调用“抱抱脸团队打造的Transformers pipeline API” && 通过预训练模型,快速训练和微调自己的模型
本文章根据官方文件总结而成,根据第三方库Transformers and pytorch快速搭建自己的神经网络架构,可以直接下载预训练模型,涉及的数据集包括音频、文字、图像等,实用性非常强!
官方链接直达:GitHub - huggingface/transformers: Transformers: State-of-the-art Machine Learning for Pytorch, TensorFlow, and JAX. https://github.com/huggingface/transformers抱抱脸官方数据集网站,可以直接看到内容,链接直达:Hugging Face – The AI community building the future.https://huggingface.co/datasets
https://github.com/huggingface/transformers抱抱脸官方数据集网站,可以直接看到内容,链接直达:Hugging Face – The AI community building the future.https://huggingface.co/datasets
目录
一、Torch官方下载
二、Transformers以及相关包的安装
三、预处理(调用Transformers API)
(1)文本预处理
(2)音频预处理
(3)图像预处理
(4)多模式任务
四、训练与微调
(1)使用 Transformers Trainer 微调预训练模型。
(2)在原生 PyTorch 中 微调预训练模型。
一、Torch官方下载
链接直达:Previous PyTorch Versions | PyTorchhttps://pytorch.org/get-started/previous-versions/
进入官网后,根据电脑支持的CUDA版本,下载对应的torch版本,仅仅需要一行代码:
# CUDA==11.3 Window
conda install pytorch==1.10.1 torchvision==0.11.2 torchaudio==0.10.1 cudatoolkit=11.3 -c pytorch -c conda-forge
二、Transformers以及相关包的安装
- pip install transformers # 变形金刚
- pip install soundfile # 音频库
- pip install librosa # 音频处理
- pip install datasets # 负责下载一些数据集
三、预处理(调用Transformers API)
此处预处理大致可以分三步走:
- 加载数据集
- 加载预训练模型
- 数据增强
注意:下载数据集和预训练模型,运行代码,后台自动下载压缩包,如果网络突然中断,需要重新下载,图像的数据集有的5GB左右,尽量保持网络流畅。
*****************************************总结全在代码的注释之中*****************************************
(1)文本预处理
处理单个句子:
import torch
from transformers import AutoModel, AutoTokenizer # 调用Transformer API
# 自动从官网下载预训练模型
tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
# ======================================================================================== #
# input_ids: 是对应于句子中每个标记的索引。 [101, 7769, 9255, 14082, 102]
# token_type_ids: 当有多个序列时,辨认出属于哪一个序列 [0, 0, 0, 0, 0]
# attention_mask: 表示是否应该被注意 [1, 1, 1, 1, 1]
encoded_input = tokenizer('Flying Bulldog')
print(encoded_input) # 返回一个字典
# 如您所见,标记器在句子中添加了两个特殊标记 - CLS 和 SEP(分类器和分隔符)。
# 并非所有模型都需要特殊标记,但如果需要,标记器会自动为您添加它们。
decode_output = tokenizer.decode(encoded_input["input_ids"])
# CLS and SEP (classifier and separator)
print(decode_output) # [CLS] Flying Bulldog [SEP]处理多个句子:
import torch
from transformers import AutoModel, AutoTokenizer # 调用Transformer API
# ======================================================================================= #
# 如果您要处理多个句子,请将这些句子作为列表传递给标记器:
batch_sentences = ["Flying Bulldog",
"Good Morning",
"Factory no smoking!"]
