Amazon EMR HBase on S3 之二级索引、Thrift 和性能评测


点击上方【凌云驭势 重塑未来】
一起共赴年度科技盛宴!
HBase 是作为 Apache 软件基金会 Hadoop 项目的一部分开发的开源、非关系、分布式数据库,为 Hadoop 生态系统提供非关系数据库功能。Amazon EMR 从4.6.0版本开始,就提供了 HBase。
Amazon EMR 从5.2.0版本开始,就支持把 HBase 根目录和元数据直接存储到 Amazon S3, 这样就实现了HBase 的存算分离,使得数据变成了高可用。我们可以启动一个 Amazon EMR 集群,在使用 HBase 时将其目录指向 S3 中的 HBase 根目录位置。当关闭 EMR 集群后,HBase 的数据文件仍然保留在 S3 上,如果启动新的 EMR集群,HBase 仍然可以使用原来位于 S3 的数据文件。
关于 HBase on S3, 请参考:
https://docs.aws.amazon.com/emr/latest/ReleaseGuide/emr-hbase-s3.html
Amazon EMR 从5.7.0版本开始,HBase on S3 支持只读副本集群。只读副本群集为只读操作提供对主集群数据文件和元数据的只读访问。这样就实现了 HBase 的读写分离。
关于使用 HBase on S3 设置只读副本集群,请参考:
https://aws.amazon.com/cn/blogs/china/setting-up-read-replica-clusters-with-hbase-on-amazon-s3
关于 HBase on S3 和 HBase 只读副本集群,上述文档里已经说的非常清楚了,这里不再赘述。本文从实战的角度,解释一下客户在选择使用 HBase on S3 的时候比较关心的两个问题,一个是如何把已有的 HBase on HDFS 迁移到 HBase on S3,并包含二级索引的迁移;另一个是 HBase on S3 的性能问题。
HBase 的架构和文件
为了方便后面介绍 HBase 迁移的步骤,以及确保迁移过程中避免数据丢失,需要先了解 HBase 的架构和数据文件,来看存储在 HDFS 上的 HBase 的架构图:
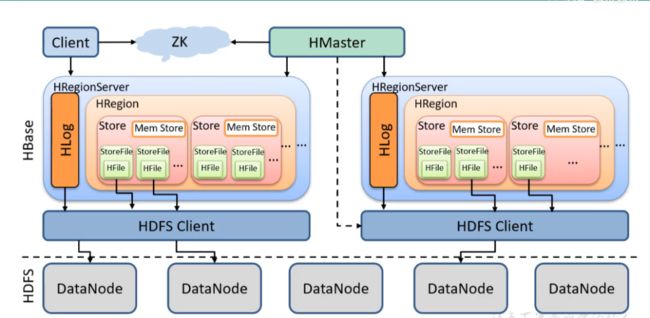
图1: HBase on HDFS 的架构和组成部分
下面依次介绍上图中的元素:
1. Client
提供了访问 HBase 的一系列 API 接口,如 Java Native API、Rest API、Thrift API 等,并维护 Cache 来加快对 HBase 的访问。
2. Zookeeper
HBase 通过 Zookeeper 来实现 Master 的高可用,保证任何时候集群中只有一个 Master、实时监控 Region Server 的上线和下线信息,并实时通知 Master 元数据的入口,以及集群配置等工作。
在创建 Aamazon EMR 时选中 HBase 应用后,会自带创建一个 Zookeeper 应用。
3. HDFS
HDFS 为 HBase 提供底层数据存储服务。使用 Amazon EMR HBase 时,我们推荐使用 S3 替换 HDFS。
4. Master(即图中的 HMaster)
HBase 通过 Master 来管理所有的 Region Server 和对表的 DDL 操作。
5. Region Server(即图中的 HRegionServer)
Region Server 用来管理 Region,处理外部对 Region 的 IO 请求,即对表的 DML 操作,向底层文件系统中读写数据。
Region Server 管理多个 Region,一个 Region 包含多个 Store, 一个 Store 对应一个 CF(列族),而一个 Store 包括位于内存中的 Mem Store 和位于磁盘的 Store File(即 HFile)。
6. Mem Store
写缓存,数据是先存储在 Mem Store 中,排好序后刷写(flush)到 Store File。关于这个 flush 的触发机制,可以参考:
https://www.jianshu.com/p/396664db17be
7. Store File
实际的存储文件。Store File 是以 HFile 的形式存储在 HDFS(或者 S3 上)的。每个 Store 会有一个或多个 Store File。
