【代码分析】TensorRT sampleMNIST 详解
目录
前言
代码分析
Main入口
网络构建(build)阶段
网络推理(infer) 阶段
释放资源
前言
TensorRT 的”hello world“ 程序sampleMNIST是众多TensorRT初学者很好的起点,本文旨在详细分析sampleMNIST的代码,从实践出发帮助理解TensorRT的相关概念、与cuda的关系、以及核心API的使用。
代码分析
sampleMNIST的github 代码参考link: https://github.com/NVIDIA/TensorRT/blob/release/6.0/samples/opensource/sampleMNIST/sampleMNIST.cpp
程序的主要流程分为 main与程序输入参数初始化 -> 网络构建 -> 网络推理 -> 释放资源结束 这几个阶段,下面逐个阶段分析代码
Main入口
void printHelpInfo()
{
std::cout
<< "Usage: ./sample_mnist [-h or --help] [-d or --datadir=] [--useDLACore=]\n";
std::cout << "--help Display help information\n";
std::cout << "--datadir Specify path to a data directory, overriding the default. This option can be used "
"multiple times to add multiple directories. If no data directories are given, the default is to use "
"(data/samples/mnist/, data/mnist/)"
<< std::endl;
std::cout << "--useDLACore=N Specify a DLA engine for layers that support DLA. Value can range from 0 to n-1, "
"where n is the number of DLA engines on the platform."
<< std::endl;
std::cout << "--int8 Run in Int8 mode.\n";
std::cout << "--fp16 Run in FP16 mode.\n";
}
int main(int argc, char** argv)
{
samplesCommon::Args args;
bool argsOK = samplesCommon::parseArgs(args, argc, argv); - main函数开始获取程序的输入参数,允许指定caffe模型的文件目录、使用DLA engine的数目、int8或者fp16的模式,参考printHelpInfo()函数
samplesCommon::CaffeSampleParams initializeSampleParams(const samplesCommon::Args& args)
{
samplesCommon::CaffeSampleParams params;
if (args.dataDirs.empty()) //!< Use default directories if user hasn't provided directory paths
{
params.dataDirs.push_back("data/mnist/");
params.dataDirs.push_back("data/samples/mnist/");
}
else //!< Use the data directory provided by the user
{
params.dataDirs = args.dataDirs;
}
params.prototxtFileName = locateFile("mnist.prototxt", params.dataDirs);
params.weightsFileName = locateFile("mnist.caffemodel", params.dataDirs);
params.meanFileName = locateFile("mnist_mean.binaryproto", params.dataDirs);
params.inputTensorNames.push_back("data");
params.batchSize = 1;
params.outputTensorNames.push_back("prob");
params.dlaCore = args.useDLACore;
params.int8 = args.runInInt8;
params.fp16 = args.runInFp16;
return params;
}
......
int main(int arg, char** arg)
{
......
samplesCommon::CaffeSampleParams params = initializeSampleParams(args);- 根据程序运行参数生成CaffeSampleParams实例,包括配置caffe模型的默认目录、minist的proto文件、caff模型文件、binary proto文件,配置minist深度学习网络的input Tensor名字为data,output Tensor名字为prob,batch size为1,根据用户的输入参数来配置是由需要DLA Engine,是否运行在Int8 / FP16模式
class SampleMNIST
{
template
using SampleUniquePtr = std::unique_ptr;
public:
SampleMNIST(const samplesCommon::CaffeSampleParams& params)
: mParams(params)
......
int main(int argc, char** argv)
{
......
