数据分析需要知道的统计学知识
文中的大部分概念知识来自于《商务与经济统计学》,推荐有时间的朋友认真去读一读,相信会很有帮助!
目录
数据集的描述方法
概率分布
基于单样本的统计推断:置信区间和假设检验
相关性与回归分析
因果推断
数据集的描述方法
- 位置度量
集中趋势:平均数、加权平均数、中位数、众数;百分位数、四分位数、标准分位数
a1.平均值:平均值也称为均值(mean),它是一组数据相加后除以数据的个数得到的结果。平均值不适用于分类数据和顺序数据的集中趋势。


a2.中位数:中位数是一组数据中间位置上的代表值,不受极端值影响。中位数主要适合衡量顺序数据的集中趋势度。(中位数在面对具有极大、极小等异常值的数据时,衡量数据的集中趋势时比平均值更合理;但反之,平均值更为合理。)样本总数为奇数时,中位数为第(n+1)/2个值;
样本总数为偶数时,中位数是第n/2个,第(n/2)+1个值的平均数;
a3.众数:众数是一组数据分布的峰值,不受极端值影响。其缺点是具有不唯一性。众数只有在数据较多时才有意义,同时众数主要适合作为分类数据的集中趋势测度值。
b1.百分位数: 如果将一组数据从大到小排序,并计算相应的累计百分位,则某一百分位所对应数据的值就称为这一百分位的百分位数。(处于p%位置的值称第p百分位数)
b2.四分位数:第25百分位数又称第一个四分位数(First Quartile),用Q1表示;第50百分位数又称第二个四分位数(Second Quartile),用Q2表示;第75百分位数又称第三个四分位数(Third Quartile),用Q3表示。
b3.标准分位数:标准分位数代表了某个元素距离数据集平均值的距离,其单位为标准差,即某个元素和数据集均值间隔了几个标准差。标准分位数可取正负,取正表示改元素大于数据集平均值,反之表示小于数据集平均值。
- 变异程度
离散程度:极差、四分位数间距、方差、标准差;标准差系数
a.极差:极差即最大值-最小值。极差是描述数据离散程度的最简单的测度值,但是易受极端值的影响。
b.四分位数间距:求四分位数,需要先将数据集从小到大排列起来,按数据量平均分为四份,分别计算分割点两侧数字的平均值为Q1、Q2、Q3。间距IQR = Q3-Q1,四分位数一般配合箱线图进行可视化,用来对比不同数据集的分布情况。
c.方差:方差等于每个数据点距离平均值距离的平方。方差越大,数据集靠近中心的程度就越低。
对于全量数据来说: ;
;
对于抽样数据来说:
d.标准差:标准差等于每个数据点距离平均值距离的平均值。标准差不同于方差的是,标准差具有量纲,即单位。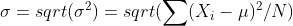
e.标准差系数:标准差系数又称均方差系数。反映标志变动程度的相对指标。总体标准差系数的计算公式为

- 偏度
分布形态、切比雪夫定理、经验法则
a.分布形态:包括左偏分布、右偏分布、正态分布。
频数分布直方图是向左偏还是右偏取决于偏度为正还是负,偏度由计算机计算,负为左偏,正为右偏,利用平均数和中位数的大小也可以判断偏度为左还是右,右偏时平均数大于中位数,左偏是,中位数大于平均数。
b.切比雪夫定理:任意一个数据集中,位于其平均数m个标准差范围内的比例(或部分)总是至少为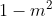 ,其中m为大于1的任意正数,适用于任何分布。
,其中m为大于1的任意正数,适用于任何分布。
c.经验法则:在正态分布中,距平均值小于一个标准差、二个标准差、三个标准差以内的百分比,更精确的数字是68.27%、95.45%及99.73%。 - 五位概括
最大、最小、中位数、下四分位数、上四分位数。箱形图是五数概括法的数据图形汇总。箱形图也称盒形图、盒须图、盒式图。用作显示一组数据的分散情况。
- 变量关系
a.协方差:用于计算两变量间的线性关系,大的正值表示强的正线性相关关系,大的负值表示强的负线性相关关系。
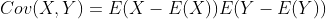
