom-up Path Augmentation:通过 融合低层特征(边缘形状等)来提升目标检测的效果。
- (c)Adaptive Feature Pooling:采用 拼接特征融合。详见下图。拼接相比加法,特征更明显,可以提高检测效果。
- (d)Fully-connected Fusion


(4.2.5)Mish激活函数
论文地址:Mish: A Self Regularized Non-Monotonic Activation Function
Mish在负值的时候并不是完全截断,允许比较小的负梯度流入。实验中,随着层深的增加,ReLU激活函数精度迅速下降,而Mish激活函数在训练稳定性、平均准确率(1%-2.8%)、峰值准确率(1.2% - 3.6%)等方面都有全面的提高。
22个激活函数

(4.3)改进之处
BackBone训练策略:数据增强、自对抗训练、DropBlock正则化、类标签平滑、CIoU损失函数、DIoU-NMS等。
(4.3.1)马赛克(Mosaic)数据增强 + CutMix数据增强
CutMix论文: https://arxiv.org/pdf/1905.04899v2.pdf
最大特点:使得yolov4只通过单CPU就能完成训练,不用再担心设备问题。
具体方式:
- 11、采用常用的数据增强方法(如:亮度、饱和度、对比度;随机缩放、旋转、翻转等)对所有的图像进行数据增强;
- 22、采用CutMix数据增强方法。详细见下。
- 33、采取马赛克(Mosaic)数据增强方法,即随机取四张图像拼接为一张图像。
由图可得(左):CutMix表现最优。- (1)ResNet-50:采用常规的数据增强方法。如:调整亮度、饱和度、对比度;随机缩放、旋转、翻转等。
- (2)Mixup:将猫狗两张图像进行图像融合,其中狗和猫的权重参数都为0.5,故标签概率值都为0.5。
- (3)Cutout:随机删除/遮挡一个区域。
- (4)CutMix:随机删除/遮挡一个区域,并用A图像的一部分粘贴到B图像上。 如:将狗头替换为猫头,其中狗和猫的权重参数分别为0.6、0.4,故标签softmax的概率值分别为0.6、0.4。
备注1:softmax能够得到当前输入属于各个类别的概率。
备注2:标签(分类结果)会根据patch的面积按比例分配,计算损失时同样采用加权求和的方式进行求解。


数据增强的其余方法扩展:

(4.3.2)自对抗训练(Self-Adversarial Training,SAT)
在第一阶段:在原始图像的基础上,添加噪音并设置权重阈值,让神经网络对自身进行对抗性攻击训练。
在第二阶段:用正常的方法训练神经网络去检测目标。
备注:详细可参考对抗攻击的快速梯度符号法(FGSM)。

(4.3.3)改进的Dropout(DropBlock)
- b图:Dropout是随机删除一些神经元(如:a图的红点),但对于整张图来说,效果并不明显。比如:眼睛被删除,我们仍然可以通过眼睛的周边特征(眼角、眼圈等)去近似识别。
- c图:DropBlock是随机删除一大块神经元。 如:将狗头的左耳全部删除。

(4.3.4)标签平滑(Label Smoothing)
问题:标签绝对化:要么0要么1。该现象将导致神经网络在训练过程中,自我良好,从而过拟合。
具体方式:将绝对化标签进行平滑( 如:[0,0] ~ [0.05,0.95] ),即分类结果具有一定的模糊化,使得网络的抗过拟合能力增强。
左图(使用前):分类结果相对不错,但各类别之间存在一定的误差;
右图(使用后):分类结果比较好,簇内距离变小,簇间距离变大。


(4.3.5)CIoU损失函数
效果:采用CIoU Loss损失函数,使得预测框回归的速度和精度更高一些。
loss优化历程:经典IOU损失 -> GIOU损失(Generalized IoU) -> DIOU损失(Distance IoU) -> CIOU损失
优缺点:
- IoU_Loss:主要考虑检测框和目标框重叠面积。
- GIoU_Loss:在IOU的基础上,解决边界框不重合时的问题。
- DIoU_Loss:在IOU和GIOU的基础上,考虑边界框中心点距离的信息。
- CIoU_Loss:在DIOU的基础上,考虑边界框宽高比的尺度信息。



