SENet(Squeeze-and-Excitation Networks)
什么是计算机视觉注意力
注意力机制就是对输入权重分配的关注,最开始使用到注意力机制是在编码器-解码器(encoder-decoder)中, 注意力机制通过对编码器所有时间步的隐藏状态做加权平均来得到下一层的输入变量。
计算机视觉(computer vision)中的注意力机制(attention)的基本思想就是想让系统学会注意力——能够忽略无关信息而关注重点信息。
注:我们只讨论CV里面的注意力机制,不谈NLP的注意力机制。随着注意力机制在CNN网络中的广泛应用,并且日趋成熟,我将用几篇博客陆续更新注意力机制的主要网络的分析,分享给有需要的同学,也是自己的学习记录。觉得还不错的同学可以给个赞并关注博主,不胜感激^_^。
注意力机制:硬注意力和软注意力。
硬注意力:是具体到某一数值,例如:分类中的概率最高的一项。硬注意力是不连续的,不可微,所以很难进行训练。
神经网络中一般注意力指的是软注意力机制:是指某一区间范围内的连续数值。那么,重点是软注意力是可微的,则我们可以利用神经网络的正向传播进行数值传递,并利用方向传播进行梯度更新,学习到较好的注意力权重。
就注意力关注的域来分:
空间域(spatial domain)
通道域(channel domain)
层域(layer domain)
混合域(mixed domain)
时间域(time domain)
SENET
本文介绍的是CVPR2017上的文章,并且赢得了ImageNet2017分类任务的冠军,SENET模块简单,方便扩展到其他网络模型中,论文地址:SENET。
SENET主要思路
CNN网络中,图像或者说Feature Map的特征主要分为空间特征(Spatial)和通道(Channel)特征。对于空间特征来说,在CNN网络正向传播的过程中,通过卷积运算从输入特征一步步的卷积操作得到新的Feature Map么本质上来说,卷积操作是局部特征,那么随着网络正向传播的深入,到深层网络的特征野会远大于浅层网络特征图的感受野,说明深层网络有着更多的空间维度信息。对于通道特征来说,是通过卷积操作后得到的空间特征,并在通道维度上进行融合而得到。
SENET就是对通道维度的注意力机制,上面介绍了通道特征是对空间特征Featue Map的融合。其实同一个通道维度的不同的Feature Map是用着不同的重要程度的,也就是说对于同一个Feature Map里面的信息权重的分配是不同的。SETNET就是针对通道维度上的特征进行信息权重分配,重要的信息获取更多的权重,轻量的信息获取较少的权重分配,这样就可以学习到通道特征的重要程度,下面是SENET论文Squeeze-and-Excitation(SE)模块的设计图:
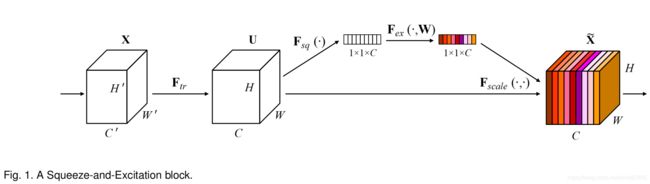
SE模块基本流程是将Feature Map分别对每个特征图进行全局池化操作得到一个具体数值,并进行Squeeze的通道维度压缩,之后经过Excitation操作得到不同通道维度的权重,最后将输入的Feature Map和得到的权重值进行內积操作,为原始Featue Map进行权重分配,整体流程有点类似残差块的操作,可以分方便的嵌入到其他CNN网络中。
Squeeze-and-Excitation (SE) 模块
在介绍SE模块之前先回忆一下卷积操作(其实论文就是这么来的^_^),看一下下面的公式:

这么看可能不是很明确,解释一下参数其实就很好理解,它其实就表示一个卷积过程。![]() ,
,![]() 表示一个卷积运算,X到U的过程。V=[v1,v2,…,vC]表示学习到的一组卷积核,vc指的是第c个卷积核。*代表卷积操作,
表示一个卷积运算,X到U的过程。V=[v1,v2,…,vC]表示学习到的一组卷积核,vc指的是第c个卷积核。*代表卷积操作,![]() 表示通道数为s的第c组卷积核,
表示通道数为s的第c组卷积核,![]() 表示通道数为s的Feature Map。那么可以看出,公式(1)表示卷积核
表示通道数为s的Feature Map。那么可以看出,公式(1)表示卷积核![]() 经过对
经过对![]() 的卷积,并对卷积结果求和,得到
的卷积,并对卷积结果求和,得到![]() 。这就是一组典型的卷积操作。
。这就是一组典型的卷积操作。
从上述的卷积操作可以看出来,卷积操作是将Feature Map将单独一个特征图结果通过卷积操作得到一个值(空间特征信息),再将这个值进行sum操作得到一组新的Feature Map。所以,通过这种卷积操作得到的Feature Map是将原始输入的Feature Map的空间关系和通道关系纠缠到了一起,这种纠缠就无法最大化有用的信息。SE模块就是为了将这种纠缠尽可能的最小化,放大有用特征,减少无用特征的利用率。
Squeeze操作
Squeeze操作,以下我就简称S操作。在卷积过程中,单个特征卷积是局部的空间感受野,并没有通道信息数据,只是在进行sum操作时候才有了通道特征的概念。S操作的目的就是为了打通通道之间只有sum操作的相关性,从而提升通道数据的关联性。S操作将每个特征图通过全局池化操作提取为标量数据,其实这个操作是比较暴力的,完全可以通过其他操作进行优化,下面是S操作的公式:

