Python爬虫第一课:了解爬虫与浏览器原理

fightingoyo
 于 2020-02-26 17:55:46 发布
于 2020-02-26 17:55:46 发布
 1661
1661

 收藏 12
收藏 12
于 2020-02-26 17:55:46 发布
1661
收藏 12
当我们要将网页的信息保存到本地时,通常是打开网页,然后通过复制网页的文本,接着粘贴到本地
从上图中,只有我们和浏览器。但是实际上还有一方,那就是「服务器」。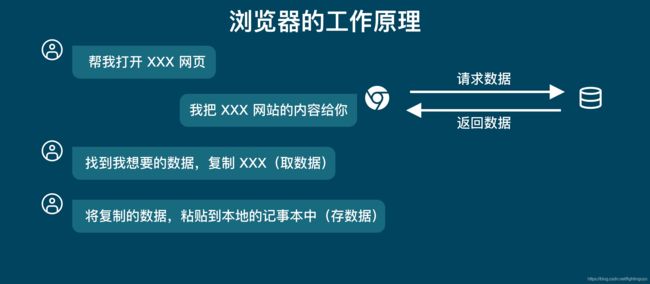
所以当你用浏览器去浏览网页的时候,都是浏览器去向服务器请求数据,服务器返回数据给浏览器的这样一个过程。

当浏览器收到服务器返回的数据时,它会先「解析数据」,把数据变成人能看得懂的网页页面。
当我们浏览这个网页的时候,我们会「筛选数据」,找出我们需要的数据,比如说一篇文章、一份论文等。然后我们把这一篇文章,或者是一篇论文保存到本地,这就叫做「存储数据」。
当你要去某个网站批量下载文章,如果单纯的使用浏览器的话,那么你就得打开浏览器,输入网址,页面加载完成后,寻找对应文章,一个一个的去点下载按钮。
如果这个过程使用爬虫来处理,那么爬虫就会代替我们去服务器请求数据,然后爬虫帮我们去解析数据,然后按照我们设定好的规则批量把文章下载下来,存储到特定文件中。

对于爬虫来说,「请求」和「响应」都是去「获取数据」。他们是一个步骤的两个部分。所以把他们统一之后,爬虫的工作原理就是下图:

这是爬虫的第一步:获取数据。
在电脑中安装requests库的方法如下:
- 在Mac电脑里打开终端软件(terminal),输入pip3 install requests,然后点击enter即可;
- Windows电脑里叫命令提示符(cmd),输入pip install requests 即可。
import requests
#在使用前需要先通过 import 来引入 requests 库
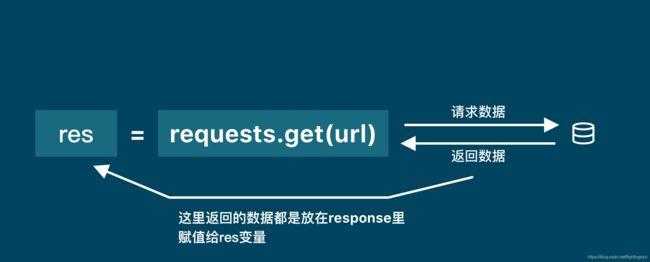
res = requests.get('URL')
#我们通过调用requests库中的get()方法来获取数据,这个方法需要一个参数,这个参数就是你需要请求的网址。当请求得到「响应」时,服务器返回的数据就被赋值到 res 这个变量上面
import requests
response = requests.get(‘https://xiaoke.kaikeba.com/example/gexu/tengwanggexu.txt’)
Python是一门面向对象编程的语言,在面向对象的世界中,一切皆可为对象。在这里Response也是一个对象,他有自己的属性和方法。在我们知道一个数据是什么对象的时候,就可以去使用它对应的属性和方法。
刚刚通过requests.get()拿到的就是一个response对象。
import requests
response = requests.get(‘https://xiaoke.kaikeba.com/example/gexu/tengwanggexu.txt’)
print(type(response)) # 打印response的数据类型
# 输出结果:
<class ‘requests.models.Response’>
代码运行结果显示,res是一个对象,它是一个requests.models.Response类。


import requests
response = requests.get(‘https://xiaoke.kaikeba.com/example/gexu/tengwanggexu.txt’)
print(response.status_code)
# 输出结果:
200
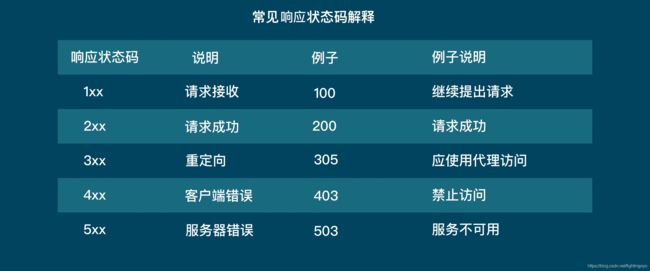
这段代码把response的status_code打印出来,如果是200,那么就意味着这个请求是成功的。服务器收到了我们的请求,并返回了数据给我们。