# 这给我们带来了一个重要的话题。 当你处理一批句子时,它们的长度并不总是相同的。
# 这是一个问题,因为作为模型输入的张量需要具有统一的形状。
# 填充是一种通过向具有较少标记的句子添加特殊填充标记来确保张量是矩形的策略。
# encoded_inputs = tokenizer(batch_sentences, padding=True)
# 另一方面,有时序列可能太长,模型无法处理。 在这种情况下,您需要将序列截断为更短的长度。
# truncation: 截断
# encoded_inputs = tokenizer(batch_sentences, padding=True, truncation=True)
# Finally, you want the tokenizer to return the actual tensors that are fed to the model.
# Set the return_tensors parameter to either pt for PyTorch, or tf for TensorFlow:
encoded_inputs = tokenizer(batch_sentences, padding=True, truncation=True, return_tensors="pt")
print(encoded_inputs)
for i in range(len(batch_sentences)):
decode_outputs = tokenizer.decode(encoded_inputs["input_ids"][i])
print(decode_outputs)
(2)音频预处理
补充:采样率(Sample Rate) 指一秒钟记录的音频点的数据量,通常用HZ(赫兹)来描述,比如44.1kHz表示1s中采样44100次。而音频的一个数据点就是一个数字,该数字如果用float类型表示的话,44.1kHz1s采样的数据就有44100个float数值。
"""
音频输入的预处理与文本输入不同,但最终目标保持不变:创建模型可以理解的数字序列。
特征提取器旨在从原始图像或音频数据中提取特征并将其转换为张量。
在开始之前,安装 Datasets 以加载音频数据集以进行试验:
"""
"""
在本教程中,您将使用 Wav2Vec2 模型。 从模型卡中可以看出,Wav2Vec2 模型是在 16kHz 采样语音音频上进行预训练的。
音频数据的采样率与用于预训练模型的数据集的采样率相匹配非常重要。
如果您的数据的采样率不同,那么您需要重新采样您的音频数据。
"""
from datasets import load_dataset, Audio
# Load the MInDS-14 dataset https://huggingface.co/docs/transformers/preprocessing
dataset = load_dataset("PolyAI/minds14", name="en-US", split="train")
print(dataset[0])
# array is the speech signal loaded - and potentially resampled - as a 1D array.
# path points to the location of the audio file.
# sampling_rate refers to how many data points in the speech signal are
print(dataset[0]["audio"])
# ============================================================ #
# 1. Use Datasets’ cast_column method to upsample the sampling rate to 16kHz:
# 8KHZ >>> 16KHZ
dataset = dataset.cast_column("audio", Audio(sampling_rate=16_000))
# 2. Load the audio file:
file = dataset[0]["audio"]
# ============================================================ #
"""
下一步是加载一个特征提取器来规范化和填充输入。 填充文本数据时,为较短的序列添加 0。
同样的想法适用于音频数据,音频特征提取器将向数组添加一个 0(解释为静音)。
"""
from transformers import AutoFeatureExtractor
feature_extractor = AutoFeatureExtractor.from_pretrained("facebook/wav2vec2-base")
audio_input = [dataset[0]["audio"]["array"]]
print(feature_extractor(audio_input, sampling_rate=16000))
# padding and truncation
def preprocess_function(examples):
audio_arrays = [x["array"] for x in examples["audio"]]
inputs = feature_extractor(
audio_arrays,
sampling_rate=16000,
padding=True,
max_length=100000,
truncation=True,
)
return inputs
processed_dataset = preprocess_function(dataset[:5])
print(processed_dataset["input_values"][0].shape)
print(processed_dataset["input_values"][1].shape)(3)图像预处理
"""
特征提取器还用于处理视觉任务的图像。 再一次,目标是将原始图像转换为一批张量作为输入。
让我们为本教程加载 food101 数据集。 使用 数据集拆分参数仅从训练拆分中加载一个小样本,因为数据集非常大:
"""
import cv2
import numpy
from datasets import load_dataset
# 下载数据集food101(5GB),选取前100张图像,作为预处理的数据
dataset = load_dataset("food101", split="train[:100]")
image_data = dataset[0]
print(image_data['image'])
# =============================================== #
from transformers import AutoFeatureExtractor
feature_extractor = AutoFeatureExtractor.from_pretrained("google/vit-base-patch16-224")
# # Data augmentation
# 标准化、随机选件角度、颜色跳动、最后转换成张量
from torchvision.transforms import Compose, Normalize, RandomResizedCrop, ColorJitter, ToTensor
normalize = Normalize(mean=feature_extractor.image_mean, std=feature_extractor.image_std)
