NASNet:Learning Transferable Architectures for Scalable Image Recognition
Learning Transferable Architectures for Scalable Image Recognition
在NAS论文的基础上进行改善;
controller不再预测CNN的Layer参数,而是用来预测Cell里block的参数(cell与block定义解释见第3节);
发表时间:[Submitted on 21 Jul 2017 (v1), last revised 11 Apr 2018 (this version, v4)];
发表期刊/会议:Computer Vision and Pattern Recognition;
论文地址:https://arxiv.org/abs/1707.07012;
系列论文阅读顺序:
0 摘要
本文研究了一种直接在感兴趣的数据集上学习模型架构的方法。由于这种方法在数据集较大时成本较高,因此建议在小数据集上搜索架构构建block,然后将该block转移到更大的数据集上。
本文贡献:设计了一个新的搜索空间(称为“NASNet搜索空间”),实现了可移植性,搜索出的网络架构称为"NASNet";
1 简介
本文工作受NAS启发,NAS或任何其他搜索方法直接应用于大型数据集(如ImageNet数据集),计算成本很高;
本文建议在一个小型数据集上搜索,迁移到大型数据集,通过设计一个搜索空间来实现这种可移植性;
3 方法
搜索方法见图1,同NAS:

本文的方法中,卷积网络的整体架构是手动预定的,由重复多次的卷积Cell组成,每个卷积Cell具有相同的架构,但权重不同;
为了让网络适应不同的图片大小,在将feature map作为输入时,需要两种类型的卷积Cell(convolutional cells)来完成主要功能:
- Normal Cell:返回相同维度的特征图的cell;
- Reduction Cell:返回特征图高度和宽度减少为1 / 2的cell(利用stride = 2来下采样);
详情见图2:

在本文的搜索空间中,每个cell接受两个输入 h i h_i hi和 h i − 1 h_{i-1} hi−1(两个hidden state),将每个Cell划分为B个block(论文里B = 5),controller搜索步骤见图3:
- Step1. 从 h i h_i hi和 h i − 1 h_{i-1} hi−1或从前面的Block中选择一个hidden state;
- Step2. 从Step1.中相同的选项中选择第二个hidden state;
- Step3. 选择要应用于Step1.中选择的hidden state的操作;
- Step4. 选择要应用于Step2.中选择的hidden state的操作;
- Step5. 选择一个方法来组合Step3.和Step4.的输出,以创建一个新的hidden state;

算法将新建的hidden state追加到现有的hidden state集中,作为后续block的潜在输入,一共重复B次对应B个block,见图7(附录);

在Step3.和Step4.中,可选的操作包括:

Step5.的选择范围:
- (1) 在两个隐藏状态之间按元素进行相加(add);
- (2) 在两个隐藏状态之间沿滤波器维度进行串联(concat);
为了让控制器RNN同时预测Normal Cell和Reduction Cell,我们简单地让控制器总共有2 × 5B预测,其中第一个5B预测是Normal Cell,第二个5B预测是Reduction Cell;
本文的工作利用了NAS中的强化学习[71];然而,在NASNet搜索空间中使用随机搜索来搜索架构也是可能的。
在随机搜索中,可以从均匀分布中采样决策,而不是从控制器RNN中的softmax分类器中采样决策。在本文的实验中发现随机搜索比CIFAR10数据集上的强化学习略差。虽然使用强化学习是有价值的,但差距比原文[71]中发现的要小。这一结果表明:
- NASNet搜索空间构造良好,因此随机搜索可以相当好地执行;
- 随机搜索是一个难以超越的基线。在第4.4节中比较强化学习和随机搜索;
4 实验
最终搜索出三个有效架构:NASNet-A、NASNet-B和NASNet-C;

本文发现DropPath不能很好地用于NASNets,而ScheduledDropPath显著提高了NASNets的最终性能;
两个可讨论的参数:
- 重复的次数N;
- 初始化时Cell里卷积核的数量;
例如,重复4次,64个卷积核写作:4@64;
4.1 CIFAR-10图像分类任务
架构见图2,结果见表1;

4.2 ImageNet图像分类任务
在ImageNet上使用从CIFAR-10中学到的最好的卷积Cell进行了几组实验。
只是从CIFAR-10转移架构,从头开始训练所有ImageNet模型的权重(和迁移学习不同);
结果见表2,表3,图5;


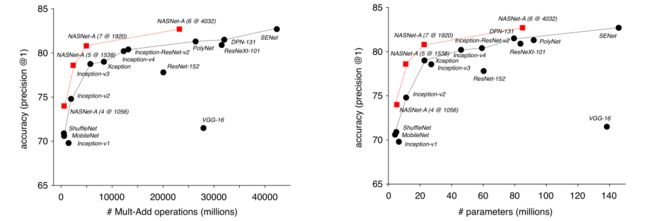
NASNet在同等复杂度下(操作数量/参数数量),精度最高;
4.3 目标检测任务

4.4 模型搜索的效率

尽管RS可能提供了一种可行的搜索策略,但RL在NASNet搜索空间中找到了更好的架构;