公式(2)很简单,就是将H*W的特征图计算每个像素值的和,并处以H*W,获取全局平均池化的结果![]() ,就是将H*W的Feature Map压缩为一个标量的全局描述特征,那么将原来H*W*S的特征图转化为1*1*S的特征,通道数量保持不变。
,就是将H*W的Feature Map压缩为一个标量的全局描述特征,那么将原来H*W*S的特征图转化为1*1*S的特征,通道数量保持不变。
Excitation操作
Excitation操作,以下简称E操作。S操作得到了每个Feature Map的全局描述,打通了通道之间的联系,E操作就是用来获取通道之间的关系。
论文强调E操作的两个原则:
1、操作要灵活,方便嵌入到不同的网络,最主要的是它要可以学习通道之前的非线性关系。
2、每个通道之间的关系不能是互斥的,比如(softmax),因为它要记录多通道之间的关系,不能是one-hot形式。

公式(3)是E操作模块的方法,它通过两次全连接操作和sigmoid激活函数得到相应的通道权重。其中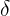 是ReLU函数,W1是第一个全连接操作,目的是降维,它有一个降维系数r是超参数。W2是第二个全连接操作的参数,将维度恢复为输入维度。经过两次全连接之后,利用sigmoid激活函数对每个特征图进行权重归一化操作。最后将sigmoid激活函数的输出的权重矩阵与原始的Feature Map相乘获得带权重的输出Feature Map,最后获得Feature Map的结果如下公式:
是ReLU函数,W1是第一个全连接操作,目的是降维,它有一个降维系数r是超参数。W2是第二个全连接操作的参数,将维度恢复为输入维度。经过两次全连接之后,利用sigmoid激活函数对每个特征图进行权重归一化操作。最后将sigmoid激活函数的输出的权重矩阵与原始的Feature Map相乘获得带权重的输出Feature Map,最后获得Feature Map的结果如下公式:
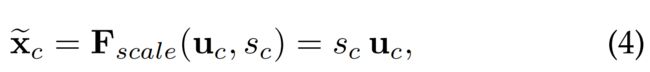
根据公式(3)(4)将原始经过卷积操作的过程,添加了在通道维度上每个特征图的权重系数从而使Feature Map的通道特征更具对特征的提取能力,放大了有效特征,减小了无效特征信息,这就是通道注意力机制。
SE模块在其他模型的应用
论文中提到了再Inception和ResNet上的应用,SE模块具有灵活的实用性,可以方便的添加到其他CNN网路中,下图是对Inception和ResNet模块嵌入SE模块示意图:


图2和图3分别是Inception和ResNet加入SE模块之后的SE-Inception和SE-ResNet模块。图2就是Inception中添加了SE模块,输入的特征图x进入到SE模块,首先进入S操作,利用全局平均池化得到每个特征图的全局特征表示数据,并进入到降维全连接操作,SE模块默认将为系数r为1/16,之后Relu激活添加非线性功能,在进入第二个全连接恢复通道维度,最后经过sigmoid函数进行权重系数分配得到通道特征权重,最后与输入x的Feature Map相乘获得带系数的输出Feature Map。图3的ResNet多了一个残差结构,其余都是一样的操作,就不再赘述。
模型复杂度分析
在实践中提出的SE块是可行的,它必须提供可接受的模型复杂度和计算开销。每个SE块利用压缩阶段的全局平均池化操作和激励阶段中的两个小的全连接层,接下来是几乎算不上计算量的通道缩放操作。增加了SE模块后,模型参数以及计算量都会增加,对于模型参数增加量为下面公式:

公式(5)中,r为降维系数,默认取16。![]() 表示输出的通道数量,
表示输出的通道数量,![]() 表示s阶段重复的的SE模块数量。
表示s阶段重复的的SE模块数量。
SE模块可以添加到应用到很多其他网络模型,如ResNetXt,Inception-ResNet,MobileNet和ShuffleNet等等。论文给出了SE-ResNet-50和SE-ResNeXt-50的架构,如下表所示:

对于224×224像素的输入图像,ResNet-50单次前向传播需要∼ 3.86 GFLOP。总的来说,SE-ResNet-50需要∼ 3.87 GFLOP,相对于原始的ResNet-50只相对增加了大约0.26%。
为了验证SE模块的作用论文在其他通用网络,用ImageNet上进行测试,如下表所示:
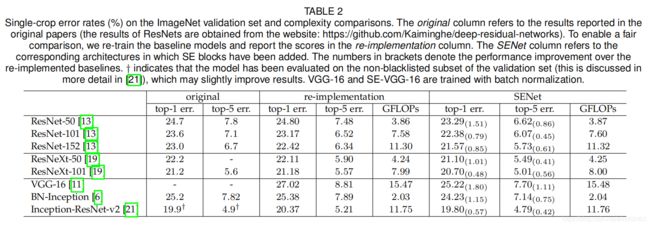
从上表可以看到在加入SE模块之后,分类的精确度均有提升。
总结
SE模块是轻量级的,为特征的通道相关性提供了权值参数,实现了通道间的注意力机制。增加了很少的开销,有效的提升了通用网络效果。网上开源的SENET实现很多可以自行学习。2019年发表的SKNET通过对感受野的自适应性优化了SENET,有兴趣的同学可以了解一下。
下一篇准备分享一下空间注意力机制网络 Spatial Transformer Networks。