8. HFile
文件格式,HBase 的数据文件,即 Store File 是以 HFile 格式存储的。
默认情况下, HFile 位于 HDFS 文件系统的 /user/hbase/data 目录下。如果是 HBase on S3,则位于指定的 S3 目录。
9. HLog, 预写入日志,又称 Write-Ahead Logs (WAL)
用来保存 HBase 的修改记录,当对 HBase 操作数据的时候,对数据的操作会先写在一个叫做 Write-Ahead Log 的文件中,然后再将操作的数据写入内存中。所以在系统出现故障的时候,可以通过这个日志文件来恢复数据。
默认情况下, HLog 位于 HDFS 文件系统的 /user/hbase/WALs 目录下。
HBase 的二级索引
之所以会谈到二级索引,是因为我们在后面的 HBase on HDFS 迁移到 HBase on S3 时,也会涉及二级索引的迁移。这也是很多客户关心的话题。
HBase 的表数据按 RowKey 进行字典排序, RowKey 实际上是数据表的一级索引(Primary Index),由于 HBase 本身没有二级索引(Secondary Index)机制,基于索引检索数据只能单纯地依靠 RowKey, 这使得 HBase 不能有效地支持多条件查询。
HBase 本身不提供二级索引(Secondary Index),而是通过新建一个表的方式来实现实现二级索引的功能。为了实现索引而带来的额外的需求,例如更新数据时需要原子更新索引表,则需要在 HBase 上去开发实现,好在有开源的组件替 HBase 考虑到并实现了这些需求,例如 Apache Phoenix。
Phoenix 提供了几种类型的二级索引,常用的是一种叫 Covered Index(覆盖索引)的二级索引。这种索引在获取数据的过程中,内部不需要再去 HBase 表上获取任何数据,你查询需要返回的列的数据都被存储在索引中。要想达到这种效果,你的 select 的列,where 的列,group by 的列,都需要在索引中出现。
举个例子,如果你的 SQL 语句是:
SELECT "customer"."type" AS credit_card_type, count(*) AS num_customers
FROM "customer" WHERE "customer"."state" = 'CA' GROUP BY "customer"."type";左滑查看更多
要最大化查询效率和速度最快,你就需要建立覆盖索引:
CREATE INDEX my_index ON "customer" ("customer"."state")
INCLUDE("PK", "customer"."city", "customer"."expire", "customer"."type");左滑查看更多
我们可以参考文档:
https://docs.aws.amazon.com/emr/latest/ReleaseGuide/emr-phoenix-clients.html
来使用 Phoenix 建立 HBase 二级索引。在操作过程中,请注意:文档中还是使用 sqlline-thin 来执行 Sql 语句,新版本的 Phoenix 已经替换为 psql 了,例如:
/usr/lib/phoenix/bin/psql.py localhost:2181 /home/hadoop/phoenixQuery.sql左滑查看更多
另外,如果遇到 ” a) Scanner id given is wrong, b) Scanner lease expired because of long wait between consecutive client checkins” 之类的错误提示,可以设置 hbase.client.scanner.timeout.period 为更大的值,例如3000000。
建立二级索引后,我们可以看到 HBase 里多了这样几张表,如下图:
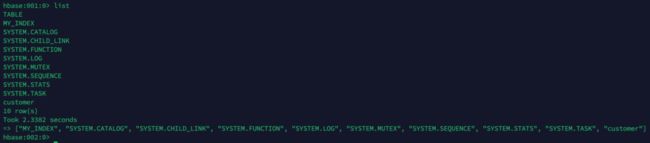
图2: Phoenix 二级索引建立的 HBase 表(customer 表是 HBase 的测试表)
我们可以执行命令 ”/usr/lib/phoenix/bin/sqlline.py localhost:2181” 进入 Phoenix 执行环境,然后检查执行计划如下:

图3: 从执行计划看二级索引的效果
HBase on HDFS 迁移到 HBase on S3
HBase on S3 的优点,很多文档和 Blog 已经介绍的很详细了,具体可以参考:
https://docs.aws.amazon.com/zh_cn/emr/latest/ReleaseGuide/emr-hbase-s3.html
我们总结起来就是:实现 HBase 的存算分离和读写分离,以及由此带来的各种优势,例如数据高可用、降本增效等。
需要指出的是:HBase on S3 并不是指 HBase 所有的组成部分都放到 S3,我们在章节1中提到的写缓存(Mem Store)是内存部分,需要把写缓存的数据 Push 到位于 S3 的 HFile 文件里。另外 HLog (WAL) 仍然是位于 EMR Core 节点的 HDFS 上。HBase on S3 的组件分布图如下:
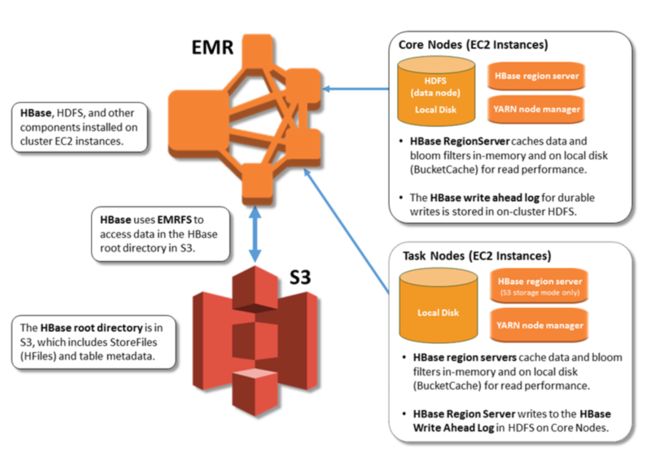
图4: HBase on S3 的组件分布
由于很多客户已经在使用 HBase on HDFS 了,怎样帮助客户从 HBase on HDFS 迁移到 HBase on S3,就成了一个亟待解决的问题。在文章中,提供了三种迁移的方法:
https://aws.amazon.com/cn/blogs/china/tips-for-migrating-to-apache-hbase-on-amazon-s3-from-hdfs/
● 快照(Snapshot)
● 导出和导入(Export / Import)
● CopyTable
上述三种方法,都是对单个表的迁移,在实际项目中可能多个表,包括二级索引产生的表,可能还需要自己写脚本实现整库的迁移。
还有一种迁移方式,就是把所有的库文件迁移到 S3。 前提是把所有的表都 Disable, 步骤如下:
1.在 S3 上创建 HBase 根目录,例如 s3://dalei-demo/hbase
2.将 HBase on HDFS 集群的表 Disable, 并刷新 ‘hbase:meta’
bash /usr/lib/hbase/bin/disable_all_tables.sh
hbase:001:0>flush 'hbase:meta'左滑查看更多
3. 将 HBase 在 HDFS 上的文件全部 Distcp 到 S3 的 HBase 根目录
hadoop distcp hdfs://ip-10-0-0-126:8020/user/hbase/* s3://dalei-demo/hbase/左滑查看更多
4.创建新的 Amazon EMR 集群,指定 HBase on S3, 步骤可以参考:
https://docs.aws.amazon.com/zh_cn/emr/latest/ReleaseGuide/emr-hbase-s3.html
5.在新的 HBase on S3 上 Enable 所有的表,然后做常规操作的测试,包括二级索引的测试
6.创建只读副本集群,并测试
到目前为止,HBase on HDFS 已经迁移到了 HBase on S3, 有兴趣的读者可以再去测试一下数据文件的高可用性,例如把 HBase on S3 所在的 Amazon EMR 集群终止,然后重建一个新的集群,配置 HBase on S3 指向老集群使用的 S3 上的 HBase 根目录,会发现表、索引、数据都可以正常使用。
请注意一点,上述测试可能因为数据没有 Flush 到 HFile,而导致数据丢失,所以如果是生产环境,还是建议使用3个 Master 节点的 Amazon EMR, 避免集群的突然崩溃。
如果是正常释放 Amazon EMR 集群,请一定执行迁移步骤中的第2)步,确保所有的数据和 Meta Data,都被 Flush 到 S3 的 HBase 根目录下,避免可能出现的数据丢失。
性能评测
实际开发中,客户是把 HBase 作为一种高并发、低延迟的 No-Sql 数据库来使用,并通过 Thrift 实现的接口来进行随机的读写。我们来对比一下 HBase on HDFS 和 HBase on S3 上的性能。
Thrift 的编译和实现
Thrift 是一种接口描述语言和二进制通讯协议,它被用来定义和创建跨语言的服务。它被当作一个远程过程调用(RPC)框架来使用,是由 Facebook 为“大规模跨语言服务开发”而开发的,它现在是 Apache 软件基金会的开源项目。
