SENet:Squeeze-and-Excitation Networks
Squeeze-and-Excitation Networks
主要贡献:SE模块;
插入其他网络里简称:SE-Net;
最后一届ImageNet 分类赛冠军;
亮点:关注通道之间的关系,希望网络可以学习到不同通道特征的重要程度;
发表时间:[Submitted on 5 Sep 2017 (v1), last revised 16 May 2019 (this version, v4)]
发表期刊/会议:Computer Vision and Pattern Recognition
论文地址:https://arxiv.org/abs/1709.01507
代码地址: https://github.com/hujie-frank/SENet;
关键字:Squeeze-and-Excitation, Image representations, Attention, Convolutional Neural Networks.
系列论文阅读顺序:
0 摘要
CNN的核心是卷积运算,它使网络能够通过融合每一层局部视野内的空间信息和通道信息来构建信息特征。
前人很多关注空间信息的工作;
本文关注通道关系,提出了一种新的架构,称为SE Block(Squeeze-and-Excitation block),通过显式建模通道之间的相互依赖性,自适应地重新校准通道特征响应;
本文展示了这些SE block可以插入其他网络,形成SE-Net架构,在不同的数据集上非常有效。
1 简介
CNN研究空间关系的工作背景;
本文,研究了另一个方面:通道关系,引入SE block;
SE block、复杂度、效果等概述;
2 相关工作
Deeper architectures方面工作:VGG、Inception等;
Algorithmic Architecture Search:自动设计网络方面的工作;
Attention and gating mechanisms:注意力方面的工作;
3 SE-block
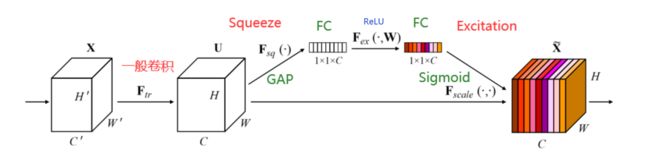
如图1所示,
输入: X ∈ R H ′ × W ′ × C ′ X∈R^{H' × W' × C'} X∈RH′×W′×C′;
F t r F_{tr} Ftr一个转换操作,就是一个普通卷积操作,转换结果为 U ∈ R H × W × C U∈R^{H × W × C} U∈RH×W×C;
后序模块分为两部分:
- Squeeze模块:压缩通道,从 H × W × C H × W × C H×W×C变为 1 × 1 × C 1 × 1 × C 1×1×C;
- Excitation模块:自适应调整,调整为通道权重( F s c a l e F_{scale} Fscale之后变成0~1范围的通道权重)和原特征图相乘,得到 X ~ \widetilde{X} X ;
3.1 Squeeze: Global Information Embedding
通过全局平均池化,将全局空间信息压缩到通道描述符中;
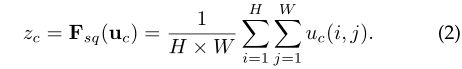
3.2 Excitation: Adaptive Recalibration
捕获通道依赖性,用sigmoid函数实现;