_transforms = Compose(
[RandomResizedCrop(feature_extractor.size),
ColorJitter(brightness=0.5, hue=0.5),
ToTensor(),
normalize]
)
# 该模型接受 pixel_values 作为输入。 该值由特征提取器生成。 创建一个从变换生成 pixel_values 的函数:
def transforms(examples):
examples["pixel_values"] = [_transforms(image.convert("RGB")) for image in examples["image"]]
return examples
# 然后使用 Datasets set_transform 即时应用转换:
dataset.set_transform(transforms)
# 现在,当您访问图像时,您会注意到特征提取器已添加模型输入 pixel_values:
image_aug = dataset[0]["image"]
print(image_aug)
(4)多模式任务
"""
用于多模式任务。 您将结合迄今为止所学的所有知识,并将您的技能应用于自动语音识别 (ASR) 任务。这意味着您将需要:
1.用于预处理音频数据的特征提取器。
2.用于处理文本的标记器。
"""
from datasets import load_dataset
lj_speech = load_dataset("lj_speech", split="train")
lj_speech = lj_speech.map(remove_columns=["file", "id", "normalized_text"])
print(lj_speech[0]["audio"])
print(lj_speech[0]["text"])
# 请记住前面关于处理音频数据的部分,
# 您应该始终重新采样音频数据的采样率,以匹配用于预训练模型的数据集的采样率:
lj_speech = lj_speech.cast_column("audio", Audio(sampling_rate=16_000))
# ============================================================ #
# Processor
from transformers import AutoProcessor
processor = AutoProcessor.from_pretrained("facebook/wav2vec2-base-960h")
# 1. 创建一个函数以将音频数据处理为 input_values,并将文本标记为标签。 这些是您对模型的输入:
def prepare_dataset(example):
audio = example["audio"]
example["input_values"] = processor(audio["array"], sampling_rate=16000)
with processor.as_target_processor():
example["labels"] = processor(example["text"]).input_ids
return example
# 2. Apply the prepare_dataset function to a sample:
prepare_dataset(lj_speech[0])
# 请注意,处理器添加了 input_values 和标签。 采样率也已正确下采样至 16kHz。太棒了,您现在应该能够为任何模态预处理数据,甚至可以组合不同的模态!在下一个教程中,学习如何根据新预处理的数据微调模型。
四、训练与微调
官网给出了三种训练和微调的方式:
- 使用 Transformers Trainer 微调预训练模型。
- 使用 Keras 在 TensorFlow 中微调预训练模型。
- 在原生 PyTorch 中微调预训练模型。
注:本文章没有涉及Tensorflow,有兴趣的可以到官网自行查看。
(1)使用 Transformers Trainer 微调预训练模型。
"""
使用预训练模型有很多好处。 它降低了计算成本和碳足迹,并允许您使用最先进的模型,而无需从头开始训练。
Transformers 为各种任务提供了对数千个预训练模型的访问。
当您使用预训练模型时,您可以在特定于您的任务的数据集上对其进行训练。 这被称为微调,一种非常强大的训练技术。
在本教程中,您将使用您选择的深度学习框架微调预训练模型:
1.使用 Transformers Trainer 微调预训练模型。
2.使用 Keras 在 TensorFlow 中微调预训练模型。
3.在原生 PyTorch 中微调预训练模型。
"""
# =========================================================== #
# Begin by loading the Yelp Reviews dataset:
from datasets import load_dataset
dataset = load_dataset("yelp_review_full")
print(dataset["train"][100])
# =========================================================== #
# 分词器
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
# padding and truncation strategy
def tokenize_function(examples):
return tokenizer(examples["text"], padding="max_length", truncation=True)
# 要一步处理您的数据集,请使用 Datasets map 方法对整个数据集应用预处理函数:
tokenized_datasets = dataset.map(tokenize_function, batched=True)
# =========================================================== #
# 如果您愿意,您可以创建完整数据集的较小子集以进行微调以减少所需时间:
small_train_dataset = tokenized_datasets["train"].shuffle(seed=42).select(range(1000))
small_eval_dataset = tokenized_datasets["test"].shuffle(seed=42).select(range(1000))
# =========================================================== #
# Transformers 提供了一个 Trainer 类,针对训练 Transformers 模型进行了优化,无需手动编写自己的训练循环即可更轻松地开始训练。
# Trainer API 支持广泛的训练选项和功能,例如日志记录、梯度累积和混合精度。
from transformers import AutoModelForSequenceClassification
model = AutoModelForSequenceClassification.from_pretrained("bert-base-cased", num_labels=5)