b.相关系数:由于计量单位的变化会出现协方差变大,但是相关关系并无变化。为避免这种情况,我们使用相关系数代替协方差。相关系数在-1和+1之间,值得我们注意的是,相关系数提供的是线性关系而不是因果关系。相关系数也可以看成协方差:一种剔除了两个变量量纲影响、标准化后的特殊协方差。
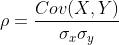
概率分布
-
离散型概率分布
a.二项分布:进行n次伯努利试验,成功概率为p,且成功了x次,发生上述情况的概率为:
1、每次试验只有两种可能的结果(“成功”、“不成功”)
2、每次试验前成功的概率为p,则不成功的概率为(1-p)
3、每次试验相互独立
b.泊松分布:指在连续时间或空间单位上发生随机事件次数的概率,根据过去单位时间段内随机事件的平均发生次数,推断未来相同单位时间内随机事件发生不同次数的概率。泊松分布由二项分布转化而来,当n>=100且p<=0.05时,用泊松分布近似二项分布的效果最好。
1.泊松分布是一种描述和分析稀有事件的概率,样本量n必须足够大。
2.λ是泊松分布所依赖的唯一参数。λ值越小,分布越偏倚,随着λ的增大,分布趋于对称。
c.超几何分布:感兴趣可查阅相关资料。
-
连续型概率分布
a.指数分布:主要应用在随机事件之间发生的时间间隔的概率问题。泊松分布是描述某一区间内发生随机事件次数的概率分布,而指数分布是描述两次随机事件发生时间间隔的概率分布。因此,两种分布有着密切的关系,在管理科学中经常将两者结合起来共同解决排队理论等有关问题。
(1) 随机变量X的取值范围是从0到无穷;
(2) 极大值在x=0处,即f(x)=λ;
(3) 函数为右偏,且随着x的增大,曲线稳步递减;
(4) 随机变量的期望值和方差为=1/λ,σ2=1/λ2。
b.正态分布:表明被测事物处于稳定的状态下,测量数据的波动由偶然因素引起。
1、服从正态分布,经验法则指68.3%数据落在一倍标准偏差之内,95.4%数据落在二倍标准偏差之内,99.7%数据落在三倍标准偏差之内;
2、只有当连续型随机变量服从正态分布时,其Z变换才能转换为标准正态分布;
3、二项分布、泊松分布的正态近似
基于单样本的统计推断:置信区间和假设检验
置信区间(confidence interval):用一个区间范围来估计总体参数,和点估计对比。一般情况下,取95%的置信度。
置信系数(confidence coefficient):置信区间包含总体参数的概率。
置信水平(confidence level):显著性水平是估计总体参数落在某一区间内,可能犯错误的概率。置信系数的百分比表示形式。一般情况下,取5%的置信水平。
零假设和备择假设:一个研究者想证明自己的研究结论是正确的,备择假设的方向就要与想要证明其正确性的方向一致;同时将研究者想收集证据证明其不正确的假设作为原假设H0。
假设检验中的概率:
α=P(第I类错误的概率)=P(当H0正确时拒绝H0)
β=P(第II类错误的概率)=P(当H0错误时接受H0),要计算β值,备选假设需要一个关于样本统计量的具体数值
1-β=统计检验功效=P(当H0错误时拒绝H0)
假设检验的步骤:
1. 确定目标检验参数
2.确定原假设H0和备选假设Ha
3. 计算检验统计量
4. 根据显著性水平α确定拒绝域
5. 将检验统计量计算值与拒绝域进行比较,得出结论
常用假设检验的类型:
总体均值的假设检验:正态z统计量--大量样本(n>=30);

总体均值的假设检验:学生t统计量(小样本)--小样本(小于30),样本的总体近似服从正态分布;
总体比例的假设检验:
1.样本来自二项分布中随机抽取
2. 样本量n很大,满足np>=15且nq>=15,其中q=1-p

总体方差的假设检验:方差检验运用统计量:(n-1)s^2/σ ^2,其中n为样本个数,s^2为方差,σ ^2为总体方差对假设值,如果总体符合正态分布,统计量分布符合卡方分布(样本方差的抽样分布)。样本来自的总体服从近似正态分布(卡方分布对样本大小不敏感,对总体是否正态分布非常敏感)

相关性与回归分析
相关分析:研究有没有关系,关系强度如何。