import requests
# 发出请求,并把返回的结果放在变量response中
response = requests.get(‘http://b-ssl.duitang.com/uploads/blog/201501/20/20150120134050_BXihr.jpeg’)
# 把Reponse对象的内容以二进制数据的形式返回
pic = response.content
# 新建了一个文件jay.jpeg,这里的文件没加路径,它会被保存在程序运行的当前目录下
# 图片内容需要以二进制wb读写。
photo = open(‘jay.jpeg’,‘wb’)
# 获取pic的二进制内容
photo.write(pic)
# 关闭文件
photo.close()
# 输出结果为:我们能在本地得到一张周杰伦的图片
import requests
# 用request去下载《滕王阁序》,将返回的 response 对象保存到 res 变量中
response = requests.get(‘https://xiaoke.kaikeba.com/example/gexu/tengwanggexu.txt’)
# 把Response对象的内容以字符串的形式返回
novel = response.text
# 打印变量novel
print(novel)
# 输出结果为整篇《滕王阁序》
import requests
# 用request去下载《滕王阁序》,将返回的 response 对象保存到 res 变量中
response = requests.get('https://xiaoke.kaikeba.com/example/gexu/tengwanggexu.txt')
# 把Response对象的内容以字符串的形式返回
novel = response.text
# 将《滕王阁序》保存到本地
with open('滕王阁序.txt','w') as twg:
twg.write(novel)
import requests
# 用request去下载《滕王阁序》,将返回的 response 对象保存到 res 变量中
response = requests.get('https://xiaoke.kaikeba.com/example/gexu/tengwanggexu.txt')
# 把Response对象的内容以字符串的形式返回
response.encoding='gbk'
novel = response.text
print(novel)
以上经过encoding之后的novel打印出来为一堆乱码。
这是因为所有的文本数据都有编码类型。这篇文章的编码格式原本是’utf-8’。一般来说,requests库会帮我们自动去判断编码类型,不需要手动指定。
但是如果遇到一些需要自己去指定数据的编码类型的情况,就可以使用“response.encoding”去改变“response”拿到的数据的编码类型。我们手动指定了编码类型为‘gbk’而不是‘utf-8’。所以导致了编码类型不一致,出现了乱码!
再将更改为’gbk‘的编码变更回’utf-8’,这样就能正常打印输出了。
import requests
# 用request去下载《滕王阁序》,将返回的 response 对象保存到 res 变量中
response = requests.get('https://xiaoke.kaikeba.com/example/gexu/tengwanggexu.txt')
# 把Response对象的内容以字符串的形式返回
response.encoding='gbk'
response.encoding='utf-8'
novel = response.text
print(novel)

浏览器工作原理
爬虫工作原理

爬虫的四个步骤

requests库

import requests
# 使用requests.get()获取数据
response = requests.get(‘https://xiaoke.kaikeba.com/example/gexu/shudaonan.txt’)
# 打印数据请求的状态
print(response.status_code)
# 将返回的数据以text形式赋值给变量
article = response.text
# 打印articel
print(article)
import requests
# 使用requests.get()获取数据
response = requests.get(‘https://xiaoke.kaikeba.com/example/gexu/shudaonan.txt’)
# 打印数据请求的状态
print(response.status_code)
# 将返回的数据以text形式赋值给变量
article = response.text
# 创建"蜀道难.txt"的文件,并以写入模式打开
sdn = open(‘蜀道难.txt’,‘w’)
# 将网站返回的内容写入txt文件中
sdn.write(article)
# 关闭文件
sdn.close()
import requests
# 使用requests.get()获取数据
response = requests.get(‘https://ss3.bdstatic.com/70cFv8Sh_Q1YnxGkpoWK1HF6hhy/it/u=21565698,717792087&fm=26&gp=0.jpg’)
# 将数据以二进制的形式存储到变量中
pic = response.content
# 以"彭于晏.jpg"创建文件,并以’wb’模式打开
with open(‘彭于晏.jpg’,‘wb’) as myfile:
# 将图片写入文件中
myfile.write(pic)
 fightingoyo
fightingoyo