(4.3.6)DIoU-NMS
在检测结果中,若存在多个检测框的IOU大于置信度阈值
(1)NMS非极大值抑制:只取IoU最大值对应的框。
(2)DIoU-NMS:只取公式计算得到的最大值对应的框。取最高置信度的IoU,并计算最高置信度候选框(M)与其余所有框(Bi)的中心点距离。优点:在有遮挡的情况下识别效果更好。
(3)SOFT-NMS:对于不满足要求,且与最大置信度对应的检测框高度重叠的检测框,不直接删除,而采取降低置信度的方式。优点:召回率更高


五、横空出世:YOLOv5
论文下载:yolov5没有论文
官网代码:https://github.com/ultralytics/yolov5
2020年2月YOLO之父Joseph Redmon宣布退出计算机视觉研究领域。
2020 年 4 月 23 日YOLOv4发布☘️。
2020 年 6 月 10 日YOLOv5发布。
⭐(1)该两个版本的改进都属于多种技术堆积版本,且两个版本差异不大。
(2)一直在更新中,且更新较快(平均2~3个月一次)。
✨(3)yolov5对应的GitHub上有详细的项目说明。但由于v5项目的训练数据集过于庞大,故可以选择自己的数据集 or 小样本数据集学习。
Roboflow:开源自动驾驶数据集。该数据集已经画好边界框;下载格式:YOLO v5 PyTorch。
(5.1)性能表现
yolov5是在COCO数据集上预训练的系列模型,包含5个模型:YOLOv5n、YOLOv5s、YOLOv5m、YOLOv5l、YOLO5x。不同的变体模型使得YOLOv5能很好的在精度和速度中权衡,方便用户选择。


(5.2)网络模型(YOLOv5s)
模块1:CBL-CBL模块由Conv+BN+Leaky_relu激活函数组成。
模块2:Res unit-借鉴ResNet网络中的残差结构,用来构建深层网络,CBM是残差模块中的子模块。
模块3:CSP1_X-借鉴CSPNet网络结构,该模块由CBL模块、Res unint模块以及卷积层、Concate组成而成。
模块4:CSP2_X-借鉴CSPNet网络结构,该模块由卷积层和X个Res unint模块Concate组成而成。
模块5:Focus结构首先将多个slice结果Concat起来,然后将其送入CBL模块中。
模块6:SPP-采用1×1、5×5、9×9和13×13的最大池化方式,进行多尺度特征融合。

(5.2.1)Backbone(特征提取模块)
- (1)Backbone(骨干网络):用于提取图像特征的网络。*常用不是我们自己设计的网络,而是通用网络模型resnet、VGG等。
使用方式: 将通用模型作为backbone时,直接加载预训练模型的参数,再拼接上我们自己的网络。网络训练方法参考迁移学习的微调算法,即对预训练模型进行微调,使其更适合我们自己的任务。- (2)Neck(脖子):在backbone和head之间,是为了更好的利用backbone提取的特征。
- (3)Bottleneck(瓶颈):指输出维度比输入维度小很多,就像由身体到脖子,变细了。经常设置的参数 bottle_num=256,指的是网络输出的数据的维度是256 ,可是输入进来的可能是1024维度的。
- (4)Head(头部):head是获取网络输出内容的网络,利用之前提取的特征,head利用这些特征,做出预测。