SampleMNIST sample(params);
gLogInfo << "Building and running a GPU inference engine for MNIST" << std::endl; - 通过CaffeSampleParams作为配置参数来构造SampleMNIST对象,将配置参数保存到mParams中
int main(int argc, char** argv)
{
......
if (!sample.build())
{
return gLogger.reportFail(sampleTest);
}通过SampleMNIST对象来创建MNIST深度学习网络,下面开始详细分析网络构建阶段的build方法
网络构建(build)阶段
bool SampleMNIST::build()
{
auto builder = SampleUniquePtr(nvinfer1::createInferBuilder(gLogger.getTRTLogger()));
if (!builder)
{
return false;
}
auto network = SampleUniquePtr(builder->createNetwork());
if (!network)
{
return false;
}
auto config = SampleUniquePtr(builder->createBuilderConfig());
if (!config)
{
return false;
}
auto parser = SampleUniquePtr(nvcaffeparser1::createCaffeParser());
if (!parser)
{
return false;
}
constructNetwork(parser, network);
- TensorRT使用的标准流程即通过Logger创建IBuilder,通过IBuilder创建INetworkDefinition,通过INetworkDefinition创建IBuilderConfig,再创建用于解析Caffe模型的ICafferParser,然后调用constructNetwork通过ICafferParser对象分析caffe模型,通过INetworkDefinition对象创建可以被TensorRT优化和运行的网络
void SampleMNIST::constructNetwork(
SampleUniquePtr& parser, SampleUniquePtr& network)
{
const nvcaffeparser1::IBlobNameToTensor* blobNameToTensor = parser->parse(
mParams.prototxtFileName.c_str(), mParams.weightsFileName.c_str(), *network, nvinfer1::DataType::kFLOAT);
for (auto& s : mParams.outputTensorNames)
{
network->markOutput(*blobNameToTensor->find(s.c_str()));
}
// add mean subtraction to the beginning of the network
nvinfer1::Dims inputDims = network->getInput(0)->getDimensions();
mMeanBlob
= SampleUniquePtr(parser->parseBinaryProto(mParams.meanFileName.c_str()));
nvinfer1::Weights meanWeights{nvinfer1::DataType::kFLOAT, mMeanBlob->getData(), inputDims.d[1] * inputDims.d[2]};
// For this sample, a large range based on the mean data is chosen and applied to the head of the network.
// After the mean subtraction occurs, the range is expected to be between -127 and 127, so the rest of the network
// is given a generic range.
// The preferred method is use scales computed based on a representative data set
// and apply each one individually based on the tensor. The range here is large enough for the
// network, but is chosen for example purposes only.
float maxMean
= samplesCommon::getMaxValue(static_cast(meanWeights.values), samplesCommon::volume(inputDims));
auto mean = network->addConstant(nvinfer1::Dims3(1, inputDims.d[1], inputDims.d[2]), meanWeights);
mean->getOutput(0)->setDynamicRange(-maxMean, maxMean);
network->getInput(0)->setDynamicRange(-maxMean, maxMean);