两个FC((为了减少计算量)):
- 第一个FC,降维,降到C / r;
- 第二个FC,升维,升回C;
其中:δ:ReLU;
最终输出:
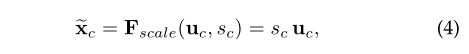
F s c a l e F_{scale} Fscale:缩放到0 ~ 1之间,变为权重;
SE模块Pytorch实现代码:
from torch import nn
class SELayer(nn.Module):
def __init__(self, channel, reduction=16):
super(SELayer, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(channel, channel // reduction, bias=False),
nn.ReLU(inplace=True),
nn.Linear(channel // reduction, channel, bias=False),
nn.Sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size()
# 平均池化层
y = self.avg_pool(x).view(b, c)
# FC(C->C/r)-ReLU-FC(C/r->C)-Sigmoid
y = self.fc(y).view(b, c, 1, 1)
# expand_as(x):将张量扩展为x的大小
# x:原通道 y:权重值
# 将权重乘进原通道
return x * y.expand_as(x)
3.3 Instantiations
SE模块可以很容易的插入其他网络;
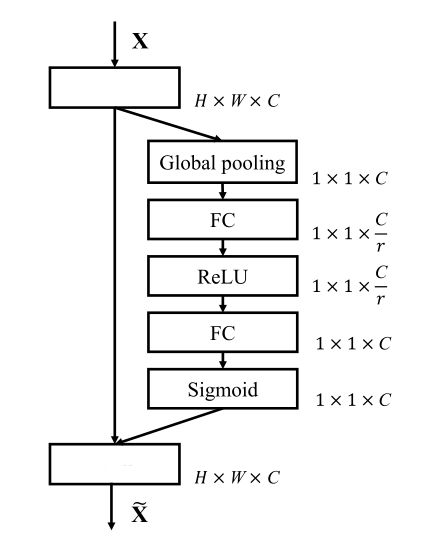
比如SE-Inception网络,如图2;

比如SE-ResNet网络,如图3;
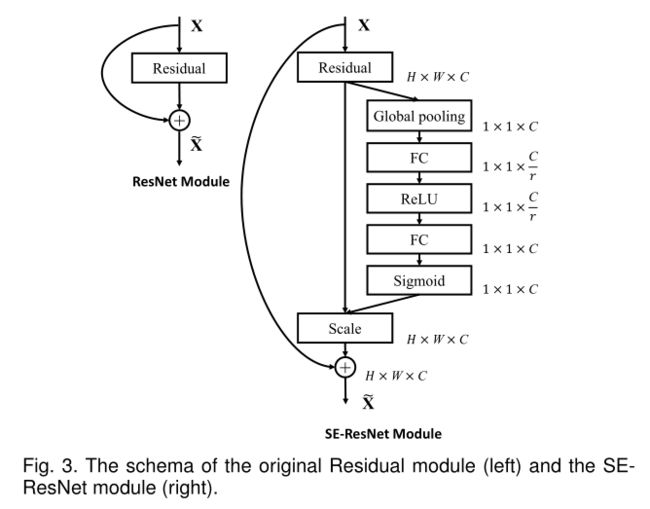
SE-Resnet代码Pytorch实现:
class SEBasicBlock(nn.Module):
expansion = 1
def __init__(self, inplanes, planes, stride=1, downsample=None, groups=1,
base_width=64, dilation=1, norm_layer=None,
*, reduction=16):
super(SEBasicBlock, self).__init__()
self.conv1 = conv3x3(inplanes, planes, stride)
self.bn1 = nn.BatchNorm2d(planes)
self.relu = nn.ReLU(inplace=True)
self.conv2 = conv3x3(planes, planes, 1)
self.bn2 = nn.BatchNorm2d(planes)
# SE模块
self.se = SELayer(planes, reduction)
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
# 经过SE模块
out = self.se(out)
if self.downsample is not None:
residual = self.downsample(x)
# 残差连接
out += residual
out = self.relu(out)
return out
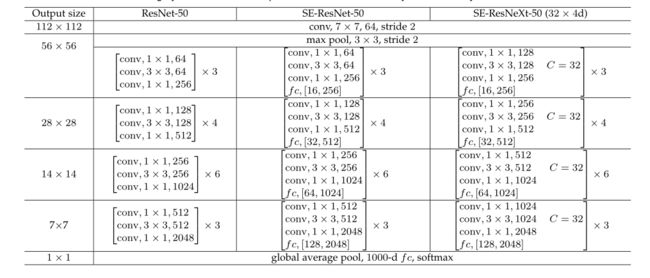
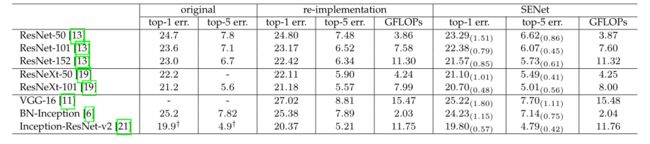
表1展示了SE-ResNet-50和SE-ResNeXt-50的架构;
4 模型复杂度/计算复杂度
224 * 224的图像,用ResNet-50在一次前向传播中需要~3.86 GFLOPs;
用SE-ResNet-50需要~3.87 GFLOPs,相比原来只增长0.26%(r=16的情况下);
SE-ResNet-50的准确性超过了ResNet-50,更接近ResNet-101;
详细情况见表2;
5 实验

6 消融实验

7 ROLE OF SE BLOCKS
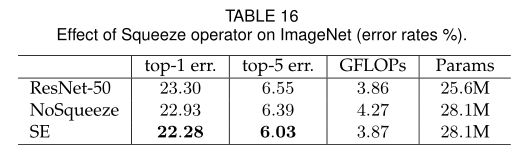
7.1 Effect of Squeeze
评估Squeeze模块的全局嵌入是否在性能中发挥重要作用,进行对比实验;
实现SE的变体NoSqueeze,有相同的参数量,但是没有全局平均池化操作(去掉池化操作,将FC层换成激励算子中具有相同通道维度的1*1卷积);
实验结果见表16;
7.2 Role of Excitation
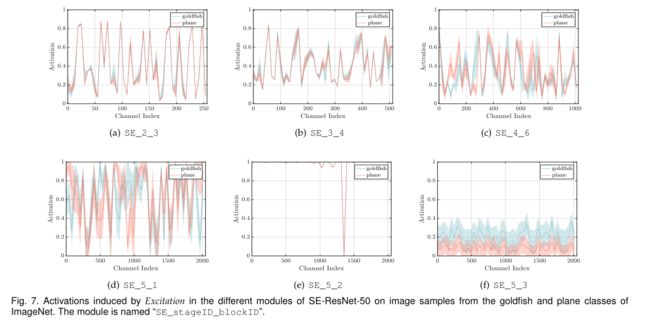
为了更清晰地了解SE模块中Excitation的功能,本节研究了SE- resnet -50模型中的Excitation作用,检查了它们在网络中不同深度的不同类别和不同输入图像中的分布。
首先考虑不同类的excitation分布,从ImageNet数据集中选取了四个表现出语义和外观多样性的类,即金鱼(goldfish)、哈巴狗(pug)、平面(plane)和悬崖(cliff),然后,从验证集中为每个类抽取50个样本,并计算每个阶段的最后一个SE块中50个均匀采样通道的平均激活(在降采样之前),并在图6中绘制它们的分布。
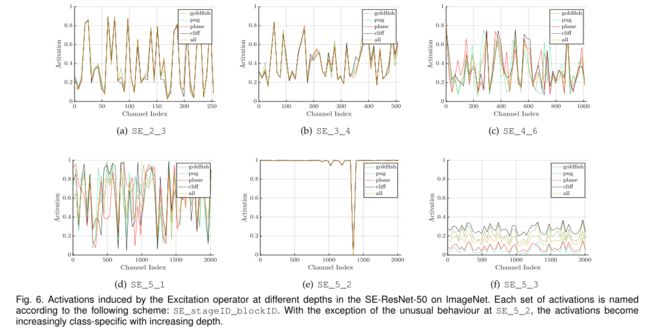
(ResNet不同Stage详情见ResNet论文)
excitation的作用:
- 首先,不同类之间的分布在网络的早期层非常相似,例如SE_2_3。这表明特征通道的重要性很可能在早期阶段由不同的类共享;
- 第二,在更深入的层,每个通道的值变得更具有类别特异性,因为不同的类别对特征的判别值表现出不同的偏好,例如SE_4_6和SE_5_1;
- 第三,在网络的最后阶段观察到一个有些不同的现象。SE_5_2表现出一种有趣的趋向于饱和状态,在这种状态下,大多数激活都接近于一个。在SE_5_3中的网络末端(紧接着是在分类器之前的全局池化),在不同的类上出现了类似的模式,直到规模上有一定的变化(可以由分类器进行调优)。
图7中显示了两个样本类(goldfish和plane)的同一类内图像实例的激活的均值和标准差。我们观察到一个与类间可视化一致的趋势,表明SE块的动态行为在类和类中的实例中都是不同的。特别是在网络的后期层,在单个类中有相当多的多样性表示,网络学会利用特征重新校准来提高其判别性能[84]。总之,SE块产生特定于实例的响应,这些响应的功能是支持模型在体系结构的不同层上日益增长的特定于类的需求。