Backbone结构主要分成三类:CNNs结构(非轻量级、轻量级)、Transformer结构、CNNs+Transformer结构。

深度学习框架-Backbone汇总(超详细讲解)
❤️ 一、普通(非轻量化)CNNs结构Backbone
- LeNet5:(1998)
- AlexNet:(2012)
- VGG:(2014)
- GoogLeNet(InceptionNet)系列:Inception-v1(GoogleNet): (2015)、Inception-v2 (2015,BN-inception)、Inception-v3 (2015)、Inception-v4: (2017)、Inception-resnet-v2: (2017)
- Resnet: (2016)
- ResNet变种:ResNeXt (2016)、ResNeSt(2020)、Res2Net(2019)、DenseNet (2017)
- DPNet:(2017)
- NasNet:(2018)
- SENet及其变体SKNet:SENet(2017)、SKNet(2019)
- EfficientNet 系列:EfficientNet-V1(2019)、EfficientNet-V2(2021)
- Darknet系列:Darknet-19 (2016, YOLO v2 的 backbone)、Darknet-53 (2018, YOLOv3的 backbone)
- DLA (2018, Deep Layer Aggregation)
❤️ 二、轻量化CNNs结构Backbone
- SqueezeNet:(2016)
- MobileNet-v1:(2017)
- XCeption:(2017, 极致的 Inception)
- MobileNet V2:(2018)
- ShuffleNet-v1:(2018)
- ShuffleNet-v2:(2018)
- MnasNet:(2019)
- MobileNet V3 (2019)
- CondenseNet(2017)
- ESPNet系列:ESPNet (2018)、ESPNetv2 (2018)
- ChannelNets
- PeleeNet
- IGC系列:IGCV1、IGCV2、IGCV3
- FBNet系列:FBNet、FBNetV2、FBNetV3
- GhostNet
- WeightNet
- MicroNet
❤️ 三、 ViT(Vision Transformer )结构Backbone
- ViT-H/14 和 ViT-L/16 (2020)(Vision Transformer,ViT)
- Swin Transformer(2021)
- PVT(2021, Pyramid Vision Transformer)
- MPViT (CVPR 2022,Multi-path Vision Transformer, 多路径 Vision Transformer)
- EdgeViTs (CVPR 2022,轻量级视觉Transformer)
❤️ 四、CNNs+Transformer/Attention结构Backbone
- CoAtNet(#2 2021)
- BoTNet(#1 2021)
(5.2.1)EfficientNet
EfficientNet网络详解
(5.3)改进之处
深入浅出Yolo系列之Yolov5核心基础知识完整讲解
六、昙花一现:YOLOv6
手把手教你运行YOLOv6(超详细)
yolov6与v7相差不到十天,区别不大。
七、谁与争锋:YOLOv7
论文下载:YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object
detectors
代码地址:https://gitcode.net/mirrors/WongKinYiu/yolov7
在项目实战中,只研究yolov5或yolov7对应的项目即可,yolov3不要再研究了。因为现在的torch版本是高版本,而v3当时是低版本。
(7.1)性能表现
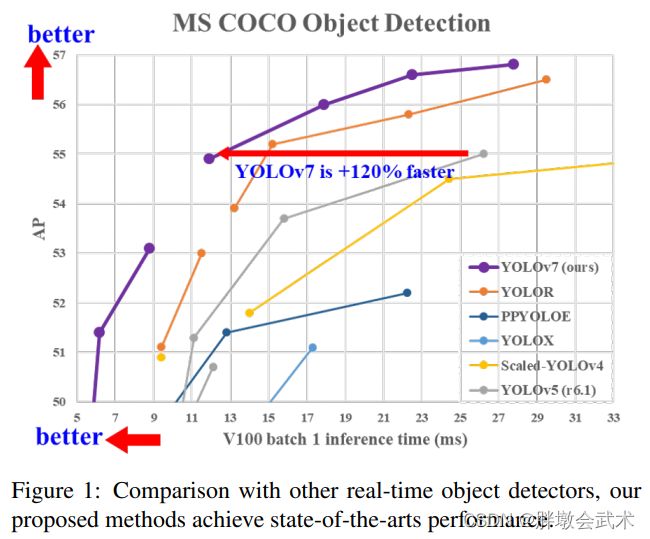

(7.2)网络模型

(7.3)改进之处
(7.3.1)RepVGG(最大改进)
- 2014年:牛津大学著名研究组VGG (Visual Geometry Group), 提出VGGNet。
- 2021年:清华大学、旷视科技以及香港科技大学等机构,基于VGG网络提出了RepVGG网络。
由图可得:RepVGG无论是在精度还是速度上都已经超过了ResNet、EffcientNet以及ResNeXt等网络。

(7.3.1.1)结构重参数化
RepVGG采用结构重参数化方法(structural re-parameterization technique)。
详细过程:
- (1)在训练时,使用ResNet-style的多分支模型(特点:增加模型的表征能力);
- (2)在测试时,转化成VGG-style的单线路模型(特点:速度更快、更省内存并且更加的灵活。)。
过程特点:训练的网络结构和测试的网络结构可以不一样。
核心操作:在测试时,将训练时的多分支模型进行合并得到一条单线路模型,即将1 x 1卷积 + BN(批标准化)与3 x 3卷积进行合并。详见下图。RepVGG网络:结构重参数化 - 详细过程
- (1)将1x1卷积转换成3x3卷积
- (2)将BN和3x3卷积进行融合,转换成3x3卷积
- (3)多分支融合
备注1:yolo的核心是检测速度快,而不是检测精度高。
备注2:在前六个版本的优化后,网络层只留下了3 x 3卷积、1 x 1卷积和BN(每一个网络层之后都进行批标准化)。
备注3:VGG在2014年告诉我们,3 x 3卷积是计算速度最快的,优化最好的。
备注4:黄色模块是激活函数ReLU,蓝色模块是卷积层。
备注5:单支路模型可以节约内存。