auto meanSub = network->addElementWise(*network->getInput(0), *mean->getOutput(0), ElementWiseOperation::kSUB);
meanSub->getOutput(0)->setDynamicRange(-maxMean, maxMean);
network->getLayer(0)->setInput(0, *meanSub->getOutput(0));
samplesCommon::setAllTensorScales(network.get(), 127.0f, 127.0f);
} - 通过parser->parse方法分析caffe的模型和权重文件,构建network并返回可以通过名字查找数据ITensor的对象blobNameToTensor
- 通过blobNameToTensor->find方法找到输入参数中指定的网络output ITensor对象,并通过network->markOutput标记它为网络的Output ITensor
- 通过network->getInput(0)->getDimensions()找到网络的input ITensor对象并获取它的Dims维度对象
- 通过parser->parseBinaryProto解析caffe权重平均值文件并包装为IBinaryProtoBlob对象
- 创建Input的平均权重meanWeights,该权重的数据从mMeanBlob->getData()获得,数据个数是inputDims.d[1] * inputDims.d[2]
- 如下图所示为网络的Input做一个范围限制处理,包括
- 通过network->addConstant方法创建一个IConstant Layer,该Layer的input是个3维Dims3对象
- 通过network->addElementWise方法创建一个IElementWise Layer,将原网络的Input和IConstant Layer的output作为Input求相减
- 最后通过network->getLayer(0)->setInput替换原网络的Input为IElementWise Layer的output,完成对原网络Input的范围限制处理
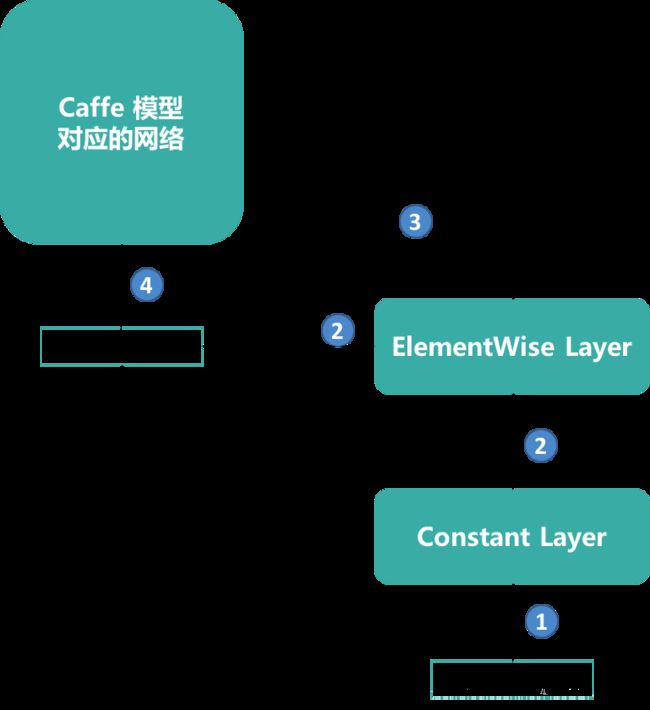 替换原网络的Input做范围限制处理
替换原网络的Input做范围限制处理
bool SampleMNIST::build()
{
......
builder->setMaxBatchSize(mParams.batchSize);
config->setMaxWorkspaceSize(16_MiB);
config->setFlag(BuilderFlag::kGPU_FALLBACK);
config->setFlag(BuilderFlag::kSTRICT_TYPES);
if (mParams.fp16)
{
config->setFlag(BuilderFlag::kFP16);
}
if (mParams.int8)
{
config->setFlag(BuilderFlag::kINT8);
}
samplesCommon::enableDLA(builder.get(), config.get(), mParams.dlaCore);
mEngine = std::shared_ptr(
builder->buildEngineWithConfig(*network, *config), samplesCommon::InferDeleter());
if (!mEngine)
return false;
assert(network->getNbInputs() == 1);
mInputDims = network->getInput(0)->getDimensions();
assert(mInputDims.nbDims == 3);
return true;
} - constructNetwork函数执行完毕后,通过builder设置程序运行参数中的batchSize
- 通过config设置每一层Layer的内存大小和相关FLAG
- 通过enableDLA函数设置是否适用NV的DeepLearn Accelerator做硬件加速
- 通过network和config对象创建ICudaEngine对象用户后续的推理过程
- 最后确定network的input个数只有1个,input的维度为3维
网络推理(infer) 阶段
bool SampleMNIST::infer()
{
// Create RAII buffer manager object
samplesCommon::BufferManager buffers(mEngine, mParams.batchSize);
auto context = SampleUniquePtr(mEngine->createExecutionContext());
if (!context)
{
return false;
}
// Pick a random digit to try to infer
srand(time(NULL));
const int digit = rand() % 10;
// Read the input data into the managed buffers
// There should be just 1 input tensor
assert(mParams.inputTensorNames.size() == 1);
if (!processInput(buffers, mParams.inputTensorNames[0], digit))
{
return false;
}
.....
int main(int argc, char** argv)
{
......