1.Pearson乘积矩相关系数:皮尔森相关系数评估两个连续变量之间的线性关系。建立在线性相关的基础上,一般指直线,若是曲线则要求两变量数据的间距相同或者数据取自于正态分布数据中。
样本相关系数,表示为r,介于-1和+1之间,并量化两个变量之间的线性关联的方向和强度。相关系数的符号表示关联的方向。相关系数的大小表示关联的强度。接近于零的相关性表明两个连续变量之间没有线性关联。Pearson系数对绝对数值不敏感。
2.Spearman秩相关系数:斯皮尔曼相关系数评估两个连续变量之间的单调关系。在单调关系中,变量趋于一起变化,但不一定以恒定速率变化。只要两个变量的观测值是成对的等级评定资料,或者是由连续变量观测资料转化得到的等级资料,不论两个变量的总体分布形态、样本容量的大小如何,都可以用斯皮尔曼等级相关系数来进行研究。当两个变量有具有严格单调函数关系时,那就是完全Spearman相关的 。
假设两个随机变量分别为X、Y(也可以看做两个集合),它们的元素个数均为N,两个随即变量取的第i(1<=i<=N)个值分别用Xi、Yi表示。对X、Y进行排序(同时为升序或降序),得到两个元素排行集合x、y,其中元素xi、yi分别为Xi在X中的排行以及Yi在Y中的排行。将集合x、y中的元素对应相减得到一个排行差分集合d,其中di=xi-yi,1<=i<=N。随机变量X、Y之间的斯皮尔曼等级相关系数可以由x、y或者d计算得到,其计算方式如下:
![]()
这里需要注意:当变量的两个值相同时也必须有相同的秩次,所以它们的排行是通过对它们位置进行平均而得到的。因此,斯皮尔曼相关系数对于数据错误和极端值的反应不敏感。
3.Kendall Rank(肯德尔等级)相关系数:肯德尔相关系数与斯皮尔曼相关系数对数据条件的要求相同。假设两个随机变量分别为X、Y(也可以看做两个集合),它们的元素个数均为N,两个随即变量取的第i(1<=i<=N)个值分别用Xi、Yi表示。X与Y中的对应元素组成一个元素对集合XY,其包含的元素为(Xi, Yi)(1<=i<=N)。当集合XY中任意两个元素(Xi, Yi)与(Xj, Yj)的排行相同时(也就是说当出现情况1或2时;情况1:Xi>Xj且Yi>Yj,情况2:Xi
回归分析:研究影响关系如何,有没有影响关系,影响关系如何。线性回归(一元线性、多元线性)VS非线性回归(logistic回归,)
1) 指示自变量和因变量之间的显著关系;2) 指示多个自变量对一个因变量的影响强度。
三个度量:自变量的个数、因变量的类型以及回归线的形状。
a.线性回归:Y=a+b*X + e,其中a 表示截距,b 表示直线的倾斜率,e 是误差项。这个等式可以根据给定的单个或多个预测变量来预测目标变量的值。
线性回归要点:
1)自变量与因变量之间必须有线性关系;
2)多元回归存在多重共线性,自相关性和异方差性;
3)线性回归对异常值非常敏感。它会严重影响回归线,最终影响预测值;
4) 多重共线性会增加系数估计值的方差,使得估计值对于模型的轻微变化异常敏感,结果就是系数估计值不稳定;
5)在存在多个自变量的情况下,我们可以使用向前选择法,向后剔除法和逐步筛选法来选择最重要的自变量。
a1.一元线性:单变量,回归线使得每个Y的实际值与预测值之差的平方和最小(评估拟合程度好坏,误差平方和SSE),(回归平方和SSR:因变量的回归值-直线上的Y值与其均值-给定点的Y值平均的差的平方和)
选择最佳拟合曲线的标准可以确定为:使总的拟合误差(即总残差)达到最小:最常用的是普通最小二乘法——所选择的回归模型应该使所有观察值的残差平方和达到最小。使用梯度下降法寻找最优解(求偏导为0)。
b.Logistic回归:当因变量的类型属于二元(1 / 0、真/假、是/否)变量时,我们就应该使用逻辑回归。这里,Y 的取值范围是从 0 到 1。
![]()
![]()
要点:
1)Logistic回归广泛用于分类问题;
2)Logistic回归不要求自变量和因变量存在线性关系。它可以处理多种类型的关系,因为它对预测的相对风险指数使用了一个非线性的 log 转换;
