图机器学习-图机器学习传统方法
图机器学习-图机器学习传统方法
最近在学习一些GNN相关的知识,想写一些笔记记录一下自己的学习过程,主要的学习资料为CS224W课程主页上面的资料和b站同济子豪兄的中文讲解。这篇博客是我2023年的第一篇博客,想以图机器学习中的传统方法作为博客的内容。

对于图上面的任务,可以分为几类
- Node-level prediction,比如银行判断一个用户是否借钱之后会按时还钱
- Link-level prediction,比如推荐算法判断是否一个用户可能会喜欢某个商品
- Graph-level prediction,比如制药判断整个分子结构是否会有好的药效
参考之前的传统机器学习,图机器学习也一样需要将node,link或者graph用一些features来表示。这篇博客主要讲的就是一些传统的方法来得到这些features。(本文的例子皆为无向图)
Node-level prediction
Node有很多种描述刻画的方式,比如最直观的node degree,即node上面的link数量(邻居的数量)
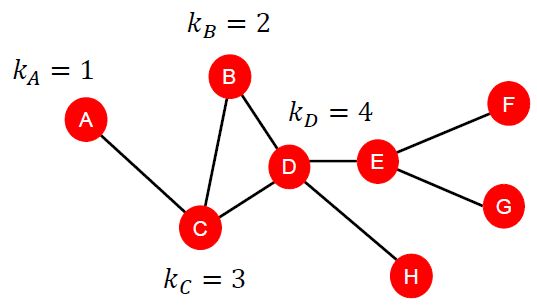
但是node degree中没有体现出邻居节点的重要程度,把影响力大的邻居和影响力小的邻居同等对待。node centrality则克服了这一点。当考虑eigenvector centrality时,一个节点的node centrality表示为邻居节点的node centrality相加。
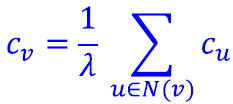
那么我们该怎么计算node eigenvector centrality呢?我们可以使用矩阵来计算

以邻接矩阵的第一行与 c \textbf{c} c相乘为例,得到等式 a λ = A 12 b + A 13 c + A 14 d a \lambda = A_{12}b + A_{13}c + A_{14}d aλ=A12b+A13c+A14d。等式的意义是节点1的centrality是它的邻居的centrality相加再除以 λ \lambda λ( A i , j A_{i,j} Ai,j用来控制是否是邻居)。
还有别的centrality也可以计算,比如betweenness centrality。这个标准的考量是一个节点是重要的,假如他在很多别的节点的shortest path上。以下面这张图为例。

假设我们想计算一下节点c的重要度,其它节点有4个,两两组合有6种,其中A到B,A到D,A到E的最短路径都需要经过C。所以 C C C_C CC为3。
还有别的centrality也可以计算,比如closeness centrality。他认为一个节点是重要的,如果他距离所有别的节点都是近的。

我们还可以考虑别的特征来刻画一个节点,比如使用graphlets。
Graphlet Degree Vector(GDV):Graphlet-base features for nodes
GDV计算的是一个节点接触的graphlets数量(需要注意的是node level定义的graphlets和graph level定义的有些不一样,node level里所有节点都是连接的)。
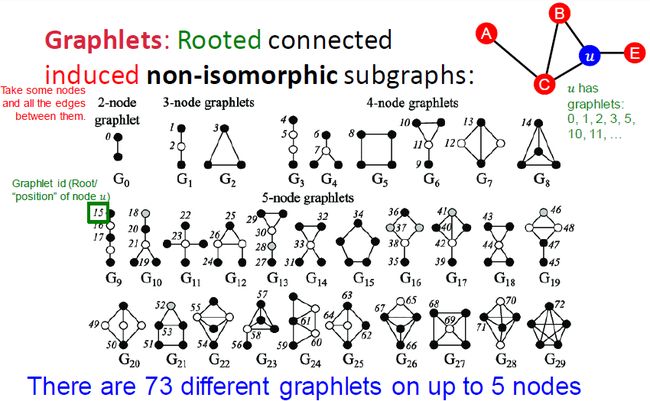
课程中举了一个例子,我们一起来看一下。
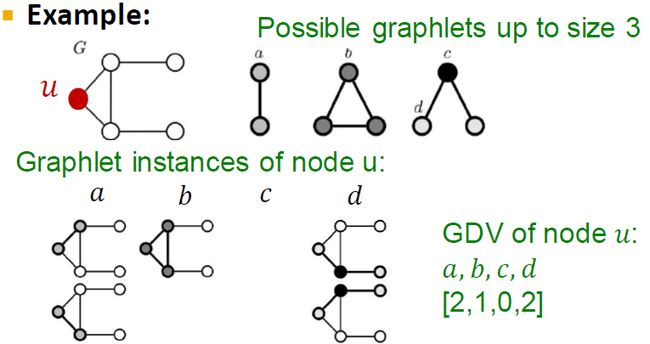
以节点u为例子,假设我们要计算size到3的graphlets数量我们可以把u节点编码成为[2,1,0,2]的向量。
Link level prediction
Link level features可以分为三种
- distance based feature
- local neighborhood overlap
- global neighborhood overlap
distance based feature
用节点之间的最短距离来判断两个节点之间的关系紧密程度。