if (!sample.infer())
{
return gLogger.reportFail(sampleTest);
} - main函数执行完build函数后,通过infer函数开始做网络推理
- infer函数通过帮助类构建了BufferManager,用户创建和管理host与device的memory,如下图所示
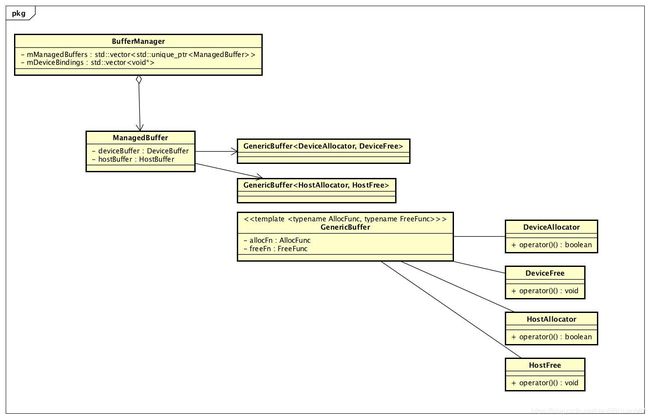 BufferManager 主要类图
BufferManager 主要类图
- 模板类GenericBuffer通过模板参数AllocFunc和FreeFunc来指定Host和Device分配存储的类型,如下代码所示,DeviceAllocator/DeviceFree类使用了cudaMalloc/cudaFree方法从GPU Device分配和释放存储,HostAllocator/HostFree则时候用malloc/free方法从CPU Device分配和释放存储
class DeviceAllocator
{
public:
bool operator()(void** ptr, size_t size) const
{
return cudaMalloc(ptr, size) == cudaSuccess;
}
};
class DeviceFree
{
public:
void operator()(void* ptr) const
{
cudaFree(ptr);
}
};
......
class HostAllocator
{
public:
bool operator()(void** ptr, size_t size) const
{
*ptr = malloc(size);
return *ptr != nullptr;
}
};
class HostFree
{
public:
void operator()(void* ptr) const
{
free(ptr);
}
};- ManagerBuffer对象通过配对的deviceBuffer和hostBuffer来管理Device和Host 存储
BufferManager(std::shared_ptr engine, const int& batchSize,
const nvinfer1::IExecutionContext* context = nullptr)
: mEngine(engine)
, mBatchSize(batchSize)
{
// Create host and device buffers
for (int i = 0; i < mEngine->getNbBindings(); i++)
{
auto dims = context ? context->getBindingDimensions(i) : mEngine->getBindingDimensions(i);
size_t vol = context ? 1 : static_cast(mBatchSize);
nvinfer1::DataType type = mEngine->getBindingDataType(i);
int vecDim = mEngine->getBindingVectorizedDim(i);
if (-1 != vecDim) // i.e., 0 != lgScalarsPerVector
{
int scalarsPerVec = mEngine->getBindingComponentsPerElement(i);
dims.d[vecDim] = divUp(dims.d[vecDim], scalarsPerVec);
vol *= scalarsPerVec;
}
vol *= samplesCommon::volume(dims);
std::unique_ptr manBuf{new ManagedBuffer()};
manBuf->deviceBuffer = DeviceBuffer(vol, type);
manBuf->hostBuffer = HostBuffer(vol, type);
mDeviceBindings.emplace_back(manBuf->deviceBuffer.data());
mManagedBuffers.emplace_back(std::move(manBuf));
}
} - BufferManager对象则管理多个ManagerBuffer,保存每个ManagerBuffer中deviceBuffer对应的设备存储器指针到DeviceBindering
- BufferManager的构造函数可以看到,通过mEngine->getNbBindings()遍历当前网络的所有Input/Output(此处有个细节,即遍历的index i和Tensor的名字是有一一对应关系的,即通过Tensor的名字查找到的Binding index == 对应的index i ),对每个Input/Output获得它的维度dims和数据类型type,计算Input/Output的ITensor数据需要的存储器容量vol,通过构造ManagerBuffer的DeviceBuffer和HostBuffer对象来分配Device和Host存储(用于后续CPU Host端输入数据到GPU Device端),再将Device的数据指针保存到DeviceBindering,将ManagerBuffer保存到BufferManager的队列中,最终通过BufferManager获得了所有Input/Output的Device和Host 存储空间
bool SampleMNIST::infer()
{
......