3)为了避免过拟合和欠拟合,我们应该包括所有重要的变量。有一个很好的方法来确保这种情况,就是使用逐步筛选方法来估计Logistic回归;
4)Logistic回归需要较大的样本量,因为在样本数量较少的情况下,极大似然估计的效果比普通的最小二乘法差;
5) 自变量之间应该互不相关,即不存在多重共线性。然而,在分析和建模中,我们可以选择包含分类变量相互作用的影响;
6)如果因变量的值是定序变量,则称它为序Logistic回归;
7)如果因变量是多类的话,则称它为多元Logistic回归。
计算方法:常数项表示自变量取值为0时,比值的自然对数值;自变量前的回归系数。回归系数表示自变量每改变一个单位,比值比自然对数值的改变量。
评估方法:通过观测样本的极大似然估计值来选择参数。logistic 回归是对 0-1 响应变量的期望做 logit 变换,然后与自变量做线性回归。参数估计采用极大似然估计,显著性检验采用似然比检验。通常采用 ROC 曲线与 lift 曲线作为评价logistic回归模型的指标。
ROC 曲线:
1.TPR:True Positive Rate(正例覆盖率),将实际的1正确地预测为1的概率;
2.FPR:False Positive Rate(负例误判率),将实际的 0 错误地预测为1的概率。1-FPR其实就是“负例的覆盖率”。
使TPR尽量地大,而FPR尽量地小。纵坐标为 TPR ,横坐标为 FPR 。向左上角凸意味着有较高的 TPR,与较小的 FPR。故而ROC曲线下的面积可以定量地评价模型的效果,记作AUC,AUC越大则模型效果越好。
lift 曲线:
正例的命中率是指预测为正例的样本中的真实正例的比例。
为了画 lift 图,需要定义一个新的概念depth深度,这是预测为正例的比例。
1.如果是类似信用评分的问题,希望能够尽可能完全地识别出那些有违约风险的客户(不使一人漏网),我们需要考虑尽量增大TPR(覆盖率),同时减小FPR(减少误杀),因此选择ROC曲线及相应的AUC作为指标;
2.如果是做类似数据库精确营销的项目,希望能够通过对全体消费者的分类而得到具有较高响应率的客户群,从而提高投入产出比,我们需要考虑尽量提高lift(提升度),同时depth不能太小(如果只给一个消费者发放传单,虽然响应率较大,却无法得到足够多的响应),因此选择lift曲线作为指标。
多项式回归:对于一个回归等式,如果自变量的指数大于1,那么它就是多项式回归等式。
回归结果诊断——空间聚类、倾向性、冗余、性能、效果
因果推断
相关性通常是对称的,因果性通常是不对称的(单向箭头),相关性不一定说明了因果性,但因果性一般都会在统计层面导致相关性。
相关性是指在观测到的数据分布中,X与Y相关,如果我们观测到X的分布,就可以推断出Y的分布;因果性是指在操作/改变X后,Y随着这种操作/改变也变化,则说明X是Y的因。
我们需要确切地知道因果性,且无法通过ABtest简单地判断。
因果推断的核心思想在于反事实推理,即在我们观测到X和Y的情况下,推理如果当时没有做X,Y'是什么。
A/B Test实际上是判断因果性的很有效的方法,但有时候成本过高、测试类型太多无法采用。
a.随机实验方法:强化学习中的多臂老虎机,实际上是对explore和exploit的平衡。* explore,随机选择一个动作,在上面的问题中是随机选择一个算法* exploit,选择收益最高的动作,在上面的问题中是选择当前效果最好的算法
通过某种规则(e-greedy等)重复上述过程,优点是可以同时测试多种算法,并且每个用户都能使用到最好的算法,减少流失可能性。缺点是效果难以评估,也很难让用户按照我们的想法行动。
b.自然实验:随机分配(分组)、人为干预(施加不同的treatment)、结果比较(满足上述三个条件中的两个).关键在于,实验对象是否能“自然”/随机地分组。断点回归——在回归过程中,观察在临界点处是否出现断层/断点。
- 如果可以的话,尽可能使用随机实验(ABtest……)
- 如果无法进行随机实验,则探索自然实验(断点回归……)
- 如果自然实验也无法找到,考虑使用基于条件的方法(倾向得分匹配……)