Thrift 包含一套完整的栈来创建客户端和服务端程序。服务端的程序我们不需要关心,很多应用都自带了(Amazon EMR 也带了 Thrift Server)。客户端的接口是由 Thrift 提供的,客户端的代码是由 Thrift 根据这个接口文件生成的。生成的步骤请参考:
https://thrift.apache.org/tutorial/py.html
通过 Thrift 访问 HBase
Thrift 为 HBase 提供了两个版本的服务端程序(Thrift Server):Thrift 和 Thrift2。Amazon EMR HBase 默认启动的 Thrift,目前大部分客户都在使用 Thrift2, 我们先把启动的 Thrift Server 的版本改一下,步骤如下:
1.关闭 Thrift 服务
sudo systemctl stop hbase-thrift2.修改 hbase-thrift 服务的启动脚本
sudo vim /etc/systemd/system/hbase-thrift.service
将 ExecStart=/usr/lib/hbase/bin/hbase-daemon.sh start thrift
替换为 ExecStart=/usr/lib/hbase/bin/hbase-daemon.sh start thrift2
将 /var/run/hbase/hbase-hbase-thrift.pid
替换为 /var/run/hbase/hbase-hbase-thrift2.pid左滑查看更多
3. 刷新 systemd 服务配置
sudo systemctl daemon-reload4.重新启动 hbase-thrift 服务,此时启动的是 Thrift2
sudo systemctl start hbase-thrift5.检查是否启动成功
ps aux | grep thrift2通过 Thrift2 访问 HBase 的步骤如下:
1.安装 Python 依赖包
pip install thrift
pip install hbase-thrift2.部署客户端代码
将上一节编译生成的 Thrift 客户端代码中的 ttypes.py 和 THBaseService.py, 放到 Python 依赖包生成的目录,例如 /home/hadoop/.local/lib/python3.7/site-packages/hbase。如果已有 ttypes.py 文件,则替换它。
如果自己编译失败,也可以从:
https://github.com/xudalei1977/hbase-thrift-performance
直接下载这两个文件,放到上面的目录里。
3.在 hbase shell 里创建表空间和表
hbase:001:0> create_namespace 'test_ns'
Took 8.4409 seconds
hbase:002:0> create 'test_ns:test_1', {NAME =>'cf_1', COMPRESSION => 'snappy', TTL=>'86400' }, { NUMREGIONS => 257, SPLITALGO => 'HexStringSplit' }
Created table test_ns:test_1
Took 48.2039 seconds
=> Hbase::Table - test_ns:test_1左滑查看更多
4.执行的测试代码如下:
from thrift.transport import TSocket
from thrift.protocol import TBinaryProtocol
from thrift.transport import TTransport
from hbase.ttypes import *
from hbase import THBaseService
transport = TTransport.TBufferedTransport(TSocket.TSocket('127.0.0.1', 9090))
protocol = TBinaryProtocol.TBinaryProtocolAccelerated(transport)
client = THBaseService.Client(protocol)
transport.open()