// Pick a random digit to try to infer
srand(time(NULL));
const int digit = rand() % 10;
// Read the input data into the managed buffers
// There should be just 1 input tensor
assert(mParams.inputTensorNames.size() == 1);
if (!processInput(buffers, mParams.inputTensorNames[0], digit))
{
return false;
}
......
bool SampleMNIST::processInput(
const samplesCommon::BufferManager& buffers, const std::string& inputTensorName, int inputFileIdx) const
{
const int inputH = mInputDims.d[1];
const int inputW = mInputDims.d[2];
// Read a random digit file
srand(unsigned(time(nullptr)));
std::vector fileData(inputH * inputW);
readPGMFile(locateFile(std::to_string(inputFileIdx) + ".pgm", mParams.dataDirs), fileData.data(), inputH, inputW);
// Print ASCII representation of digit
gLogInfo << "Input:\n";
for (int i = 0; i < inputH * inputW; i++)
{
gLogInfo << (" .:-=+*#%@"[fileData[i] / 26]) << (((i + 1) % inputW) ? "" : "\n");
}
gLogInfo << std::endl;
float* hostInputBuffer = static_cast(buffers.getHostBuffer(inputTensorName));
for (int i = 0; i < inputH * inputW; i++)
{
hostInputBuffer[i] = float(fileData[i]);
}
return true;
} - 有了 BufferManager后通过processInput函数来获取Input数据,通过随机构建文件名的方式readPGMFfile 读取Input的数据
- 如下代码所示,通过buffers.getHostBuffer(inputTensorName) 根据Input Tensor的名字找到对应的Binding index,进而找到对应的HostBuffer获得CPU Host端的存储指针
- 通过inputH*inputW 计算input数据的尺寸、遍历input数据,将input数据从文件中读取到CPU 端的存储器中( hostInputBuffer[i] = float(fileData[i]); )
void* getDeviceBuffer(const std::string& tensorName) const
{
return getBuffer(false, tensorName);
}
void* getHostBuffer(const std::string& tensorName) const
{
return getBuffer(true, tensorName);
}
......
void* getBuffer(const bool isHost, const std::string& tensorName) const
{
int index = mEngine->getBindingIndex(tensorName.c_str());
if (index == -1)
return nullptr;
return (isHost ? mManagedBuffers[index]->hostBuffer.data() : mManagedBuffers[index]->deviceBuffer.data());
}
bool SampleMNIST::infer()
{
......
// Create CUDA stream for the execution of this inference.
cudaStream_t stream;
CHECK(cudaStreamCreate(&stream));
// Asynchronously copy data from host input buffers to device input buffers
buffers.copyInputToDeviceAsync(stream);
......- 通过cudaStreamCreate 创建cuda stream用于GPU Device上做并行计算流
- 通过buffers.copyInputToDeviceAsync 将processInput中读取的Input数据从CPU 端异步传送到GPU Device端,如下代码所示copyInputToDeviceAsync最终会通过cudeMemcpyAsync方法结合CPU -> GPU还是GPU -> CPU的方向来异步传送数据
void copyInputToDeviceAsync(const cudaStream_t& stream = 0)
{
memcpyBuffers(true, false, true, stream);
}
......