(7.3.1.2)将1x1卷积转换成3x3卷积
具体过程:
(1)取1x1卷积(卷积核:1个参数),设置padding=1(即在其周围填补一圈全为零的元素)
(2)设置原始输入的padding=1
(3)输入与卷积核进行卷积操作,得到3x3的卷积层。。
注意:原始输入和1x1卷积都需要设置padding=1。

(7.3.1.3)将BN和3x3卷积进行融合,转换成3x3卷积
通俗来讲:将BN公式拆解为 一元二次方程(y1 = k1* x1 + b1);然后与损失函数(y2 = k2* x2 + b2)进行合并得到新的方程(y3 = k3* x3 + b3)。


(7.3.1.4)多分支融合
具体过程:(1)将1x1卷积 + BN全部转换为3x3卷积,然后与3x3卷积进行合并,得到一个3x3卷积。

(7.3.2)正样本分配策略
主要目的:为了得到更多的正样本。正样本即先验框(anchor),负样本即背景。
具体计算过程分两个步骤:(1)提取anchor;(2)筛选anchor。
具体过程(提取anchor):
- (1)计算先验框的中心点位置
- (2)在当前网格中进行上、下、左、右四个方向的位置偏移,偏移大小为0.5。
- (3)最后取当前网格 + 四个方向的中心点所对应的除当前网格的二个网格。共三个网格作为正样本
具体过程(筛选anchor):
提取满足要求的anchor,去掉匹配度低的anchor(该类anchor无意义)。
- 条件一:候选框和先验框(anchor)的长款比范围:[0.25,4] 。
- 条件二: 候选框和先验框(anchor)的IOU要大于自定义阈值。
- 条件三: 候选框和先验框(anchor)的类别预测损失要大于自定义阈值。
- 条件四: 将以上三个条件进行权重相加,并进行损失排名。 loss = (权重系数1 * 条件一) + (权重系数2 * 条件二) + (权重系数3 * 条件三)


举例:以下是具体过程(筛选anchor)中,条件二的损失计算。
- 备注1:计算真实框(Ground Truth,GT) 对应的候选框数量(损失计算得到的结果):向下取整。
- 备注2:若一个候选框同时和多个anchor高度匹配,则按照损失计算原则,只能匹配损失最小对应的一个anchor。


(7.3.3)相对偏移量计算(yolov5/v7版)


(7.3.4)辅助头(auxiliary head)+主头(lead head)
详细说明请看论文
图5:辅助用粗,头部用细。与常规模型(a)相比,(b)模式具有辅助头。与通常的独立标签分配器©不同,我们提出(d)铅头引导标签分配器和(e)粗至细铅头引导标签分配器。该标签分配器通过前导头预测和地面真实值进行优化,同时得到训练前导头和辅助头的标签。详细的从粗到细的实现方法和约束设计细节将在附录中详细阐述。

参考文献
1.YOLO学习:召回率Recall、精确率Precision、IoU、Map
2.YOLOv1到YOLOv3的演变过程及每个算法详解
3.YOLO系列总结:YOLOv1, YOLOv2, YOLOv3, YOLOv4, YOLOv5, YOLOX
4.YOLO系列详解:YOLOv1、YOLOv2、YOLOv3、YOLOv4、YOLOv5
5.YOLO系列算法精讲:从yolov1至yolov5的进阶之路(2万字超全整理)
6.深入浅出Yolo系列:Yolov3、Yolov4、Yolov5、YoloX(超多-免费数据集)
7.深度学习框架-Backbone汇总(超详细讲解)
8.深入浅出Yolo系列之Yolov5核心基础知识完整讲解
9.YOLOv7 RepVGG网络:结构重参数化 - 详细过程
10.目标检测算法——YOLOV7——详解
实战一:目标检测:教你利用yolov5训练自己的目标检测模型
实战二:认真总结6000字Yolov5保姆级教程(2022.06.28全新版本v6.1)
实战三:利用yolov5实现口罩佩戴检测算法(非常详细)
实战四:YOLOv7(目标检测)入门教程详解—检测,推理,训练
❤️ roboflow官网:开源自动驾驶数据集(Computer Vision Datasets)❤️