table = 'test_ns:test_1'
row = 'row1'
put_columns = [
TColumnValue('cf_1'.encode(), 'col_1'.encode(), 'value_1'.encode()),
TColumnValue('cf_1'.encode(), 'col_2'.encode(), 'value_2'.encode()),
TColumnValue('cf_1'.encode(), 'col_3'.encode(), 'value_3'.encode()),
TColumnValue('cf_1'.encode(), 'col_4'.encode(), 'value_4'.encode()),
TColumnValue('cf_1'.encode(), 'col_5'.encode(), 'value_5'.encode())
]
tput = TPut(row.encode(), put_columns)
client.put(table.encode(), tput)
get_columns = [
TColumn('cf_1'.encode(), 'col_1'.encode()),
TColumn('cf_1'.encode(), 'col_2'.encode()),
]
tget = TGet(row.encode(), get_columns)
tresult = client.get(table.encode(), tget)
print(tresult)
transport.close()左滑查看更多
性能对比
我们会在 HBase on HDFS 和 HBase on S3 上分别测试写入(Put)操作和读取(Get)操作的性能。首先创建两个 Amazon EMR 集群,一个使用 HBase on HDFS, 一个使用 HBase on S3, 版本采用最新的6.9.0, 配置都是如下:

测试代码位于:
https://github.com/xudalei1977/hbase-thrift-performance
用户可以 git clone 到 Amazon EMR 的 Master 节点上。
我们会用到 Parallel 模拟并发测试,先下载 Parallel 源文件到 Master 节点,并进行编译如下:
wget https://ftpmirror.gnu.org/parallel/parallel-20221122.tar.bz2
tar -jxvf parallel-20221122.tar.bz2
cd parallel-20221122
./configure
make && sudo make install左滑查看更多
测试写入(Put)操作的性能的代码是 hbase-put.py, 我们使用如下 Shell 执行:
CONF_FILE=parallel.hbase
rm -rf $CONF_FILE
CORE_NUM=`nproc`
KEY_NUM=4
TASK_NUM=`expr $CORE_NUM \* $KEY_NUM`
for i in $(seq 1 $TASK_NUM);do echo "/usr/bin/python3 ~/hbase-put.py 400000 1" >> $CONF_FILE ; done;
wc -l $CONF_FILE
nohup parallel -j $TASK_NUM < $CONF_FILE &左滑查看更多
在上面的代码中,请注意:
▌ Parallel 根据当前节点的核数,乘以每个节点的 Task 数目,来确定执行 hbase-put.py 文件的并发数。
▌ hbase-put.py 用来写入数据到表 “test_ns:test_1”, 后面的参数表示每次执行写入的条数和线程数,由于 Parallel 已经使用了并发,这里线程数就指定为1,可以修改这两个参数来调整写入的记录条数。
▌ 在写入数据时,RowKey 是采用了 md5 作用于随机数,保证了数据在 Region 上的均匀分布。
写入(Put)操作的性能对比如下:
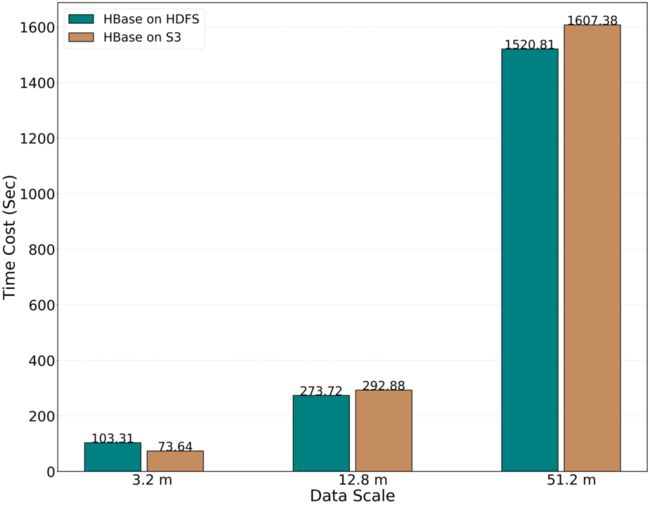
图5: HBase on HDFS 和 HBase on S3 的写入(Put)操作的性能对比
可以看出,二者在写入时的性能,相差无几。
再来看读取(Get)操作,性能测试的代码是 hbase-get.py, 我们使用如下 Shell 执行:
CONF_FILE=parallel.hbase
rm -rf $CONF_FILE
CORE_NUM=`nproc`
KEY_NUM=4
TASK_NUM=`expr $CORE_NUM \* $KEY_NUM`
for i in $(seq 1 $TASK_NUM);do echo "/usr/bin/python3 ~/hbase-get.py 400000 1" >> $CONF_FILE ; done;
wc -l $CONF_FILE
nohup parallel -j $TASK_NUM < $CONF_FILE &左滑查看更多
在上面的代码中,请注意:
▌Parallel 根据当前节点的核数,乘以每个节点的 Task 数目,来确定执行 hbase-get.py 文件的并发数。
▌hbase-get.py 用来从表 ”test_ns:test_1”中读取数据, 后面的参数表示每次执行读取的次数和线程数,由于 Parallel 已经使用了并发,这里线程数就指定为1,可以修改这两个参数来调整读取的次数/
▌在读取数据时,采用了 md5 作用于随机数去匹配 Rowkey,有可能因为匹配不到 Rowkey 而遍历所有的 HFile,这保证了读取的数据不是只位于 Mem Store, 也有位于 HDFS 或者 S3 上的 HFile 里的数据。
读取(Get)操作的性能对比如下:
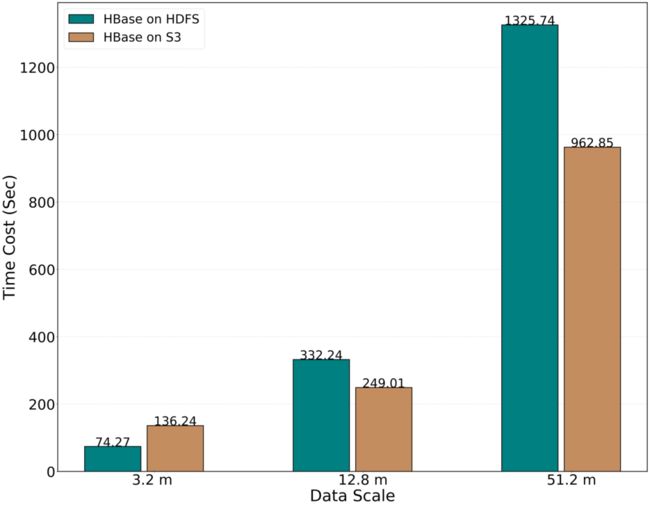
可以看出在进行读操作时,HBase on S3 有性能优势。
关于其它的操作,不论是 HBase 自带的 Count, Scan, Filter,还是 Spark 读写 HBase,还是我们前面介绍的二级索引,作者在实际开发中都做过比较,HBase on HDFS 和 HBase on S3 的性能差别不大。此外,如果使用只读集群实现 HBase 的读写分离的话,还可获得更多的优化空间,因为读和写可以设置不同的参数。有兴趣的朋友可以自己测试一下。
总之,还是鼓励 HBase 的用户,把数据迁到 S3 上来。
参考文档
https://docs.aws.amazon.com/emr/latest/ReleaseGuide/emr-hbase.html
https://thrift.apache.org/
https://hbase.apache.org/
https://phoenix.apache.org/
https://aws.amazon.com/cn/blogs/china/setting-up-read-replica-clusters-with-hbase-on-amazon-s3/
https://aws.amazon.com/cn/blogs/china/tips-for-migrating-to-apache-hbase-on-amazon-s3-from-hdfs/
https://aws.amazon.com/cn/blogs/china/using-athena-to-replace-hbase-to-query-analyze-historical-data/
https://aws.amazon.com/cn/blogs/china/migrate-to-apache-hbase-on-amazon-s3-on-amazon-emr-guidelines-and-best-practices/
https://aws.amazon.com/cn/blogs/china/build-a-hbase-read-backup-cluster-based-on-s3/
https://aws.amazon.com/blogs/big-data/amazon-emr-6-2-0-adds-persistent-hfile-tracking-to-improve-performance-with-hbase-on-amazon-s3/
本篇作者

Dalei Xu
亚马逊云科技解决方案架构师,负责亚马逊云科技数据分析的解决方案的咨询和架构设计。多年从事一线开发,在数据开发、架构设计和组件管理方面积累了丰富的经验,希望能将亚马逊云科技优秀的服务组件,推广给更多的企业用户,实现与客户的双赢和共同成长。
![]()
2022亚马逊云科技 re:Invent 全球大会
精彩视频现已上线!
点击下方图片立即观看

听说,点完下面4个按钮
就不会碰到bug了!