# 您将看到有关未使用某些预训练权重以及随机初始化某些权重的警告。 不用担心,这是完全正常的!
# BERT 模型的预训练头被丢弃,并替换为随机初始化的分类头。 您将在序列分类任务上微调这个新模型头,将预训练模型的知识传递给它。
# =========================================================== #
# 接下来,创建一个 TrainingArguments 类,其中包含您可以调整的所有超参数以及用于激活不同训练选项的标志。
# 对于本教程,您可以从默认的训练超参数开始,但可以随意尝试这些参数以找到您的最佳设置。
from transformers import TrainingArguments
# 指定从训练中保存检查点的位置:
training_args = TrainingArguments(output_dir="test_trainer")
# =========================================================== #
# METRIC
# Trainer 在训练期间不会自动评估模型性能。 您需要向 Trainer 传递一个函数来计算和报告指标。
# Datasets 库提供了一个简单的精度函数,您可以使用 load_metric (请参阅本教程了解更多信息)函数加载:
import numpy as np
from datasets import load_metric
metric = load_metric("accuracy")
# 调用 compute on metric 来计算预测的准确性。
# 在将预测传递给计算之前,您需要将预测转换为 logits(记住所有 Transformers 模型都会返回 logits):
def compute_metrics(eval_pred):
logits, labels = eval_pred
predictions = np.argmax(logits, axis=-1)
return metric.compute(predictions=predictions, references=labels)
# 如果您想在微调期间监控评估指标,请在训练参数中指定评估策略参数以在每个 epoch 结束时报告评估指标:
from transformers import TrainingArguments, Trainer
training_args = TrainingArguments(output_dir="test_trainer", evaluation_strategy="epoch")
# =========================================================== #
# Create a Trainer object with your model, training arguments, training and test datasets, and evaluation function:
trainer = Trainer(
model=model,
args=training_args,
train_dataset=small_train_dataset,
eval_dataset=small_eval_dataset,
compute_metrics=compute_metrics,
)
# Then fine-tune your model by calling train():
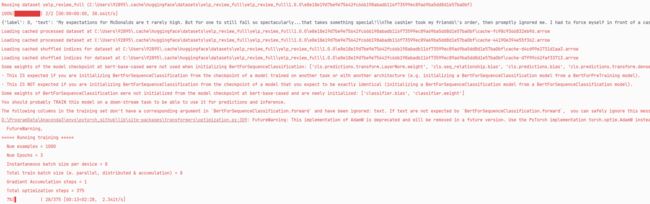
trainer.train()
# {'eval_loss': 1.2004259824752808, 'eval_accuracy': 0.484, 'eval_runtime': 18.4503, 'eval_samples_per_second': 54.2, 'eval_steps_per_second': 6.775, 'epoch': 3.0}
# {'train_runtime': 229.7662, 'train_samples_per_second': 13.057, 'train_steps_per_second': 1.632, 'train_loss': 1.3347870279947918, 'epoch': 3.0}
>>>运行结果图:

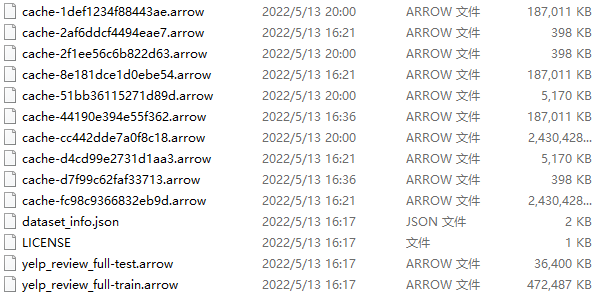
补充:下载的数据集的格式为arrow格式
- 数据格式:arrow 定义了一种在内存中表示tabular data的格式。这种格式特别为数据分析型操作(analytical operation)进行了优化。比如说列式格式(columnar format),能充分利用现代cpu的优势,进行向量化计算(vectorization)。不仅如此,Arrow还定义了IPC格式,序列化内存中的数据,进行网络传输,或者把数据以文件的方式持久化。
- 开发库:arrow定义的格式是与语言无关的,所以任何语言都能实现Arrow定义的格式。arrow项目为几乎所有的主流编程语言提供了SDK
- 下载部分文件如下:
(2)在原生 PyTorch 中 微调预训练模型。
"""
Trainer 负责训练循环,并允许您在一行代码中微调模型。
对于喜欢编写自己的训练循环的用户,您还可以在原生 PyTorch 中微调 Transformers 模型。
"""
# =========================================================== #
# Begin by loading the Yelp Reviews dataset:
from datasets import load_dataset
dataset = load_dataset("yelp_review_full")
print(dataset["train"][100])
# =========================================================== #
# 分词器
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
# padding and truncation strategy
def tokenize_function(examples):
return tokenizer(examples["text"], padding="max_length", truncation=True)
# 要一步处理您的数据集,请使用 Datasets map 方法对整个数据集应用预处理函数:
tokenized_datasets = dataset.map(tokenize_function, batched=True)
