hiveSQL基本语句二------常用函数(时间戳、时间间隔、if、case)
查看所有函数
show functions;
查看某一函数
desc function extended from_unixtime;
一、时间戳转化为指定格式的函数from_unixtime
格式:from_unixtime(bigint unixtime,string format)
format
- yyyy-MM-dd hh:mm:ss
- yyyy-MM-dd hh 12小时制
- yyyy-MM-dd HH 24小时制
- yyyy-MM-dd hh:mm
- yyyyMMdd
注意yyyy要小写,千万不要大写*****
select pay_time,from_unixtime(pay_time,'yyyy-MM-dd hh-mm-ss')
from user_trade
where dt = '2019-04-09' limit 1;

二、日期转化为时间戳函数 unix_timestamp
三、时间间隔函数datediff
datediff(string enddate,string startdate)
to_date函数可将格式改为年月日
select user_name,datediff('2019-05-01',to_date(firstactivetime))
from user_info limit 1;

四、日期增加/减少
date_add(string startdate,int days)
date_sub(string startdate,int days)
五、条件函数case when
case when … then …
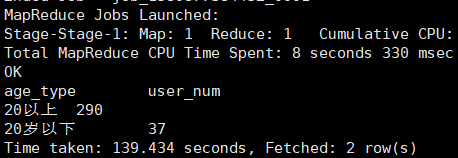
例:20岁以下,20以上用户数
select case when age<20 then '20岁以下'
else '20以上' end as age_type,
count(distinct user_id) as user_num
from user_info
group by case when age<20 then '20岁以下'
else '20以上' end;
六、判断函数if
if(A>0,B,C)
条件满足,结果为B;不满足,结果为C
例:等级大于5及小于5的人数
select if(level>5,'yes','no') as level,
count(distinct user_id) as user_num
from user_info
group by if(level>5,'yes','no');

七、字符串函数—指定目标长度字符串 substr()
substr(string A,int start,int len)
若不指定长度,则截取到最后;
不一定从1开始;
闭区间
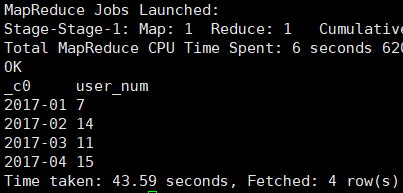
场景:每月新增用户数
select substr(firstactivetime,1,7),
count(distinct user_id) as user_num
from user_info
group by substr(firstactivetime,1,7)
limit 4;
八、如何取出键值对中的值—函数get_json_object(A,’$.B’)
很重要
例:不同手机品牌的用户数
方法一:get_json_object
1、查看数据类型
desc user_info;