local neighborhood overlap

可以使用多种overlap,比如共同邻居的个数,jaccard’s coefficient, Adamic-Adar index。local neighborhood overlap同样也存在着一些的局限,比如有的时候两个节点之间的共同邻居可能不存在等等问题。
global neighborhood overlap
我们可以使用katz index来刻画两个节点之间的关系
katz index: count the number of walks of all lengths between a given pair of nodes。
我们可以使用邻接矩阵的幂来求解katz index
P K \mathbf{P}^K PK来表示整个图节点之间的距离为 K K K的路径个数(可证明 P K = A K \mathbf{P}^K=\mathbf{A}^K PK=AK)。用一个例子说明一下

红色方框框出来的数字代表节点1到节点2的距离为1的路径的个数为1。
P K = A K \mathbf{P}^K=\mathbf{A}^K PK=AK简单证明

以2次方为例,蓝色方框圈出来的是与node1距离为1的节点,在这里例子中是2和4。绿色方框圈这一列是与node2距离为1的节点,这两个向量相乘,如果一个节点既与node1距离为1又与node2距离为1那么他就可以为 P 12 \mathbf{P_{12}} P12贡献+1。以此类推得到 P K = A K \mathbf{P}^K=\mathbf{A}^K PK=AK
两个节点之间的katz index可以使用下面的式子计算


越长的paht认为越不重要,所以增加了折扣系数。这里需要用到一些等比数列求和的知识。
Graph level prediction
核方法核心思想是通过某种非线性映射将原始数据嵌入到合适的高维特征空间,然后再在高维特征空间上做分类等等任务。
我们可以使用以下的kernel来衡量图的相似度
- graphlet kernel
- Weisfeiler-Lehman kernel
我们的目标是设计一个graph feature来表示一张图。我们可以联想到NLP里面的bag of words。BoW使用的是一个文档里面词语出现的次数来刻画一个文档。我们也可以在图里面参考这个思想,用节点的个数来刻画图。这个方法存在着一些缺陷,显而易见的是相同节点个数的图很可能完全不一样。如果再改进一些我们可以使用bag of node degree来刻画图。后面要记录的graphlet kernel和Weisfeiler-Lehman kernel都是借鉴了bag of的思想。
graphlet kernel
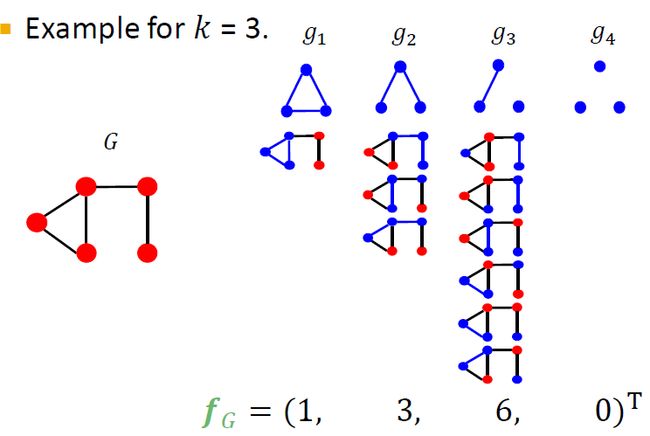
graphlet features核心思想是寻找一个图中的graphlets个数(这里graphlet中的节点可以孤立)。下面是一个例子
Weisfeiler-Lehman kernel
计算graphlet总个数的计算复杂度过高,所以又有了新的算法利用Weisfeiler-Lehman kernel。这个算法使用的思想是color refinement。乍一看很抽象,用例子就会好理解不少。



需要注意的是这里算出来的颜色的值并不是根据相加而得来的,而是根据hash table得来。我们可以这样子迭代若干次,最终得到一个图的表示。使用Weisfeiler-Lehman kernel的算法复杂度是O(n),相比于graphlet kernel大大降低。

Reference:
1:Stanford CS224W
2:b站up主同济子豪兄