FATE —— 二.4.3 使用冻结参数Bert进行情绪分类
在本例中,我们将使用Frozen Parameters Bert构造一个文本分类器,并在IMDB情感分类数据集上进行训练
数据集:IMDB情感
这是一个二进制分类数据集,您可以从这里下载我们的处理数据集:
https://webank-ai-1251170195.cos.ap-guangzhou.myqcloud.com/fate/examples/data/IMDB.csv
并将其放在examples/data文件夹中(或者自己存放文件的地址,代码中需要用到)。
组织数据来自:
https://ai.stanford.edu/~amaas/data/sentiment/
检查数据集
import pandas as pd
df = pd.read_csv('/mnt/hgfs/examples/data/IMDB.csv') # 根据自己的文件位置进行调整
df
from federatedml.nn.dataset.nlp_tokenizer import TokenizerDatasetds = TokenizerDataset(tokenizer_name_or_path="bert-base-uncased")
ds.load('/mnt/hgfs/examples/data/IMDB.csv') # 根据自己的文件位置进行调整from torch.utils.data import DataLoader
dl = DataLoader(ds, batch_size=16)
for i in dl:
break构建Bert分类器
from pipeline.component.nn import save_to_fate%%save_to_fate model bert_.py
import torch as t
from federatedml.nn.model_zoo.pretrained_bert import PretrainedBert
class BertClassifier(t.nn.Module):
def __init__(self, ):
super(BertClassifier, self).__init__()
self.bert = PretrainedBert(pretrained_model_name_or_path='bert-base-uncased', freeze_weight=True)
self.classifier = t.nn.Sequential(
t.nn.Linear(768, 128),
t.nn.ReLU(),
t.nn.Linear(128, 64),
t.nn.ReLU(),
t.nn.Linear(64, 1),
t.nn.Sigmoid()
)
def parameters(self, ):
return self.classifier.parameters()
def forward(self, x):
x = self.bert(x)
return self.classifier(x.pooler_output)model = BertClassifier()import torch as t
from federatedml.nn.homo.trainer.fedavg_trainer import FedAVGTrainer
trainer = FedAVGTrainer(epochs=3, batch_size=16, shuffle=True, data_loader_worker=4)
trainer.local_mode()
trainer.set_model(model)本地测试
opt = t.optim.Adam(model.parameters(), lr=0.005)
loss = t.nn.BCELoss()
# local test
trainer.train(ds, None, opt, loss)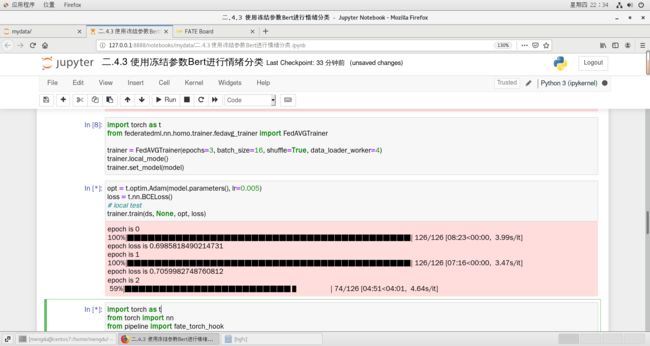
提交pipeline
import torch as t
from torch import nn
from pipeline import fate_torch_hook
from pipeline.component import HomoNN
from pipeline.backend.pipeline import PipeLine
from pipeline.component import Reader, Evaluation, DataTransform
from pipeline.interface import Data, Model
fate_torch_hook(t)
import os
# fate_project_path = os.path.abspath('../../../../')
guest_0 = 10000
host_1 = 9999
pipeline = PipeLine().set_initiator(role='guest', party_id=guest_0).set_roles(guest=guest_0, host=host_1,
arbiter=guest_0)
data_0 = {"name": "imdb", "namespace": "experiment"}