# =========================================================== #
# 1. Remove the text column because the model does not accept raw text as an input:
tokenized_datasets = tokenized_datasets.remove_columns(["text"])
# 2. 将标签列重命名为标签,因为模型需要将参数命名为标签:
tokenized_datasets = tokenized_datasets.rename_column("label", "labels")
# 3. 设置数据集的格式以返回 PyTorch 张量而不是列表:
tokenized_datasets.set_format("torch")
# =========================================================== #
# 然后创建一个较小的数据集子集,如前所示以加快微调:
small_train_dataset = tokenized_datasets["train"].shuffle(seed=42).select(range(1000))
small_eval_dataset = tokenized_datasets["test"].shuffle(seed=42).select(range(1000))
# =========================================================== #
# DataLoader
# 为您的训练和测试数据集创建一个 DataLoader,以便您可以迭代成批数据:
from torch.utils.data import DataLoader
train_dataloader = DataLoader(small_train_dataset, shuffle=True, batch_size=8)
eval_dataloader = DataLoader(small_eval_dataset, batch_size=8)
# 加载具有预期标签数量的模型:
from transformers import AutoModelForSequenceClassification # 序列分类的自动模型
model = AutoModelForSequenceClassification.from_pretrained("bert-base-cased", num_labels=5)
# =========================================================== #
# 优化器和学习率调度器
# 创建一个优化器和学习率调度器来微调模型。 让我们使用 PyTorch 的 AdamW 优化器:
from torch.optim import AdamW
optimizer = AdamW(model.parameters(), lr=5e-5)
# 从 Trainer 创建默认学习率调度程序:
from transformers import get_scheduler
num_epochs = 3
num_training_steps = num_epochs * len(train_dataloader)
lr_scheduler = get_scheduler(
name="linear", optimizer=optimizer, num_warmup_steps=0, num_training_steps=num_training_steps
)
# 最后,如果您有权使用 GPU,请指定使用 GPU 的设备。
# 否则,在 CPU 上的训练可能需要几个小时而不是几分钟。
import torch
device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
model.to(device)
# =========================================================== #
# Great, now you are ready to train!
# Training loop
# 要跟踪您的训练进度,请使用 tqdm 库在训练步骤数上添加进度条:
from tqdm.auto import tqdm # 添加进度条
progress_bar = tqdm(range(num_training_steps))
model.train()
for epoch in range(num_epochs):
for batch in train_dataloader:
batch = {k: v.to(device) for k, v in batch.items()}
outputs = model(**batch)
loss = outputs.loss
loss.backward()
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
progress_bar.update(1)
# =========================================================== #
# Metrics(评价指标)
# 就像您需要向 Trainer 添加评估函数一样,您在编写自己的训练循环时也需要这样做。
# 但不是在每个 epoch 结束时计算和报告指标,这次您将使用 add_batch 累积所有批次并在最后计算指标。
from datasets import load_metric
metric = load_metric("accuracy")
model.eval()
for batch in eval_dataloader:
batch = {k: v.to(device) for k, v in batch.items()}
with torch.no_grad():
outputs = model(**batch)
logits = outputs.logits
predictions = torch.argmax(logits, dim=-1)
metric.add_batch(predictions=predictions, references=batch["labels"])
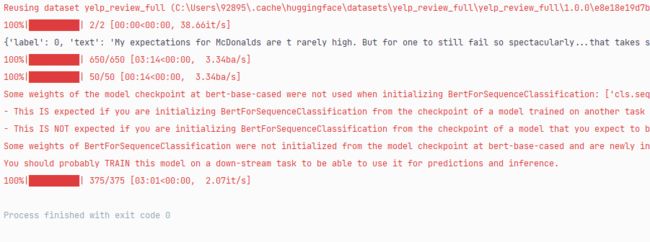
metric.compute()
>>>运行结果图:
>>> 如有疑问,欢迎评论区一起讨论