void memcpyBuffers(const bool copyInput, const bool deviceToHost, const bool async, const cudaStream_t& stream = 0)
{
for (int i = 0; i < mEngine->getNbBindings(); i++)
{
void* dstPtr
= deviceToHost ? mManagedBuffers[i]->hostBuffer.data() : mManagedBuffers[i]->deviceBuffer.data();
const void* srcPtr
= deviceToHost ? mManagedBuffers[i]->deviceBuffer.data() : mManagedBuffers[i]->hostBuffer.data();
const size_t byteSize = mManagedBuffers[i]->hostBuffer.nbBytes();
const cudaMemcpyKind memcpyType = deviceToHost ? cudaMemcpyDeviceToHost : cudaMemcpyHostToDevice;
if ((copyInput && mEngine->bindingIsInput(i)) || (!copyInput && !mEngine->bindingIsInput(i)))
{
if (async)
CHECK(cudaMemcpyAsync(dstPtr, srcPtr, byteSize, memcpyType, stream));
else
CHECK(cudaMemcpy(dstPtr, srcPtr, byteSize, memcpyType));
}
}
}
bool SampleMNIST::infer()
{
......
// Asynchronously enqueue the inference work
if (!context->enqueue(mParams.batchSize, buffers.getDeviceBindings().data(), stream, nullptr))
{
return false;
}
// Asynchronously copy data from device output buffers to host output buffers
buffers.copyOutputToHostAsync(stream);
// Wait for the work in the stream to complete
cudaStreamSynchronize(stream);
// Release stream
cudaStreamDestroy(stream);
// Check and print the output of the inference
// There should be just one output tensor
assert(mParams.outputTensorNames.size() == 1);
bool outputCorrect = verifyOutput(buffers, mParams.outputTensorNames[0], digit);
return outputCorrect;
}- 通过context->enqueue 通知TensorRT 进行网络推理过程,传入的参数包括batchSize,Input与Output的Device端存储器指针(其中Input的数据已经在processInput函数中传入Device端),用于cuda并行计算的stream流
- 通过buffers.copyOutputToHostAsync将TensorRT计算结果从Device端的Output存储器指针copy到CPU端的存储器指针中
- 通过cudaStreamSynchronize同步等待上面的所有计算完成,这样在buffers的CPU端Output指针中即保持了网络的推理结果
- 通过cudaStreamDestroy(stream) 释放cuda并行计算资源
bool SampleMNIST::verifyOutput(
const samplesCommon::BufferManager& buffers, const std::string& outputTensorName, int groundTruthDigit) const
{
const float* prob = static_cast(buffers.getHostBuffer(outputTensorName));
// Print histogram of the output distribution
gLogInfo << "Output:\n";
float val{0.0f};
int idx{0};
const int kDIGITS = 10;
for (int i = 0; i < kDIGITS; i++)
{
if (val < prob[i])
{
val = prob[i];
idx = i;
}
gLogInfo << i << ": " << std::string(int(std::floor(prob[i] * 10 + 0.5f)), '*') << "\n";
}
gLogInfo << std::endl;
return (idx == groundTruthDigit && val > 0.9f);
} - 通过verifyOutput方法来验证网络推理结果的正确性
- 通过buffers.getHostBuffer(outputTensorName)根据output Tensor的名字找到对应的Binding index,进而找到对应的HostBuffer和它的数据指针*prob
- 遍历所有*prob找到概率最大的结果并输出
- 最后判断概率最大的结果是否等于groundTruth,得出Output是否正确的结论
释放资源
bool SampleMNIST::teardown()
{
//! Clean up the libprotobuf files as the parsing is complete
//! \note It is not safe to use any other part of the protocol buffers library after
//! ShutdownProtobufLibrary() has been called.
nvcaffeparser1::shutdownProtobufLibrary();
return true;
}
......
int main(int argc, char** argv)
{
.......
if (!sample.teardown())
{
return gLogger.reportFail(sampleTest);
}
return gLogger.reportPass(sampleTest);
}- 最后通过teardown 释放分配的资源,完成整个构建网络,网络推理的过程