data_path = '/mnt/hgfs/examples/data/IMDB.csv' # 根据自己的文件位置进行调整
pipeline.bind_table(name=data_0['name'], namespace=data_0['namespace'], path=data_path)
pipeline.bind_table(name=data_0['name'], namespace=data_0['namespace'], path=data_path){'namespace': 'experiment', 'table_name': 'imdb'}
reader_0 = Reader(name="reader_0")
reader_0.get_party_instance(role='guest', party_id=guest_0).component_param(table=data_0)
reader_0.get_party_instance(role='host', party_id=host_1).component_param(table=data_0)
reader_1 = Reader(name="reader_1")
reader_1.get_party_instance(role='guest', party_id=guest_0).component_param(table=data_0)
reader_1.get_party_instance(role='host', party_id=host_1).component_param(table=data_0)如果虚拟机没有GPU,这里建议将cuda=True给删除。否则会报错
from pipeline.component.homo_nn import DatasetParam, TrainerParam
model = t.nn.Sequential(
t.nn.CustModel(module_name='bert_', class_name='BertClassifier')
)
# nn_component = HomoNN(name='nn_0',
# model=model,
# loss=t.nn.BCELoss(),
# optimizer = t.optim.Adam(lr=0.001, weight_decay=0.001),
# dataset=DatasetParam(dataset_name='nlp_tokenizer', tokenizer_name_or_path="bert-base-uncased"), # 使用自定义的dataset
# trainer=TrainerParam(trainer_name='fedavg_trainer', epochs=2, batch_size=16, data_loader_worker=8, cuda=True),
# torch_seed=100
# )
nn_component = HomoNN(name='nn_0',
model=model,
loss=t.nn.BCELoss(),
optimizer = t.optim.Adam(lr=0.001, weight_decay=0.001),
dataset=DatasetParam(dataset_name='nlp_tokenizer', tokenizer_name_or_path="bert-base-uncased"), # 使用自定义的dataset
trainer=TrainerParam(trainer_name='fedavg_trainer', epochs=2, batch_size=16, data_loader_worker=8),
torch_seed=100
)这里把pipeline.add_component(reader_0)添加上,否则会报错
pipeline.add_component(reader_0)
pipeline.add_component(reader_1)
pipeline.add_component(nn_component, data=Data(train_data=reader_0.output.data, validate_data=reader_1.output.data))
pipeline.add_component(Evaluation(name='eval_0', eval_type='binary'), data=Data(data=nn_component.output.data))pipeline.compile()
pipeline.fit()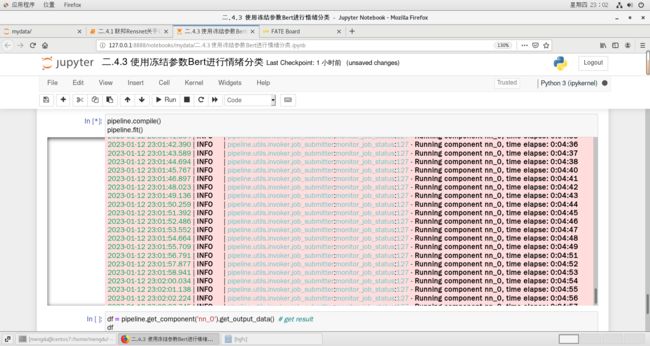
写入并保存
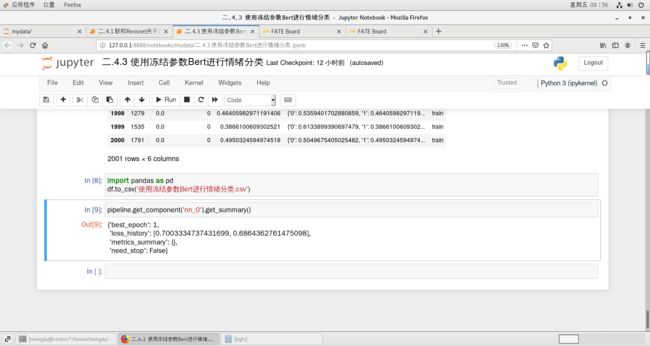
df = pipeline.get_component('nn_0').get_output_data() # get result
df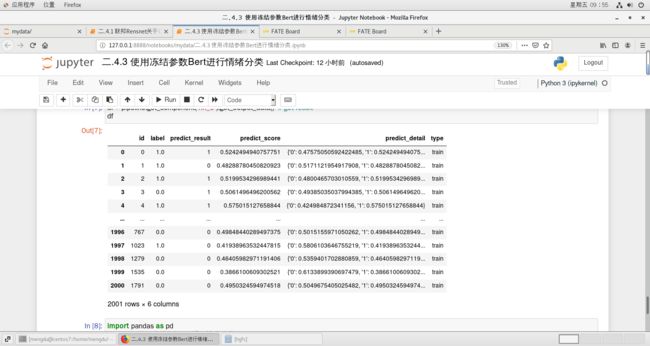
import pandas as pd
df.to_csv('使用冻结参数Bert进行情绪分类.csv')pipeline.get_component('nn_0').get_summary()