extra1是string类型
extra2是map类型
2、查看extra1具体数据格式
select extra1 from user_info limit 1;
–结果
extra1
{“systemtype”: “android”, “education”: “doctor”, “marriage_status”: “1”, “phonebrand”: “VIVO”}
3、函数get_json_object(A,’$.B’)
A 为列名,B为目标
select get_json_object(extra1,'$.phonebrand') as phone_brand,
count(distinct user_id) as user_num
from user_info
group by get_json_object(extra1,'$.phonebrand') limit 2;
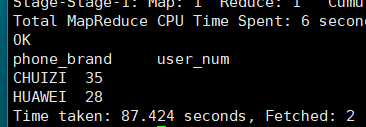
方法二:map类型,直接取A[‘B’]
1、查看extra2具体数据格式
select extra2 from user_info limit 1;
–结果
extra2
{“systemtype”:“android”,“education”:“doctor”,“marriage_status”:“1”,“phonebrand”:“VIVO”}
2、A[‘B’],A为列名,B为目标值
select extra2['phonebrand'] as phone_brand,
count(distinct user_id) as user_num
from user_info
group by extra2['phonebrand'] limit 2;
练习
先看下结构:
hive (kaikeba)> select * from user_info limit 1;
OK
user_info.user_id user_info.user_name user_info.sex user_info.age user_info.city user_info.firstactivetime user_info.level user_info.extra1 user_info.extra2
10001 Abby female 38 hangzhou 2018-04-13 01:06:07 2 {“systemtype”: “android”, “education”: “doctor”, “marriage_status”: “1”, “phonebrand”: “VIVO”} {“systemtype”:“android”,“education”:“doctor”,“marriage_status”:“1”,“phonebrand”:“VIVO”}
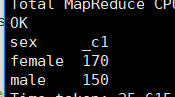
作业1:激活天数距今超过300天的男女分布情况(user_info)
select sex,count(distinct user_name)
from user_info
where datediff('2020-02-02',to_date(firstactivetime)) >300
group by sex;
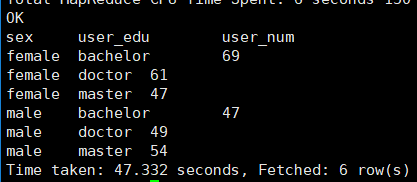
作业2:不同性别、教育程度的分布情况(user_info)
select sex,get_json_object(extra1,'$.education') as user_edu,count(user_name) as user_num
from user_info
group by sex,get_json_object(extra1,'$.education');
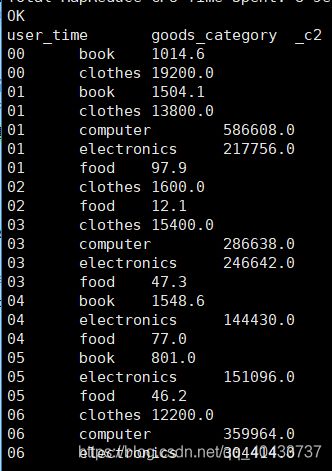
作业3:2019.1.1到2019.4.30,每个时段的不同种类购买金额分布(user_trade)
开始想复杂了,想把时段按照上午下午晚上划分的。分组的时候将时段和种类一起分组
记住有分组想查询其他结果就要聚合,一定一定
另外时间格式用HH,24小时制
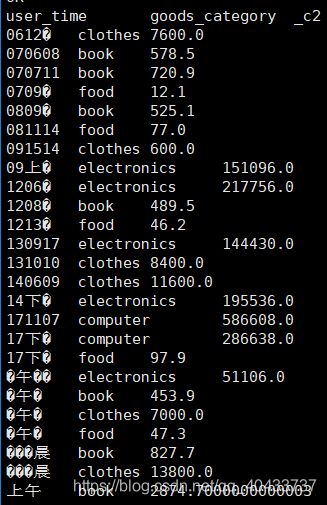
select substr(from_unixtime(pay_time,'yyyy-MM-dd HH'),12) as user_time,goods_category,sum(pay_amount)
from user_trade
where dt between '2019-01-01' and '2019-04-30'
group by substr(from_unixtime(pay_time,'yyyy-MM-dd HH'),12),goods_category;
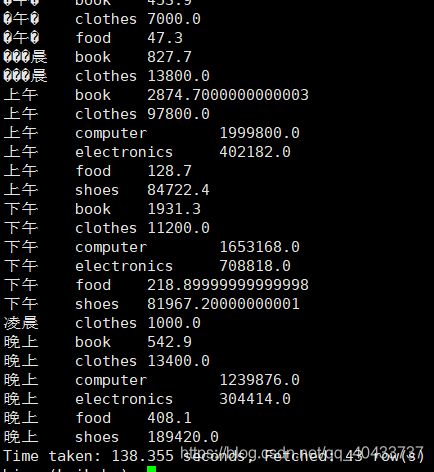
另外想把时段按照上午下午晚上凌晨划分,结果有一部分未正确显示,后续看看如何优化?
select case when substr(from_unixtime(pay_time,'yyyy-MM-dd HH'),12) >=18 and substr(from_unixtime(pay_time,'yyyy-MM-dd HH'),12) <=23 then '晚上'
when substr(from_unixtime(pay_time,'yyyy-MM-dd HH'),12) >=0 and substr(from_unixtime(pay_time,'yyyy-MM-dd HH'),12) <=5 then '凌晨'
when substr(from_unixtime(pay_time,'yyyy-MM-dd HH'),12) >=6 and substr(from_unixtime(pay_time,'yyyy-MM-dd HH'),12) <=11 then '上午'
else '下午' end as user_time,
goods_category,sum(pay_amount)
from user_trade
where dt between '2019-01-01' and '2019-04-30'
group by case when substr(from_unixtime(pay_time,'yyyy-MM-dd HH'),12) >=18 and substr(from_unixtime(pay_time,'yyyy-MM-dd HH'),12) <=23 then '晚上'
when substr(from_unixtime(pay_time,'yyyy-MM-dd HH'),12) >=0 and substr(from_unixtime(pay_time,'yyyy-MM-dd HH'),12) <=5 then '凌晨'
when substr(from_unixtime(pay_time,'yyyy-MM-dd HH'),12) >=6 and substr(from_unixtime(pay_time,'yyyy-MM-dd HH'),12) <=11 then '上午'
else '下午' end,
goods_category;