 5
5




 12
12

 1
1
 复制链接
复制链接
 3万+
3万+
 写评论
写评论
 努力的小bai 热评
1万+
努力的小bai 热评
1万+
先看后赞,养成习惯。
点赞收藏,人生辉煌。
讲解我们的爬虫之前,先概述关于爬虫的简单概念(毕竟是零基础教程)
爬虫
网络爬虫(又被称为网页蜘蛛,网络机器人)就是模拟浏览器发送网络请求,接收请求响应,一种按照一定的规则,自动地抓取互联网信息的程序。
原则上,只要是浏览器(客户端)能做的事情,爬虫都能够做。
76
...了解 新建隐身窗口的目的
了解 chrome中network的使用
了解 寻找登录接口的方法
1 新建隐身窗口
浏览器中直接打开网站,会自动带上之前网站时保存的cookie,但是在爬虫中首次获取页面是没有携带cookie的,这种情况如何解决呢?
使用隐身窗口,首次打开网站,不会带上cookie,能够观察页面的获取情况,包括对方服务器如何设置cookie在本地
2 chrome中network的更多功能
2.1 Perserve log
默认情况下,页面
549
1058
第7部将复制的jspath 黏贴到控制台加一个.href(就是下面的代码)这样变得到了一个下载链接
document.querySelector(“#jishu > div > ul > li:nth-child(2) > div > span.xl > a”).href
分析此代码可以看出 li:
1259
f = open(pat…
2万+
爬取某网 response= requests.get(“http://www.xxxxx.com/“)
我们都知道response有 text 和 content 这两个property, 它们都是指响应内容,但是又有区别。我们从doc中可以看到:
text的d…
129
4399
这是一篇详细介绍Python爬虫入门的教程,从实战出发,适合初学者。读者只需在阅读过程紧跟文章思路,理清相应的实现代码,30 分钟即可学会编写简单的 Python 爬虫。
这篇 Python 爬虫教程主要讲解以下 5 部分内容:
了解网页;
使用 requests 库抓取网站数据;
使用 Beautiful S…
3172
从现在开始,你要去争取属于你的一切,格局、身材、思维、胆识、人脉、能力以及成熟和自信,要有野心,不负众望。
你要知道,有钱能治愈一切自卑,光善良没有用,你得优秀。
藏好软弱,世界大雨滂沱,万物苟且而活,无人会为你背负更多,除了坚强没有退路!
了解新建无痕窗口的目的
了解chrome中network的使用
了解寻找登录接口的方法
一、新建无痕窗口
浏览器中直接打开网站,会自动带上之前网站保存的cookie,但在爬虫中首次获取页面是没有携带cookie的,这种情况就要用到无痕窗口
1324
72
640
url = ‘https://c.y.qq.com/soso/fcgi-bin/client_search_cp’#要爬取的网址的headers
wb=openpyxl.Workbook()#利用openpyxl.W…
1431
Windows环境下运行,需要在命令提示符内运行代码:pip install bs4
MacOS环境下需要输入pip3 install BeautifulSoup4
requests库帮我们搞定了爬虫第1步——获取数据。
HTML知识,则有助于我们解析和提取网页源代码中的数据。
本次,则掌握如何使用BeautifulSoup解析和提取网页中的数据。
…
1109
python爬虫基础01
我们可以通过爬虫来从网站上爬取到自己想要的数据。我使用的爬虫是Pycharm+anaconda。想要爬取数据,首先你得python环境和相关的IDE,这里不多赘述。
python爬虫的原理知识
python爬虫的工作原理:
爬虫的四个步骤:
获取数据。爬虫会拿到我们要它去爬的网址,像服务器发出请求,获得服务器返回的数据。
解析数据。爬虫会将服务器返回的数据转换成人能看懂的样式。
筛选数据。爬虫会.
804
2630
目录
前言
requests如何解码(encoding)
解决思路
终极工具类
前言
相信大家在使用requests模块在抓取网页时,有时会遇到类似好å�¬ç��é�³ä¹�ï¼�好ç��ç��格式的编码,很是头疼。
如何解决这种问题呢?下面来看一下requests解码方式
requests如何解码(encoding)
直接来看源码:
当调用r.text方法时,其内部是如何实现转码过程的
从图片中可以看出调用流程
1.首先获取self.
2万+










 400-660-0108
400-660-0108  [email protected]
[email protected]  在线客服
在线客服  公安备案号11010502030143 12088 9637 8986 8972 7785
公安备案号11010502030143 12088 9637 8986 8972 7785
打赏作者
fightingoyo
你的鼓励将是我创作的最大动力
 获取中
获取中
您的余额不足,请更换扫码支付或充值
打赏作者
点击重新获取


 扫码支付
扫码支付




 到【灌水乐园】发言
到【灌水乐园】发言
weixin_43840345: pivot_table中有index有几个就对应有几层分类汇总
weixin_43840345: 大佬,有没有函数可以是实现多层分类汇总,感觉使用循环叠加会很麻烦
爱可劳特: 非常感谢博主,看了真的解了我得问题
python_xiaofeng: 收藏了。我是需要列索引是多层索引,不过方法是通用的,只是这里的index换成columns就可以了。
m0_51467506: 没有找到seaborn-data文件夹